
面向航空领域HowNet构建的术语内部动态角色标注
2021-03-16 13:29赵超丽王裴岩蔡东风
计算机应用与软件 2021年3期
赵超丽 王裴岩 蔡东风
(沈阳航空航天大学人机智能研究中心 辽宁 沈阳 110136)
0 引 言
HowNet是使用最为广泛的可计算中文常识语义知识库,能够支持相似度计算[1]、相关度计算[2]、倾向性计算[3]和神经网络语言模型[4-6]训练等,被广泛应用于自然语言处理的各个领域。HowNet面向通用领域,但对专业领域如航空领域的自然语言理解任务的支持能力尚显不足。
近年来,文献[7-9]先后进行了对面向航空领域的术语语义知识库构建方法的研究,基于HowNet语义理论体系对HowNet在航空领域的应用进行了扩展。但现有的航空领域HowNet构建方法还未能实现大规模构建,主要困难在于HowNet定义的动态角色种类较多,共计116种(2012版[10]),使其选择范围较大,增加了航空术语内部动态角色标注难度。而术语内部动态角色标注是航空领域HowNet构建的关键环节,其直接影响航空领域HowNet的规模与质量。就术语内部动态角色的标注方法而言,文献[7]采用了手工标注的方法,为后续开展自动化标注研究积累了语义资源。文献[8]采用了基于角色框架填充的方法,该方法虽实现了自动化标注,但术语内部词语之间的动态角色被固定,导致系统泛化能力较低。文献[9]提出了基于最大熵分类、基于相似度计算、基于最大熵分类与相似度计算相结合的一系列方法,并且推荐多个动态角色供用户参考,最终实现了术语内部动态角色的标注,但该方法仅仅依靠将一些语义特征集中训练分类器仍未能很好地解决动态角色种类多造成标注困难的问题。
针对该问题,本文提出了一种基于KNN分类算法的术语内部动态角色标注方法。首先通过对术语内部词语DEF项的分析对训练集进行预选择,有效地降低了动态角色关系类型选择范围。然后利用DEF及词向量两种方法所蕴含语义信息的差异性,提出了一种训练单位排序表合并算法,有效地提高了动态角色排序准确性。最后经真实数据集上的实验验证,当推荐的动态角色数量为10时,推荐结果的准确性达95%以上,从116种动态角色关系类型中过滤出10个动态角色,有效降低了选择范围,且绝大多数情况下正确动态角色关系类型被排在第一位或第二位,能够快速选取到正确动态角色关系,提升了标注准确率和效率。
1 相关概念
一些本文用到的相关概念定义如下:
(1) 术语内部词语,是指构成术语的词语,如:“工程”“管理”“标准”均为术语“工程管理标准”的内部词语。
(2) 标注单位,是指术语经过内部依存结构分析所确定的具有依存关系的词对,表示为(w1,w2),其中依存方向为w1依存于w2。例如,术语“工程管理标准”经过术语内部依存结构分析,可以得到如下2个标注单位:(工程,管理)、(管理,标准)。
(3) 训练单位,是指由标注单位和动态角色组成训练集中的一个样例,表示为((w1,w2),EventRole),其中:(w1,w2)为标注单位,EventRole为动态角色。比如,((工程,管理),patient)。
(4) 首义原,是指术语内部词语DEF项中的第一个义原。比如术语“工程管理标准”中内部词语“工程”选择的DEF项为:DEF={affair|事务:domain={industrial|工}},则内部词语“工程”DEF项的首义原为“affair|事务”。
(5) 术语内部动态角色标注,是指采用HowNet定义的动态角色体系为术语中所有具有依存关系的内部词对之间的语义关系进行标注,明确了术语内部非核心词语之间以及非核心词与核心词之间的语义关系,它为领域术语语义知识库中术语DEF(概念描述)[11]的生成标注了内部词语之间的语义关系,使得术语内部的简单概念可以通过动态角色有机关联起来,从而形成表示术语本身语义知识的复杂概念[9],在领域术语语义知识库构建过程中起着关键性的作用。例如:“((工程,管理),patient)、((管理,标准),host)”,其中:“工程”“管理”“标准”均为术语“工程管理标准”的内部词语,“工程”依存于“管理”“管理”依存于“标准”,动态角色“patient”表示“工程”是“管理”的受事者,动态角色“host”表示“管理”是“标准”的宿主。根据该术语的内部依存结构,将术语内部词语的DEF以及两者之间的动态角色按照知识系统描述语言(Knowledge Database Mark-up Language,KDML)[11]的规定而生成的DEF如下:DEF={Standard|标准:host={manage|管理:patient={affair|事务:domain={industrial|工}}}},该术语DEF的结构分析如图1所示。

图1 术语“工程管理标准”DEF的结构分析
2 术语内部动态角色标注方法
2.1 基于首义原的KNN样本预选择
HowNet先把世界知识本体进行定义,然后在定义里作具体的区分,采取自上而下的方法,并采用以义原为基的策略。基于此思想,本文首先使用术语内部两词语DEF项中的首义原对训练集进行预选择;接着对动态角色关系做进一步的标注。
标注单位(w1,w2)对应的义原类别组合可表示为:(Class1,Class2)。其中:Class1、Class2分别表示词语w1和w2已选DEF项的首义原所属的义原类别。HowNet将义原分为属性类、属性值类、事件类、实体类四类。因此,本文根据标注单位对应的义原类别组合可将已有的样本数据分为16类。
HowNet中每个动态角色都有其特定的描述对象,使其接纳标注单位的条件比较苛刻,从而造成有些动态角色关系类型只出现于固定的几个义原类别组合对应的训练单位中。比如,动态角色host用于标注属性的宿主,一般多出现于义原类别组合为(实体类,属性类)所对应的训练单位中;动态角色degree、scope分别用于描述属性值的程度、范围;动态角色agent表示行动的事件类型中“变关系”“变状态”“变属性”和“使之动”四类事件中充当“变”这一功能的实体,一般情况只会在义原类别组合为(实体类,事件类)所对应的训练单位中出现。
在样本预选择过程中,首先利用HowNet的义原分类体系Taxonomy[10]。图2为HowNet 2012版中义原分类体系部分展示图,从上到下从左往右依次为属性类、属性值类、实体类和事件类,该四个义原类别包含的义原个数分别为245、887、154和812个。该分类体系为标注单位中术语内部词语找到其DEF项中首义原所属的义原类别,从而获得标注单位对应的义原类别组合。然后在已有的样本数据中选择与其具有相同义原类别组合的数据,作为下一过程即基于KNN分类算法的动态角色标注方法的训练样本数据。

图2 HowNet中义原分类体系部分展示图
2.2 基于KNN分类算法的动态角色标注
由于目前国内外许多大规模的知识库大多都面向通用领域[12-14],在特定领域研究较少,造成领域术语语义知识库的可获得标注资源匮乏,且标注成本代价较高,限制了当前需要更多数据支撑的深度学习等主流算法的使用。KNN算法是一种基于实例学习的分类算法,适合多分类任务,不需要构建分类模型,对新增类别有较好的适应能力[15]。本文将动态角色标注转化成对标注单位的分类问题,并且将标注单位所对应的动态角色关系类型作为分类的类别。
本文将待标注动态角色的标注单位与训练集中每一个训练单位中的标注单位进行相似度计算,并将此相似度值作为训练单位的分值,根据分值的大小将训练单位按从高到低的顺序进行排序,从而得到训练单位排序表Score={s1,s2,…,sn},该训练单位排序表为KNN分类算法找到了相似度与待分类样本数据最近的K个邻居,具体如下所示:
(1)
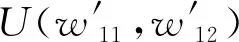
(2)
本文将KNN分类算法中最近邻样本数据的获取转化为训练集中训练单位排序表的生成。KNN分类算法是对最近邻样本采用多数表决投票法来决定待分类样本的类别,因此最近邻样本数据选取的好坏即训练单位排序表生成策略制定的优劣对分类效果有着重要影响。
下面介绍生成训练单位排序表的三种策略,分别为基于词语DEF相似度的排序表生成、基于词向量相似度的排序表生成、训练单位排序表合并。其中,DEF是对词语概念定义的描述,包含有丰富的义原信息,但脱离了具体上下文语境;而词向量表示与词语DEF所隐含的语义信息不同,它更能反映上下文信息、主题信息和词的功能等,蕴涵了词语在大规模数据集中的语义信息,词语之间的语义和句法关联关系在空间中也得到很好的体现[16]。本文利用DEF及词向量两种方法蕴涵语义信息的差异性,提出了一种训练单位排序表合并算法,该算法最大化地发挥出基于不同词语语义表示的相似度计算的优势,实现了两者排序的互补,提高了正确动态角色关系类型在候选答案中的排序准确性。
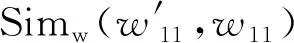
该算法定义了HowNet义原间的相似度计算公式。通过利用HowNet中DEF项由不同义原构成,加权组合各个部分义原相似度实现了登录词的相似度计算。通过对未登录词进行概念切分和语义自动生成,解决了未登录词无法参与语义计算的难题,实现了任意词语在语义层面上的相似度计算[17]。
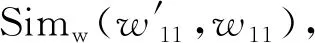
(3)

3) 训练单位排序表合并算法。
提出了一种训练单位排序表合并算法。已知基于词语DEF的相似度计算生成的训练单位排序表ScoreD={d1,d2,…,dm}和基于词向量的相似度计算生成的训练单位排序表ScoreE={e1,e2,…,em}。首先将表ScoreD中的元素di和表ScoreE中的元素ei依次按照各自所在表中顺序各取前n个,然后根据动态角色数量的大小将该2n个训练单位按从高到低的顺序进行排序,从而得到新的训练单位排序表ScoreC={c1,c2,…,c2n}。在该训练单位排序表合并算法中,未采用对两种相似度值规范化线性组合后再排序,原因在于该方法会拉低标注单位的相似性。
下面将举例对该算法进行说明与分析。例如,待标注动态角色的标注单位为(信号,选择),该标注单位希望从训练集中学习到的动态角色为“content”,动态角色“content”表示“信号”是“选择”的内容,其训练单位形式表示为:((信号,选择),content)。由三种策略得到的训练单位排序表部分结果如图3、图4、图5所示,训练单位排序表合并算法中n取值为5。
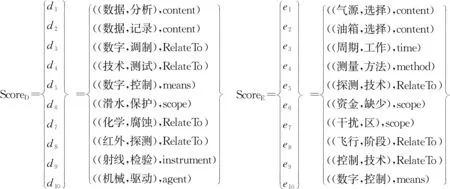
图3 训练单位排序表ScoreD 图4 训练单位排序表ScoreE

图5 训练单位排序表ScoreC
可以看出,当KNN分类算法中的K取值为9时,基于训练单位排序表ScoreD、ScoreE、ScoreC生成的候选动态角色集分别为ResultD{RelateTo、content、means}、ResultE{RelateTo、content、scope}、ResultC{content、RelateTo、time},其中候选动态角色集中包含前三位对应排序位置上的动态角色,并且正确动态角色“content”在候选动态角色集ResultC中位列第一,而在候选答案集ResultD、ResultE中都只位列第二。由此可知,基于本文提出的训练单位合并算法生成最近邻的KNN算法,提高了正确动态角色在候选答案集中的排序准确性。
3 实 验
3.1 实验数据集
本文实验从手工构建好的航空术语语义知识库[7]中抽取出500条航空术语DEF。人工将每条术语DEF分解成若干个训练单位以及术语内部词语DEF,去除重复的数据后,数据集最终共有1 587个不同的训练单位,共出现了38种动态角色,其分布情况如图6所示。词向量数据来源于腾讯AI实验室公开的中文词向量数据集[18],包含800多万个中文词汇,每个词对应一个200维的向量。本文从中抽取了294 144条数据作为基于词向量的相似度计算的语料。该实验均基于十折交叉验证下进行。
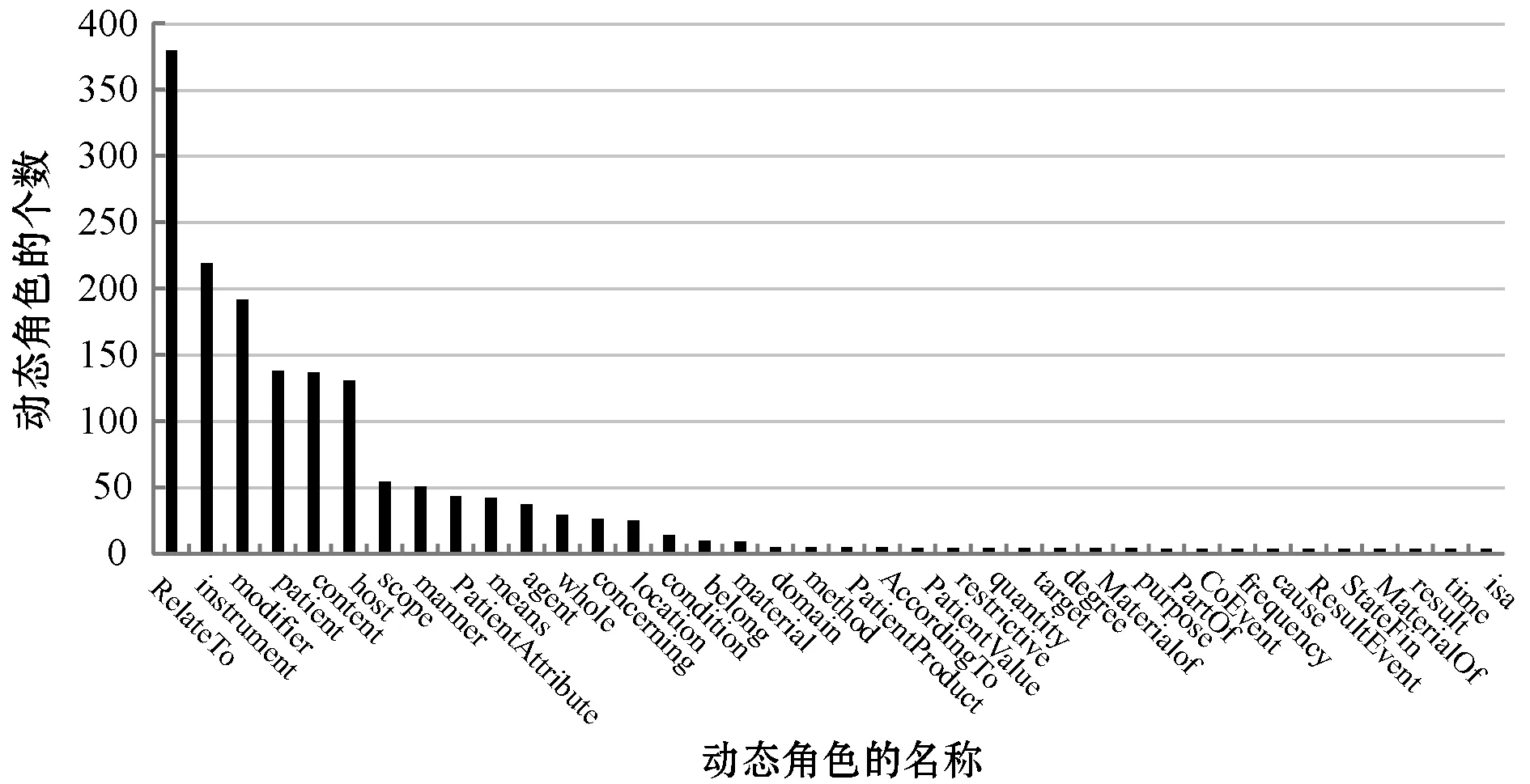
图6 数据集中动态角色的分布情况
3.2 评价指标
由于在术语内部动态角色标注中,如果系统只推荐Top1的动态角色,准确率会很差,所以在当前自然语言处理技术不够成熟的情况下,一般先推荐多个动态角色供用户参考。在此类问题中,不仅需要考察系统推荐出的动态角色正确与否,还需要关注正确答案在系统推荐的多个结果中所排列的位置。这里隐含了评价术语内部动态角色辅助标注方法的两个指标:准确率P和平均倒数排名MRR(Mean Reciprocal Rank)。实验对所推荐动态角色候选集合进行排序,MRR关心推荐集合内准确答案的位置,MRR值越大说明目标动态角色在推荐结果集合中的位置越靠前,位置越靠前则表明用户体验越好。

(4)

(5)
式中:|Q|是测试集中的样本个数;ranki表示测试样本i的动态角色排名,如果目标动态角色出现在推荐结果集合中的第二位,则ranki=2。
3.3 实验结果分析
为了评估本文方法在术语内部动态角色标注中推荐结果的好坏,在训练集经过基于首义原预选择的情况下,设置了排序准确性实验、推荐准确性实验。为了测试训练样本预选择对KNN算法分类结果的影响,设置了样本预选择验证相关实验。该实验中KNN分类算法的最近邻生成方法均包括基于DEF相似度计算、基于词向量相似度计算、训练单位排序表合并算法。
3.3.1排序准确性实验
推荐动态角色数量为7,K值取1到45,其得到的MRR值如图7所示。由图7可知,随着K值的变化,排序表合并算法、基于DEF生成最近邻的KNN算法的MRR值较为平稳,且均在0.72以上;而基于词向量生成最近邻的KNN算法在K值小于31时,MRR值也在0.70以上。根据MRR的计算方法,该实验结果说明绝大多数情况下正确动态角色关系类型被排在第一位或第二位,这验证本文方法排序的有效性,能够快速选取到正确动态角色关系,一定程度上降低了人工选择难度。当K=9时,基于排序表合并算法生成最近邻的KNN算法的MRR值最高,不同K值下,排序表合并算法始终优于其他两种算法,且本实验是在十折交叉验证下进行,因此选取K=9为本文实验中KNN算法的最优K值。

图7 不同K值下的MRR值
3.3.2推荐准确性实验
设定K值为9,推荐动态角色的数量取1到15,其得到的平均准确率如图8所示。可以看出,随着推荐动态角色数量的增加,三者的平均准确率都在提高,且当推荐的动态角色数量大于7时,三者的平均准确率增长趋势逐渐趋于平缓。当推荐的动态角色数量为10时,推荐结果的准确性达95%以上,说明推荐结果涵盖正确动态角色关系,使得正确动态角色关系能被选择到,从90种动态角色关系类型中过滤出10个动态角色,大大降低了选择范围。

图8 不同推荐动态角色数量下的平均准确率
3.3.3样本预选择验证实验
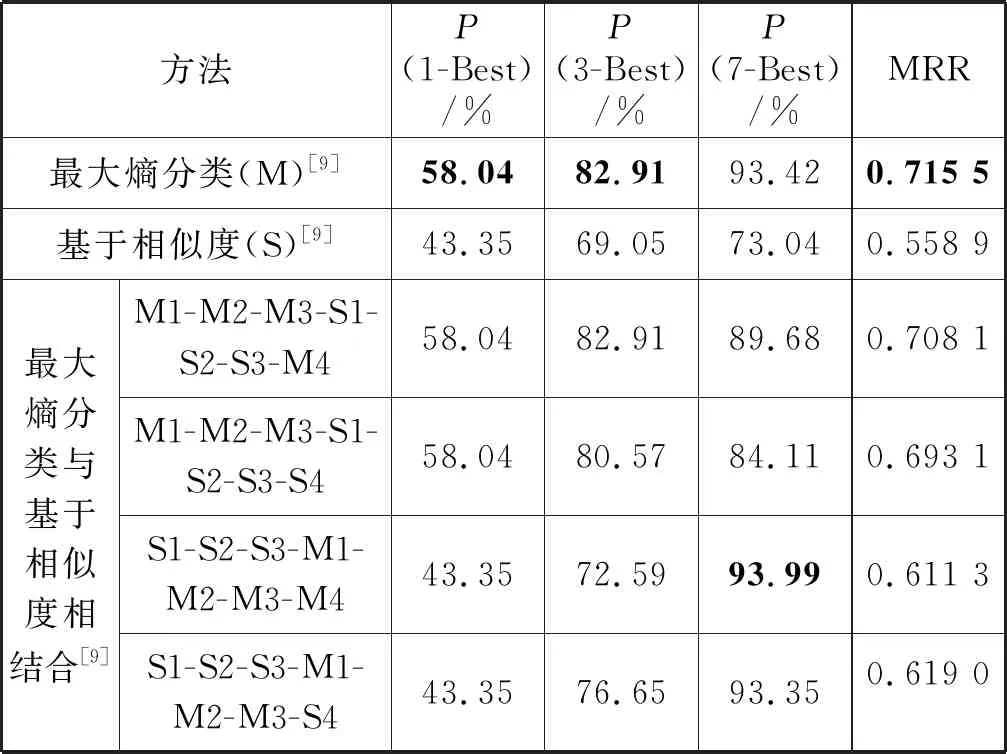
表1列出了K值为9时,基于DEF、基于词向量、排序表合并算法生成最近邻的KNN分类算法在训练集基于首义原预选择与未预选择的对比实验结果。以及文献[9]方法在该数据集上的实验结果。显示了每种方法的1-Best、3-Best和7-Best(最有可能成为正确答案的1个、3个和7个候选动态角色)在测试集上的平均准确率以及7-Best的平均倒数排名MRR值。
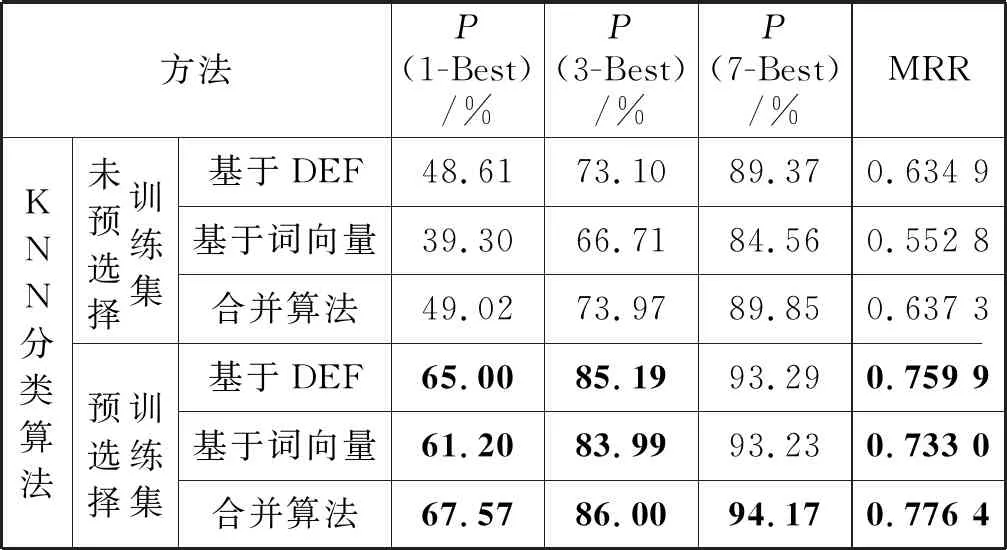
表1 对比实验结果
续表1
表1中:“M1,M2,M3,M4”(“S1,S2,S3,S4”)是基于最大熵分类方法(基于相似度方法)获得的动态角色排序表中的4个不同的动态角色。按照一定的推荐规则,类如优先级顺序为“M1-M2-M3-S1-S2-S3-M4”,将不同的动态角色添加入动态角色候选答案集。
从表1可见,本文方法即训练集经过基于首义原预选择的KNN分类算法的MRR值,均明显高于文献[9]方法,其中训练单位排序表合并算法生成最近邻的KNN算法表现最好,平均准确率P(1-Best)、P(3-Best)、P(7-Best)分别提高了9.53、3.09和0.18个百分点,平均倒数排名MRR值提高了0.060 9。
通过表1的实验结果可得以下研究结论:(1) 通过对比训练集预选择与未预选择的实验结果可看出,基于首义原对训练集预选择后,评测指标均有大幅度提高,这说明利用首义原对训练集预选择后再使用KNN分类算法会具有更高的动态角色标注准确率。(2) 通过对比基于DEF与基于词向量生成最近邻KNN算法的实验结果可看出,在本实验中基于DEF生成最近邻的方法优于基于词向量生成最近邻的方法,原因在于本文的术语内部语义关系标注是以HowNet为基础。并且,基于DEF与基于词向量生成最近邻KNN算法两者实验结果间的差距在训练集预选择后变小,究其原因在于训练集预选择阶段也利用了DEF项信息。
图7、图8和表1的实验结果表明,基于训练单位排序表合并算法生成最近邻的KNN算法明显优于基于词语DEF、基于词向量生成最近邻的KNN算法,充分说明在KNN分类算法的最近邻样本数据选择方法中即训练单位排序表生成策略中,训练单位排序表合并要比只用基于词语DEF相似度的排序表生成或基于词向量相似度的排序表生成更加适合本文任务中KNN分类算法最近邻样本集的确定。原因在于基于词语DEF的相似度算法计算出的训练单位其相似性更多地体现在义原信息方面,而基于词向量的相似度算法计算出的训练单位其相似性相对较多地体现在上下文语法和语义信息方面。本文算法将隐含不同语义信息的相似度算法计算生成的训练单位排序表合并,实现了两者排序的互补。
4 结 语
本文基于HowNet的理论体系,提出了一种面向领域术语语义知识库构建任务的术语内部语义关系辅助标注方法。利用术语内部具有依存关系的两词语的DEF项首义原对训练样本数据进行预选择,并在最近邻样本选择阶段融合了基于DEF的语义相似性及基于词向量的语境分布相似性,实现了基于KNN分类算法的动态角色标注。实验结果表明,该方法可以有效地降低动态角色关系类型选择范围,提升了标注准确率和效率。
未来可以利用KNN的分类结果,在动态角色标注中加入主动学习[19]技术,使系统选取那些有潜在价值的样例予以标注[20],期望能在较小训练集合的情况下获得较高的动态角色推荐准确率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
英美文学研究论丛(2017年2期)2017-03-01
长江学术(2015年1期)2015-02-27
