
一种基于最短路径的视频摘要方法
2021-03-15 04:24葛钊,赵烨
合肥工业大学学报(自然科学版) 2021年2期
葛 钊, 赵 烨
(1.合肥工业大学 智能制造技术研究院,安徽 合肥 230051; 2.合肥工业大学 计算机与信息学院,安徽 合肥 230601)
0 引 言
视频内容作为多媒体信息的载体之一,一直被广泛应用于生活的方方面面。近些年来,随着移动电话和其他面向消费者的相机设备的快速发展,以及互联网技术和多媒体技术的飞速发展,视频内容特别是用户视频的数量日益增长,这些海量的视频数据给视频存储、传输、检索等带来巨大的压力[1]。而且由于视频内容错综复杂,观众在浏览视频时会耗费大量的时间去寻找自己真正感兴趣的内容。
在这样的背景下,视频摘要技术应运而生。所谓视频摘要,就是以简短的内容概括原始视频的主要内容,一般有静态的摘要和动态的摘要,静态的摘要从原始视频中抽取一些具有代表性的关键帧以生成摘要,而动态的摘要是由原始视频的一些视频片段组成的。相对于动态视频摘要而言,静态视频摘要不受视频时序的约束,故形式更加直观且灵活[2]。基于此,本文主要研究静态视频摘要。
静态视频摘要即关键帧的提取,最早可追溯到20世纪90年代。至今针对此问题,许多学者进行了大量的研究并取得了一定的成果。比较典型的有基于聚类的方法,文献[3]提出了VSUMM(video SUMMarization)方法,该方法基于帧图片的颜色特征对视频帧进行K均值聚类,选取每个类的中心作为关键帧,从而生成视频摘要;文献[4]采用FCM(fuzzy C means clustering)算法对帧图片进行聚类求得各个类的隶属度矩阵,将隶属度高的帧作为关键帧;文献[5]提出了STIMO 方法,该方法通过提取原始视频帧的颜色特征,再使用FPF(farthest point-first) 算法对视频帧进行聚类,选取聚类中心并去除无意义的冗余关键帧;文献[6]在DBSCAN算法的基础上进行改进,提出了新的对视频进行聚类的VSCAN 方法,最后选择聚类中心作为关键帧;文献[7]基于聚类方法做出了尝试,首先对视频帧进行聚类,将每一类作为GOPs(groups of pictures),对GOPs 通过一种迭代算法进行排序,再根据摘要长短需求选取合适的关键帧。基于图模型的方法将视频帧间的关系以图的形式表达,图的顶点即为视频帧,连接顶点的边一般为帧间的相似性度量,最后通过相关目标函数的优化计算生成关键帧。文献[8]对视频采样,提取采样视频帧的颜色特征,将每一个采样视频帧看作德劳内(Delaunay) 图的顶点并构建德劳内图,通过移除德劳内图中的部分边进行聚类,最后选取距离聚类中心最近的一帧作为关键帧;文献[9]在上述方法的基础上进行改进,在移除德劳内图中的部分边进行聚类时,加入了结构约束,进一步保证了能够更好地保留类内的边,同时移除类间的边;文献[10]通过视频帧构建K近邻图,将其分割为多个子图,最后通过一个混合模型选取关键帧;文献[11]通过构建骨架(skeleton) 图,使用最小生成树(MST) 的方法对顶点进行筛选排序,从而选取关键帧集合。
这些传统的基于聚类方法和图模型方法的有效性都已得到验证,然而其实都有各自的缺陷。例如聚类方法中往往要人为设定初始聚类中心、确定关键帧数目、选择阈值等,关键帧提取一定程度上受到主观因素影响;虽然层次聚类方法[12-13]无需提前设定聚类中心和关键帧数目,但是其有着计算复杂度大、合并点或分裂点难以选择的缺点。而基于图模型的方法共同点是将视频帧看作图的顶点,通过边的权重来衡量2个顶点的相似性,实际情况中,一个视频的视频帧数量往往是相当大的,如果考虑所有的帧图片间的关系,那么图模型会变得相当复杂,计算量也会加大。
本文将聚类方法和图模型的方法结合并优化,提出了一种新的基于有向图最短路径算法的视频摘要方法(shortest path for video summary,SPVS)。SPVS方法先将视频分段处理,之后在分段内部进行聚类操作,在构建图模型时引入了顶点连接的约束条件,大大降低了图模型的复杂度,最后将关键帧提取问题转化为最短路径求解问题。
1 SPVS算法
SPVS算法的主要步骤如图1所示。
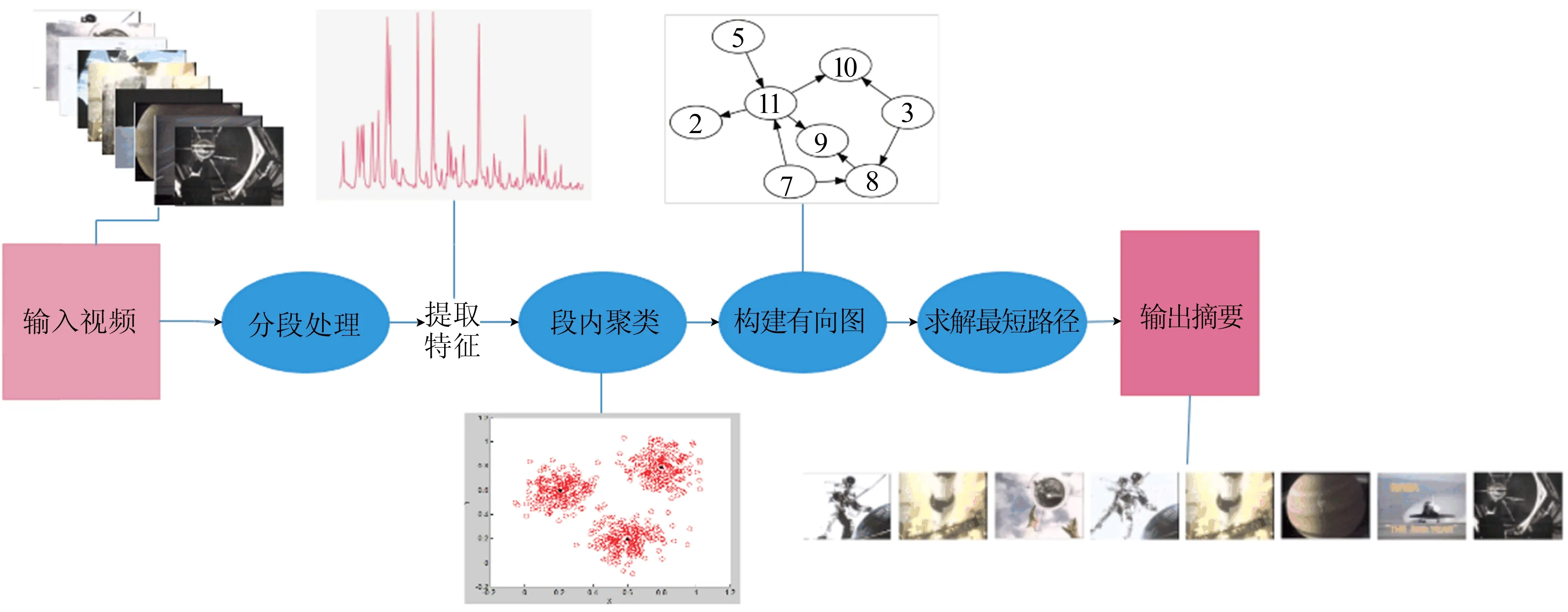
图1 SPVS算法流程
对于输入的视频首先进行分段处理,也就是将其分为n个分段,从每个分段文章中提取帧图片的颜色特征并进行一次聚类处理,在每个分段中选取距离聚类中心最近的20张帧图片并以此构建有向图,最后转化为最短路径问题,通过求解结果生成视频摘要。
1.1 视频分段处理
静态视频摘要的生成可以分为2个步骤:① 视频的分段处理; ② 基于分段的结果在每段中进行关键帧的提取。将视频分成合适的分段对于最后的摘要生成是有好处的,传统的方式有均匀采样或者随机采样,这种随意的分段方式显然不能很好地符合视频的真实情况;也有基于视频边界检测的方法[14-15]找到视频中镜头突变的帧作为边界来分割视频,这种方法对于一些编辑过的有明显的镜头切换的视频效果较好,而对于未编辑过的用户视频往往并不能合适地进行分段。由于人们在观看视频时容易受到运动信息变化的影响,文献[16]提出了一种称之为SuperFrame的视频分段方法,初始对视频帧均匀采样,通过计算采样位置的前向信息、后向信息以及运动信息对目标函数进行优化并使之收敛,最后确定视频的分段位置,本文在分段处理上采用这种方法。
1.2 提取特征和段内聚类
在视频摘要领域,图片颜色特征、纹理特征、运动估计特征被广泛使用, 其中颜色特征和运动特征起着主导作用。本文将采用颜色特征,与一般方法中使用的颜色直方图形式不同,本文采用熵值的形式,图像熵反映了图像包含的信息量,通过对RGB 3个不同颜色强度平面计算熵值,可以得到图像传送的平均信息,即
Efi=[ErEgEb]
(1)
其中:Efi为视频帧序列中第i帧的特征向量;Er为图像在红色平面的熵值;Eg为图像在绿色平面的熵值;Eb为图像在蓝色平面的熵值。
将视频序列分成了n个分段,在每段中提取帧图片的熵值信息,并在分段内部进行聚类操作。本文使用FCM聚类算法,FCM算法是一种以隶属度来确定每个数据点属于某个聚类程度的算法。该算法首先用0~1的随机数初始化隶属度矩阵,且矩阵所有元素和为1,然后开始迭代直到目标函数收敛到极小值,根据迭代结果,由最后的隶属矩阵确定数据所属的类,显示最后的聚类结果。本文使用FCM聚类算法的目标函数定义为:
(2)
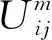
(3)
(4)
根据最后聚类结果在每个分段中选取隶属度最高的20张图片,n个分段后得到图片帧集合S={S1,S2,S3,…,Sn}作为摘要候选帧。
1.3 构建有向图
对于集合S中的帧图片,本文提取图片的加速稳健特征(speeded up robust features, SURF),其结果是一个64维的向量,代表一张图片帧。
SURF特征是一种稳健的图像识别和描述算法,不仅拥有尺度不变性,而且相对于尺度不变特征变换(scale-invariant feature transform,SIFT)而言更加高效。将帧集合Si作为一个整体,基于SURF特征计算两两帧集合中图片的相似度Aij,且0≤Aij≤1,构建相似度矩阵。如对于集合S1、S2,相似度矩阵如下:
(5)
其中,A11为集合S1中的第1帧和集合S2中的第1帧的相似度。
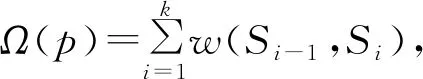
有向图的连接关系可以用一个邻接矩阵M来表示,矩阵M中元素Mij,即顶点Si到顶点Sj的连接的边。若边存在的话,则Mij=w(Si,Sj);不存在,则置为∞。本文将集合S中所有顶点考虑进来,找到它们两两的连接关系,生成邻接矩阵并构建有向图。在实际构建有向图时,发现如果对于所有顶点都产生连接的话将是不符合实际的。对于本文的任务来说,需要一定的约束条件。首先,视频是有时序的,Mij若存在,则j>i;其次,如果时间上相隔一定距离的顶点中帧图片差异很大,那么此时相似度φ会很小,它们连接的边的权重w也会很小,甚至会小于中间顶点的连接边的和,此时计算最短路径将会错误地淘汰中间顶点,从而使最后产生的摘要缺少信息,基于此,定义一个阈值Tmin,Mij若存在,则Mij≥Tmin;最后,在实验时发现,对于有些视频,基于2个约束条件构建的有向图在寻找最短路径时,还是会或多或少地错误淘汰一些关键顶点,为此在第2个约束条件的基础上再加上条件,即若Mij存在,则对于所有的i≤k≤j,都有w(Si,Sk)≥Tmin。
综上所述,本文将每个视频分段视为顶点,相似度作为连接顶点的边,并且w(Si,Sj)=min(Aij),在约束条件下构建了有向图,成功将关键帧提取问题转化为最短路径求解问题。
构建有向图时,边(Si,Sj)存在连接的3个约束条件为:
1.4 最短路径求解
有向图构建后只要计算第1个顶点到最后一个顶点的最短路径,路径上的帧图片即选为关键帧。因为图中顶点是一个20帧图片的集合,所以选最短路径时顶点内可能会有2张帧图片被选择,本文认为顶点内帧图片是相似的,基于聚类结果此时只要选取隶属度高的帧图片即可。最短路径确保了最后生成的关键帧图片的独特性,具有很低的冗余度。
关于最短路径求解问题的算法有很多,对于本文的有向图来说,由于没有负权值且为单源的,可以采用Dijkstra算法。Dijkstra算法采用的是一种贪心的策略,声明一个数组dis来保存源点到各个顶点的最短距离和一个顶点的集合T保存已经找到的最短路径,其主要步骤如下:
(1) 初始时,源点S1的路径权重被赋为 0 (dis[S1]=0)。若对于顶点S1存在能直接到达的边(S1,Si),则把dis[Si]设为w(S1,S2),同时把所有其他(S1不能直接到达的)顶点的路径长度设为无穷大。初始时,集合T只有顶点S1,然后,从dis数组选择最小值,则该值就是源点S1到该值对应的顶点的最短路径,并且把该点加入到T中。
(2) 确认新加入的顶点是否可以到达其他顶点,并且通过该顶点到达其他点的路径长度是否比源点直接到达短,如果是,那么就替换这些顶点在dis中的值。
(3) 从更新后的dis中找出最小值,重复上述步骤,直到集合T中包含了图的所有顶点。
2 实验结果和评价
为了验证所提SPVS方法的有效性,在Open-Video数据集和 SumMe数据集上进行实验。Open-Video数据集是视频摘要算法使用的一个经典的数据集,采用其中的50个不同种类的视频进行测试,每个视频长度大约为2~5 min,同时该数据集对每个视频给出了由用户手工产生的摘要作为真值。SumMe数据集包含25个用户视频,即未编辑过的视频,内容有料理、运动等,每个视频长度在1.5~6.5 min之间。
视频摘要评价标准主要有主观评价和客观评价2种。主观评价即让用户对生成的视频摘要进行主观判断,如给生成的摘要打分决定摘要的好坏,是一种直观而且有效的方法。客观评价则是通过制定评价函数来评价视频摘要的好坏,比较普遍的评价函数有准确率(CUSA)和错误率(CUSE)。对于Open-Video数据集,由于有用户摘要作为对照,因此采用客观评价标准;对于SumMe数据集由于缺少真值将采用主观评价标准。
准确率为:
CUSA=NmAS/NUS
(6)
错误率为:
(7)
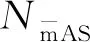
2.1 Open-Video数据集实验
对于Open-Video数据集,很多方法都曾证明了其有效性,本文将使用客观评价的方法分别与OV[17]、STIMO[5]、VSUMM[3]、FCM[4]、MST[11]5种方法进行对比,以证明所提SPVS算法的优良性能,具体的数据结果见表1所列。

表1 Open-Video数据集实验结果对比
由表1可知,在准确率方面SPVS算法仅略逊于VSUMM算法,比STIMO算法更是高出了25%,而在错误率方面,SPVS算法也有良好的表现,在几个算法中仅比STIMO高出1%。这说明SPVS算法能在保持低的错误率的同时仍能拥有较高的准确率,整体来说性能上优于其他几个算法。为了更直观地将本文所提的SPVS算法与其他算法进行对比,本文将SPVS算法与其他对比算法在2个视频上的摘要结果进行直观对比,如图2所示。

图2 第9个、第34个视频上视频摘要结果对比
2.2 SumMe数据集实验
对于SumMe数据集,本文采用主观评价来评价SPVS算法生成摘要的好坏,制定3个评价等级,分别为较差、普通、较好。20个声称经常浏览各种视频并对视频摘要有一定了解的志愿者参与了本次实验。为了结果更加直观且方便统计,使用数值L来表示算法生成摘要所获得的分数,即
L=x/y
(8)
其中:x为用户对所生成摘要评价为较好的个数;y为参与的志愿者的数量。实验结果见表2所列。
由表2可知,用户对于所提算法生成的摘要的评价主要集中在普通和较好等级上,且两者平均个数相差不大,较差的评价所占比例较小,较好的评价所占比例平均为30.6%,其中最高比例更是达到了85%,这表明了对于未编辑的用户视频,本文所提SPVS算法仍然具有相当不错的表现,进一步证明了SPVS算法的优越性。
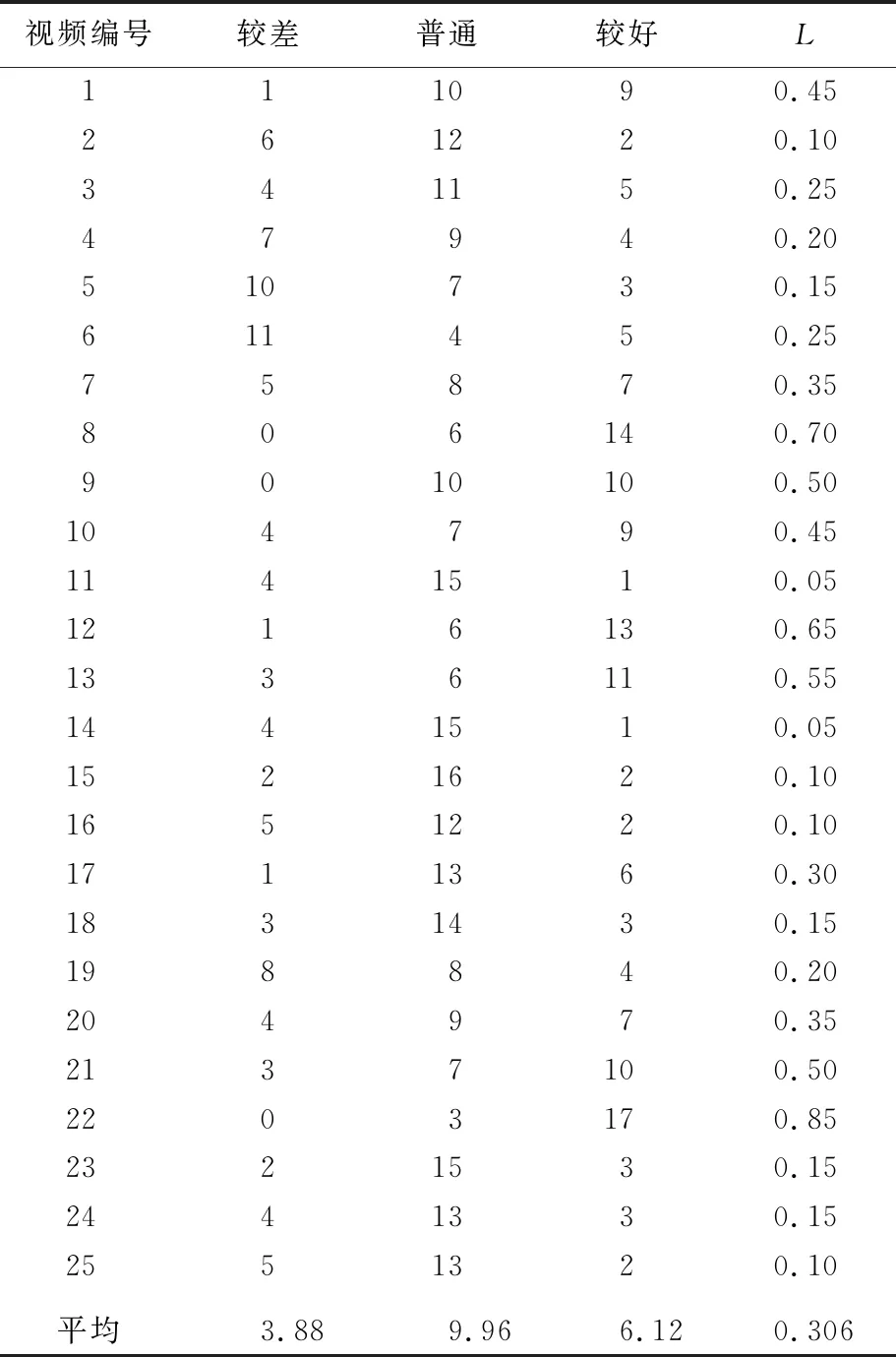
表2 SumMe数据集实验结果
3 结 论
本文通过将聚类方法和图模型的方法相结合并优化,提出了一种新的基于最短路径算法的静态视频摘要方法(SPVS)。SPVS方法将视频摘要的关键帧提取问题转化为有向图的最短路径求解问题,通过相似性度量找到的最短路径上的关键帧具有良好的代表性。在2个数据集上的大量主客观实验和与其他经典方法的对比也证明了所提方法的良好性能。
猜你喜欢
现代计算机(2022年4期)2022-04-24
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
导航定位与授时(2019年3期)2019-05-16
小学生学习指导(低年级)(2018年11期)2018-12-03
软件导刊(2018年4期)2018-05-15
中学生数理化(高中版.高一使用)(2018年1期)2018-02-10
电脑知识与技术(2017年3期)2017-03-27
理科考试研究·高中(2016年10期)2017-01-17
太空探索(2016年9期)2016-07-12
