
智慧图书馆图书分类模型技术研究综述
2021-03-14 06:12沈雅婷邵莹卞恺
电脑与电信 2021年12期
沈雅婷 邵莹 卞恺
(南京理工大学紫金学院计算机学院,江苏 南京 210023)
1 研究背景及意义
目前智慧图书馆的规模正在发展,库存量大,书品繁多,对于图书分类的管理就成了一个问题。智慧图书馆首先需要在图书分类方面能够有较高的准确度,才能确保其运行发展。图书分类的不准确不仅会影响读者的查阅,也会增加管理者工作的繁琐度。本文为方便图书管理员的操作,加快图书分类流通作业的速度,使其能更有效地管理书库中图书的分类,且在已有的图书名称分类的基础上完成新模式图书分类工作建设。该项研究的意义有如下两点:
(1)对数据集的采集:能够将大量的图书信息存储,并将信息格式统一化,使图书分类简单化。
(2)对要求的细化:及时全面地提供对分类过程中提出的不同分类要求的、不同分类细度的信息,以期实现图书快速分类。
2 主要研究成果
近年来对于图书分类系统的研究越发向着更深层次、更多维的方向发展,而图书分类算法也正在逐步完善,精确度、分类速度也在逐步提高。
2.1 基于集成学习的中文书目自动分类研究
该研究构建一个中文书目自动分类系统来实现高效分类,于2019年4月1日发表。该系统首先预处理输入数据,提取其特征后将其文本表示,最后运用集成学习算法进行分类[1]。系统的主要流程分为两个阶段,第一阶段为分类器训练阶段,第二阶段为书目分类阶段,中文书目自动分类系统的具体流程如图1所示。

图1 中文书目自动分类系统的具体流程
首先在中文书目预处理方面,在西安电子科技大学图书馆提供的数目数据和通过爬虫技术获取的数据中整理出的135493条有效数据进行数据清理和中文分词这两个步骤;特征提取是将表示书目的特征词提取出来作为空间向量的每个维度,对于此流程,介绍了TF-IDF法、词频方法等的常用特征提取方法;文本表示是在特征提取完成构建特征空间的基础上,将对应词的特征值作为向量中的每个元素赋值,形成文本的向量表示。在文本表示方面,该文对比了传统词袋模型中的词频模型和TF-IDF模型[2]、分布式表示方法中的Word2vec模型和GloVe模型在中文书目表示能力上的差异[3],通过实验发现分布式表示方法在书目表征能力上远胜于传统词袋模型[4]。传统词袋模型中的词频模型用以计算词出现的频率,TF-IDF模型即逆文档频率模型[5],表示这个词越稀有,也越关键。Word2vec是一种基于预测的模型,其可以不断提高预测准确性,减少预测误差,最终得到词向量。GloVe是一种基于统计的模型,是通过对词的共现计数矩阵进行降维[6],来得到词向量,首先通过输入的所有语句资料建立大规模的共现计数矩阵,不仅能优化目标,还能减少共现计数矩阵重建的误差,使降维后的向量尽可能全面表达原始向量表示的语句资料,对于Word2vec无法解决的多义词问题有所克服。最后提出了一种将Word2vec和GloVe的不同表示特点结合起来的分布式混合表示模型,获得了最好的书目表征能力。在分类算法选择方面,引入集成学习算法Bagging框架,在集成学习Bagging框架下,反向传播神经网络算法的分类准确率最终达到90.19%,在智慧图书馆的中文书目自动分类工作中能够发挥作用,为图书名称分类问题提供了新的解决方法。
2.2 基于双向LSTM的图书分类系统的设计与实现
该设计模型在2020年1月17日发表,构建了一种处理中文图书分类的双向LSTM模型,即双向长短时记忆循环神经网络,可以解决循环网络RNN长期依赖的问题,使其能记住长期的信息,也能由前后若干输入进行双向准确预测。该系统录入书籍信息后识别信息特征,最后进入分类管理模块。其主要创新是用双向LSTM模型对字符向量进行编码的方式,实现中文分类的简单化,还降低了向量的维度与规模[7-10]。
基于双向LSTM的图书分类系统的基本流程如图2所示。

图2 基于双向LSTM的图书分类系统的基本流程
LSTM模型包含输入门、遗忘门和输出门这三种门限,此研究所设计与实现的图书分类系统以双向LSTM模型为基础[11],引入较为经典的神经网络模型层次结构,在其应用下,输入图书文本信息可以将文本信息编码化。同时改进分类模型嵌入层,采用基于字符的向量化表示方法,避免了分层困难,提高了分类精确度。模型的输出层上为输出隐藏层得到的信息分类,使用到softmax激活函数,同时树立以softmax回归模型为基础的代价函数当作优化的目标。softmax回归模型可实现优化逻辑回归目标,适用于具有多分类任务的分类模型中[12]。如果在图书的分类中共有n种分类类别,则每次输入都将对其进行所属类别的概率计算。计算过程中使用归一化运算计算概率,即书籍所属于某种类别的概率之和始终计算为1[13]。为了方便对分类模型效率不同方面的考察,将图书分类任务划分成两种,一种是粗粒度分类,一种是细粒度分类。根据项目模块划分的详细程度,模块划分越细致,分类种类越多,则粒度越细,相反粒度越粗[14]。该文的粗粒度分类目标是中图法的22个一级分类任务,细粒度分类目标为32个四级分类。该双向LSTM分类模型在大量的训练后准确率有大幅度提升,其中在149轮训练后,粗粒度分类任务准确度达到90.6%,在120轮训练后细粒度分类任务准确度达到98.3%。
2.3 基于向量空模型的数字图书信息分类系统设计
该设计是近年来最新的研究进展发现,于2021年5月12日发表。该设计硬件部分选用MPC755的处理器作为图书信息处理核心,设计一个CPU板卡,为了满足硬件数据冗余信息的输出,连接一个输出电路[15]。软件部分利用向量空模型构建信息分类规则,向量空间模型可以将对文本文件的处理简化为对标识符向量的运算[16],主要运用在信息过滤、信息检索、索引以及相关排序过程中[17]。在利用向量空间模型构成信息分类规则时,转化数字图书信息为空间向量[18],转化过程中,箭头的起始点为数字图书信息所在的文件,在向量空间模型的处理下,参照不同的数据特征,形成了不同的方向[19],以一个方向为分类类别。以相同分类规则下的图书信息样本为实现对象[20],构建一个停用信息过滤模块,将停用信息筛选出后,利用软件线程池的Link List链表作为线程分类任务[21],在Thread Pool接口处形成如图3所示的分类过程。

图3 分类功能实现
在图3所示的分配过程下,左边的运行链组抽取MTQueue中的数字图书信息进行处理,通过invoke Later(·)输出一个数字图书信息的对应的类别[22],最终完成对基于向量空模型的数字图书信息分类系统的设计。
在此实现模型中,使用到数字图书分类。数字图书馆使用数字技术存储信息,用户可以用其查询不同位置、不同载体的信息资源[23]。而将向量空间模型运用到数字图书信息分类系统中,在其控制下,能为不断优化的数字图书馆各项性能提供帮助。该文在实验测试环节对比了一种基于LSTM和CNN混合模型的文本分类方法[24]、传统信息分类系统以及文中设计的基于空向量模型的分类系统的性能。实验表明,第一种分类准确率约为77.91%,传统分类系统准确率数值约为87.58%,而该文设计的分类系统分类准确率约为97.76%,准确率最高[25];在300条数字图书信息为对比标准,第一种信息分类系统所需时间在140ms左右,传统信息分类所需分类时间在180ms左右,而文中的基于空向量模型的分类系统所需时间在90ms左右,所需分类时间最短[26]。三种分类系统的分类时间如图4所示。
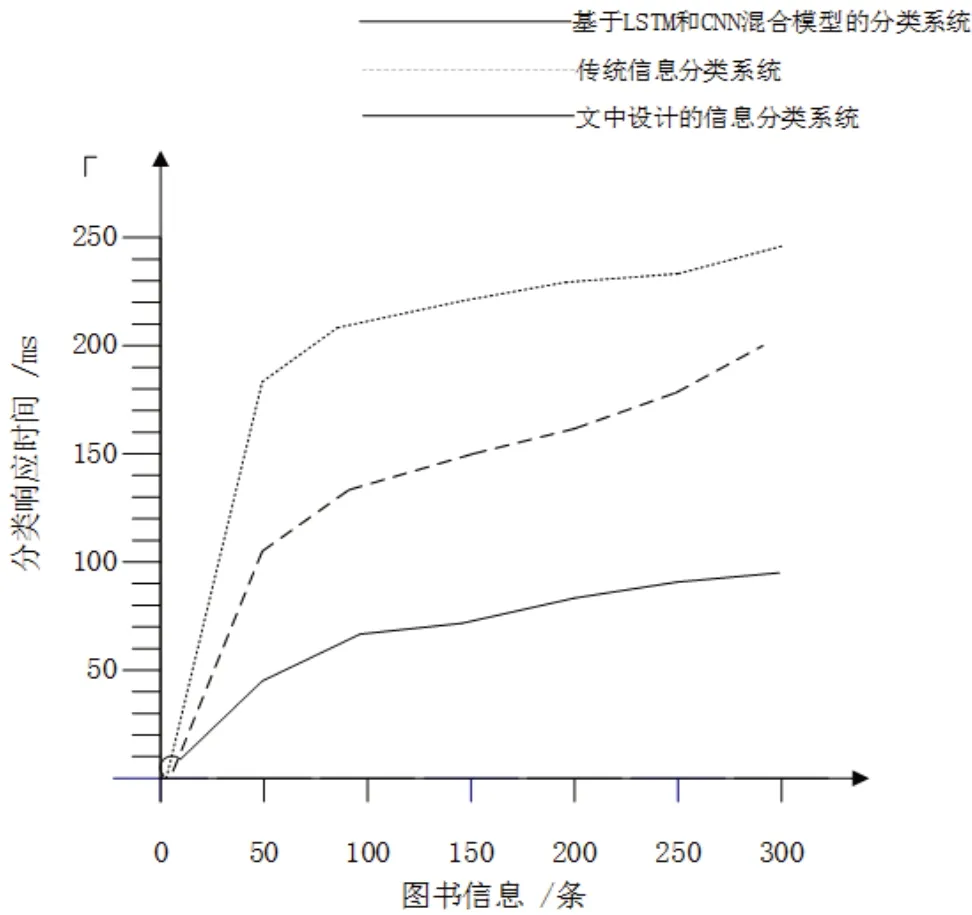
图4 三种分类系统的分类时间
3 研究分析
基于以上几种图书分类的系统设计,可以看出这一领域的研究在算法方面不断发展,出现如本文提到的集成学习、双向LSTM模型、向量空模型等的新式算法应用,这些研究正不断向更深处探索,算法也在向更多维方向升级。
对于上文介绍的三种分类算法,表1是它们处于同一数据集下的分类准确率比较。

表1 三种分类算法比较
基于集成学习的中文书目自动分类研究,运用到集成学习这种具有极高分类准确率的算法框架,相较于前人构建的书目自动分类,本项研究做出了文本表示和分类算法选择两个角度的进步,极大地提高了准确率。但是这项研究局限于中文书目,如果扩大范围,将外文书籍纳入分类体系中,也不失为一种突破。
基于双向LSTM的图书分类系统的设计与实现,通过新的算法模型,将分类准确度提高到一个新的高度97.88%。该图书分类系统通过动态配置和分类管理器,可以提高图书管理人员工作的效率,提升其分类准确度,提高系统的适应性和应用范围,对智慧图书馆的数字化平台建设起到促进作用。
最后一种图书分类系统在向量空模型的加持下,它的分类准确率为96.02%,同时所用时间大大缩短,如此的高效率分类,是图书分类的一大进步。
在相同数据集上测试,后两者分类模型的准确率相近,它们相较于第一种模型的准确率高出约2%~8%,其中基于向量空模型的分类模型用时短;而基于双向LSTM的分类模型的准确率有提升空间,会随训练次数的增加而逐步上升,但所耗时间也会增加。当然两者对于图书馆的数字化平台建设都有极大的帮助,有很大的现代化意义。众所周知,现在的社会是数字化的,数字化管理也将是主流趋势。随着数字图书馆不断的普及利用,如何对数字图书信息进行分类逐渐成为研究重点,上文的算法有利于其发展。但是上述测试数据量为300条,数据量较小,对于在更多数据量上的效果有待深层次的研究。可以看出,对于不同分类算法的研究,有机会对分类的准确度、速度实现突破。
4 结语
本文概括并研究分析了近年来几种图书分类系统的设计突破,这几种研究都在图书名称分类方面分别做出了不同的贡献,成功提高了分类系统的分类准确度,对后期智慧图书馆图书名称分类模型的研究起着不可忽视的启示作用,学者们可以根据需要选择使用上述算法模型,对于不同分类算法的研究,有机会对分类的准确度、速度实现突破。
猜你喜欢
今传媒(2022年12期)2022-12-22
都市人(2022年3期)2022-04-27
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中文信息(2021年6期)2021-03-27
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
办公室业务(2015年6期)2015-11-26
中国民间疗法(2012年1期)2012-07-27
全国新书目(2009年1期)2009-04-13
