
基于时频域特征与DPRNN的语音增强方法
2021-03-14 00:50张禧辰李云海朱文辉陈静静
现代计算机 2021年36期
张禧辰,李云海,朱文辉,陈静静
(1.江苏大学卓越学院,镇江 212000;2.江苏大学计算机科学与通信工程学院,镇江 212000)
0 引言
语音增强旨在解决噪声对语音的干扰问题,是语音信号处理中的重要前端技术之一。截至目前,语音增强技术已经在各领域中占据十分重要的地位,例如Google智能音箱的语音唤醒,该功能就需要利用语音增强技术滤除环境中的噪声,以提高语音唤醒的成功率。总的来说,语音增强方法可以分为单通道语音增强方法和多通道语音增强方法,其划分的主要标准是根据麦克风的数量不同。单通道语音增强方法接收单麦克风信号,主要从信号本身的声学和统计特性等角度出发进行增强;多通道语音增强方法则接收麦克风阵列的信号,可以利用麦克风阵列之间的空间信息。相比于多通道语音增强方法,单通道语音增强方法缺少空间信息,更具挑战性,但具备便捷、成本低的特点。因此,本文针对单通道语音增强问题提出了基于时频域特征与DPRNN(dual-path recurrent neural network,双路循环神经网络)的语音增强方法。
传统的单通道语音增强方法有谱减法[1-2]、维纳滤波法[3]等。谱减法是在带噪语音中预测出噪声信号,将带噪语音与预测出的噪声信号在功率谱(或幅度谱)上直接进行相减,从而得到增强语音的一种语音增强方法。谱减法假设混合信号是由纯净信号与平稳的噪声信号叠加形成,不能有效处理随机干扰信号,实际应用场景十分受限。维纳滤波法则是将带噪语音经过线性滤波器后得到次优语音,并求得次优语音与纯净语音均方误差最小时的最优滤波器参数,再根据该滤波器参数处理得到最优的增强语音。维纳滤波法能够有效处理语音中的平稳噪声,但很难抑制语音信号中的不规则信号。
近年来,随着深度学习在各个领域中取得成功,越来越多的研究者提出了深度学习方法在语音增强上的应用,克服了传统语音增强方法很难抑制随机干扰信号的局限性。总体上,语音增强领域中的深度学习方法可分为两大类:一类是端到端的时域方法,另一类是时频域方法。时域方法中,常见的设置是利用一维卷积神经网络作为编码-解码器。例如,2019 年Ashutosh Pandey 等人提出的一种在时域上基于CNN 的语音增强架构[4],该方法就是利用1-D CNN 作为语音序列输入的编码-解码器。然而,当1-D CNN 的感受野大小设置不合理时,会在一定程度上忽略相隔较远的语句关系,从而影响语音增强的效果。而在时频域方法中,通常使用STFT(short-time Fourier transform,短时傅里叶变换)提取输入语音的时频域特征,再对时频域特征进行时序建模处理,最后通过对时频域特征进行ISTFT(inverse shorttime Fourier transform,短时逆傅里叶变换)得到增强语音。但是,当语音的时频域特征序列较长时,系统将会很难对其进行有效建模。
本文针对语音的时频域特征长度较长时所带来的难以有效建模的弊端,并受到Yi Luo 等人在2019 年提出的DPRNN-TasNet[5-6](dual-path recur⁃rent neural network time-domain audio separation network, 双路循环神经网络-时域语音分离网络)模型的启发,提出了基于时频域特征与DPRNN的语音增强方法。这一方法使用STFT提取语音时频域特征,再将语音特征送入双路循环神经网络中进行建模,最后将逆傅里叶变换进行语音重建。在VBD 数据集上得到的实验结果表明,该方法能够显著提高语音质量并且有效消除了低频段噪声,PESQ(perceptual evaluation of speech qual⁃ity,客观语音质量评价)指标达到了2.43。
1 基于时频域特征与DPRNN的语音增强方法
本文针对语音时频域特征较长所带来的难以有效建模的问题,提出了基于时频域特征与DPRNN 的语音增强方法,该方法首先利用短时傅里叶变换进行语音的特征提取,然后加入DPRNN层使模型捕获上下文语音特征之间的关系,并将该方法应用到语音增强的领域,如图1 所示。与语音分离任务不同,语音增强过程中会遇到各种带噪语音,其中大部分噪声的频率与人声频率差距较大。我们引入的STFT语音特征提取过程能够利用这一特点,对这类带噪语音提取出与纯净语音特征差别较大的时频域特征。同时,由于纯净语音与带噪语音的时频域特征差距较大,DPRNN更容易捕获带噪语音与纯净语音之间的区别,从而完成语音增强任务。这也是我们将DPRNN 利用在语音增强领域的一大优势。

图1 基于时频域特征与DPRNN的语音增强方法流程
1.1 语音的特征提取
特征提取如图1(A)所示。在特征提取前,首先需要对语音进行采样,我们使用16 kHZ的采样率对wav格式语音进行采样得到一维的语音数据。在特征提取过程中,我们采用短时傅里叶变换,具体过程为将语音序列分割成固定大小且具有重叠部分的语音片段,对这些语音片段即各帧进行函数处理,完成逐帧加窗,再对各帧进行傅里叶变换,提取出时频域特征。在此我们使用汉明窗对各帧进行加窗处理(窗口大小为256 ms,帧移为64 ms),利用汉明窗可以突出帧的中心数据特征,当帧移取值合适时,利用汉明窗可以突出全部语音数据并将它们分隔在不同的帧中。汉明窗函数如式(1)所示:
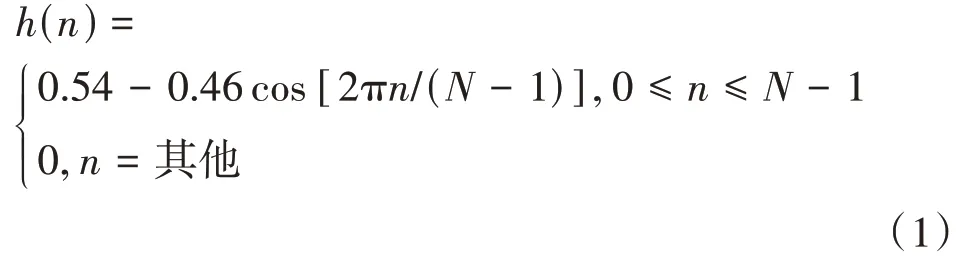
分帧加窗后,对各帧进行傅里叶变换,即下式:
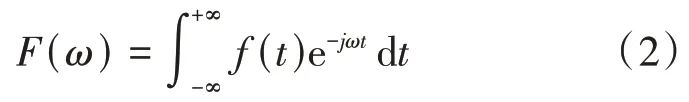
f(x)是将要变换的语音信号,由于在计算机中处理的语音数据是由各采样点得到的离散信号,所以我们要对语音数据采用离散傅里叶变换进行特征提取,即:
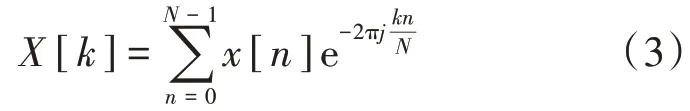
最终我们将一维的语音数据转化为二维时频域上的频率-振幅语音特征。
在特征提取过程中,我们计算出语音特征的幅值与相位。但由于相位缺少明显的结构化信息,难以建模,因此我们忽略了语音相位对语音增强算法的影响,只对幅值进行处理。此外,我们对语音的相位进行保存记录,以便在最后的语音重建中,将增强后的幅值与原相位进行处理完成语音重建。
1.2 DPRNN模型结构
DPRNN 由Yi Luo,Zhuo Chen 等人在2019 年提出,他们考虑到了一维卷积神经网络(one di⁃mensional convolution neural network,1-D CNN)的感受野小于语音序列长度时将会无法执行超长的全局建模,所以提出了能够捕获跨度更大的语言关系的DPRNN 模型。这是一种简单而又有效的方法,用于在深层结构中组织RNN 层对极长的序列进行建模,DPRNN 将长序列输入分割成更小的块,并迭代地应用块内建模和块间建模,其中输入长度可以与每个操作中原始序列长度的平方根成正比。通过块内和块间操作能够使模型在多个维度上进行训练,优于普通的LSTM(long shortterm memory,长短期记忆网络)结构。
DPRNN 具体结构由输入序列的分割处理、DPRNN 块的内部操作、序列片段的重叠相加三部分组成。即如图1 中的(B)、(C)、(D)三部分所示。
1.2.1 序列输入的分割
在图1中(B)过程序列分割中,假设输入序列的宽度为N,长度为L。模型将该序列在长度维度上进行分割,具体过程如图2所示。
在图2 中所采用的片段大小为2P,片段与片段之间具有重叠部分,图示中所采用的重叠率为50%,其分割出的片段数量取决于序列输入的长度,当序列输入的最后部分不满足分段大小2P时,将进行补零以达到2P的大小。最终,将分割出的S个长度为2P,宽度为N的片段组合成一个三维张量,这个张量的两个维度保持原片段的宽度N及长度L,而第三个维度的大小即为分割出片段的数量S,这一部分将根据输入序列的变化而变化。
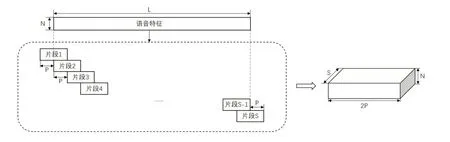
图2 序列输入分割图
1.2.2 DPRNN的内部操作
DPRNN 的第二部分即为DPRNN 的内部操作,如图1(C)所示。这一部分的输入是图1(B)过程输出的三维张量。它主要分为两个部分,一是三维张量的块内建模过程;二是三维张量的块间建模过程。其中图1 中(B)部分所示的Bi-RNN(bi⁃directional recurrent neural network,双向神经网络)具体采用的是BiLSTM(bidirectional long shortterm memory neural network,双向长短期记忆网络), 在Bi-RNN 后连接一个全连接层,再对全连接层的输出进行归一化处理,这里我们使用LN(layer normalization,层标准化)归一化。在块内建模时,将三维张量在维度大小为S的片段数量维度上分割成S个宽度为N,长度为L的二维张量,这些二维张量即为BiLSTM 的输入序列,这一步能够让模型捕获到紧密连接的上下文的语句关系。在进行块间建模时,将三维张量在大小为2P的维度上分割成2P个宽度为N、长度为S的二维张量,这些二维张量即为第二个BLSTM 的输入序列,这一步能够让模型捕获在时间上跨度更大的语句关系。最终,在LN 操作的输出和下一过程的输入之间添加剩余连接。
1.2.3 片段的重叠相加
第三部分是重叠相加生成掩膜值,如图1(D)所示。由于在(B)中对序列输入进行分段时片段与片段之间具有重叠部分,因此在该过程的重叠相加操作中,不能简单地直接在2P维度上进行拼接,而是要使各片段重叠部分为50%的重叠相加。此外,在具体的操作中,还要去除第一个片段的前P长度部分与第S个片段的后P长度部分以保证生成的掩膜值维度与序列输入的维度完全相等。
1.2.4 DPRNN的总体操作流程
整体DPRNN的处理过程如下列各式所示:
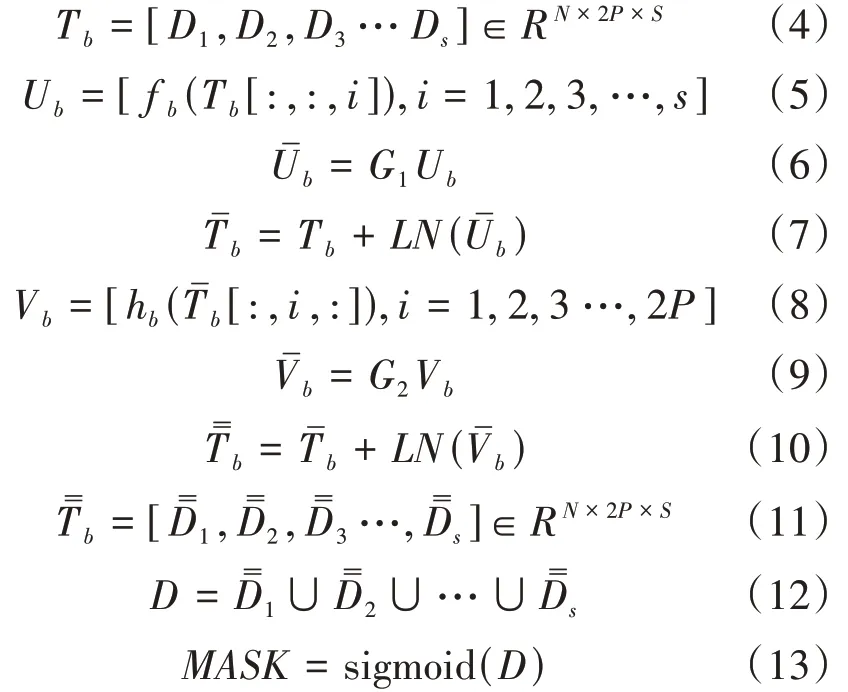
在公式中,Tb是语音特征分割后所得到的三维张量;D1,D2,D3,…,Ds是分割所得到的S个片段;f b、hb代表块内与块间流程中的RNN 处理,f b代表在第三维度即S上进行的RNN 处理,hb代表在第二维度即2P上进行的RNN 处理;G1、G2指Bi-RNN层后的全连接层;LN代指LN归一化处理;指块内处理与块间处理后所得结果,即经过DPRNN内部操作后所得结果;是处理后的S个片段;D指重叠相加后所得到的与语音特征维度相同的数据,D经过sigmoid函数映射后得到掩膜值MASK。
1.3 重建语音
重建语音的具体操作如图1(E)过程所示。在图2 中,我们将DPRNN 输出的掩膜值对所提取的语音特征进行加权,得到了增强后的语音特征。由于我们使用的是傅里叶变换进行语音的特征提取,所以将语音特征(时频域)返回成语音序列(时域)要进行逆傅里叶变换,即下式:
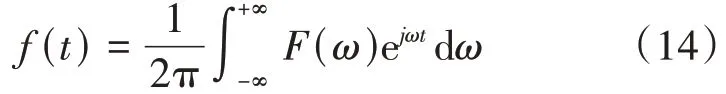
由于在计算机中所要处理的是离散信号,所以要进行离散逆傅里叶变换,即:
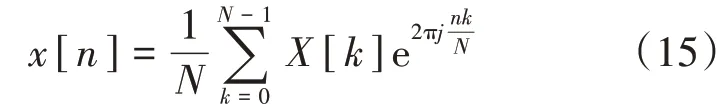
进行离散逆傅里叶变换后即得到语音序列,完成语音重建。
2 实验
2.1 数据集与实验设置
实验中选取VBD(Voice Bank + DEMAND)[7-9]作为实验数据集,VBD 数据集内有训练集与测试集两部分,训练集中有11572 组音频文件,测试集中有824组文件(一组音频文件由带噪语音和配对的纯净语音组合而成),我们从训练集中提取了300组文件作为验证集。
VBD 语音数据集与我们的实验数据需求十分契合。数据集中的每个纯净语音文件都包含一个句子,这些句子是在安静的录音棚条件下由多位演讲者录制得到,制作者将一系列噪声添加到这些语音中从而构成了噪声数据集。这些文件均为wav 格式文件,录制时的采样频率为48 kHZ,但为了减小数据规模,我们在具体的实验过程中将采样频率降低到了16 kHZ。
在训练过程中,我们选择的初始学习率为0.001,每训练2 代,学习率衰减为之前的0.98倍。即:

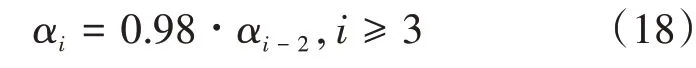
式中,αi指训练到第i代时的学习率。
2.2 损失函数
在本实验中,我们选取了MSE(mean square error,均方误差)函数作为实验中的损失函数,其公式如下所示:
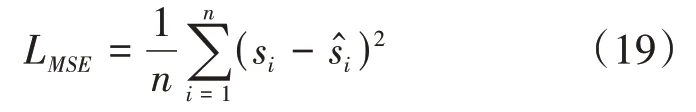
在LMSE公式中,si指数据集中的纯净语音,ŝi指经过增强处理后的语音,n代表数据集中的所有语音文件个数。
另外,我们在实验中分别测试了另外两个损失函数:PCMSE 函数[10-12]与SNR 函数。但我们在实验中发现,如果以PCMSE函数或SNR函数作为模型的损失函数,loss 值会在一个常数值上下小范围的波动,没有明显的下降趋势。而以MSE 函数作为模型的损失函数,则对模型的训练效果十分显著,各周期的loss 值有明显的下降趋势并且最终将会趋于一常数值。因此在最终的模型构造中,我们采取了效果更好的MSE函数作为我们的损失函数。
2.3 评价指标
为了评估模型的性能,我们采用了以下4 个评价指标:
(1)PESQ。客观语音质量评估,由国际电信联盟电信标准化部门(international telecommunica⁃tion union communication standardization sector,ITU-T)P.862 建议书提供,得分在[-0.5,4.5]区间内。
(2)CBAK。背景噪声侵入的平均意见得分预测,得分在[1,5]区间内。
(3)CSIG。仅与语音信号有关的信号失真的平均意见得分预测,得分在[1,5]区间内。
(4)COVL。整体语音质量的平均意见得分预测,得分在[1,5]区间内。
以上四个语音指标中,第一个语音指标PESQ 与语音的客观质量相关[13],后三个指标与语音的主观质量相关[14],并且均是在数值大的情况下说明语音的质量越高。
3 实验结果比较与分析
通过不同模型处理后的语音的各项指标如表1 所示。表中各结果均是基于VBD 数据集所得到的,并且,各类模型的指标值均为各模型提出者所给出的最优值。表中NOISY 一栏下各结果指的是未经处理的测试集中带噪语音的初始各项指标值,WIENER 是指传统的维纳滤波法,SEGAN 是生成对抗网络在语音增强上的应用[15],OPENUNMIX是一个开源模型[10,16-17]。在表中不难发现,在四项指标中,我们所提出的语音增强方法仅在CBAK 中略逊于Open-unmix 模型,而在PESQ、CSIG、COVL 三项指标上分别达到了2.43、3.74、3.11,均超过其他方法。

表1 各模型评价指标对比
为了更加清晰地展示我们所提出的方法对语音增强的效果,我们从VBD 的测试集中选取了p232_001.wav文件,绘制了它的纯净语音频谱图、带噪语音频谱图以及增强语音频谱图,即图3。从图中可以清晰地看出,我们所提出的方法去除了大部分低频的噪声,增强后的语音十分接近纯净语音。此外,在语音的播放时,人耳能够清晰感受到语音中的噪声部分在很大程度上被削弱,例如在原始的带噪语音中,语音中有明显的汽车鸣笛声、键盘敲击声、多个人的说话声音等,经过我们的方法处理后,在很大程度上减弱了这些噪声。
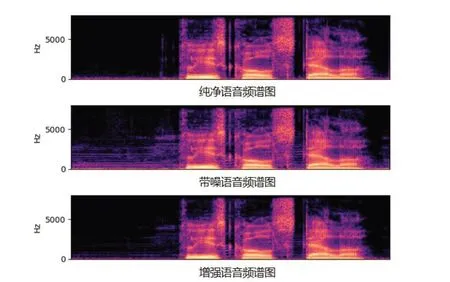
图3 纯净语音、带噪语音与增强语音的频谱图对比
4 结语
我们所提出的基于时频域特征与DPRNN 的语音增强方法,使用短时傅里叶变换对语音进行处理,提取出输入语音的时频域特征,再使用DPRNN 模型在语音的时频域特征上进行处理,让模型能够捕获到语音上下文之间的关联性,最终通过短时逆傅里叶变换进行语音重建,完成了去除带噪语音中大部分噪声的语音增强任务。在VBD 数据集上得到的实验结果表明,该方法能够显著提高语音质量并且有效消除了低频段噪声,PESQ(perceptual evaluation of speech quality,客观语音质量评价)指标达到了2.43。
在接下来的工作中,我们将会继续探究不同的损失函数对于模型效果的影响以及PCMSE 函数与SNR 函数不适用的原因。此外,在与抗噪声干扰有关的CBAK 指标上,我们所提出的方法得分并不高,因此在未来的工作中我们也会在抗噪声干扰这一方面继续研究,继续探索出能够提高增强语音抗噪声干扰能力的有效方法。
猜你喜欢
电脑报(2022年24期)2022-07-01
数理化解题研究·综合版(2021年11期)2021-12-22
小学教学研究(2021年5期)2021-09-29
课程教育研究(2021年27期)2021-04-13
舰船科学技术(2021年12期)2021-03-29
初中生世界·九年级(2020年2期)2020-04-10
振动工程学报(2019年2期)2019-05-13
物联网技术(2016年11期)2017-01-12
科学与财富(2016年18期)2016-12-22
饮食科学(2016年7期)2016-07-27
