
面向OLAP数据库查询处理功能的模糊测试工具
2021-03-14 19:07项兆坤陈婷苏仟张蓉
华东师范大学学报(自然科学版) 2021年5期
项兆坤 陈婷 苏仟 张蓉

摘要:查询处理是现代关系型数据库管理系统(DBMS)中最重要的功能之一,主要包括查询优化和查询 执行.然而查询处理的复杂性导致了测试的高成本,阻碍了开发过程中的快速迭代,并可能在生产环境中 导致严重错误.为了更好地服务于DBMS查询处理功能的评测,采用模糊测试的方法生成基于主键约束的 随机数据和完全有效的复杂分析型查询;构建约束优化,对查询中算子的精确基数进行高效计算,从而获 得查询的正确结果;最后实现了完整的工具.通过对TiDB的不同版本进行了小规模的测试,结果表明可 以有效地检测出TiDB不同版本的一些Bug.
关键词:分析型数据库;查询处理;查询执行;查询优化器;模糊测试
中图分类号:TP392 文献标志码:A DOI: 10.3969/j.issn.1000-5641.2021.05.007
A fuzzer for query processing functionality of OLAP databases
XIANG Zhaokun1, CHEN Ting1, SU Qian2, ZHANG Rong1
(1. School of Data Science and Engineering, East China Normal University, Shanghai 200062, China;
2. China Industrial Control Systems Cyber Emergency Response Team, Beijmg 100040, China)
Abstract: Query processing, including optimization and execution, is one of the most critical functionalities of modern relational database management systems (DBMS). The complexity of query processing functionalities, however, leads to high testing costs. It hinders rapid iterations during the development process and can lead to severe errors when deployed in production environments. In this paper, we propose a tool to better serve the testing and evaluation of DBMS query processing functionalities; the tool uses a fuzzing approach to generate random data that is highly associated with primary keys and generates valid complex analytical queries. The tool constructs constrained optimization problems to efficiently compute the exact cardinalities of operators in queries and furnish the results. We launched small-scale testing of our method on different versions of TiDB and demonstrated that the tool can effectively detect bugs in different versions of TiDB.
Keywords: OLAP database; query processing; query execution; exact cardinality; fuzzing
0引 言
分析型數据库管理系统(Database Management System, DBMS)主要用于处理复杂的查询,艮口 OLAP负载,被广泛应用于金融科技、商业智能等领域,查询处理[1]是分析型数据库中最重要的功能
收稿日期:2021-08-04
基金项目:国家自然科学基金(62072179); 2020年关键软件适配验证中心项目
通信作者:张蓉,女,教授,博士生导师,研究方向为分布式数据管理.E-mail: rzhang@dase.ecnu.edu.cn
之一.这些分析型SQL语句大多包含多表连接、聚集运算等操作,帮助分析师完成复杂的分析处理任务.
对于分析型数据库来说,一个复杂的SQL语句查询要经历查询解析(Parser)、查询优化(Query Optimization)和查询执行(Query Execution).在查询解析阶段,解析器会对SQL语句进行语法检查 (Syntactic Check)和语义检查(Semantic Check),如果SQL语句有语法或者语义错误,DBMS会直接 返回错误信息,不会进入查询优化和执行阶段.通过查询解析阶段,SQL语句会被转换为初始的逻辑 查询计划,接着会经过查询优化将初始的逻辑查询计划优化为代价较低的等价查询执行计划.然后将 该执行计划交给查询执行器去执行,最终得到SQL的执行结果.
查询优化问题已经被研究了 40余年,是计算机领域的NP难问题之一[2].查询优化器目的是选出 一个比较好的查询执行计划交给执行器去执行,几乎所有的现代数据库系统使用的都是基于成本的 优化器(Cost-Based Optimizer),使用枚举算法(Enumeration Algorithm)在计划搜索空间中搜索执行 计划,同时使用代价模型(Cost Model)预估执行计划的代价,最终选择代价最低的执行计划[3].在代价 模型中最重要的因素是查询中算子的中间结果集大小,简称基数(Cardinality),基数预估的误差是造 成优化器无法选出合适的执行计划的因素之一[4],所以使用某种方法快速获得精确的基数能使查询优 化器的效果获得很大的提升.
模糊测试(Fuzzing)是一种软件测试技术,被广泛运用于检查软件系统的漏洞模糊器(Fuzzer) 是指实施模糊测试的工具.模糊测试分为基于突变的模糊测试和基于生成的模糊测试.基于突变的模 糊测试依赖于对测试输入的变异来构造新的测试输入,基于生成的模糊测试依赖于一个给定的输入 模型来生成测试输入[6].
数据库系统在快速迭代开发阶段进行充分的测试是很有必要的,能够提前发现问题,避免上线后 产生错误.针对数据库系统的模糊测试工具不同于通用的模糊测试工具,由于数据库系统的输入为高 度结构化的SQL语句,有着严格的语法格式和语义格式,不同的SQL关键字的组合可以抵达不同的 代码逻辑,所以需要设计特别的测试工具.服务于DBMS的基于生成的模糊器根据预先设计的 SQL生成模型生成SQL,而服务于DBMS的基于突变的模糊器主要对SQL语句进行突变来产生新 的SQL.目前已经有很多针对数据库功能的模糊测试工具[7-12]和数据库性能回归诊断的模糊测试 工具[13]. —些传统的模糊器[14-15]以及负载生成工具[16]也可以生成复杂度高的SQL语句,它们有的生成 的SQL语句不能保证语法正确性,有的虽然保证了语法正确性,但是无法保证语义正确性,这些 SQL语句无法通过数据库查询处理的解析器,不能抵达更深的代码逻辑.RAGS[7]保证了语义的正确 性但是有50%左右的SQL执行为NULL,这些SQL也不能很好地对数据库系统进行测试.总体来说, 现有的一些模糊测试工具要么无法保证负载语法正确性和语义正确性[14-15,17-18],要么大量的负载执行 结果为NULL[7],而且一些工具[8,11]需要去使用权威数据库作为结果参照.另外,当前的一些针对查询 优化器的测试工具[19-20]都无法保证测试方法能触及优化器的核心——基数,已有的一些精确基数获取 的工作[21-23]都是通过使用数据库执行额外的负载获取查询中所有算子的精确基数,会造成很大的开销.
针对DBMS查询处理功能的模糊测试工具应该提供测试数据生成器、测试负载生成器以及结果 验证器.那么,如何更好地生成测试所需要数据,如何生成更有效的负载以检测数据库系统内核代码 逻辑,以及如何高效地进行结果验证,是开发面向数据库系统的模糊测试工具所要着重考虑的难点问 题.本文提出一款面向OLAP数据库查询处理功能的模糊测试工具,采用基于主键的关联数据生成、 避免NULL值的负载生成、构建约束优化问题进行算子基数及查询结果计算,实现更加有效的分析型 数据库查询处理功能的正确性测试,可服务于面向金融应用的数据库系统的评测.
1相关工作
模糊测试是生成输入到软件系统以发现漏洞,是一种传统的漏洞发现方法.在数据库系统的评测中,生成数据、生成负载都是服务于DBMS的模糊测试工具要考虑的重要环节.
在传统的负载生成工具中,微软开发的RAGS[7]是比较有代表性的工作.它根据已有的数据库 Schema信息,参照标准的SQL语法随机生成大量语法正确的SQL语句,将这些SQL在不同的数据 库上执行并利用对比库进行结果验证,即使用差异测试的方法来测试SQL Server版本迭代中出现的 Bug.但是RGAS生成的负载大约有50%的查询的执行结果为空,造成了测试资源很大的浪费.同时 RGAS使用的差异测试方法需要数据和负载在不同的数据库上去执行,不同数据库的语法可能还不 兼容,是一种耗时耗力的方法.
文献[16]中介绍了微软提出的一个基于突变的负载生成工具,主要通过增减关键字来对已有的 SQL语句进行突变,能保证语法的正确性,但是无法保证语义的正确性.
目前,有一些通用模糊测试工具支持生成结构化的SQL.但文献[14]提出的工具生成的SQL 大多数语法不正确,AFL(American Fuzzy Lop)|15]生成的SQL语句中只有30%语法正确,其中语义正 确的SQL比例不到5%.这些通用型模糊测试工具无法很好地对数据库进行测试.故后续出现了专门 针对数据库系统的模糊测试工具,比如SQLSmith、SQLFuzz、SQLancer、SQUIRREL、SparkFuzz、 MutaSQL 等.
SQLSmith[8]是基于生成的模糊测试工具,基于给定的数据库模式(Schema)随机生成大量语法正 确的SQL,用于发现DBMS的系统崩溃问题(Crash),但是它无法保证生成SQL的语义正确,同时也 不包含查询结果的正确性验证模块.SQLFuzz[13]是数据库系统性能回归测试工具APOLLO中的一部 分,通过随机生成SQL在数据库的不同版本上执行以检测数据库系统的性能回退.SQLancer[9]是主要 用于检测数据库系统逻辑Bug的模糊测试工具,其中的PQS(Pivoted Query Synthesis)测试方法通过 选择表中的一行作为Pivot Row,然后去构造一定可以包含该行的查询,如果数据库执行该查询后结 果中没有出现预设的Pivot Row,则表明数据库实现有Bug.但是,PQS在测试Left Join、Group By等关键字时存在缺陷,同时无法验证查询中间结果集大小,不支持测试聚集运算.8卩。1只只瓦^12]通 过保留语法的突变来提高生成SQL的语法正确性,使用语义指导的查询参数实例化算法来提高生成 SQL的语义正确性,发现了许多数据库中内存相关的Bug. SparkFuzz[11]通过随机生成数据和负载,以 测试SparkSQL的查询执行引擎Bug,但是它分別在PostgreSQL和SparkSQL上执行生成的负载,耗 时耗力.MutaSQL[10]使用基于突变的方法将SQL改写成结果等价但形式不同的其他SQL,如果两个 SQL执行结果不同,表明数据库存在Bug.但是MutaSQL的缺点是需要将SQL在数据库上执行才能 知道结果.
综上所述,由于SQL的高度结构化,需要保证语法语义的严格正确性才能对数据库进行测试,通 用的模糊测试工具[14—15,17—181无法对数据库系统进行很好的测试;一部分负载生成工具[7,16]生成的负载质 量需要提升;针对数据库的模糊测试工具[8,,10-11]需要在真实数据库上执行生成的SQL才能获得查询的 基准结果,测试代价太高.
2系统整体架构
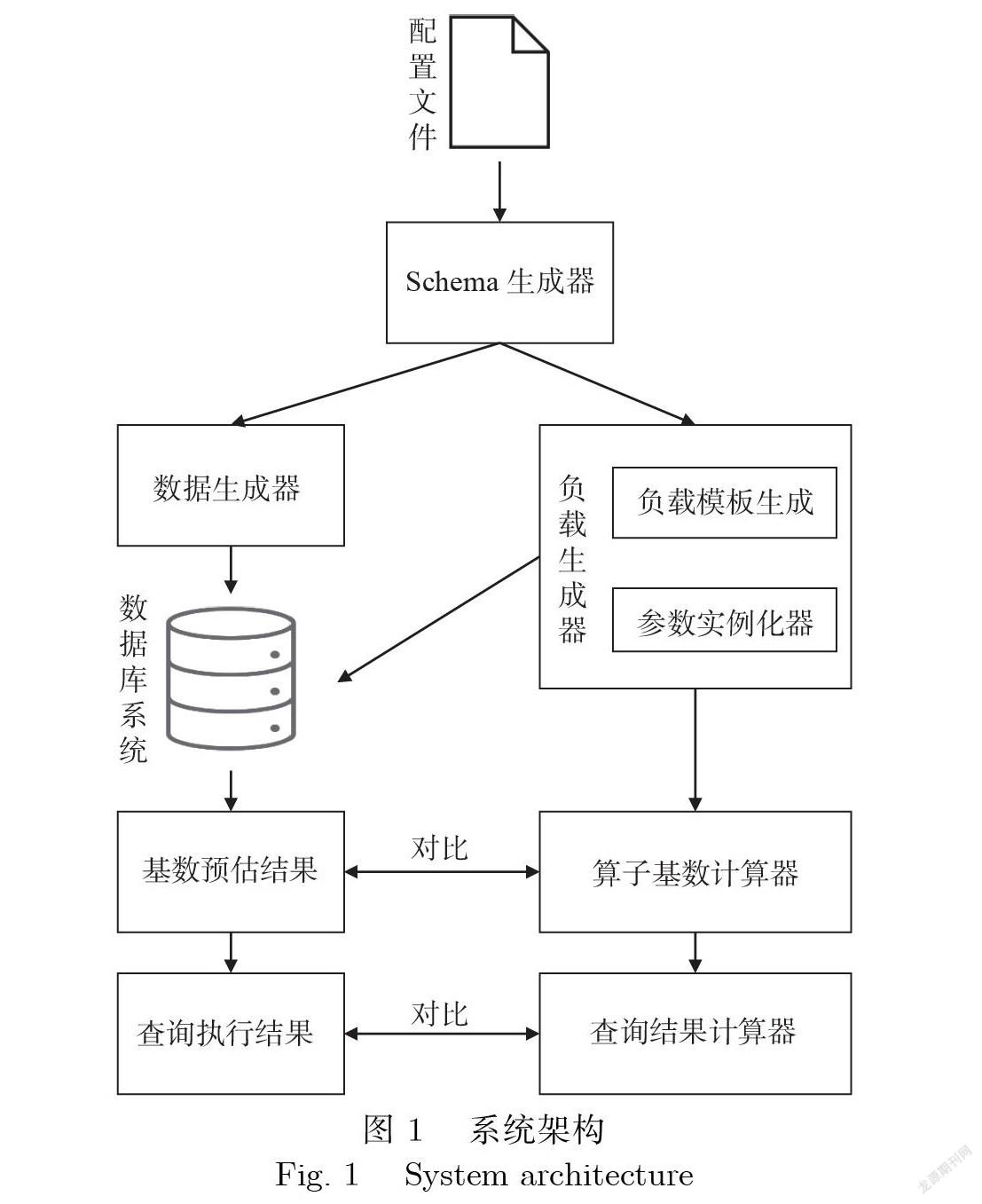
系统的整体架构如图1所示.用户首先在配置文件中定义本次测试所需要生成数据库模式中表的 数目、每张表的属性列数目分布、属性列数据分布、每张表的大小、生成查询中连接算子的数目等关 键信息;Schema生成器会读取配置文件,根据要生成的属性列的数据类型及分布情况进行属性生成 函数生成,同时根据每张表的外键数量进行表的参照关系生成;接着进入数据生成器进行大规模数据 生成,其中属性生成函数是数据生成机制的核心,所有的非主键属性是基于主键通过属性生成函数确 定性计算得出.
负载生成器也会用到Schema生成器的结果,在负载生成器中,首先会根据定义的连接算子的数目进行复杂负载模板的生成,负载生成器所生成的负载模板保证语法和语义正确.为了进一步提升生 成负载的质量,使用参数实例化器进行合理的查询参数填充.
生成完数据和负载后,将这些数据和负载导入数据库中执行,获得数据库执行结果,同时将负载 输入算子基数计算器进行算子中间结果的计算,可与数据库查询优化器基数预估的结果进行对比;最 后再到查询结果计算器中进行最终查询结果的计算,与数据库执行的结果进行对比.如果两者不一样, 则表明数据库有Bug,工具会把生成的数据以及该条SQL保存下来以便对Bug进行复现.
2.1基于主键的数据生成
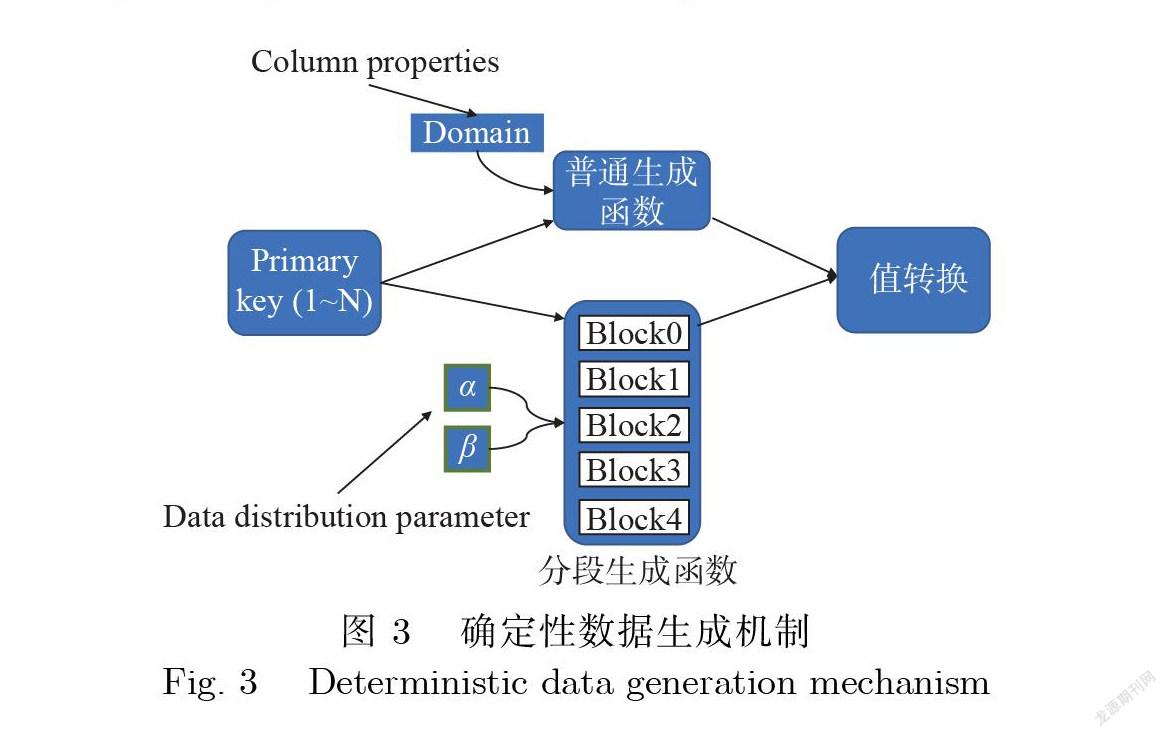
在数据生成模块中使用了关联主键的确定性的数据生成机制,为后续在算子基数计算器和查 询结果计算器中构建约束优化问题奠定基础.确定性数据生成机制具有关联主键的性质,即所有非主 键属性以主键为自变量使用生成函数确定性计算,其中主键值是采用自增形式产生,即被设置为 AUTO_INCREMENT.
数据生成器首先根据拟生成的属性列的数据分布情况进行属性生成函数的生成,从而使得生成 的数据满足一定的数据分布,比如高斯分布、ZipFian分布,具体做法是生成随机的分段函数.如果生 成的数据不需要满足任何分布,则默认为随机分布.具体做法是先确定要生成的属性列的数据类型, 如INT类型的范围是-2 147483648?2147483647,再确定生成函数,确保主键经过生成的函数映射 后的值不能超过预定数据类型的范围.
假如要生成10000个值域为1?100并满足高斯分布的数,首先将10000个数按照高斯分布序列 分块,将这些块随机装到100个桶中,这100桶即代表值域为1?100.按照上述方法生成的分段函数 如图2所示,1?10000的主键值通过该分段函数生成的10000个数即为值域为1?100、满足高斯分 布的数.
函数生成完成后,主键就可以通过已经生成的函数进行确定性数据生成.具体过程如图3所示. 首先,数据生成器根据配置文件的要求生成满足特定分布的数据:如果某一列需要满足分布,则根据 分布的参数A卢等随机生成分段函数,否则根据列的属性(如值域Domain)随机生成普通函数.接着 生成数据,最后再进行数据类型的转换.
2.2表间依赖关系生成
在Schema生成器中,重点关注表间参照依赖关系生成.Schema生成器会根据配置文件生成每张 表,基于依赖的拓扑按序生成每张表的所有外键以及这些外键的参照关系.一张表中可能有很多外键, Schema生成器确保单个表中的每个外键参照的表都不同,以此构建表的参照依赖关系图,如图4所示.
2.3有效负载生成
负载生成器会参考Schema生成器的结果,同时组合不同种类的关键字生成语法和语义正确的负载模板,并使用查询参数实例化算法填充模板,最终生成有效负载.
2.3.1负载模板生成
负载模板生成器使用SQL生成模型,根据配置选择SQL关键字来生成语法语义正确的负载模板. 如图5所示,首先SQL生成模型会根据Schema定义获得表间参照依赖关系,然后选择有依赖关系的 表来生成多表连接;接着从这些表中预先生成一个谓词生成顺序,按照该顺序进行谓词语句的生成以 及查询参数实例化,接着再生成Group By和Order By关键字;最后生成Select关键字以及5种聚集 运算表达式.
2.3.2查询参数实例化
负载模板生成器生成的是参数化的查询模板.如图6所示,该查询模板以A、B、C、D四表连接为 例,查询参数实例化器将按照的谓词顺序进行相关参数(K)的实例化.进行查询参数实 例化后负载才能被DBMS正常执行.查询参数实例化十分重要,因为它可以控制查询中算子的中间结 果集大小,从而使得查询优化器选择代价不同的查询执行计划,直接影响查询的执行时间.
负载生成器使用查询参数实例化器进行有效查询参数实例化,按照查询模板中的预定的连接顺 序对所有的谓词进行查询参数实例化.
基于关联主键的确定性数据生成机制,预生成的谓词参数的取值范围可以由已经实例化完成的 算子的连接结果确定性得到.查询参数实例化器会根据这个取值范围选择合理的参数对查询模板进 行填充.这种感知数据的查询参数实例化算法可以確保每个过滤谓词(Filter)算子以及每个连接 (Join)算子的有效性,故查询的最终结果不会为NULL,从而提高了生成负载的测试效果.
2.4算子基数的高效计算
查询优化器依赖代价模型为搜索空间中的每个执行计划进行代价预估.代价模型中的一个关键 参数就是算子的基数,现代查询优化器使用基数预估技术来获取算子的基数大小,但是会有很大的误 差,而且误差会随着连接算子数量的增多而越来越严重,最终导致优化器选择不到良好的执行计划. 如果能够提供算子的精确基数,消除基数预估带来的影响,可以对查询优化器进行很好的评测.
例 1 select * from a join b on a.fkx = b.primaryKey where a.colx < 1 993 and b.col2 > 2 000 算子基数计算器参照确定性的数据生成机制为每个算子构造约束优化问题来表示其结果.以例 1为例,单表、Filter算子、Join算子的约束优化表达式如图7所示.在本例中,表a和表b的主键的取 值范围分别是[0, 23444]和[0, 32345],所以表a未加过滤谓词(Filter)的约束为[Ka, [0, 23444]].表 a存在一个过滤谓词为a.col1 < 1993,属性a.col1是主键Ka使用生成函数F1(Ka)生成,所以 Filter的约束表示为[F1(Ka) < 1993, [0, 23444]].对于连接(Join)算子,涉及约束的转移,由于连接 条件是a.fki = b.primaryKey, &.&1属性同时又是表a的主键Ka使用f(Ka)函数生成的,所以可推导 出表b的主键Kb = f(Ka),将表b上的过滤谓词约束F2(Kb) > 2000加入Filter的约束中,连接(Join) 算子的约束表达式即为[FjKa) < 1993, F2(f(Ka)) > 2000,[0, 23444]].
对于每个算子的约束表达式,使用Mathematical进行约束求解.查询中所有算子的精确基数被 基数计算器计算出后,查询结果计算器会以主键对的形式表示每个算子的具体结果,接着参照查询中 Select关键字后面的复杂表达式的情况再计算查询的最终结果.基数计算器和查询结果计算器为生成 的复杂分析型负载提供了基准结果高效自计算、不用去执行额外负载即可获得算子的精确基数,可服 务于查询优化器的评估,同时查询的精准结果可用于发现数据库执行引擎的执行问题.
3实验分析
本章首先展示了工具的生成效率;然后,在开源的分布式数据库TiDB的不同版本上来验证本文 提出的模糊测试工具的有效性.
3.1实验环境
TiDB部署在UCloud集群中的5台机器上.本工具使用Java语言开发,运行环境为OpenJDK 14, 约束求解工具使用的是Mathematica12[24]. TiDB集群中有1台主TiDB节点用于处理客户端连接, 3台TiKV节点用于存储数据,1台PD节点用于调度以及1台Monitor节点用于监控整个TiDB集群 的情况.部署TiDB模块和TiKV模块的机器的主要配置是16核心CPU、16GB内存,部署PD模块 的机器的主要配置是2核心CPU、2GB内存,部署Monitor监控节点的机器的主要配置是8核心 CPU、8GB 内存.
3.2负载生成效率
本节展示工具的负载生成效率,设置生成1000个Query,在每个Query中分别设置生成0 ~ 8个 连接算子,查看Query中连接算子的个数对Query平均生成时间的影响,实验结果如图8所示.由于 负载生成过程中需要根据预定的连接顺序进行每个过滤谓词的参数范围计算,所以Query中连接算 子的个数会影响单条Query的生成效率.
3.3测试有效性展示
本节展示了利用该工具测试TiDB的不同版本,发现的一些查询处理功能的缺陷或者Bug.
3.3.1Decimal 类型转换 Bug
本例展示了 TiDB Master:1cebae2b版本的一个已经确认的Bug.在表中创建decimal(17, (3)类型 的属性列,并插入相应数据,但是在查询结果时使用cast as decimal关键字转换的时候出现结果错误. decimal默认长度为10,但是返回的结果长度为11.本工具通过生成如下的数据和查询发现了该问题: ---创建表
create table table_0_0 (primaryKey bigint,col_0 int,col_1 double,col_2 int,col_3 int,col_4 int,col_5 int,col_6 double,col_7 decimal(17,(3),primary key (primaryKey));
---插入工具生成的数据
insert into table_0_0 values (1,1,544.67,65,766,5 544,65 554, 44 336.7,93 994 883 422 334.30(1); ---执行工具生成的负载
select length (cast(col_7 as decimal)) from table_0_0;
-工具计算出的理想结果 10
---数据库执行的真实结果 11
3.3.2TiDB Float类型不精确的问题
本例展示了 TiDB的表中属性列设置float数据类型不能被精确查找出来的问题.由于本工具中 的数据生成器采用确定性的数据生成机制,所有的数据都能被精确地生成,同时约束求解器求解过程 准确,所以可以对float类型参与的计算进行精确的表示.该问题尽管已经证实是TiDB的原始设计意 图,但是这也证明了本工具的计算结果是精确而有效的,不用依赖权威数据库.测试样例如下:
…创建表
create table table_0_13 (primaryKey bigint, col_0 int, col_1 double, col_2 int, col_3 int, col_4 int, col_5 float, primary key (primaryKey));
---插入工具生成的数据
insert into table_0_13 values (7, 1, 9 983.22, 62, 76, 55, -8 888.9(5);
---執行工具生成的负载
select col_5 from table_0_13 where table_0_13.col_5 = 8 888.95;
一工具计算出的理想结果 -8 888.95
---数据库执行的真实结果 Empty set
3.3.3TiDB主键自增Bug
本例展示了在TiDB5.0版本表中设置float或double类型的主键同时设置auto_increment,使用 insert into或者replace into插入数据,每次插入会出现增量步长不是1的问题.本文提出的模糊测试 工具生成的如下负载发现了这个Bug,因为7个值之间的增量变成了 2,所以求和为错误的结果49而 不是理想的结果28.测试样例如下:
---创建表
create table table_0_2 (id double primary key AUTO_INCREMENT, col1 int);
---插入工具生成的数据
replace into table_0_2 (col(1) values (1); insert into table_0_2 (col(1) values (1); replace into table_0_2 (col(1) values (1); insert into table_0_2 (col(1) values (1); replace into table_0_2 (col(1) values (1); insert into table_0_2 (col(1) values (1); replace into table_0_2 (col(1) values (1); ---执行工具生成的负载
select sum(id) from table_0_2; 一工具计算出的理想结果28
---数据库执行的真实结果 49
4结论
针对分析型数据库查询处理功能正确性的测试问题,本文实现了一个模糊测试工具.使用关联主 键的确定性数据生成机制生成满足给定分布的数据;使用SQL生成模型生成语法语义正确的负载模 板并使用查詢参数实例化算法使得负载有效;通过构建约束优化问题高效求解算子基数及查询结果. 经过小规模测试,在开源的NewSQL分布式数据库TiDB上检测出了一些问题,验证了工具的可用性.
[参考文献]
[1]SILBERSCHATZ A, KORTH H F, SUDARSHAN S. Database Systems Concepts [M]. 5th ed. New York: McGraw-Hill Book Company, 2005.
[2] CHAUDHURI S. An overview of query optimization in relational systems [C]//Proceedings of the Seventeenth ACM SIGACT- SIGMOD-SIGART Symposium on Principles of Database Systems - PODS '98. Seattle: ACM Press, 1998: 34-43.
[3 ] LAN H, BAO Z, PENG Y. A survey on advancing the DBMS query optimizer: Cardinality estimation, cost model, and plan enumeration [J]. Data Science and Engineering, 2021, 6(1): 86-101.
[4 ] LEIS V, GUBICHEV A, MIRCHEV A, et al. How good are query optimizers, really? [J]. Proceedings of the VLDB Endowment, 2015, 9(3): 204-215.
[5 ] LI J, ZHAO B, ZHANG C. Fuzzing: A survey [J]. Cybersecurity, 2018, 1(1): 6.
[6 ] MANES V J M, HAN H, HAN C, et al. The art, science, and engineering of fuzzing: A survey [J]. IEEE Transactions on Software Engineering, 2019. DOI: 10.1109/TSE.2019.2946563.
[7]SLUTZ D R. Massive stochastic testing of SQL [C]//Very Large Data Base. 1998: 618-622.
[8 ] SELTENREICH A, TANG B, MULLENDER S. SQLSmith [CP/OL]. [2021-08-01]. https://github.com/anse1/sqlsmith.
[9]RIGGER M, SU Z. Testing database engines via pivoted query synthesis [C]//14th Symposium on Operating Systems Design and Implementation. 2020: 667-682.
[10]CHEN X, WANG C, CHEUNG A. Testing query execution engines with mutations [C]//Proceedings of the Workshop on Testing Database Systems. Portland Oregon: ACM, 2020: 1-5.
[11]GHIT B, POGGI N, ROSEN J, et al. SparkFuzz: Searching correctness regressions in modern query engines [C]//Proceedings of the Workshop on Testing Database Systems. Portland Oregon: ACM, 2020: 1-6.
[12]ZHONG R, CHEN Y, HU H, et al. SQUIRREL: Testing database management systems with language validity and coverage feedback [C] //Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security. Virtual Event USA: ACM, 2020: 955-970.
[13]JUNG J, HU H, ARULRAJ J, et al. APOLLO: Automatic detection and diagnosis of performance regressions in database systems [J]. Proceedings of the VLDB Endowment, 2019, 13(1): 57-70.
[14]BLAZYTKO T, BISHOP M, ASCHERMANN C, et al. GRIMOIRE: Synthesizing structure while fuzzing [C]//28th Security Symposium (Security 19). 2019: 1985-2002.
[15]ZALEWSKI M. American fuzzy lop (2.52b) [CP/OL]. [2021-08-01]. http://lcamtuf.coredump.cx/afl.
[16]BATI H, GIAKOUMAKIS L, HERBERT S, et al. A genetic approach for random testing of database systems [C]//Proceedings of the 33rd International Conference on Very Large Data Bases. 2007: 1243-1251.
[17]ASCHERMANN C, FRASSETTO T, HOLZ T, et al. NAUTILUS: Fishing for deep bugs with grammars [C]//NDSS. 2019.
[18]PADHYE R, LEMIEUX C, SEN K, et al. Semantic fuzzing with zest [C] //Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis. 2019: 329-340.
[19]STILLGER M, FREYTAG J C. Testing the quality of a query optimizer [J]. IEEE Data Engineering Bulletin, 1995, 18(3): 41-48.
[20]GU Z, SOLIMAN M A, WAAS F M. Testing the accuracy of query optimizers [C] //Proceedings of the Fifth International Workshop on Testing Database Systems. 2012: 1-6.
[21]CHAUDHURI S, NARASAYYA V, RAMAMURTHY R. Exact cardinality query optimization for optimizer testing [J] . Proceedings of the VLDB Endowment, 2009, 2(1): 994-1005.
[22]TRUMMER I. Exact cardinality query optimization with bounded execution cost [C]//Proceedings of the 2019 International Conference on Management of Data. Amsterdam Netherlands: ACM, 2019: 2-17.
[23]SHIN J H, RUSU F, SUHAN A. Exact selectivity computation for modern in-memory database query optimization [EB/OL]. (2019- 01-06)[2021-09-18]. https://arxiv.org/pdf/1901.01488.pdf.
[24]WOLFRAM. Mathematica 12 [CP/OL]. [2021-08-01]. https://www.wolfram.com/mathematica/.
(責任编辑:李万会)
