
基于代表性视图的三维模型检索
2021-03-14 11:33:04丁博汤磊何勇军于军
哈尔滨理工大学学报 2021年6期
关键词:卷积神经网络
丁博 汤磊 何勇军 于军


摘 要:提出了一种基于代表性视图的三维模型检索方法。在三维模型的视图表示方面,为了充分表示模型,并减少冗余信息,首先采用光场描述符(light field descriptor, LFD)将三维模型投影成二维视图,再将二维视图采用k均值聚类算法(K-means clustering algorithm, K-MEANS)进行聚类,生成代表性视图。然后采用卷积神经网络(convolutional neural network, CNN)提取视图特征并进行分类。同时提出了一种支持多种查询方式的相似度评价方法,以实现草图、图片或三维模型为输入条件的模型检索。本文在ModelNet40模型庫上的实验结果表明,部分特征突出的三维模型检索的准确率可以达到100%。
关键词:三维模型检索;代表性视图;卷积神经网络;k均值聚类算法
DOI:10.15938/j.jhust.2021.06.003
中图分类号: TP315.69
文献标志码: A
文章编号: 1007-2683(2021)06-0018-06
3D Model Retrieval Based on Representative Views
DING Bo1, TANG Lei1, HE Yong-jun1, YU Jun2
(1.School of Computer Science and Technology, Harbin University of Science and Technology, Harbin 150080, China;
2.School of Automation, Harbin University of Science and Technology, Harbin 150080, China)
Abstract:3D model retrieval based on representative views was proposed. On the view representation of the 3D model, in order to fully represent the model and reduce redundant information, we firstly adopt Light Field Descriptor (LFD) to generate 2D views, and then use K-MEANS to get representative views from the 2D views. Next, a Convolution Neural Network (CNN) is adopted to extract the view feature and classify. At the same time, a similarity metrics supporting multiple query method is proposed to realize model retrieval with sketches, pictures or 3D models as input. Results on ModelNet40 showed that the proposed method could achieve an accuracy of 100% for part of models with distinct features.
Keywords:3D model retrieval; representative views; convolutional neural network; K-MEANS
0 引 言
近年来,三维模型被广泛用于计算机辅助设计(computer aided design, CAD)、虚拟现实、3D动画和影视、医学诊断、3D网络游戏、机械制造等领域。尤其是最近几年3D打印技术的兴起,三维模型的应用得到了更为广泛的普及,已经成为各行各业不可或缺的技术手段[1]。三维模型数量的飞速增长为模型增量设计提供了大量素材。有关研究表明,新产品开发中重用现有的或供应商提供的零部件占40%,修改后重用的零部件占40%,完全全新设计的零部件仅占20%。据估计变型设计或自适应设计约占到其中的90%,这表明大多数的设计工作可重用以前的产品设计知识[2]。根据产品之间的相似性,最大限度地重用已有的设计资源来开发新产品,不仅可以降低产品成本,缩短设计时间,而且还可以有效的提高产品可靠性,保证产品质量[3]。
描述符是真实三维模型的代表。三维模型检索技术首先采用描述符对三维模型进行表达,然后通过对描述符进行相似性度量来进行检索。常用的三维模型描述符可以分为如下四种:基于几何结构分析的描述符[4]、基于统计的描述符[5]、基于投影视图的描述符[6]和基于拓扑的描述符[7]。基于投影的三维模型检索是将三维模型在特定的位置投影,得到一组二维视图,利用这组二维视图提取三维模型相应的特征表示,即将三维模型的分类检索转换成二维视图的分类检索。这类方法更加符合人的视觉感知特性,因此得到了广泛的应用。基于投影的三维模型检索的一个重点和难点是选择多少数量的投影视图。该投影的数量既能对三维模型充分描述,不丢失模型的空间信息;又不会产生冗余视图,给检索以及计算机的存储造成不便。最简单的视图是模型的三视图,Min等[8]就是用提取三视图的方法,从模型三个固定的方向获取了正视图、俯视图、侧视图,然后对这些二维轮廓特征图进行相似性比较。但是此类简单视图对于模型本身的拓扑等空间信息不能表达,最后的检索性能并不能取得足够的满意度。Chen等[9]提出一种光场描述符(light field descriptor, LFD)的算法。此算法首先利用正十二面体包围模型,在正12面体中取得10个非对称顶点;然后在10个顶点中的每个顶点设置10个不同的光场;最后对得到的100幅视图进行Zernike特征提取和傅里叶变换特征提取。然而该算法存在大量冗余,虽然可以充分地表达三维CAD模型,但是不利于计算机的计算。针对大量的冗余视图,一些学者采用如下方法加以改进,Cyr等[10]提出一种通过比较代表性视图中形状结构的方法。通过多个视角渲染得到足够多的视图,将其中一组有明显差异的视图作为最终视图。还有一些学者将深度学习与基于投影描述符的方法结合,如秦飞巍等[11]将深度学习引入3D模型的检索当中,他选择光场描述符提取出的Zernike特征作为深层神经网络的输入进行学习,分类效果比较理想。Shi等[12]在预处理阶段利用圆柱体包围三维模型,像素值即是圆柱体的点和模型主轴的连线投射到三角面片的数量;此时将圆柱体侧面展开得到三维模型的二维视图;最后利用深度学习进行模型分类的任务。Su等[13]在对三维模型渲染时使用虚拟摄像机的技术,首先从12个方向拍摄得到12幅不同的视图;然后利用卷积神经网络对三维模型的视图特征进行提取;在三维模型的分类精度上达到了较高的水平。冯元力等[14]提出一种球面深度全景图描述三维形状的方法。该方法通过对三维模型进行多角度球面深度投影得到多个球面全景图,然后使用卷积神经网络,对多幅全景图进行整合分析。Su等[15]采用两层卷积神经网络对模型进行分类。通过第一层卷积神经网络分别提取12张二维视图的特征,然后将这些特征合并,并输入到第二层卷积神经网络,从而得到一个完整的形状描述符。白静等[16]首先采用深度学习模型CaffeNet分类二维视图,然后利用加权投票的方式完成三维模型的分类。LFD除了会产生大量冗余视图之外,还存在另一个问题,该算法只是笼统的对所有二维视图进行同等对待,却忽略了不同视图的特征对三维模型的重要性并不相同。石民等[17]提出一种基于二维投影视图最优权重对的方法,此方法是通过使用拉格朗日乘数子和支持向量机为视图配置权重,用来区分不同视图对于三维模型重要性的不同,该方法的检索性能优于传统的LFD。
本文提出了一种基于代表性视图的三维模型检索方法,该方法首先采用LFD均匀产生100二维投影视图,然后采用K-MEANS将二维投影视图进行聚类,生成代表性视图,最后将代表性视图输入VGG_16,对模型进行索引建立并获取模型特征。通过VGG_16对模型进行先分类,使待检索模型仅需与同一类别的模型进行相似度匹配。该方法通过聚类减少了冗余视图,并利用CNN对模型进行先分类再检索,有效提高了模型检索的速度和精度。
1 本文算法實现
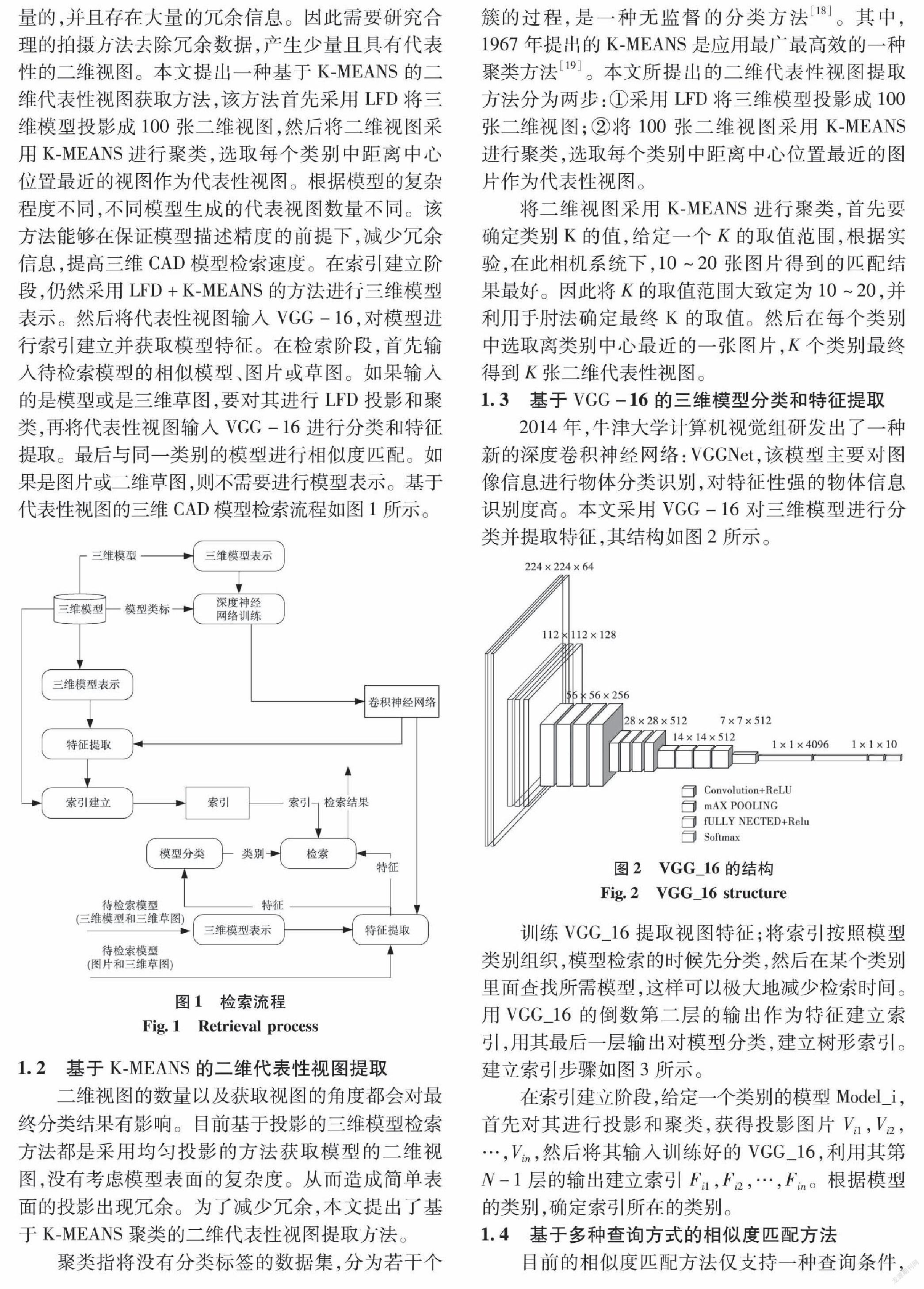
1.1 基于代表性视图的三维CAD模型检索
基于投影的特征提取方法采用多个不同视角对模型进行投影,然后提取和汇总各投影的全局图像特征作为原三维模型的内容表征。目前方法的拍摄位置均匀分布在模型周围,所产生的投影数据是海量的,并且存在大量的冗余信息。因此需要研究合理的拍摄方法去除冗余数据,产生少量且具有代表性的二维视图。本文提出一种基于K-MEANS的二维代表性视图获取方法,该方法首先采用LFD将三维模型投影成100张二维视图,然后将二维视图采用K-MEANS进行聚类,选取每个类别中距离中心位置最近的视图作为代表性视图。根据模型的复杂程度不同,不同模型生成的代表视图数量不同。该方法能够在保证模型描述精度的前提下,减少冗余信息,提高三维CAD模型检索速度。在索引建立阶段,仍然采用LFD+K-MEANS的方法进行三维模型表示。然后将代表性视图输入VGG-16,对模型进行索引建立并获取模型特征。在检索阶段,首先输入待检索模型的相似模型、图片或草图。如果输入的是模型或是三维草图,要对其进行LFD投影和聚类,再将代表性视图输入VGG-16进行分类和特征提取。最后与同一类别的模型进行相似度匹配。如果是图片或二维草图,则不需要进行模型表示。基于代表性视图的三维CAD模型检索流程如图1所示。
1.2 基于K-MEANS的二维代表性视图提取
二维视图的数量以及获取视图的角度都会对最终分类结果有影响。目前基于投影的三维模型检索方法都是采用均匀投影的方法获取模型的二维视图,没有考虑模型表面的复杂度。从而造成简单表面的投影出现冗余。为了减少冗余,本文提出了基于K-MEANS聚类的二维代表性视图提取方法。
聚类指将没有分类标签的数据集,分为若干个簇的过程,是一种无监督的分类方法[18]。其中,1967年提出的K-MEANS是应用最广最高效的一种聚类方法[19]。本文所提出的二维代表性视图提取方法分为两步:①采用LFD将三维模型投影成100张二维视图;②将100张二维视图采用K-MEANS进行聚类,选取每个类别中距离中心位置最近的图片作为代表性视图。
将二维视图采用K-MEANS进行聚类,首先要确定类别K的值,给定一个K的取值范围,根据实验,在此相机系统下,10~20张图片得到的匹配结果最好。因此将K的取值范围大致定为10~20,并利用手肘法确定最终K的取值。然后在每个类别中选取离类别中心最近的一张图片,K个类别最终得到K张二维代表性视图。
1.3 基于VGG-16的三维模型分类和特征提取
2014年,牛津大学计算机视觉组研发出了一种新的深度卷积神经网络:VGGNet,该模型主要对图像信息进行物体分类识别,对特征性强的物体信息识别度高。本文采用VGG-16对三维模型进行分类并提取特征,其结构如图2所示。
训练VGG_16提取视图特征;将索引按照模型类别组织,模型检索的时候先分类,然后在某个类别里面查找所需模型,这样可以极大地减少检索时间。用VGG_16的倒数第二层的输出作为特征建立索引,用其最后一层输出对模型分类,建立树形索引。建立索引步骤如图3所示。
在索引建立阶段,给定一个类别的模型Model_i,首先对其进行投影和聚类,获得投影图片Vi1,Vi2,…,Vin,然后将其输入训练好的VGG_16,利用其第N-1层的输出建立索引Fi1,Fi2,…,Fin。根据模型的类别,确定索引所在的类别。
1.4 基于多种查询方式的相似度匹配方法
目前的相似度匹配方法仅支持一种查询条件,这样限制了用户采用不同的输入进行检索。本文提出的三维模型检索方法支持多种查询方式,即支持三维模型、图片、二维草图和三维草图为输入。因此模型相似度匹配方法要根据待检索模型输入的不同采用不同的方法。
检索条件可以分为三维模型、图片、二维草图和三维草图。对于三维模型或三维草图输入,首先生成二维投影视图。生成视图的张数可以根据匹配的情况灵活确定。而对于图片和二维草图则直接当做视图。对于模型和三维草图首先生成一张二维投影视图,与现有模型库中的模型匹配,如果匹配度达到η,则匹配成功,否则继续生成二维投影进行匹配。直到匹配度达到η或没有新的二维视图产生为止。相似度匹配流程如图4所示。
基于多种查询方式的相似度匹配方法分为两种情况。第一种情况是当输入为图片或二维草图时,
不需要进行投影和聚类,直接将其输入到CNN中分类,然后根据提取出来的特征与同一类别中的模型特征进行距离度量,距离函数采用欧氏距离,即
i=argmini,kdis(W,Fik)(1)
其中:W为CNN输出的特征值;Fik为同一类别模型的特征值,1≤i≤m,m为同一类别中的模型数,1≤k≤n,k为同一模型的投影数,求得的i为最终匹配的模型。
第二种情况是当输入为三维模型或三维草图时,首先需要进行投影和聚类,当产生多个视图作为检索条件时,假定其CNN的输出特征为W1,W2,…,Wl,…,WL,这些特征需要与同一类别的模型特征进行相似度匹配。其相似度计算为
il=argmini,kdis(Wl,Fik)(2)
其中:Wl为CNN输出的特征值;l={1,2,3,…,L};L为输入模型产生的投影数;Fik为同一类别模型的特征值,求得的il为与特征Wl最匹配的模型。
创建模型向量Model_Vector,并赋其初值为0。如式(3)所示。
Model_Vector[1,2,…,p]=[0,0,…,0](3)
其中p为同一类别中的模型数。
当Wl与同一类别中的模型相匹配时,其对应的向量值加1。如式(4)所示。
Model_Vector[il]=Model_Vector[il]+1(4)
最后统计哪个模型对应的向量值最高,该模型为最终匹配模型。
2 实验结果与分析
实验基于Tensorflow框架,使用VGG16完成图像特征提取及分类,Python处理相关数据。实验所用的PC为intel i72600k + gtx 1060,GPU为GTX965。
文中算法应用于刚性三维模型库ModelNet40。由于ModelNet40数据集中不同分类下的模型数量差距较大。为了测试VGG16对此数据集的鲁棒性,本文在ModelNet40中选取10类模型airplane、car、chair、cone、door、guitar、person、plant、sofa、stairs作为实验数据集。该10类模型中有的数量多达989个,如chair,有的则只有108个模型,如person。选取数据集共有3955个模型,10种类别,平均每种类别包含395个模型。选择3275个模型作为训练,680个模型作为测试集。
由于本文采用基于K-MEANS的方法进行二维代表性视图提取,因此确定K的取值对三维模型的表示有着重要的影响。K取值过小,会造成模型描述不全面,而K值过大又会无法达到去除冗余图片的效果。经过实验,本文最终确定K的取值范围是10~20。不同取值下对检索的影响如图5所示。
另一个影响检索结果的是η的取值。适当的η值不仅可以提高检索速度还可以提高检索精度。当η取值过大时,检索速度会加快,但对精度会降低。反之,当η取值过小时,检索精度有所提升,但速度稍微下降。同时,在本数据集中,当η取值范围是0~1时,对检索精度产生的影响不大。综合以上因素,本文确定η取值为0.5。不同η值对检索的影响如图6所示。
确定不同参数的值以后,将本文所提出的算法与现有算法LFD[9]和Su-MVCNN[15]进行对比。准确率以及P-R曲线对比实验结果如图7所示。
通过对比实验表明,本文提出的方法在选取数据集上取得相对好的检索效果。采用基于K-MEANS聚类的方式获取三维模型的二维代表性视图,不仅减少了冗余视图,还能用尽量少的二维视图全面地描述三维模型,大大提高了特征匹配的质量。通过分析实验结果,得出以下结论:
1)训练数据不均衡会影响检索结果,但只要特征差距大,仍然会取得良好的检索准确率。本文实验选取的数据集,类别间数量差异悬殊,但同时类别间的特征差异也大。实验结果却比预期好很多。因此,本实验结果表明,只要数据间的特征差距大,同样也可以产生很好的训练效果。
2)对于特征不明显的数据来说,分类和检索效果一般。本实验所选取的10个模型中,airplane的检索效果最好,选取的二维代表性视图基本都能正确分类并取得理想的检索效果。car、cone、guitar、person效果稍次之,有个别二维代表性视图无法正确分类,但最终检索效果表现出色。chair、stairs、plant、sofa中个别模型检索效果差,其中sofa的部分模型被识别为chair。door模型的检索效果一般。产生这些现象的原因是各个模型的特征表现不一致。airplane模型比较复杂,特征比较突出,因此效果最好。sofa和chair有些模型在投影下比较类似,导致可能会被错分。而door模型比较简单,投影之后特征不够明显,因此分类和检索的效果都一般。
本文只是针对ModelNet40中部分数据做了实验分析。结果表明,本文的检索算法在性能和效率上都有所提升。下一步要加大数据集的实验,并找到相似模型内部不同局部区域,区别对待,以提升检索的精度。
3 结 论
本文提出了一种基于代表性视图的三维模型检索方法,该方法采用LFD和K-MEANS相结合的方式生成二维代表性视图,用尽量少的二维视图表示三维模型,不仅有效剔除了冗余视图,还保证了检索精度。同时训练VGG-16提取视图特征,將索引按照模型类别组织。模型检索的时候先分类,然后在某个类别里面查找所需模型,这样极大地减少检索时间。
参 考 文 献:
[1] ZENG Hui, LIU Yanrong, LI Siqi, et al. Convolutional Neural Network Based Multi-feature Fusion for Non-rigid 3D Model Retrieval[J]. Information Processing Systems, 2018, 14(1): 176.
[2] SHARMA, R., J.X. GAO. A Knowledge-based Manufacturing and Cost Evaluation System for Product Design/re-design[J]. International Journal of Advanced Manufacturing Technology, 2007, 33(9-10): 856.
[3] 李海生, 孙莉, 武玉娟, 等. 非刚性三维模型检索特征提取技术研究[J]. 软件学报, 2018, 29(2): 483.
LI Haisheng, SUN Li, WU Yujuan, et al. Survey on Feature Extraction Techniques for Non-Rigid 3D Shape Retrieval[J]. Journal of Software, 2018, 29(2): 483.
[4] BIASOTTI S,GIORGI D,SPAGNUOLO M,et al. Size Functions for Comparing 3D Models[J]. Pattern Recognition, 2008, 41(9): 2855.
[5] OHBUCHI R, TAKEI T. Shape Similarity Comparison of 3D Shapes Using Alpha Shapes[C]// Proceedings of Pacific Graphics, Canada, 2003: 293.
[6] PU J T, RAMANI K. An Integrated 2D and 3D Shape-based
Search Framework and Applications[J]. Computer Aided Design and Applications, 2007, 4(6): 817.
[7] 皇甫中民, 张树生. 基于图索引过滤机制的三维CAD模型局部检索[J]. 计算机集成制造系统, 2015, 21(7): 1679.
HUANFU Zhongmin, ZHANG shushing. Partial Retrieval Method of 3D CAD Models Based on Gragh Indexing and Filtering Mechanism[J]. Computer Integrated Manufacturing System, 2015,21(7):1679.
[8] MIN P, CHEN J, FUNKHOUSER T. A 2D Sketch Interface for a 3D Model Search Engine[C]// ACM SIGGRAPH 2002 Conference Abstracts and Applications, 2002: 138.
[9] CHEN D Y, TIAN X P, SHEN Y T. On Visual Similarity Based on 3D Model Retrieval[J]. Computer Graphics Forum, 2003, 22(3): 223.
[10]CYR C M, KIMIA B B. 3D Object Recognition Using Shape Similarity-based Aspect Graph[C]// ICCV, 2001, 1: 254.
[11]QIN Feiwei, LI Luye, GAO Shuming, et al. A Deep Learning Approach to the Classification of 3D CAD Models[J]. Comput & Electron, 2014: 91.
[12]SHI B, BAI S, ZHOU Z, et al. Deep Pano: Deep Panoramic Representation for 3-D Shape Recognition[J]. Signal Processing Letters, 2015, 2339.
[13]SU H, MAJI S, KALOGERAKIS E, et al. Multi-view Convolutional Neural Networks for 3D Shape Recognition[C]// ICCV, 2015: 945.
[14]冯元力, 夏梦, 季鹏磊. 球面深度全景图表示下的三维形状识别[J]. 计算机辅助设计与图形学学报, 2017, 29(9): 1689.
FENG Yuanli, XIA Meng, JI Penglei, et al. Deep Spherical Panoramic Representation for 3D Shape Recognition[J]. Journal of Computer-Aided Design & Computer Graphics, 2017,29(9):1689.
[15]SU H, MAJI S, KALOGERAKIS E, et al. Multi-view Convolutional Neural Networks for 3D Shape Recognition[C]// Proceedings of the IEEE International Conference on Computer Vision. Los Alamitos: IEEE Computer Society Press, 2015: 945.
[16]白静, 司庆龙, 秦飞巍. 基于卷积神经网络和投票机制的三维模型分类与检索[J]. 计算机辅助设计与图形学学报, 2019, 31(2): 303.
BAI Jing, SI Qinglong, QIN Feiwei. 3D Model Classification and Retrieval Based on CNN and Voting Scheme[J]. Journal of Computer-Aided Design & Computer Graphics, 2019,31(2):303.
[17]SHI M, ZHANG S S, LI L, et al. 3D CAD Model Retrieval Using 2D Characteristic Views[J]. Engineering & Technology, 2012:1.
[18]姚登举,詹晓娟,张晓晶.一种加权K一均值基因聚类算法[J].哈尔滨理工大学学报, 2017, 2: 112.
YAO Dengju, ZHAN Xiaojua, ZHANG Xiaojing. A Weighted K-means Gene Clustering Algorithm[J]. Journal of Harbin University of Science and Technology, 2017(2):112.
[19]吴明阳,张芮,岳彩旭,等.应用K-means聚类算法划分曲面及实验验证[J].哈尔滨理工大学学报, 2017, 1: 54.
WU Mingyang, ZHANG Rui, YUE Caixu, et al. Application of K-means Clustering Algorithm to Divide Surface and Experimental Verification[J]. Journal of Harbin University of Science and Technology, 2017(1):54.
(編辑:温泽宇)
收稿日期: 2019-09-06
基金项目: 国家自然科学基金面上项目(61673142);黑龙江省自然科学基金杰出青年项目(JJ2019JQ0013);黑龙江省普通本科高等学校青年创新人才项目(UNPYSCT-2016034).
作者简介:
汤 磊(1995—),男,硕士;
何勇军(1980—),男,教授,博士研究生导师.
通信作者:
丁 博(1983—),女,副教授,硕士研究生导师,E-mail:dingbo@hrdust.edu.cn.
猜你喜欢
电子技术与软件工程(2017年3期)2017-03-22 23:24:25
电脑知识与技术(2016年33期)2017-03-21 23:19:04
科技创新与应用(2017年5期)2017-03-16 09:48:22
电脑知识与技术(2016年30期)2017-03-06 20:14:45
科技创新与应用(2016年35期)2017-02-21 19:16:50
计算机应用(2016年12期)2017-01-13 20:26:21
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
软件(2016年5期)2016-08-30 06:27:49
电脑知识与技术(2016年10期)2016-06-16 21:27:26
