
基于主成分分析和logistic回归的中小微企业信贷决策
2021-03-12 07:15邵永运
沈阳师范大学学报(自然科学版) 2021年5期
邵永运, 惠 丹
(沈阳师范大学 软件学院, 沈阳 110034)
0 引 言
随着我国市场经济体制的日益完善,市场竞争也越来越激烈。第四次全国经济普查系列报告显示,2018年末我国中小微企业法人单位约1 807万家,较2013年末增长115%,占全部规模企业法人单位的99.8%[1]。中小微企业在经济发展、科技创新、吸纳就业方面发挥着重要作用[2],但较之大企业而言,中小微企业在融资成本、融资渠道、信贷支持等方面望尘莫及,这些因素严重阻碍了中小微企业的发展[3]。习近平总书记多次指出,为实体经济服务是金融的天职,是金融的宗旨,也是防范金融风险的根本举措[4]。银行与企业之间存在着信息不对称的问题,致使双方难以实现共赢[5-7]。因此,银行对中小微企业信贷业务的关键就在于对信贷风险的预测[8-9]。本文将结合主成分分析和logistic回归对中小微企业信贷决策问题进行建模并求解。
1 数据处理
1.1 数据源
本研究所采用的数据为2020年全国大学生数学建模竞赛中C组题目所提供的123家有信贷记录企业的相关数据。
1.2 指标提取
根据企业规模、企业信誉及供求关系稳定性,从企业进销项发票信息中提取10个可用指标[10]。影响信誉评级的指标见表1。

表1 影响信誉评级的指标Table 1 Indicators affecting reputation rating
1.3 数据预处理
数据预处理工作主要是要将源数据处理成计算机可以识别的数据[11-13]。在该数据源基础上需要做的处理工作包括:
1) 对数据进行去空值与去重处理;
2) 将发票状态以及是否违约分别使用0,1进行标记;
3) 将上述10个指标通过计算得到其数据形式。
经过处理的数据见表2,后续的分析工作将在此数据基础上展开。

表2 预处理后的数据Table 2 Preprocessed data
2 模型构建与分析
2.1 主成分分析降维
首先,对所提取的10个指标进行皮尔逊相关性分析,其结果见表3。

表3 各指标间皮尔逊相关系数Table 3 Pearson’s correlation coefficient among various indicators
由表3可知,指标X1与X2之间的皮尔逊相关系数为0.899 7,X3与X6的相关系数为0.889 1。该结果表明,所提取的10个指标之间独立性较差,需要进行降维处理,降维后使得后续的数据分析工作更加简洁明了[14-15]。
其次,考虑到各指标间数据范围差异较大,所以在进行主成分分析之前对数据进行标准化处理。标准化公式为
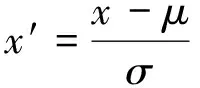
(1)
式中:μ为均值;σ为标准差。
最后,利用Pathon语言sklearn包中的PCA类对标准化处理后的数据进行主成分分析。由图1可知,前6个主成分反映了原始变量的87%的信息。
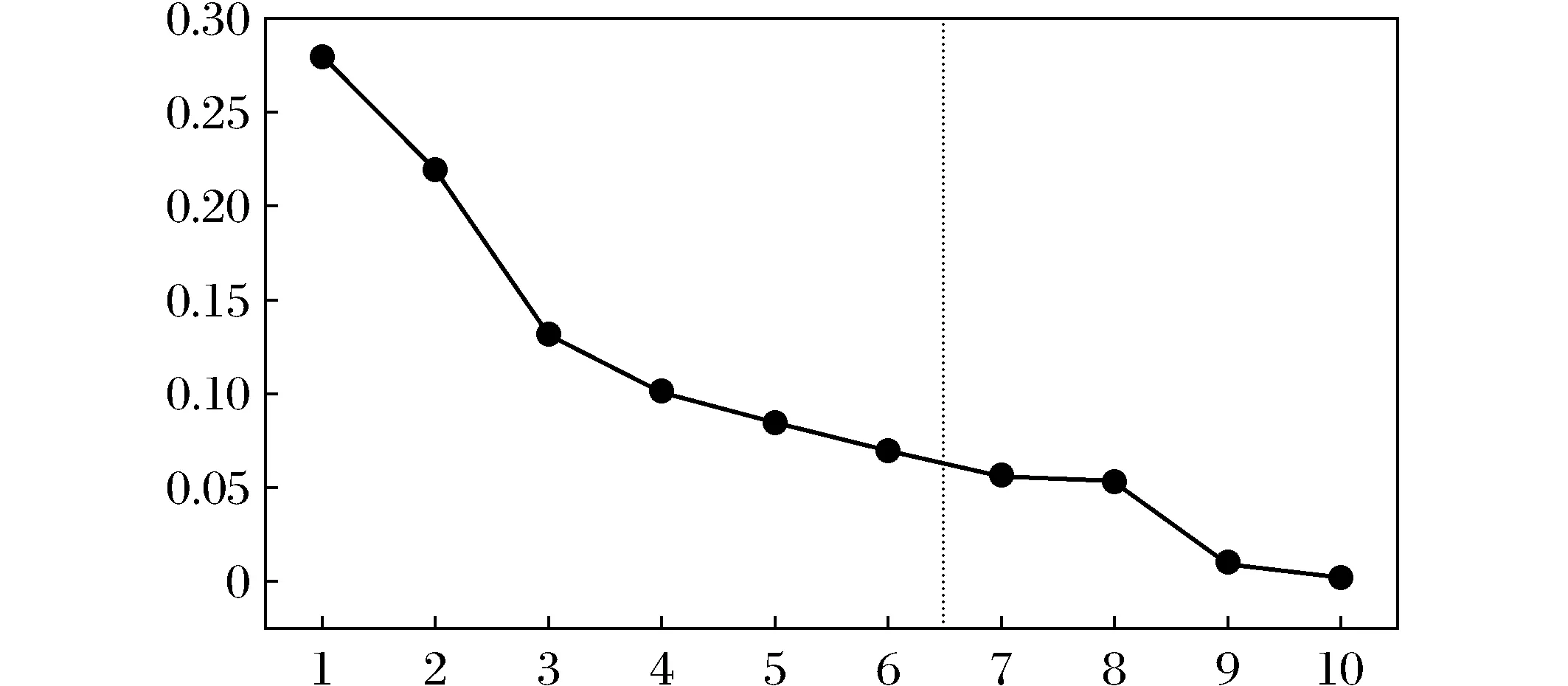
图1 主成分分析可视化结果Fig.1 Principal component analysis visualization results
2.2 logistic回归建模
经主成分分析后得到6个主成分,因此logistic回归模型中的自变量为降维后的前6个主成分,记作F1,F2,…,F6,因变量为企业是否违约(是为“1”,否为“0”)。通过logistic回归计算出回归系数(见表4)和企业违约概率Pi(见表5,i代表第i个企业)。logistic回归模型如下(β为违约损失系数):
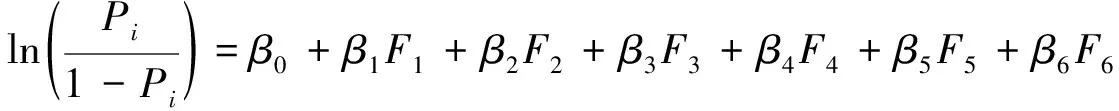

表5 企业违约概率Table 5 Probability of enterprise default
2.3 目标规划
通过logistic回归得到企业违约概率后,可通过目标规划确定银行对中小微企业的具体信贷决策,主要包括是否贷款、贷款额度以及贷款利率。
1) 决策变量
设银行对企业Ei放贷的金额为xi,贷款年利率为ri,i代表第i个企业(i=1,2,3,…,123 )。
2) 目标函数
银行的目标为总贷款利润即收益最大并且要求年总体风险最小,所以目标函数如下所示:
其中:xi为放贷金额;ri为贷款利率;FTP为银行内部资金调动利率,取0.027;α为违约系数,一般取0.2;Pi为违约概率,已通过logistic回归求出;β为违约损失系数,A,B,C类企业分别对应0.09,0.18,0.27;Li为客户流失率。
3) 约束条件
① 银行对每个企业的放贷额为10万~100万元:10≤xi≤100;
③ 贷款年利率约束:4%≤ri≤15%;
4) 信贷决策
运用pandas对上述模型进行求解,则可得到该信贷问题的最优决策(见表6)。
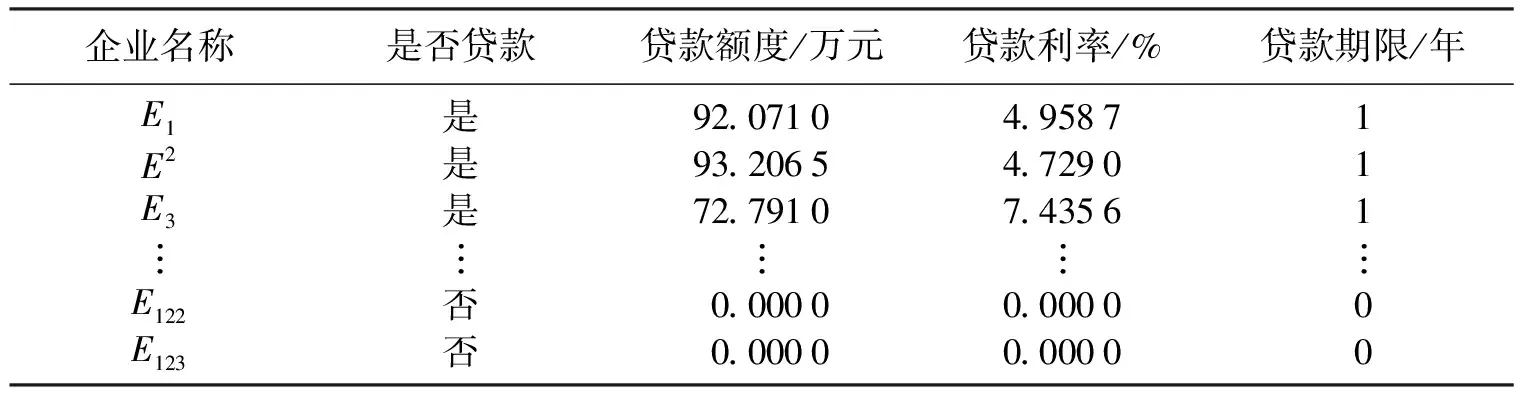
表6 银行对123家企业的信贷决策Table 6 Bank’s credit decision on 123 companies
3 结 语
信贷风险的预测与信贷决策的实现使得企业和银行双方可以实现共赢,进而推动经济发展。本文通过主成分分析与logistic回归的结合,可以有效衡量企业的违约风险,再通过目标规划进行信贷决策,最终得出银行对123家有信贷记录的中小微企业的信贷决策。该预测模型对有信贷记录的中小微企业的信贷问题提供了一种解决思路,同时也可将其延伸到无信贷记录的信贷决策问题中。
猜你喜欢
车主之友(2022年4期)2022-08-27
初中生世界(2020年43期)2020-12-18
初中生世界·九年级(2020年11期)2020-12-02
疯狂英语·新悦读(2020年1期)2020-02-20
海峡姐妹(2019年12期)2020-01-14
教育教学论坛(2019年7期)2019-03-18
科学与财富(2018年16期)2018-08-10
火控雷达技术(2016年1期)2016-02-06
