
面向方面级情感分析的BERT性能改进
2021-03-12 07:13王学颖孔德宙
沈阳师范大学学报(自然科学版) 2021年5期
王学颖, 孔德宙, 于 杨
(沈阳师范大学 软件学院, 沈阳 110034)
0 引 言
在行业环境中,消费者对待产品有一个正确的观点非常重要[1],由于在许多领域中这些观点的数量众多,长度参差不齐,对其进行分析是一项耗时且费力的任务,因此如何能够准确地把握这些观点潜在的价值已变成现在非常热门的课题。随着计算能力的不断提高和网站上大量免费数据的广泛使用,深度学习技术对自然语言处理(natural language process, NLP)领域产生了巨大的影响,尤其是语言的建模技术起着至关重要的作用。BERT[2]是最近比较流行的语言模型,已在许多NLP任务[3]以及其他领域中得到广泛使用,如利用BERT进行专利实体抽取研究[4]。其体系结构的主要组件称为transformer,由attention heads组成,这些heads的目的是要特别注意与给定的任务相对应的输入句子的各个部分,同时为了从上下文中学习语法和语义,BERT对大量的Wikipedia文档和书籍进行了预训练。
姚佳奇等[5]使用图卷积网络(graph convolutional networks, GCN)考虑了序列中的情感依赖性。研究表明,当序列中存在多个方面级时,其中一个方面级的情绪会影响另一个方面级的情绪,利用这个信息可以提高模型的性能。一些研究将AE任务转换为句子对分类任务。杨玉亭等[6]使用序列的方面级术语来构造辅助句子,然后针对此特定任务利用2个序列对BERT进行微调。还可以使用特定领域的数据来丰富模型的单词和句子级别表示。巫浩盛等[7]通过在其他餐厅和笔记本电脑数据上对BERT模型(称为BERT-PT)进行后训练来证明这一点。在实验中,将BERT-PT用于模型的初始化,由于BERT模型的特殊体系结构,所以可以在其顶部附加额外的模块。
基于上述学者的问题及经验,本文提出了并行聚合和分层聚合2个模块,以提高BERT模型的性能。首先,将BERT用于基于方面级的情感分析(ABSA)任务,使用BERT架构中相同的层模块;其次,采用隐藏层进行预测;最后选择条件随机场(CRF)进行序列标记,从而获得更好的结果。实验发现,通过长时间的BERT模型训练不会导致模型过拟合,但经过一定次数的训练后会导致模型过拟合。
1 基于方面级情感分析任务
ABSA中的2个主要任务是方面级提取和方面级情感分类(aspect sentiment classification, ASC)。
在AE中,目标是提取评论中带有情感的产品的特定方面级。例如在句子“笔记本电脑的电池质量很好”中,电池是提取的内容。此任务可以看作序列标记任务,从3个字母{B、I、O}的集合为单词分配标签。序列中的单词可以是方面级术语(O)中方面级术语(B)的起始词,也可以不是方面级术语(O)。
在ASC中,目标是提取消费者在评论中表达的情感。给定一个序列,将提取正、负和中性之一作为该序列的类。对于每个输入序列,BERT模型使用2个额外的令牌:
[CLS],w1,w2,…,wn,[SEP]
句子的情感由体系结构最后一层中的[CLS]令牌表示。然后,类别概率由softmax函数计算。
2 提出的模型
深度模型可以随着语句数量的增长而获取对语言的更深入了解。蔡国永等[8]的研究表明,BERT的起始层到中间层可以提取语法信息,而语义信息在更高的层中获取,因此在研究中可以利用BERT模型的最后几层进行语义分析。
本文提出的2个模型在原理上相似,但是实现上略有不同。同样,对于这2个任务,代价的计算方式也不同。对于ASC任务,利用交叉熵损失;对于AE任务,利用CRF。AE任务可以视为序列标记,由于CRF使用了一个建立概率模型的框架来分割和标记序列数据,所以序列中的先前标记非常重要。对于此类任务,相比隐马尔可夫模型和随机语法,CRF能够放松在这些模型中做出的强独立性假设。CRF也避免了最大熵马尔可夫模型(MEMMs)和其他基于有向图模型的判别马尔可夫模型的基本局限性。
CRF[9]是一种图形模型,已用于计算机视觉(例如用于像素级标记[10])和用于序列标记的NLP。由于可以将AE视为序列标记任务,因此本文选择在模型的最后一部分中使用CRF层。AE使用CRF模块的理由是这样做有助于网络考虑标签的联合分配,因为序列词的标签取决于出现在它们前面的词。例如,如图1所示,形容词商品的出现可以为模型提供一个线索,即下一个单词可能不是另一个形容词。用于计算标签的联合概率的方程式如下:

图1 使用CRF表示带有单词标签的句子Fig.1 An example of representing a sentence with its word labels using CRFs
序列词之间的关系通过使用等式(1)中的特征函数{fk}表示。这些关系可以强也可以弱,或者根本不存在,由在训练阶段计算出的权重{θk}控制。
2.1 并行聚合
Lee等[11]提出了一种基于2步结构的RoI提取层,用于目标检测和实例分割,称为GRoIE(通用RoI提取器)。首先对每一层进行预处理,然后将它们聚合在一起,最后应用注意机制作为后处理,以删除无用的全局信息。此外,将GRoIE添加到最先进的2步结构中,用于对象检测和实例分割。实验表明,深层模型的隐藏层可以更多地用于提取区域特定信息。
受文献[11]的启发,本文使用BERT层模块的并行聚合,称为P-SUM,结构如图2所示。由于所有较深层都包含大量有关该任务的信息,通过增加一个BERT层并使用每一层进行预测,把每一层中提取的信息组合在一起,以此来更大限度利用BERT模型的最后4层产生更丰富的语义表示。

图2 并行聚合Fig.2 Parallel aggregation (P-SUM)
2.2 分类聚合
莫凌飞和胡书铭[12]利用深度卷积网络的多尺度金字塔层次结构来构造具有边际额外成本的特征金字塔来识别系统中检测不同尺度目标的基本组成部分,提出了功能金字塔网络,该网络的架构包括一个自底向上的路径、一个自顶向下的路径和横向连接,用于在所有尺度上提取高级语义特征,结构如图3所示。
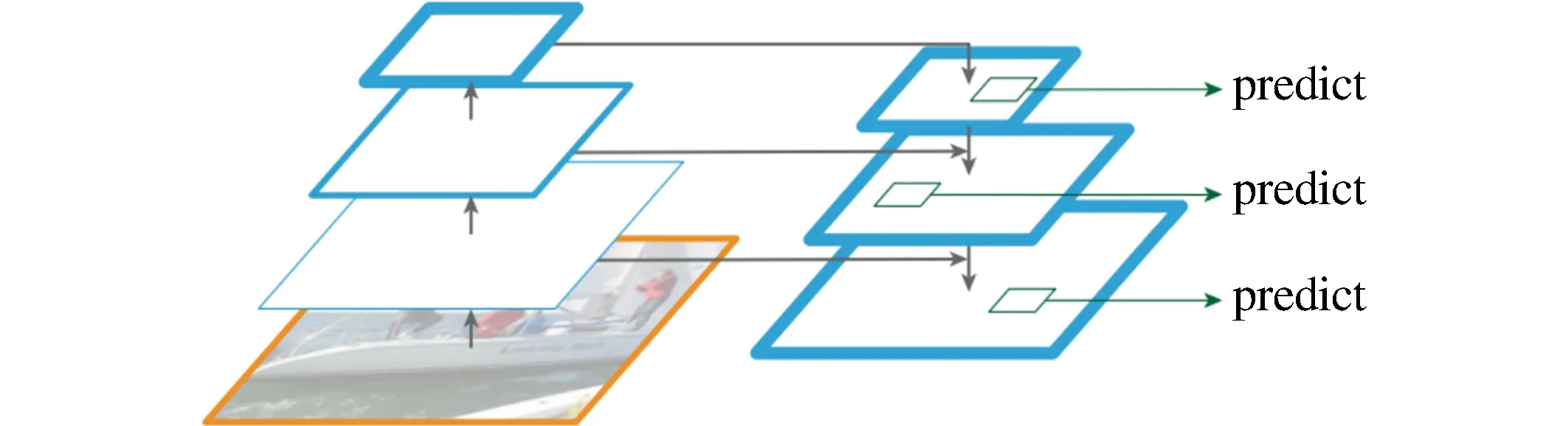
图3 架构方式Fig.3 Architecture mode
受此启发,本文提出分类聚合(H-SUM)模型,体系结构如图4所示。在这里,在每个隐藏层上应用BERT层后,采用自顶向下的架构,在每个层次上独立地进行预测,再将它们与上一层聚合,类似于P-SUM,使用每个输出分支进行预测,然后对它们进行求和进而从BERT模型的隐藏层提取更多语义,以保证模型的准确率。

图4 分类聚合Fig.4 Hierarchical aggregation (H-SUM)
3 实验和结果
模型在16 GB内存的GPU(GeForce RTX 2060)PC机器上进行实验,在Sublime编辑器中编译运行,使用Matplotlib图库绘制图片,以16个批次的模型和BERT-PT模型作为基准。对于训练,使用了Adam优化器,将学习率设置为e-4。从分布式训练数据中,使用150个示例作为验证。为了评估模型,将官方脚本用于AE任务,并将来自同一代码库的脚本用于ASC任务。结果在AE中以F1表示,在ASC中以MF1表示。实验采用了SemEval 2014和2016中的笔记本电脑和餐厅数据集,数据集的统计数据见表1和表2,其中S表示句子数量,A表示方面级数量。

表1 SemEval 2014和2016的AE笔记本电脑(LPT 14)和餐厅(RST 16)数据集Table 1 Laptop (LPT 14) and restaurant (RST 16) datasets from SemEval 2014 and 2016, respectively, for AE

表2 SemEval 2014中针对ASC的笔记本电脑(LPT 14)和餐厅(RST 14)数据集Table 2 Laptop (LPT 14) and restaurant (RST 14) datasets from SemEval 2014 for ASC
3.1 BERT 模型分析
为了更好地对BERT层进行分析,本文针对BERT层的性能以及BERT层的训练时间2个方面的内容进行了实验。
首先针对BERT模型的每一层性能表现进行实验和分析。实验表明,在更深的层中,BERT模型体现出了更好的性能,结果如图5所示。在本文实验环境中,最后4层的精确度更高,所以在P-SUM和H-SUM模型中将其引入。
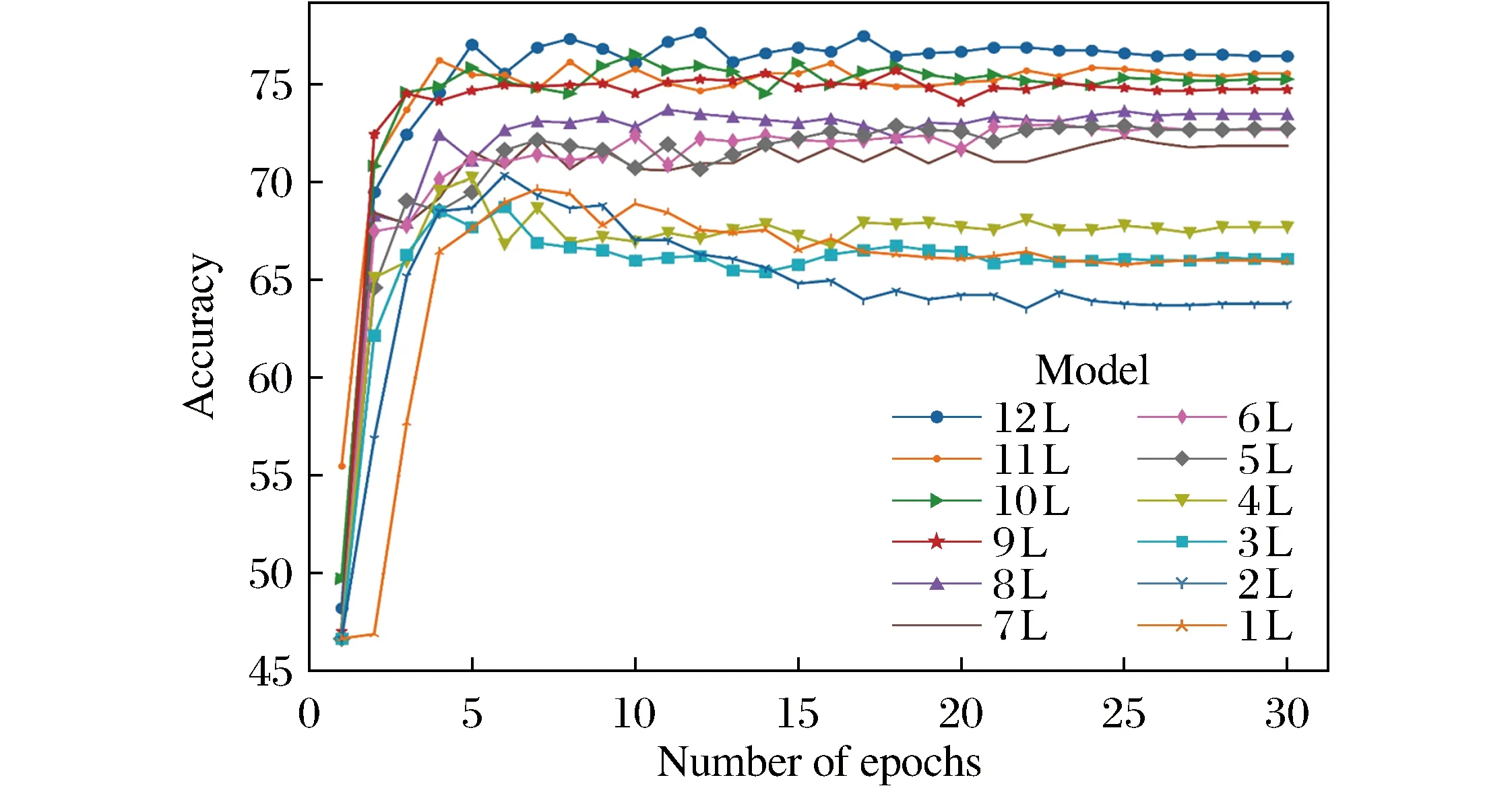
图5 RST 14验证数据上用于ASC的BERT层的性能Fig.5 Performance of BERT layers for ASC on RST 14 validation data
然后针对训练时间,尝试进行更长时间的训练以提高网络的性能。当训练样本的数量少于模型中包含的参数数量时,一味地增加训练时长可能会导致模型过度拟合。在实验过程中,尽管训练数据点的数量相对较少,但在进行更多训练的情况下,模型并不会过拟合。其原因可能是使用了已经过预训练的模型,该模型已经看到了大量数据(Wikipedia和Books Corpus)。因此,预期通过进行更多的训练,该模型仍能够推广。
通过查看图6的损失值,可以得出相同的结果。如果过度拟合,预计损失会上升,性能会下降。但是如图5所示,随着损失的增加,性能会提高。这表明在15~20个周期,随着训练次数的增加,网络权重会不断地变化,在之后保持稳定,表明没有更多的学习。

(a) AE: 笔记本电脑; (b) AE: 餐厅; (c) ASC: 笔记本电脑; (d) ASC: 餐厅图6 BERT-PT对AE和ASC任务的训练和验证损失Fig.6 Training and validation losses of BERT-PT for AE and ASC
3.2 结果与分析
实验结果表明,随着训练时间的增加, BERT模型也得到了改善(表3)。为了与DC-CNN的模型进行比较,本文针对2个模型的特点选择了相同的模型。与BERT-PT和BAT模型基于最低的验证损失选择最佳的模型不同,通过实验观察到验证集的准确性提高之后,本文选择了经过4个时期训练的模型(图5)。表3(BERT-PT*是使用本文模型修改的BERT-PT模型,表中分数均为9次测试的平均值。Acc表示精度,MF1表示Maco-F1)表明了原始的BERT-PT得分以及不同模型选择的得分。与训练30个时长的BERT-PT相比,在除AE(餐厅)以外的所有情况下,所提出的模型在F1和Macro-F1方面级产生了更好的结果。还可以看出,提出的模型在数据集和任务上均胜过BERT-PT模型。
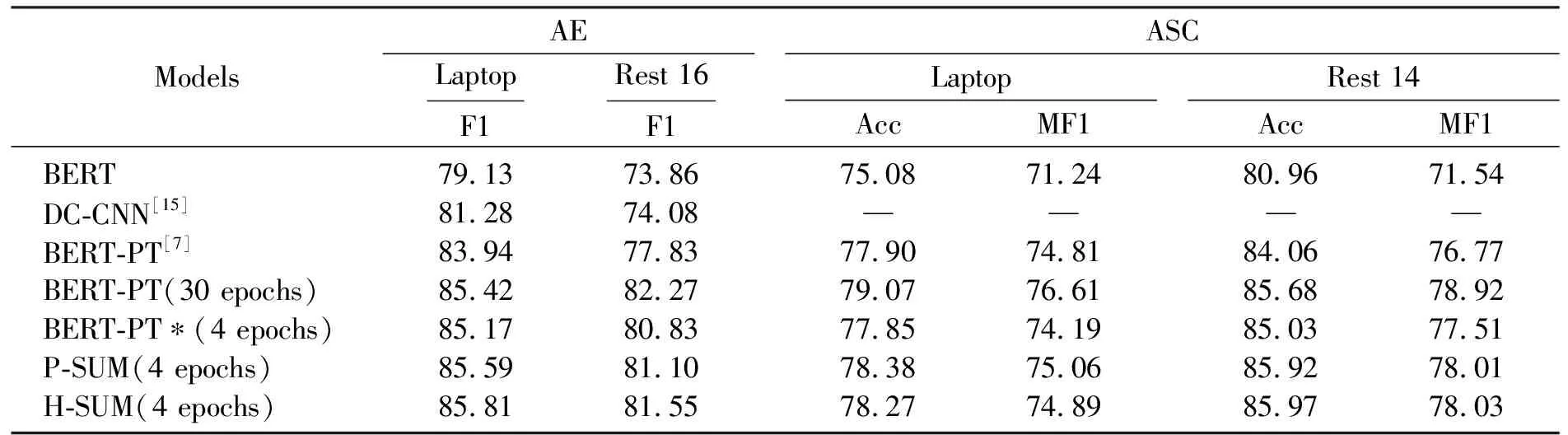
表3 结果比较Table 3 Comparison of results
4 结 语
本文提出了并行聚合和分层聚合2个模块应用于ABSA的2个主要任务,模块利用BERT语言模型的隐藏层来产生输入序列的更深层语义表示,这些层以并行方式进行聚合,并且进行了分类。对选定的每个隐藏层进行预测并计算损失,然后将这些损失求和以产生模型的最终损失。使用条件随机字段解决了方面级提取问题,这有助于考虑序列标签的联合分布以实现更准确的预测。实验表明,所提出的方法优于训练后的普通BERT模型。
猜你喜欢
小猕猴智力画刊(2022年9期)2022-11-04
北京航空航天大学学报(2022年8期)2022-08-31
英语文摘(2020年2期)2020-08-13
开放教育研究(2020年2期)2020-03-31
小哥白尼(趣味科学)(2019年6期)2019-10-10
摄影之友(影像视觉)(2017年1期)2017-07-18
中国修辞(2017年0期)2017-01-31
发明与创新(2016年38期)2016-08-22
太空探索(2016年5期)2016-07-12
长江学术(2016年4期)2016-03-11
