
基于CNN网络的带遮挡车牌识别
2021-03-11 13:06刘靖钰刘德儿陈增辉邹纪伟冀炜臻
测控技术 2021年2期
刘靖钰, 刘德儿, 杨 鹏, 陈增辉, 邹纪伟, 冀炜臻
(江西理工大学 建筑与测绘工程学院,江西 赣州 341000)
近年来,我国车辆数量快速增加,查阅国家统计局数据可知,截止至2017年[1],民用汽车拥有量约20906.7万辆,民用载客汽车拥有量约18469.5万辆,民用载货汽车拥有量约2338.8万辆,其他民用汽车拥有量约124.41万辆。庞大的汽车数量给相关部门的管理带来极大挑战。“智慧城市”是数字城市与物联网结合的产物,是时代发展的趋势。其中,车牌识别技术在智慧交通系统(Intelligent Transportation System,ITS)这一分支中发挥重要的作用[2],主要可用于道路交通监控、交通违章自动记录、交通事故现场勘查、高速公路超速管理、社区智能管理等方面[3]。
车牌识别系统主要由图像采集、车牌定位、字符分割和字符识别这4个部分构成。数据源一般使用监控录像的视频流。车牌定位算法主要有纹理特征定位[4]、颜色特征定位[5]、字符特征定位[6]、边缘检测定位[7]等, 文章岩[8]提出一种基于暗原色先验去雾算法提高雾霾环境下对车牌定位的精度;陈丹[9]采用修正过的检测网络Faster R-CNN对车牌进行定位,提高了车牌定位准确率。字符分割算法主要有投影分割[10]、连通性分割[11]和字符先验知识分割[12]。字符识别的算法有模式匹配[13]、神经网络匹配[14]和特征提取匹配[15],李祥鹏等[16]提出AlexNet-L用于解决字符分割的误差对识别效果的影响,林乾毕[17]使用结合SVM和ANN的神经网络识别车牌;张培玲等[18]提出基于改进BP神经网络算法用于识别夜间的车牌。但以上学者在研究中所用的数据均是在无遮挡条件下的完整车牌,而带遮挡的车牌在视频中也较为常见,如何有针对性地对带遮挡的车牌进行识别是一个难点。
本文主要对行驶过程中车牌上带局部自然遮挡物的车辆进行车牌识别,如泥土、水雾等遮挡情况。车牌定位部分采用HSV特征定位,字符分割时对车牌进行正射校正并利用先验的字符间距进行分割,最后基于卷积神经网络进行字符识别。常见的研究遮挡识别的算法主要着力于视频数据的预处理,尽可能地通过图像处理的方式还原原图以便进行后续识别,算法普适性较差,对任意一类的遮挡都需要有独立的算法进行去噪且耗时较长。本文直接对国内民用车牌中常见的字符建立各种形态并存在不同程度遮挡的样本库,是一种基于数据驱动[19]的识别方法,使其适用于任意情况的局部遮挡,并利用TensorFlow框架进行训练与优化,分析车牌识别的识别准确度,并选用支持向量机[20](Support Vector Machine,SVM)与循环神经网络[21](Recurrent Neural Networks,RNN)进一步验证所构建的样本库的实用性。
1 车牌获取与预处理
在进行车牌识别前,需要获取图像中的有效车牌,具体流程如图1所示。
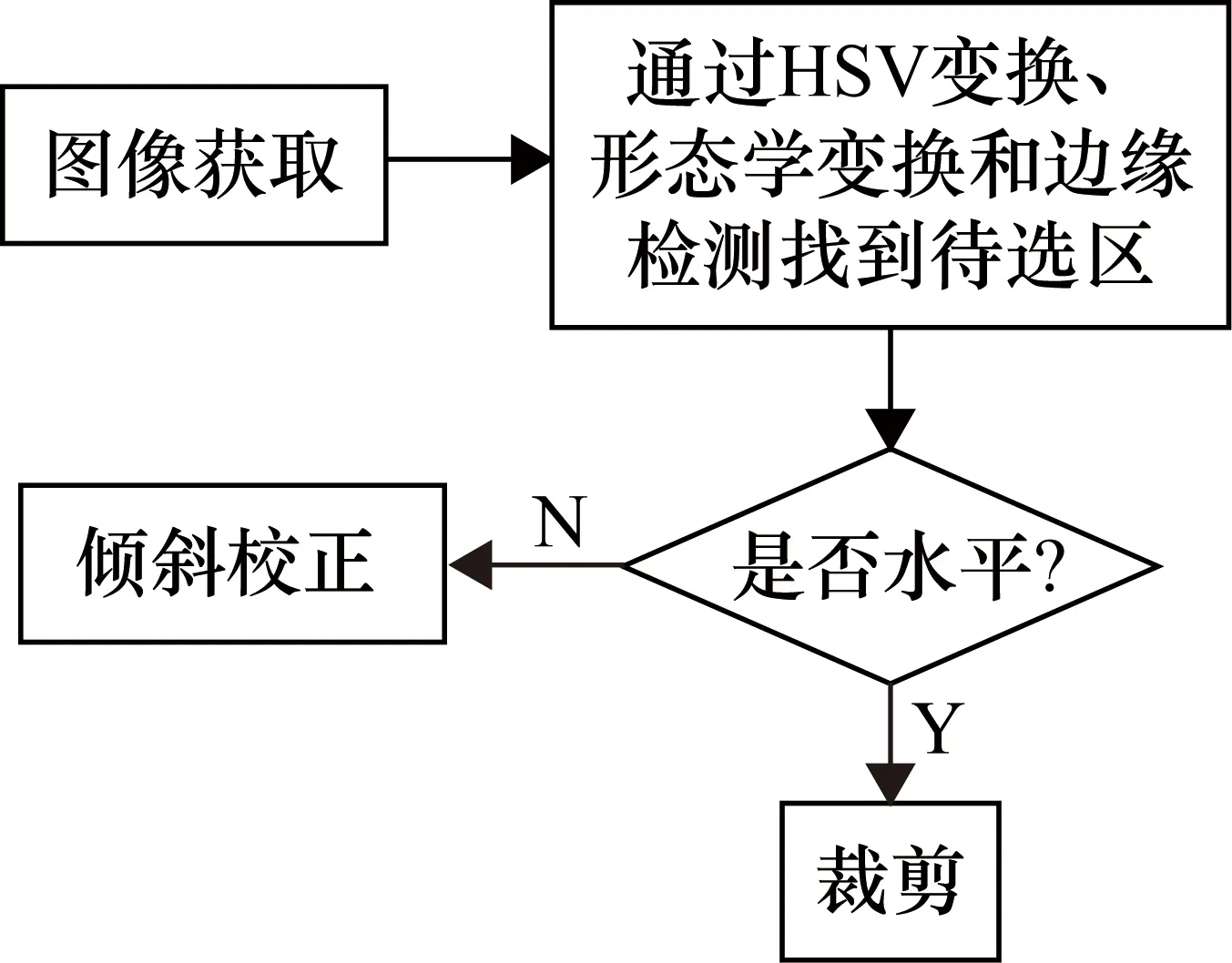
图1 车牌获取流程
1.1 车牌图像预处理
从视频中获取的原始车牌图像处于十分复杂的场景中,若直接对车牌进行定位,噪声干扰较为强烈,耗时长且定位效果较差,尤其对于车牌处存在部分遮挡的情况,更难以精确定位,因而需要先将大部分的非车牌区域去除,以提高识别精度和效率。
将视频中截取的RGB图像转换成HSV模式并单独提取其中的V通道图像,利用限制对比度的自适应直方图均衡化方法获取车牌相对于背景对比度最大的效果,之后利用黑帽运算结果减去顶帽运算结果,即可将V通道的对比度拉伸至一个较好的状态;此时根据边缘检测可以获得图像中所有边缘为矩形的区域,获取图像的blue通道,计算均值等特征,从待选区域确定车牌的位置,如图2所示。

图2 车牌定位
1.2 倾斜车牌的校正
从视频中提取出的车牌不免存在不同角度的倾斜,为避免这种现象对字符切分造成的影响,使用霍夫直线检测(式(1))与仿射变换(式(2))将其校正至正摄状态,如图3所示。

图3 倾斜车牌校正
(1)
式中,ρ,θ为一对霍夫空间的变量,可以通过判定关于ρ,θ的正弦曲线与待检测线条存在的交点个数进行霍夫直线检测。
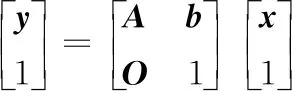
(2)
式中,A为缩放系数;b为平移系数。
经上述流程,处理300张车辆图片共耗时228.6 s,平均耗时0.762 s
2 车牌字符切分
考虑到交通管理的监控设备一般与交通指示灯一起设置在路面正上方,因而所考虑的车牌基本属于正面拍摄,偶尔存在非正面拍摄的情况则通过基于轮廓提取的校正进行旋转等处理使之被拉伸到与正面拍摄一样的视角。此外,当车牌上存在遮挡物时,常用的字符切分方法(如投影法、联通性法)将无法使用,因而选用基于先验知识的切分方式,即通过字符在正常情况下的大小和间距进行切分。通过查阅GA 36-2014[22]可知,常见民用外轮廓为440 mm×140 mm的号牌的具体标准如图4所示。计算出各个字符在整个车牌中所占的比例,对车牌进行分割。分割后的车牌不能直接进行识别,需对其进行归一化处理,将其修改为与训练样本一致的尺寸,如图5所示。随后即可对切分后的字符进行逐个识别。
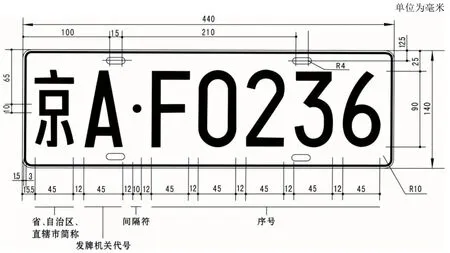
图4 车牌分割标准

图5 车牌分割
3 基于CNN的车牌字符识别
基于神经网络的字符识别具有良好的自适应性和准确度,但是对字符样本库的数量具有较高要求。因此,建立合适的样本库是本次研究的首要任务。
3.1 样本库建立
采用正射投影法获得全国车牌中所有的标准化单个字符信息,主要包括全国33个省、市、自治区的简称、24个大写英文字母(I、O除外)和10个阿拉伯数字。考虑到字符的特性,以及在一般情况下摄像机捕捉图像时可能出现的情况,本文基于形态学算法对字符样本库进行构建。首先将字符归一化为32 px×40 px的矩形,通过小波分析滤去其背景,并对字符进行二值化,背景值设为0,字符值设为1。然后对样本中字符的部分进行旋转、膨胀、腐蚀等操作,在此基础上进行4个方向上不同程度的遮挡,如图6所示。

图6 样本库样例
最终为每类字符构建10000个以上的样本,足以满足CNN训练样本的需求。
3.2 字符识别
神经网络面对复杂的、具有不确定性的、非线性的问题有较好的学习能力、处理能力和分类能力。卷积神经网络(CNN)是一类包含深度卷积计算且具有深度结构的前馈神经网络,一般包含输入层、隐含层和输出层,其中隐含层又包含卷积层、池化层、全连接层等。且CNN隐含层内的卷积核参数共享和层间连接的稀疏性可以使CNN能够以较小的计算量对格点化特征,可对像素进行较好的学习、有稳定的效果且对数据没有额外的工程特征要求。
卷积层原理如下:

(3)
式中,b为偏差量;Zl和Zl+1分别为第l+1层的卷积输入和输出;Ll+1为Zl+1的尺寸;Z(i+j)对应特征图的像素;K为通道数;f为卷积核大小;s0为卷积步长;p为填充层数。
池化层原理如下:
(4)
式中,A(i,j)对应特征图的像素;s0为池化步长;p为预制定参数。
全连接层通常搭建在CNN中隐含层的最后部分,并只向其他全连接层传递信号。特征图在全连接层中会失去三维结构,被展开为向量并通过激励函数传递至下一层,公式如下:
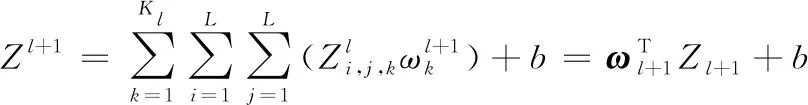
(5)
本文进行识别模型训练时选用Le-Net5模型的框架,隐含层的设置如图7所示,第一层卷积层通过5×5的卷积核提取得到32张原始图片的低层次特征,再通过2×2的池化层对提取到的低层次特征进行特征抽取,第二层卷积层通过5×5的卷积核提取到64张池化后的高层次特征,再通过2×2的池化层和两层全连接层实现图像特征的输出,最终调用激活函数SoftMax()进行非线性拟合,得到多分类的输出。
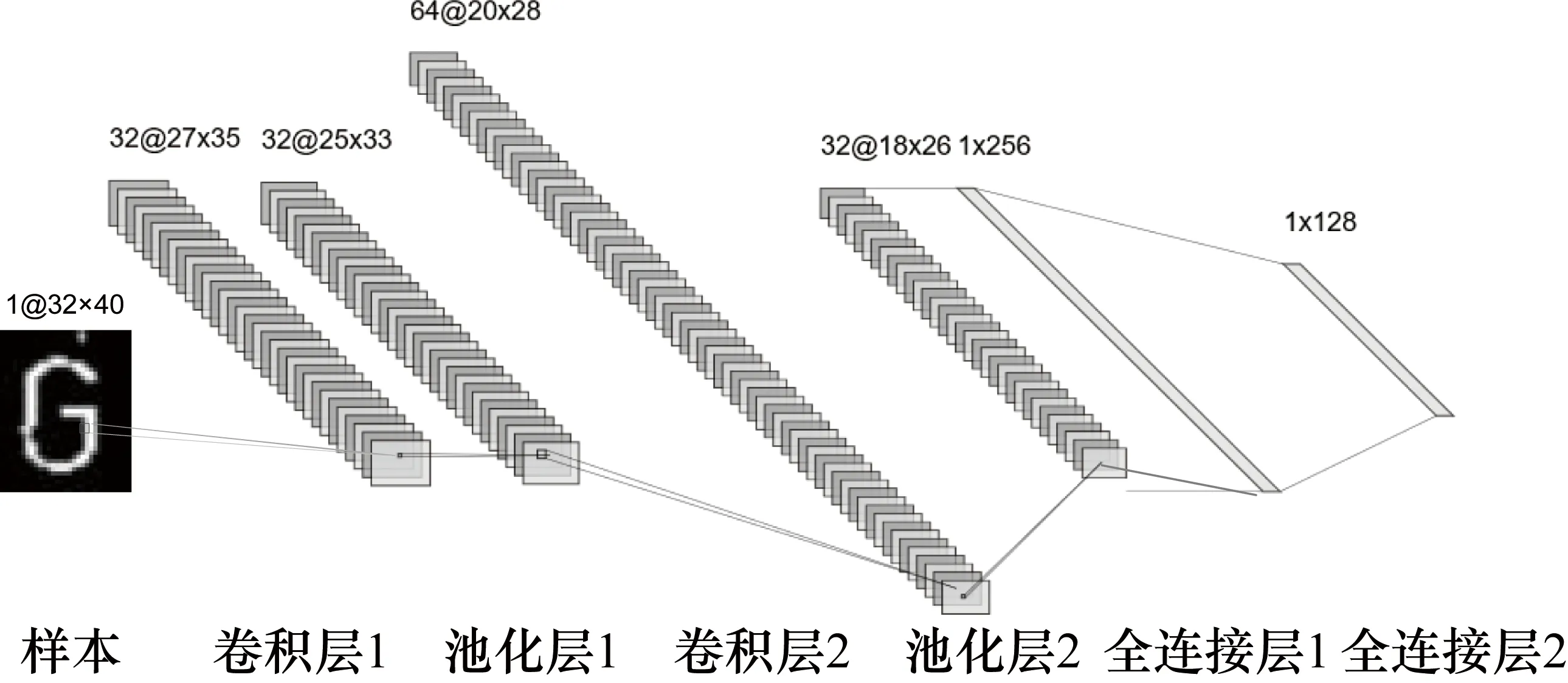
图7 网络结构
对待检测车牌数据进行阈值分割并将切割后的单字符图片长宽归一化至32 px×40 px,进行批量识别测试。
4 测试结果及分析
通过形态学算法构建的样本库主要分为汉字、字母和数字三大类,其中每一个字符通过不同形态、旋转角度、遮挡情况等共构造出10240个样本,随机取其90%作为训练集,其余为测试集。训练框架为TensorFlow1.4,将训练集转存为tfrecord类型以节约内存、统一格式并提高计算效率,通过CNN对样本进行训练与测试,最后实现对车牌的识别。实验设置卷积层池化层各两层,最终通过两层全连接层实现特征输出。具体参数设置:学习率为0.8,学习率的衰减率为0.99,损失函数系数为0.001,每一批次训练128张图片,训练至3200步时趋于收敛,精度为99.978%。同时使用上述网络训练无遮挡的字符样本,每类6542张图片,并对比不同样本库对识别效果的影响,如表1所示。

表1 测试结果
分析可知,当字符受到不同程度的遮挡时,识别精度会存在较大的差异。对于车牌中未受到任何遮挡的字符,总体识别精度可达到0.87以上,部分特征十分鲜明与别的字符不存在相互干扰的字符识别正确率可达0.95以上,但是车牌2中的“沪”由于进行二值化处理时没有自适应存在部分特征缺失,精度仅有0.74;对于遮挡面积占字符总面积1/12~1/6之间的字符,如车牌1中的“8”,其识别精度可以达到0.89以上;对于遮挡面积占字符总面积1/4左右的字符,如车牌2中的“0”、车牌3中的“苏”,识别精度在0.75以上;对于遮挡面积占字符总面积1/3左右的字符,如车牌2中的“J”和“9”,由于遮挡部分横跨字符中央,特征缺失较为严重,识别精度约在0.59以上,其中字符“9”在识别时会受到字符“2”“8”“G”等的强烈干扰,识别精度更低;当遮挡面积占总字符面积1/2以上时,识别精度持续下降,如车牌3中的字符 “3”,由于保留的有效特征具有其独特性,识别精度为0.81,效果较好,但是字符“E”和“B”识别精度仅为0.33和0.41。此外通过与无遮挡样本识别效果的对比发现,无遮挡样本在识别无遮挡字符时的精度维持在90%左右,比起带遮挡样本的识别精度较稳定,但两者的正确率相差无几,可能是样本量较大导致略微过拟合;但在存在遮挡的字符识别中,带遮挡样本库的识别效果明显优于无遮挡样本库的识别效果,如在车牌3的字符4“B”的识别上,虽然无遮挡样本库的识别精度更高,但是识别错误,除此之外有遮挡样本库的识别精度在对存在遮挡的字符进行识别时明显更高,表明该样本库的建立是有意义的。
因此本文通过形态学等算法建立的样本库适用于单字符遮挡面积在1/2以下的车牌识别,对于遮挡面积过大、失去了鲜明特征的字符,识别效果不太理想。
选取300张存在遮挡情况的车牌,经字符分割,共有汉字300个、字母及数字1800个,根据其存在的遮挡情况进行测试并统计,总体识别精度如表2所示。
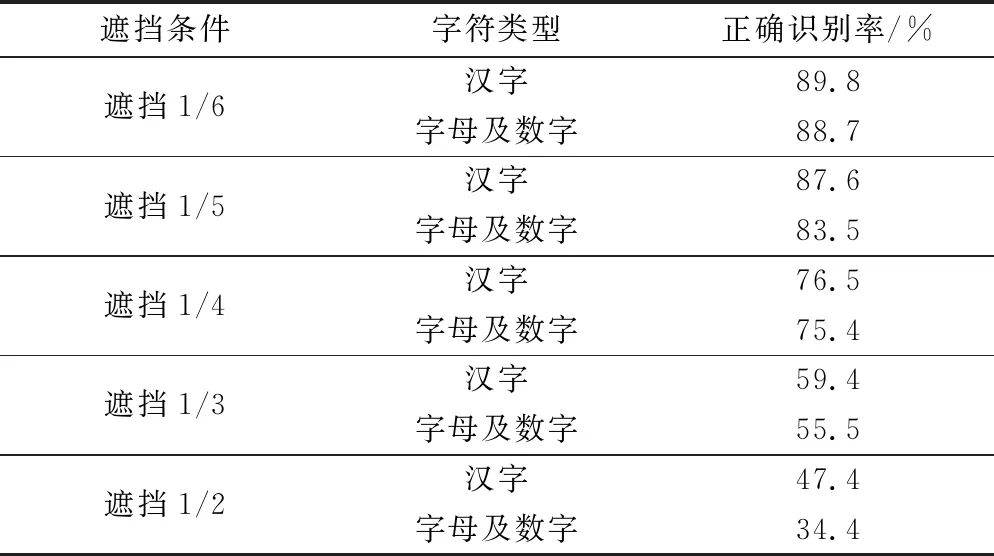
表2 不同遮挡条件下的正确识别率
为证明通过形态学所建立的带遮挡车牌字符样本库在车牌识别中比无遮挡样本库更有优势,选取SVM和RNN进行验证,以准确率和平均精度作为分析指标,验证结果如表3所示。
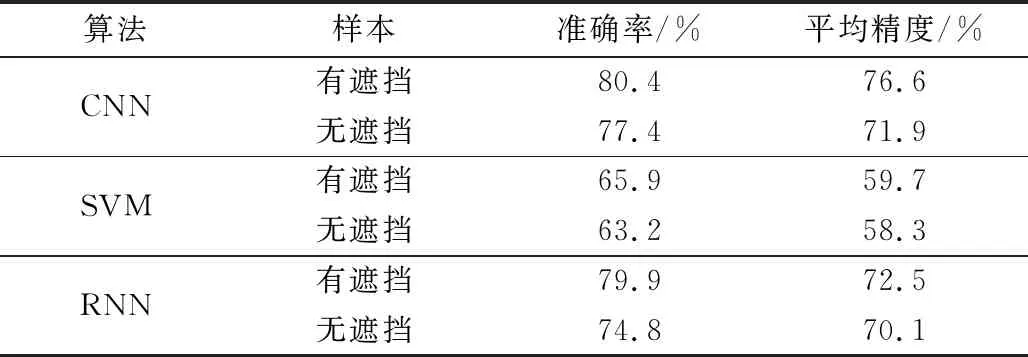
表3 不同算法中不同样本的识别情况
分析可知,在任何算法中,使用有遮挡样本的训练集去识别车牌时,准确率和平均精度相比于无遮挡样本都更高,更具实用性。
5 结论与展望
本文通过视频截帧的方式获得车辆图像,随后利用限制对比度的自适应直方图均衡化方法大致确定车牌在图片中的位置,再采取形态学等方案确定车牌的详细边界以实现车牌定位;借用霍夫直线检测对车牌进行校正,以便对其进行精准的分割。裁取完整车牌中的67个字符,按一定的规律加入不同程度的遮挡;对需要进行识别的车牌随机加入高斯滤波并计算其遮挡比例。对模型训练调参后可得出在不同遮挡程度下字符识别的准确性,通过与同一网络中训练得到无遮挡样本库的识别效果进行对比,发现带遮挡样本库精度更高,此外使用SVM与RNN对两种样本的精度进行验证。另外通过对车牌不同遮挡情况进行对比,可知带遮挡样本库可用于遮挡程度在1/2以下的车牌图片识别。
由于实验训练集测试数量不足,理应对算法做进一步的改进与优化,可以从网络结构、参数优化等方面进行后续研究。
猜你喜欢
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年12期)2019-07-16
数字通信世界(2019年3期)2019-04-19
成都信息工程大学学报(2017年3期)2017-11-09
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
