
大数据时代存储相关技术研究(二)*
2021-03-11 08:32:06冯丹
智能物联技术 2021年1期
内容提要:
3 新型非易失存储器
新型非易失存储器具有低延迟、高密度和非易失的特性,速度也接近DRAM,但技术尚未成熟,大部分还是处于研究阶段。 从目前发展趋势来看,有两大阵营:一种是代替当前的DRAM 和FLASH,在传统的冯·诺依曼体系下的SCM (Storage Class Memory);另一种是非冯·诺依曼体系下的,既可以做存储,又可以在原位进行计算,即存算一体或存算融合,如将人工智能或图像处理的算法等融合进去。
3.1 磁阻存储器
由于相变存储器PCM 和电阻式存储器RRAM都可以看作是忆阻器,因此可以用来做存储,也可以做存算一体,这两条路径一直都在向前发展。 磁阻存储器的发展历程如图7 所示。

图7 磁阻存储器的发展历程Figure 7 Development history of magnetoresistive memory
磁阻存储器主要包括传统的MRAM 和自旋转移矩MRAM(STT-MRAM)。 传统的MRAM 通过电流流过产生磁场改变MTJ (Magnetic Tunnel Junction)中的自由层磁矩方向,其特点是结构复杂、干扰大。 STT-MRAM 是第二代MRAM 技术,通过自旋电流实现自由层磁矩方向的改变。 美国的Everspin 公司一直是MRAM 产品的领导者, 已推出了多款独立式和嵌入式MRAM 存储器,并于2020 年发布了28nm 单片1Gb STT-MRAM 芯片。
3.1.1 磁阻存储器研究现状
目前有关磁阻存储器的研究比较丰富,主要包括以下几方面:
单元、 阵列级别的研究:22nm,32 2Mb eSTTRAM 设计,低延迟高寿命,并对磁场干扰免疫;3D扩展,3D1S1R 结构; 将FinFET (鳍式场效应晶体管,Fin Field-Effect Transistor) 和STT-RAM 集成,用于降低系统的延迟和面积。
可靠性方面的研究:Last Level Cache(LLC),破坏读问题,延迟恢复机制;STT-MRAM based FPGA,干扰感知内存分组; 两个MLC 存储3 位的数提升可靠性和性能。
MLC 单元优化的研究:采用MLC 的两位组成快慢区域;采用数据编码,最小两步状态转换提升MLC 寿命和性能;对MLC 硬位和软位分别编码减少两步写能耗; 对MLC 进行编码, 实现一次写操作,从而提升寿命和能效。
应用于GPU 的研究: 将STT-RAM 用于GPU中的L1 Cache,减少片外访问,提升性能和能效;将STT-RAM 用于GPU 的寄存器文件,采用压缩方法减少能耗。
存内计算架构的研究:将SOT-MRAM((Spin-Orbit Torque MRAM))应用于存内计算架构设计以提升性能。
3.1.2 MLC STT-RAM 的研究
我们也对MLC STT-RAM 进行了研究。 由于它是通过堆叠两个不同大小的MTJ 单元构成MLC STT-RAM 单元,相较于SLC 单元,密度约是其2 倍,需要采用两步读写操作,对硬位的写操作会延迟和消耗更多的时间, 对性能和能耗都会产生影响。
同时,我们发现MLC STT-RAM 存在较严重的寿命问题(<1010次),这也是两步写操作导致的,两步写操作同时导致了大量的写能耗和较高的写延迟。 测试发现, 对硬位的写对寿命的影响达到了70%,而软位则只有30%①Wei Zhao, Wei Tong, Dan Feng,et al.OSwrite∶Improving the lifetime of MLC STT-RAM with One-Step write[C]// 36th International Conference on Massive Storage Systems and Technology.MSST,2020.。
针对此问题, 我们的基本思路是通过负载分析,用压缩的方法将缓存行全部写到软行,实现一步写操作;而对不能压缩的行,用hard flag 记录硬位翻转信息,实现一步写操作。 通过内存负载测试发现, 该方案可以提高2.6 倍的寿命, 减少能耗56.2%,提升性能6.4%④。
3.2 相变存储器
相变存储器简称PCM, 它是利用特殊材料在晶态和非晶态之间相互转化时所表现出来的导电性差异来存储数据。如图8 所示为相变存储的发展历程。

图8 相变存储器的发展历程Figure 8 Development history of phase change memory
因为从晶态到非晶态和从非晶态到晶态,对操作时间和温度的要求不一样, 所以它的特点是:RESTE 延迟低,但功耗比较高;SET 过程延迟高,但功耗比较低。 相应地,相变存储器需要在功耗和延迟方面进行优化。
现在比较成熟的一款产品是Intel 和镁光合作的3D XPoint 相变存储器, 它运用的是双层架构。Intel 公司比较看好这款产品是因为它密度比较高。同样芯片体积,3DXPoint 相变存储器的存储容量是DRAM 的8~10 倍,而能耗基本相当。
3.2.1 相变存储器操作方案研究现状
有关相变存储器的研究主要有以下几个方面:
存储单元读/写操作可靠性问题研究。 针对晶格结构松弛引起的阻值状态漂移导致读不准,采取适应数据保持时间的动态读阈值参考设置及单元状态刷新;针对非线性的电流电压特性曲线导致读不准,采取两步读操作扩大读窗口;针对焦耳热干扰导致RESET 操作过程中相邻单元状态出错,设置单元间热量屏障层,并通过数据编码来减少容易产生热干扰的数据模式;对角单元布局结合数据压缩;通过数据压缩将要写入的单元位置交替地分布在一行的两端。
PCM 作主存时,对其寿命和性能优化的研究。主要包括:减少热区数据写延迟,减少set 操作;通过减少PCM 阵列的互联电阻,减少延迟。
大数据、人工智能计算环境下的存储墙问题研究。 主要是构建存算融合的计算内存,并发掘新应用,根据应用特征进行优化,包括:16.5 万个相变存储单元构成阵列做神经形态计算;相变存储单元做时间相关性检测;相变存储阵列做科学计算;相变存储器用于存内超维计算等。
3.2.2 我们对相变存储器的相关研究
我们对相变存储器的研究主要是通过压缩编码方式提升其寿命和性能。
(1)利用冗余字提升标志位的利用率
因为CPU 以字为单位进行写, 因此可能会写入相同的数据,造成相变存储器负载中存在大量冗余字。 如当缓存行中有4 个冗余字时,编码标志位的利用率只有50%②Xu J, Feng D, Hua Y, et al. Adaptive Granularity Encoding for Energy-efficient Non-Volatile Main Memory[C]// 2019 56th ACM/IEEE Design Automation Conference (DAC). IEEE, 2019.。为了提升标志位利用率,我们将编码标志位分配给脏的字, 编码粒度从16 降为8。 但标志位利用率提升到100%,导致标志位的位翻转增加。我们又利用了连续位翻转特性减少位翻转(SAE),对每一行进行分析,选择位翻转总数最少对应的编码粒度,对缓存行进行编码,以此降低功耗和提高写速度。
(2)非易失内存系统需要保持原子一致性
存储过程中, 存储控制器需要软件和硬件配合,如果配合不好会出现一致性问题。在事务中,对同一地址的写操作存在不同写间隔分布, 其中44.8%的写距离超过31,而写距离太长会导致部分日志数据不能被丢弃。分析发现,事务更新时,日志数据中存在大量的干净字节数据,70.5%的字节都是干净的。 由于一致性维护开销非常大,所以应区别对待,不对70.5%的干净字节数据进行一致性维护。 具体来说,我们设置了日志数据选择性编码机制, 该机制对事务中数据的第一次更新同时记录undo 和redo 数据,后续更新只记录redo 数据。undo数据及时写入NVMM 以保证原子性,而redo 数据则缓冲在易失性日志缓冲区和L1 缓存中, 只将最新的redo 数据写入NVMM 中。 利用日志数据的特点,该方法直接丢弃日志数据中的干净位,压缩剩余的脏位。 经实验验证, 此方案使写能耗降低了49.9%,性能提升了72.5%③X Wei,D Feng,W Tong,J Liu,et al. MorLog∶Morphable Hardware Logging for Atomic Persistence in Non-Volatile Main Memory[C]// 47th edition of ISCA. ISCA,2020.。
3.3 阻变存储器
二端无源金属氧化物阻变存储器(metal-oxide RRAM)是忆阻器的一种器件实现,是一种新兴的非易失存储器。它是通过金属氧化物的阻值状态变化来实现数据存储。 主流的阻变功能材料包括HfOx、TiOx、TaOx 等, 配套的电极材料包括TiN、Pt和Ti 等。 施加外加电压时, 其阻值会发生连续变化,因此忆阻器可以用作存储,也可以用作计算,如IMP 逻辑运算和矩阵向量乘法。阻变存储器的发展历程如图9 所示。

图9 阻变存储器发展历程Figure 9 Development history of resistive random access memory
国际上,富士通、松下、Crossbar 公司和密歇根大学都推出了一些小容量和实验性的阻变存储器产品。
3.3.1 阻变存储器操作方案研究现状
主要包括以下几个方面:
第一,非理想因素影响下存储阵列读写操作不可靠、性能差问题的研究。 针对互连线电压降导致写操作性能差,可采用双端接地、双端写驱动器、最短电压降路径等;针对部分偏压导致未选择的单元受干扰,可设置干扰参考单元、检测并刷新被干扰的行等;针对潜通电流导致读操作不准确,可采用四端电阻网络、检测并复用潜通电流和采用互补阻变单元等。
第二, 非理想因素影响下存储阵列计算不准确、能效低问题的研究。针对互连线电压降、器件变化性、环境温度导致计算不准确,可采用互连线奇异值分解数据降维、逻辑行到物理行映射等;针对互连线电压降、潜通电流导致计算能效低,采用三维阵列缩短平均互连长度等。
第三,基于阻变存储器加乘运算的灵活而通用的存算融合体系结构的研究。 如可重配架构、原位模拟运算加速器等。
3.3.2 我们对阻变存储器的相关研究
我们对阻变存储器的研究主要集中在忆阻器存内计算方面, 主要是面向人工智能的算法需求,实现了贝叶斯算法映射。
忆阻器可以用做近似计算单元,实现矩阵向量乘法④Prezioso M, Merrikh-Bayat F, Hoskins B D, et al. Training and operation of an integrated neuromorphic network based on metal-oxide memristors[J]. Nature,2015,521(7550)∶61-4.,将算法复杂度从O(n2)转换为O(1),即不需要原来的平方运算,只需要施加电压和读取电流即可完成矩阵运算。 如进行图像处理时,即可以利用此算法。而传统的矩阵运算方法,要做乘加运算,需要进行数模转换,会导致接口面积大(>30%)和延迟高(>50ns)的问题。 也有学者采用二进制接口方式,虽使接口代价减小,但数值展开消耗了更多忆阻器单元和阵列资源。
而我们所做的就是将外围电路简化以及将贝叶斯算法映射到矩阵上面。 即针对ADCs 和复杂外围电路会极大增加存内计算架构开销的问题,第一次引入朴素贝叶斯算法在存内计算架构中实现:利用现有存内计算架构兼容实现算法;针对性优化算法映射,消除ADCs 庞大的开销⑤Wu B, Feng D, Tong W, et al. ReRAM Crossbar-Based Analog Computing Architecture for Naive Bayesian Engine [C]// 2019 IEEE 37th International Conference on Computer Design (ICCD). IEEE, 2019.。
朴素贝叶斯算法是连续的乘法,我们对朴素贝叶斯公式施加了-log 函数,将连续乘法转换为点乘操作,这样就可以在阵列位线上实现,且数值为正,可直接由ReRAM 电导映射。
针对最小探测模块, 传统的方式是将其转换为数字信号之后再进行比较。 但我们发现可以直接进行模拟并行比较,因此我们设计了外围电路,通过二分探测和递增探测,直到找到最小值,即参考电压Vref同所有位线结果进行模拟量比较,通过比较结果是否形成独热码(one-hot code)来完成最小探测。
我们也对基于ReRAM 的朴素贝叶斯算法引擎的识别准确度进行了测试。 实验验证发现,现有CPU 软件实现、理想设备参数下的朴素贝叶斯算法引擎、 真实设备参数下的朴素贝叶斯算法引擎、PRIME 架构兼容实现方式下的算法识别准确度分别为89.6%,87.5%,88.2%和87.8%。 可以看出,真实设备参数下的朴素贝叶斯算法引擎的精度88.2%和软件实现的精度89.6%非常接近。 由于人工智能算法并不需要非常精确,只需要确保判断结果准确即可, 因此该算法方案是可以实际使用的。且相比软件实现来说, 其实现速度提高了11.2~2289.6 倍。⑧
4 面向NVM 的文件系统
新的存储器件出现之后,现有文件系统往往是与其不匹配的。新型NVM(Non-volatile Memory)引发了存储体系结构的变革,如微软推出了BPFS 文件系统, 英特尔推出了PMFS 文件系统,UCSD(University of California San Diego) 推出了NOVA和Moneta-D 文件系统,清华大学推出了HiNFS 文件系统, 华中科技大学则推出了Object-based NVM Management 文件系统, 以适合NVM 的特性和调度方式。
4.1 传统文件系统迁移到NVM 的问题及研究现状
4.1.1 传统文件系统迁移到NVM 的问题
当Intel Optane DC PMM (Persistent Memory Module)出现后,我们也对其进行了测试,发现它的效率达不到其标注数值,原因是没有针对其架构对文件系统进行优化。 基于新型NVM 的存储系统相对于传统磁盘存储系统的如下特点,导致传统文件系统迁移到新型NVM 存在一系列问题。
(1)I/O 瓶颈转移
分析发现数据I/O 路径上各阶段的开销比例产生了巨大的变化,软件开销开始变得不可忽略。
(2)数据一致性层次转移
传统结构中, 数据易失和非易失分界线在DRAM 和外存之间;而NVM 主存中,数据易失和非易失分界线在CPU Cache 和NVM 之间。 因此,需要专门的CPU Cache 指令以及额外硬件原语来保证数据的一致性。
(3)有限的写入耐久性
传统的存储I/O 栈系统软件主要是针对磁盘设计的。若直接将这种针对磁盘存储的系统软件应用于NVM 存储系统, 则会导致NVM 存储设备的快速磨损。
4.1.2 基于NVM 的文件系统研究现状
(1)NVM 作为内存设备,利用传统VFS 路径的文件系统
如对SCMFS 文件系统,如果无一致性、磨损均衡保障,TLB(Translation Lookaside Buffer)失效率高;对PMFS 文件系统,使用线性表管理目录,目前性能不如传统文件系统; 对NOVA 文件系统,DRAM 和NVM 混合日志结构文件系统没能完全体现NVM 支持XIP(eXecute In Place)的特性,过于依赖DRAM 管理元数据和数据块索引。
(2)用户库方式直接访问NVM
包括基于SCM 的灵活文件系统接口; 对操作系统编译程序、应用程序均做修改; Quill 仍需进入内核态,依赖于POSIX 文件系统接口。
4.2 我们对面向NVM 文件系统的相关研究
4.2.1 混合存储文件系统NOCFS:NVM+Flash
即文件系统中的大量数据使用Flash 存储,而元数据使用NVM 进行存储,系统架构如图10 所示。

图10 混合存储文件系统NOCFS 架构Figure 10 NOCFS architecture of hybrid storage file system
主要工作包括:
第一,NVM 和SSD 混合空间。文件系统直接管理NVM,NVM 存放元数据,缓存热数据。
第二,并行感知的数据同步机制,即多线程异步写回。
第三,协作式垃圾回收。 文件系统层垃圾回收与LightNVM 垃圾回收结合。
对NOCFS 性能进行测评, 采用较小容量的NVM,可以使闪存性能提升5 倍,接近于全NVM,与PMFS 文件系统性能相当。
4.2.2 基于对象的NVM 管理器
不同NVM 存储介质读写性能差别较大,特性各异。 对象管理的思想就是把对NVM 的管理从文件系统中分离,以更低的管理开销实现更加丰富的应用接口,以充分发挥不同存储介质的优势。 存储应用可绕过文件系统直接访问NVM 对象接口,精简访问路径。 如图11 所示为传统文件系统和面向对象的文件系统对比。

图11 传统文件系统和基于对象的文件系统对比Figure 11 Comparison of traditional file system and object-based file system
OBFS (Object-Based File System) 绕过VFS(Virtual File-system Switch)层,缩短了层次或路径,实现了一个精简的名字空间管理,保证其兼容性,直接截获应用的文件访问系统调用,实现对上层应用透明。 OBFS 由此消除了传统基于磁盘的文件系统中很多不必要的开销,提高了系统性能。
基于NVM 的轻量级存储系统与传统存储系统相比,明显缩短了I/O 路径,能快速响应应用请求,读写性能优于PMFS。 与基于新型非易失内存文件系统NOVA、PMFS 相比,OBFS 可以获得20%~30%的性能优势。 与RAMFS 相比,OBFS 的读性能比RAMFS 性能好, 但写性能比RAMFS 的性能要差一些。
5 分布式存储技术
5.1 软件定义存储
软件定义存储是借鉴软件定义网络的思路,即将存储的管理和调配与底层物理硬件分开,所有存储相关的控制工作都仅在相对于物理存储硬件的外部软件中,用户可以通过软件控制资源并对其进行优化。 相关研究主要如下。
5.1.1 解决路径过长带来的挑战
IOFlow 作为学术界第一篇关于软件定义存储的文章, 借鉴OpenFlow 在存储环境中将控制平面和数据平面进行分离, 在IO 栈的不同层次使用队列对请求进行限流,比如在hypervisor 里面的SMBc 和存储服务器端的SMBs,保障虚拟机端到端的性能。⑥Thereska E, Ballani H, O'Shea G, et al. IOFlow∶A software-defined storage architecture[C]// Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles. SOSP, 2013.
Moirai 提出了一种协同不同层次的cache 进行资源管理的方法,既能够最大化利用系统资源,还能有效对不同租户间进行性能隔离, 避免性能干扰。⑦Ioan Stefanovici,Eno Thereska,Greg O'Shea,et al.Software-defined caching∶managing caches in multi-tenant data centers[C]//Proceedings of the Sixth ACM Symposium on Cloud Computing. SoCC, 2015.
sRoute 把路由概念引入了存储栈, 把IO 栈的各个层次当作网络中的一个个路由器,能够根据不同的应用制定路由策略, 使得IO 请求能够在不同IO 层之间转发。⑧Stefanovici, Ioan,Schroeder, Bianca,O'Shea, Greg, et al.Treating the Storage Stack Like a Network[C]// Proceedings of the 14th Usenix Conference on File and Storage Technologie. FAST, 2016.
5.1.2 解决资源管理的挑战
即解决分布式系统内资源多样化(CPU、存储、锁等)以及任务多样化(租户产生的任务、系统产生的任务等)给资源管理带来的挑战。 如Retro 应用于分布式环境,通过策略和机制的分离,能够保障系统内所有IO 任务的SLO (Service Level Objectives),比如租户的性能需求,或者是心跳信息的延迟保障等。⑨Mace J, Peter Bodík, Fonseca R, et al. Retro∶Targeted Resource Management in Multi-tenant Distributed Systems [C]// Usenix Conference on Networked Systems Design & Implementation. NSDI, 2015.
5.1.3 解决租户需求多样化带来的挑战
Crystal 是一种应用于对象存储的软件定义存储架构, 在数据平面可以通过插入不同的filter 来提供不同的服务(压缩、加密等),设计可扩展的数据平面能够使得Crystal 具有更丰富的功能。⑩Raúl Gracia-Tinedo, Josep Sampé, Zamora E, et al. Crystal∶Software-Defined Storage for Multi-Tenant Object Stores[C]// 15th USENIX Conference on File and Storage Technologies (FAST'17).FAST, 2017.
5.2 网内计算
随着可编程交换机的兴起,使用网络的计算及存储资源来优化存储系统性能成为趋势。Eris 提出在可编程交换机内进行并发控制,保障事务操作的有序性和一致性,降低存储系统维护一致性带来的开销,优化系统性能。⑪Li J,Michael E,Ports D R K . Eris∶Coordination-Free Consistent Transactions Using In-Network Concurrency Control [C]// Proceedings of the 26th Symposium on Operating Systems Principles. SOSP,2017.
NetCache 通过在可编程交换机内做缓存,实现一种新的KV 存储架构,利用交换机内的存储资源优化存储系统性能。⑫Jin X,Li X,Zhang H,et al. NetCache∶Balancing Key-Value Stores with Fast In-Network Caching [C]// Proceedings of the 26th Symposium on Operating Systems Principles.SOSP,2017.
我们也做了一些工作。 考虑到对服务器来说,只能根据上一个时刻状态判断是轻负载还是重负载,然后明确是否进行副本服务;副本放在很多个服务器当中,如果都去访问一个空闲服务器,会出现羊群效应,使该服务器出现重负载。 但与服务器只能根据过去状态判断负载的状况不同,交换机非常清楚服务器负载,可根据当前数据包数量判断服务器负载状况,判断也会更加准确。 因此,NetRS 通过在可编程交换机内进行副本选择,有效降低应用响应延迟。⑬Jin X,Li X,Zhang H,et al. NetCache∶Balancing Key-Value Stores with Fast In-Network Caching [C]// Proceedings of the 26th Symposium on Operating Systems Principles.SOSP,2017.
5.3 高可靠性
我们对存储可靠性做了两方面的研究。
5.3.1 对编码的研究
在网络环境下,如果有节点坏掉或者不能访问时,需要把数据从其他节点算回来,如果有节点访问拥塞或链接不上,就得不到数据。在这种情况下,我们希望用少量节点就能将数据算回来,因此我们的主要思想是将节点上的数据分割为更多的数据块,通过合理组合数据块,实现最优修复。 具体来说,我们提出具有最优存储和最优重建数据量的编码方法Z 码。 Z 码的参数n 和k 选择灵活,码率可以任意大;它并非MDS 码(Maximum Distance Separable code), 但可以扩展为GZ 码且具有MDS 性质,且具有最小存储下的最优修复开销。 对同样的4 个节点来说, 对RS 码需要3 个节点将数据算回来,RRS 码平均需要2.3 个节点, 而Z 码只需要2个节点。 测试表明,Z/GZ 码和最小存储再生码FMSR 和PM-MSR 具有相同的存储开销和修复开销,但参数更灵活,且是系统码。⑭Liu Q, Feng D, Jiangy H, et al. Z Codes∶General Systematic Erasure Codes with Optimal Repair Bandwidth and Storage for Distributed Storage Systems[C]// Proceedings of the 2015 IEEE 34th Symposium on Reliable Distributed Systems. SRDS,2015∶212-217.
5.3.2 硬盘故障预警技术
硬盘故障预警技术就是在节点坏之前进行故障预警。 我们收集了惠普和微软的坏盘数据集,然后进行离线建模,具体包括数据预处理、特征选取、训练建模和参数调优。具体流程如图12 所示。在线预测时,首先进行模型导入,包括导入特征选取映射、归一化参数以及模型参数;实时预测包括解析请求、过滤特征,然后估算预测的准确度。
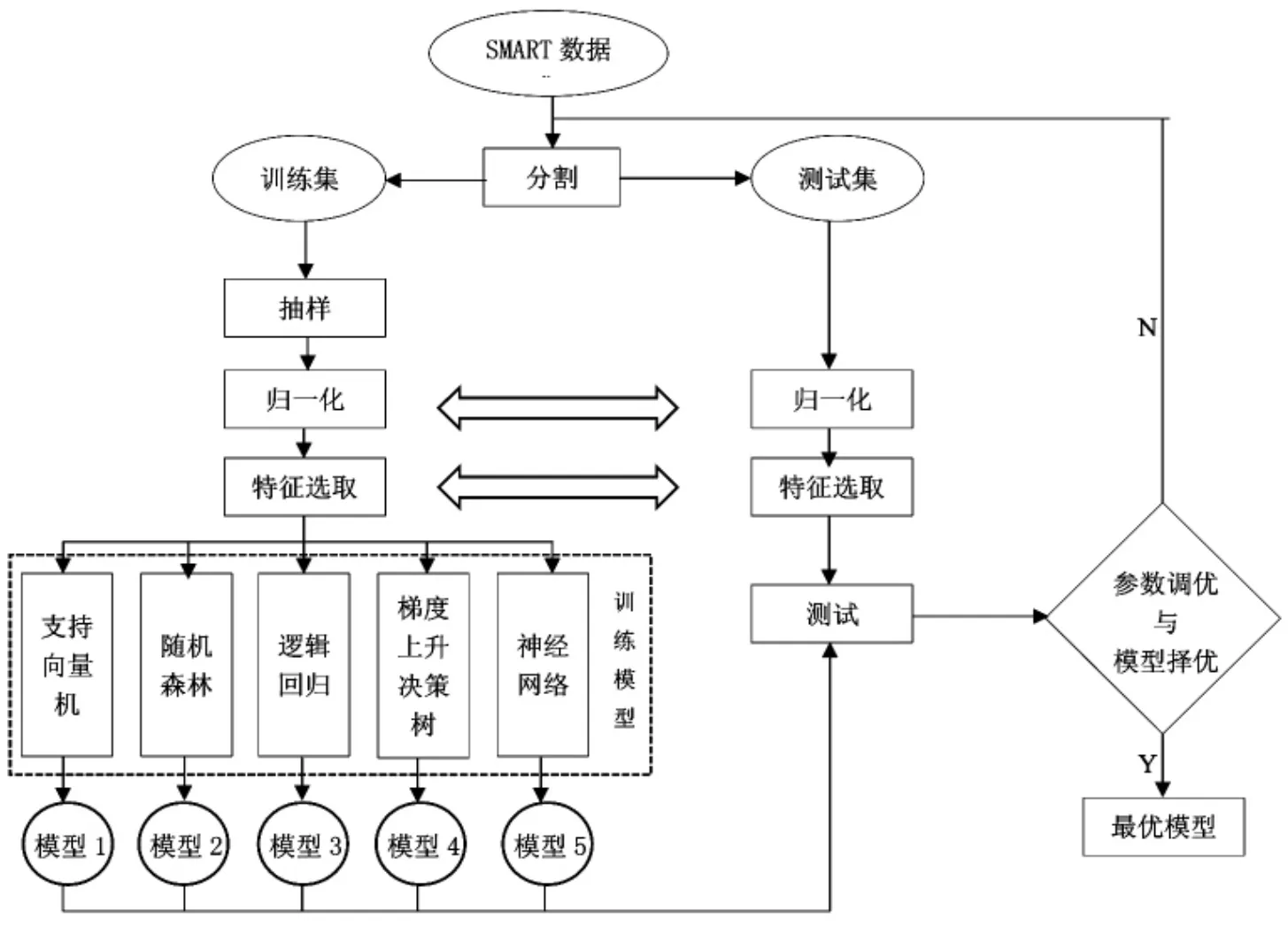
图12 硬盘故障预警流程图Figure 12 Hard disk failure warning flowchart
5.4 高性能
5.4.1 面向多租户云存储系统的软件定义文件系统SDFS
现有云平台往往将虚拟机的虚拟磁盘以大文件形式存放在用网络连接的共享存储节点上,以降低成本,方便管理。 但因此也会导致IO 栈复杂,带来性能隔离挑战。
文件系统决定了存储资源的使用,不考虑文件系统的特性,性能隔离无从实现。因此,我们通过存储服务器端文件粒度资源分配,保障虚拟机性能需求,控制文件系统影响,降低性能干扰;控制平面通过元数据来记录和传递租户性能需求;数据平面进行资源调度,配合实现软件定义的思想。
5.4.2 并行文件系统客户端持久性高速缓存
主要思想是数据按需向计算节点迁移;特点是利用分层存储管理和分布式锁管理机制,采用统一命名空间管理高性能客户端本地缓存;自定义缓存规则,客户端本地缓存数据按需预取或替换;减少数据迁移和网络拥塞,减轻服务端I/O 压力和存储开销;提供性能隔离、QoS(Quality of Service)保障,对延迟敏感,I/O 局部性应用效果显著。
SDFS 能通过文件粒度的资源分配, 保障虚拟机的性能需求。 与Pulsar 相比,Pulsar 无法控制文件系统延迟写带来的影响, 所以无法做到性能隔离;而SDFS 能够避免延迟写带来的干扰而保障各个租户的性能需求。 在使用SDFS 进行性能隔离的时候,虚拟机的性能波动降低4 倍以上。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
家庭影院技术(2019年8期)2019-08-27 02:44:56
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
现代防御技术(2016年1期)2016-06-01 12:13:27
燕山大学学报(2015年4期)2015-12-25 02:19:45
中国塑料(2015年4期)2015-10-14 01:09:28
环球时报(2014-06-18)2014-06-18 16:40:11
火炸药学报(2014年1期)2014-03-20 13:17:29
