
Python数据挖掘在高校人才引进中的应用
2021-03-11 03:34李嘉祺
电子技术与软件工程 2021年21期
李嘉祺
(南宁理工学院图文信息中心 广西壮族自治区桂林市 541006)
数据挖掘是一门新兴的交叉学科,涉及多个领域如知识工程、人工智能以及数理统计技术等,通常指的是完整的一个过程。这一过程从大兴数据库中对可实用、有效的、新颖的知识和模式进行识别,并且利用这些信息丰富知识或者做出有效决策[1]。简而言之,所谓数据挖掘,就是抽取大量数据中潜在的有价值的规则、模型或者知识的一个过程,并且在实际的运用中,与知识发现(Knowledge Discovery in Databases,KDD)的概念具有一定的相似性[2],其挖掘环境如图1。本文分析了高校人才引进中运用Python 数据挖掘的价值,现报道如下。

图1:数据挖掘环境
1 Python数据挖掘的概念
Python 语言作为当前比较热门的一个程序设计语言,也是面向对象的一种语言,其解释性、交互性较好[4]。在2017年热门计算机语言排行中,Python 居于首位,明显优于C 和Java,其中Python 开源社区的用户活跃度较高,并且开发代码库以为数据挖掘提供支持,可以提高科学计算能力。同时数据挖掘实现的功能有以下几点:
(1)聚类和分类,即发现类型不同事物之间的差异和类型相同事物的共同特征;
(2)将不同事物之间的关联性或依存关系找出来;
(3)对事物的共通性和同质性进行寻找;
(4)将历史资料和数据作为基本依据,对未来事物的发展趋势进行预测[6]。
2 Python数据挖掘的可行性
数据挖掘通常涉及比较复杂的步骤,如定义问题、预处理数据、评估模型、数据储存以及数据建模等,其中数据挖掘中运用Python的关键步骤见图2。同时,数据由两处来源:
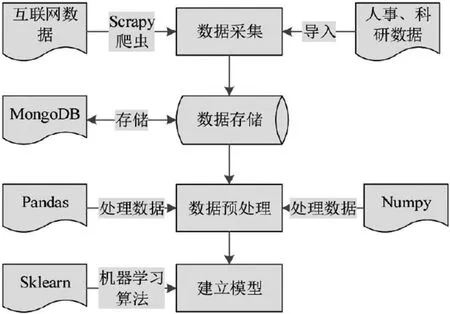
图2:Python 数据挖掘流程图
(1)运用Scrapy 框架对网络数据进行爬取;
(2)从现有科研、人事系统中导入,在MongoDB 数据库中,运用Pymongo 包对爬到的数据进行储存,并且作为后续分析的数据支持。同时,Python 工具包运用在挖掘数据和预处理阶段中的类型有很多,比如Sklearn、Matplotlib、Pands 以及Numpy 等。
Python 数据挖掘步骤有以下几点:
(1)数据采集。在指定网站上通过爬虫技术获取数据,即首先创建Scrapy 项目,然后编写爬虫规则,在维持Scrapy 项目正常运行的基础上,对相应的网络数据进行获取[7];
(2)数据存储。爬虫数据一方面具有关系型数据,另一方面还具备非关系型数据,其运用NoSQL 非关系型数据的适用性较好。在NoSQL 数据库模型中,数据间无明显联系,其灵活性较高,不仅容易读写数据,还可以方便扩展数据[8]。在本次研究中,利用MongoDB 数据导入爬取的数据后储存,为后续操作提供支持;
(3)数据预处理。首先对数据进行清洗。同时,Python 工具包中的多种工具具有较强的数据处理和矩阵运算能力如Numpy、Pandan 等。此外,运用Python 工具包可以对数据进行批量处理,再与数据预处理相关技术相结合,大批量、快速化的处理非法格式数据。
(4)数据挖掘建模。因为Sklearn 库的编写基础为Python,其在数据挖掘、机器学习等领域的知名度较高,并且库中包括的机器学习和数据挖掘经典算法较多。同时,库中含有的调试测试工具比较丰富,可以优化和调整算法运行过程中所需的参数。
3 基于Python数据挖掘构建人才发现系统
在本次研究中,通过集成知网科研论文数据以及科研、人事系统数据,在深入挖掘这些数据的基础上进行统计分析,然后构建人才发现系统,实现高校人才科研评价、人才发现以及热点发现,具体如下:
3.1 人才发现
运用Scrapy 工具抓取中外论文数据,可以作为发现人才的基础的一个数据,然后通过Web 网页对模块数据进行解析,在MongoDB 数据库中按照指定格式存储。同时,在挖掘数据时,要对论文基本信息进行充分考虑,最后对权重进行科学分配,设计算法,对挖掘模型进行构建,可以为引进高层次人才的工作发挥一定辅助作用。
3.2 人才科研评价
通常情况下,校内科研人员可以分为三种类型,分别科研为主型、科研教学并重型、教学为主型,并且通过人事系统查询教职工信息。在数据预处理中,首先将与挖掘、数据无关的家庭住址、手机号码以及姓名等去除,对与规则和分类相关的字段进行保留。同时,深入挖掘测评教师,还应该离散化各字段,比如性别为女性、男性,编码为1、0;运用区间对年龄进行分类;用硕士、博士以及其他替代学历/学位,编码为1、2、3 等。
3.3 研究热点发现
分析周期每年数据,然后将学科分类号作为基本依据,统计不同研究领域的论文变化趋势和发表数量,提取论文关键词,统计出现频率,对前沿方向和研究热点进行自动推送。同时,系统还能对研究主题相似但不同学科的文章进行分析,对学科的研究方向进行发掘,构建学术交流圈子,对科研圈和科研人员进行推荐,有助于科研人员理论成果的转化。
4 基于Python数据挖掘构建人才发现系统的实现
4.1 开发环境
本系统运用的软件和硬件系统包括数据库MongoDB v3.6.3、阿里云服务器Ubuntu16.04 64 位、开发工具PyCharm Community Edition 2018.3、开发语言Python3.7.2、内存16G、CPU Inter Core i7-4790 3.6GHz 以及操作系统64 位Win10 企业版。
4.2 搭建Scrapy爬虫项目
首先对Scrapy 爬虫项目进行搭建,对知网论文数据进行获取,即首先明确爬取数据的域名或网址信息,然后将Scrapy 内置命令作为基本依据,使项目框架自动生成。操作如下:第1 步,对项目进行搭建,执行命令;第2 部,自定义生成爬虫文件,执行Scrapy genspider-t crawl cnki cnhi.net。同时,按照上述两条简单命令,能够搭建Scrapy 爬虫项目,然后分析上述过程,可见Scrapy 框架的易用性和功能性较好。
4.3 处理请求数据
在系统中,数据库储存数据的格式为json,具体如下:


上述数据结构确定后,与操作数据库相连,然后Pymongo 作为连接MongoDB 数据的一个驱动,将Pymongo 驱动包导入后,能够进行数据的增加、查询、修改以及删除等操作。同时,在清洗数据的过程中,Matplotilib、Pabdas 以及Numpy 等工具的矩阵运算和数据处理能力较强,再结合上述Python 工具包,可以提高数据处理效率。
4.4 导入Sklearn库
在本系统中,通过导入Sklearn 库,能够促进数据挖掘和机器学习任务的实现。通常情况下,在进行建模时,可以划分数据为两个部分,分别是训练集和测试集,能够将训练数据平均分为相同大小的k 份。同时,在进行交叉验证时,能够对学习实验进行K 次单独运行,在这一期间,选择k 子集一个为验证集,而剩下的(k-1)容器则为训练集,然后对学习算法进行训练,从而对测试结果平均值进行计算。
5 结束语
在高校的管理工作中,人力资源管理系统是比较重要的一个组成部分,但是大部分高校仅实现了原始、基本、初步的一个统计和查询功能。在人事管理部门的日常工作中,采用完善的一套智能信息系统,可以科学规划与评测学生的人才引进情况,并且为在校人员的科学培养和管理提供一定的支持依据,可以为高校职能部门和决策者提供全面、多维度的智能分析功能,从而促进高校人事管理水平的提高。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电子测试(2018年1期)2018-04-18
制导与引信(2017年3期)2017-11-02
电力与能源(2017年6期)2017-05-14
电子制作(2017年9期)2017-04-17
信息通信技术(2015年6期)2015-12-26
环境科技(2015年6期)2015-11-08
电网与清洁能源(2015年2期)2015-02-28
电子设计工程(2014年18期)2014-02-27
