
大学生就业信息跟踪及管理系统设计与实现
2021-03-11 03:34金昌锦
电子技术与软件工程 2021年21期
金昌锦
(福州职业技术学院 福建省福州市 350108)
1 序言
伴随着国家经济的快速发展和产业结构的调整升级需求,大学及职业教育涌现出一大批新兴的符合国家发展方向需求的新专业。这些专业也提供了大量新兴的岗位需求,不同类型的岗位需求差异明显。特别是一些专业岗位,社会认知度不高,学生自身了解就业信息的难度较大,了解相关岗位信息的积极性不高,不利于学生树立正确的职业观念,不利于学生对自身未来职业生涯进行规划。大部分就业信息都是互联网上收集到的零散信息,或是身边家人朋友和老师等的宣传推介,难以形成明晰的职业认知。与此同时,新兴领域岗位的任职要求日新月异,以上渠道和方式都不能够满足学生对新专业新岗位,老专业新岗位的就业信息与任职要求的信息获取要求。为了让学生能够在学校就读期间就能够紧跟本专业岗位发展情况,明确目标就业岗位的任职条件,做好职业生涯规划的同时有针对性的培养自身职业素养,迫切需要一个岗位信息实时更新的就业信息查询系统来帮助学生及时的了解就业信息,帮助大中专院校师生明确学习目标。
就业问题一直是社会关注的热点问题,目前此类针对就业信息的网络爬取工作,前人已经做了较多研究。例如:太原科技大学的王芳采用基于Python 的Scrapy 框架设计了某招聘网站的爬虫系统并实现数据清洗及分析,但是没有考虑多个招聘网站作为数据源的情况[1];淮阴师范学院的常逢佳采用Python 的requests 库针获取拉勾网招聘数据,通过Ajax 异步请求的Json 数据获取了职位信息简介,并对获取的薪资、工作年限等做了简单数据清洗和分析,但没有获取岗位的详情信息[2]。福州职业技术学院的金昌锦实现了多数据源的招聘信息的数据采集,针对复杂的数据采用Python 的matplotlib 库进行了图表化,最后使用中文分词库jieba 进行分词操作,再用wordcloud 形成图云展示[3]。根据以上的研究情况分析,目前相关爬虫爬取的就业信息大多仅作为研究目的,没有真正实际的开放给高校中的教师和学生使用和参考。本文开发了一个系统能够定期爬取最新的就业岗位信息,对数据进行整理清洗后可供高校师生参考。也可以根据教师和学生的需求新增新的就业岗位进行数据采集,并实现了基本的毕业生就业情况管理功能。
2 本文采用的关键技术
2.1 爬虫主要技术
不同类型爬虫爬取网页内容的方式的不同,根据其爬取特点,一般将其分为分为通用型爬虫和聚焦型爬虫两类[4]。通用型爬虫通常是指类似百度、必应和谷歌搜索这样的面对整个互联网内容进行爬取检索的方式。而针对某个某类爬取者指定的网页信息内容进行爬取的方式,即称为聚焦型爬虫。本文所需采集的数据为就业岗位信息数据,采用的是聚焦型网络爬虫进行抓取。
2.2 B/S浏览器和服务器架构模式
B/S 架构即浏览器和服务器结构模式,是随着Internet 技术的兴起,对C/S 架构的一种变化或者改进的架构[5]。B/S 构架的优点如下:
(1)表现层、业务逻辑层和数据访问层是相互独立的,互不影响,可以降低各层之间的依赖,系统维护和升级方式简单,开发人员能够集中精力关注某一层。
(2)在计算机技术发展的背景下,B/S 构架采用当前标准的网络协议,具有良好的兼容性。
(3)B/S 构架操作方便快捷,无需安装任何应用程序,用户只需通过浏览器即可与后台的服务器和数据库进行数据信息交换[6]。
2.3 Django web框架
Django 是一个开放源代码的Web 应用框架,由Python 写成。具有功能完善、要素齐全、文档完善、强大的数据库访问、灵活的URL 映射等优点[7]。
3 系统设计
3.1 功能需求分析及设计目标
本系统主要使用者为学院内各个专业的学生、相应的专业教师和各班级辅导员三类参与者。
(1)主要为学生提供就业岗位信息的查询,毕业生就业信息的上报等服务;
(2)为专业教师提供最新的就业岗位信息数据,及时了解行业岗位任职要求的更新与变化,根据学生提交的申请及岗位的变化的情况及时更新本专业就业岗位信息及其任职要求;
(3)为辅导员提供学生毕业前后就业情况信息审查及报送功能。
总体设计要实现系统易于使用,操作便捷,有较强的易用性,较低的学习成本。二要能根据用户需求爬取跟踪最新的岗位信息,及时将信息提供给教师处理,并提供给学生了解。三是解决目前学生毕业前后就业信息报送渠道不通畅,辅导员工作量大,信息报送缓慢不及时等问题。
3.2 功能模块设计
本系统根据设计目标,主要分为5 大模块,总体的模块设计参见图1。
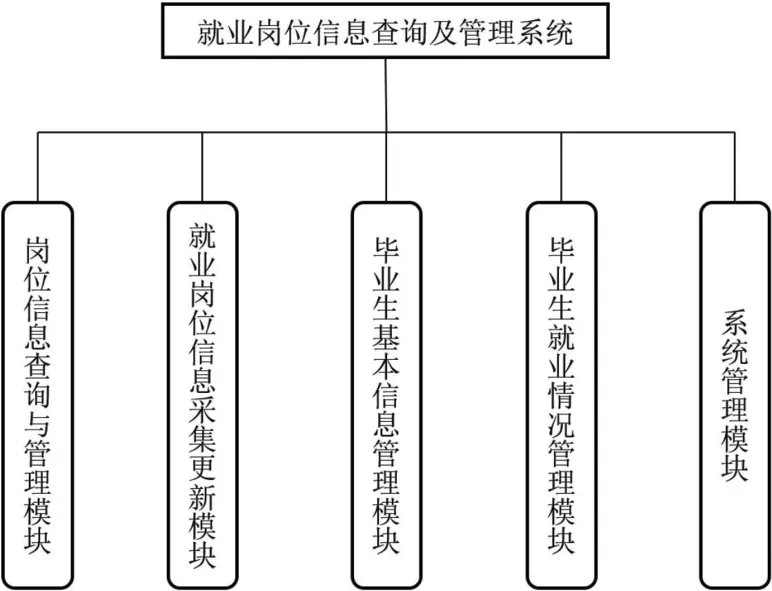
图1:就业岗位跟踪与就业管理系统功能模块图
3.2.1 岗位信息查询模块
本模块可以加深学生对于所学专业相关岗位的任职要求的了解,实时掌握最新的岗位技能与知识要求。学生可以查询了解各个专业主要岗位的就业区域,薪资分布,任职要求等就业信息,也可提交新兴岗位信息采集的申请;教师角色除了可以实现学生角色的功能以外,还可以对学生提交的申请进行审核,审核通过后提交岗位信息爬取模块获得相关信息并审核,最终实现就业岗位信息的更新。
3.2.2 就业岗位信息采集更新模块
本模块定期对数据库内已存在的就业岗位在相关招聘网站进行数据抓取并清理,归集后由专业教师进行人工审核修改后存入数据库中。由教师审核后提交的新增的岗位加入下一次的爬取过程。爬虫采用基于Python 语言编写的网络爬虫进行数据采集,利用成熟的Scrapy 框架配合Mysql 数据库进行爬取及存储任务,最后使用Re 正则表达式库和Jieba 中文分词库对数据进行清洗,提取出有效的就业岗位信息内容。
3.2.3 毕业生基本信息管理模块
本模块可直接导入现有学校教务系统学生基本信息数据表,同时提供修改更正的功能。
3.2.4 毕业生就业情况管理模块
以往毕业生就业信息都是通过学生上报材料给辅导员,辅导员人工收集材料整理后统一上报。本模块实现毕业生就业情况自主上传,辅导员角色可进行审核及管理,自动生成就业信息情况报表。
3.2.5 系统管理模块
系统管理模块可以由管理员进行用户的增减、查询,进行用户基本信息维护,权限设置及修改等。
3.3 功能模块设计
本系统采用的是Mysql 数据管理系统,主要有以下数据结构表,见以下表格:
(1)用户信息表:如表1所示。

表1:用户信息表
(2)毕业生基本信息表:如表2所示。
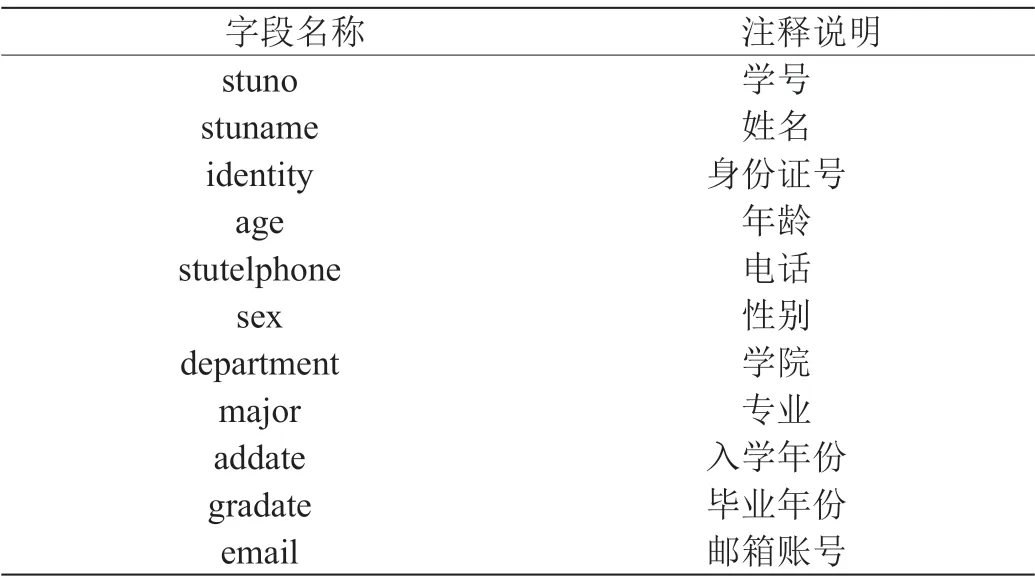
表2:毕业生基本信息表
(3)岗位信息表:如表3所示。
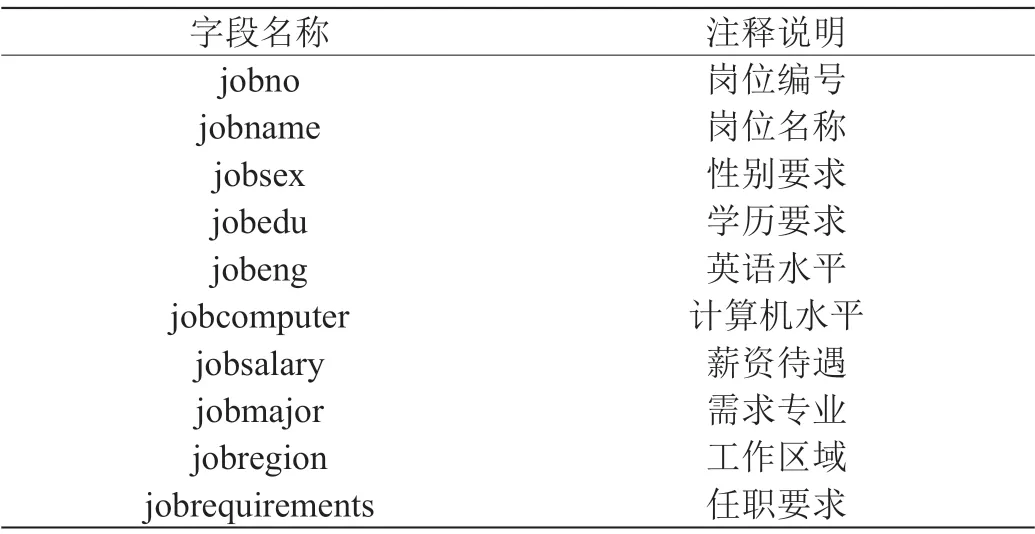
表3:岗位信息表
(4)毕业生就业情况表:如表4所示。

表4:毕业生就业情况表
4 系统实现与测试
本系统测试时服务器端采用的是Windows Server2003 操作系统,客户端采用Windows10 操作系统,使用Chrome 和360 极速浏览器进行系统运行验证。
4.1 用户登陆界面
用户登陆模块是面向用户的第一道窗口,必须确保该模块运行稳定,操作编辑,安全性高。实际测试中本界面运行情况达到预期要求,如图2所示。
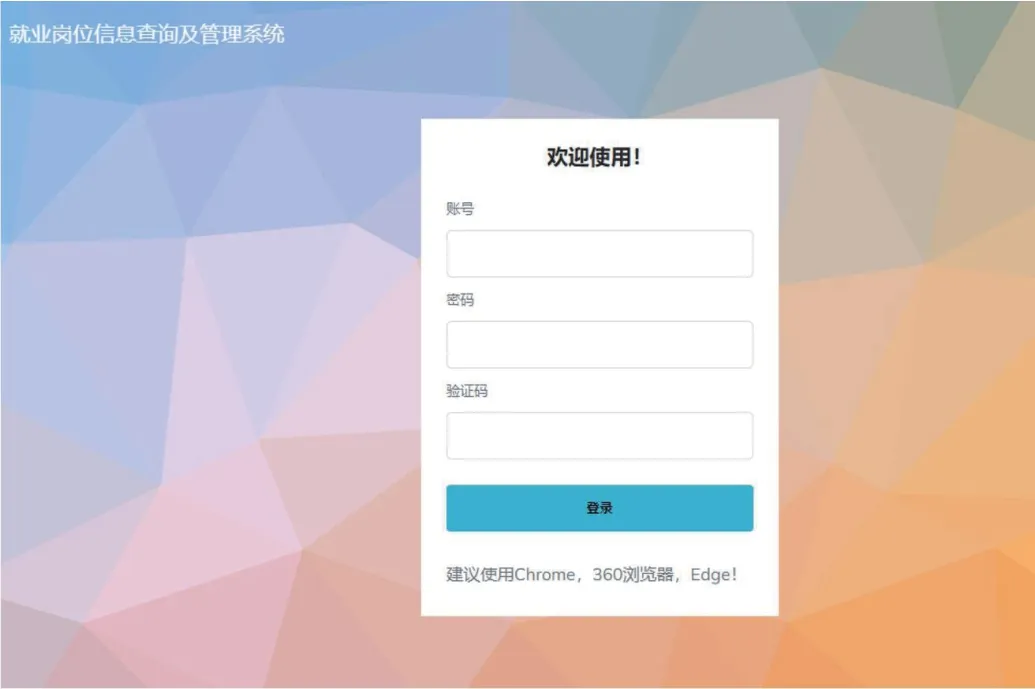
图2:用户登陆界面实现
4.2 系统主界面(学生用户)
系统主界面如图3所示。
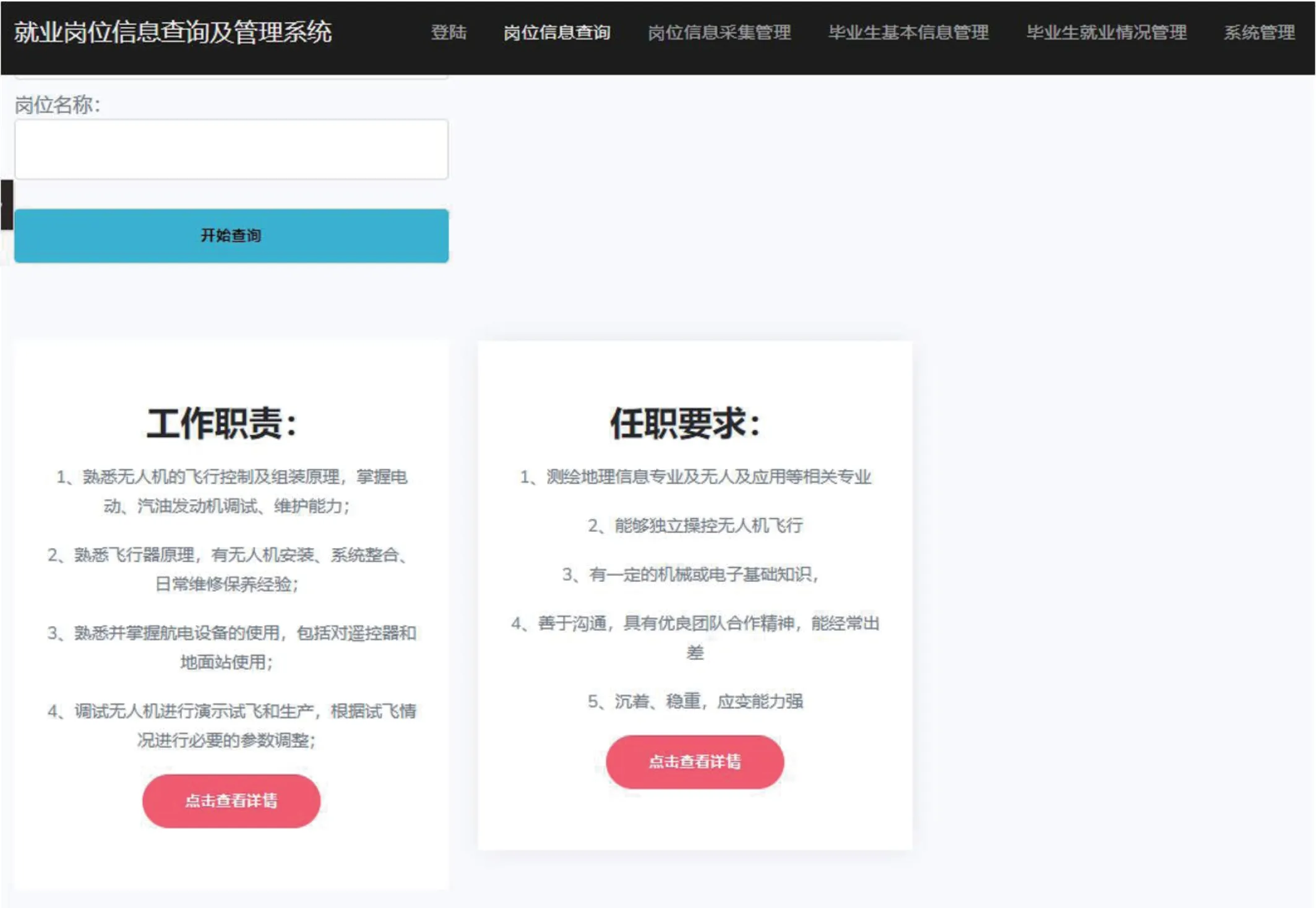
图3:系统主界面(学生用户)
5 结语
随着国家产业升级的步伐逐步加快,在教育部的统一规划下,大中专院校紧跟时代发展设立了众多新兴的就业岗位,旧有的专业及岗位也融合了新的知识和技能。通过本系统实时的跟踪最新就业岗位信息,收集整理后呈现给专业教师和学生参考,不仅让学生对自己未来可能的就业岗位有更清晰的认识,更可以让学生提前规划自身学习方向和目标。对于教师而言也可以随时紧跟行业发展情况,及时调整教学方向,提高教学的针对性。同时本系统还实现了基本的就业生毕业情况的管理功能,学生提交就业情况证明材料更加便捷,辅导员审核就业情况的效率和上报的准确性有效性得到提升,可以很好的服务于本学院的就业引导及就业管理工作,系统总体上实现了设计目标。
猜你喜欢
疯狂英语·读写版(2023年5期)2023-06-01
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
少先队活动(2020年11期)2020-12-28
意林(2020年15期)2020-08-28
意林·全彩Color(2019年7期)2019-08-13
电子测试(2018年1期)2018-04-18
辅导员(2017年18期)2017-10-16
电子制作(2017年9期)2017-04-17
创业家(2015年4期)2015-02-27
