
卷积神经网络和近红外光谱的土壤pH值预测
2021-03-09 10:37唐永生陈争光
光谱学与光谱分析 2021年3期
唐永生,陈争光
黑龙江八一农垦大学电气与信息学院,黑龙江 大庆 163319
引 言
土壤酸碱度不仅影响着土壤的理化性质和微生物的活性,还与土壤养分的转化以及农作物的生长发育息息相关[1]。为了能够合理有效地开发利用耕地资源,因地制宜地对耕地进行精准施肥,需要对土壤的酸碱度变化进行一定的监测把控。目前对土壤酸碱度的检测常采用比色法和电位法[2],虽然测量结果精确,但效率低,耗时长,不适用于在线检测以及野外大面积土壤检测。
近红外光谱在土壤成分分析与参数测定方面取得了很多研究成果。沈掌泉等[3利用近红外光谱与偏最小二乘回归法(partial least squares regression,PLSR)对土壤中的有机碳含量进行预测,其训练集和测试集的均方根误差分别为0.192和0.200; 盛梦鸽[4]等以国内7个省份共计313个茶园土壤样本为材料,采用近红外光谱分析与多元线性回归(multiple linear regression,MLR)方法对茶园土壤的pH值进行预测,其模型的预测相关系数为0.928; 王凯龙[5]等以野外实测土壤光谱数据为基础,分别采用主成分回归(principal component analysis,PCA)、PLSR及BP神经网络建立土壤pH预测模型,结果表明土壤光谱数据与土壤pH值之间存在良好的相关性且呈显著水平。高小红[6]等利用可见光-近红外光谱与BP神经网络相结合的方式对土壤全氮含量进行估算,模型对预测集的决定系数为0.81; 方向[7]等利用可见光-近红外光谱和最小二乘支持向量机(least squares support vector machine,LSSVM)对土壤中的速效磷进行预测,模型对验证集的决定系数为0.78。以上研究结果表明,采用这些方法能够有效地对小样本土壤数据养分含量进行预测,但是随着研究的深入,数据量的增加,这些方法的弊端也慢慢暴露出来,其中,PLS不能有效的处理非线性问题,BP神经网络容易出现局部最优解和“过拟合”现象,而SVM则无法对大规模的训练数据实施训练。
近年来由于卷积神经网络(convolution neural network,CNN)具备局部感知,权值共享及自动提取数据特征的特点,模型的运行效率较高,从而被广泛应用在计算机视觉[8],自然语言处理[9],语音识别[10]等领域。故将CNN应用于基于近红外光谱数据的土壤pH值预测建模中,首先对光谱数据进行一阶求导和Savitzky-Golay平滑预处理,消除基线漂移或其他背景干扰,提高信噪比。然后根据近红外光谱数据的特点对经典CNN模型进行改进,建立土壤pH值的CNN预测模型,并与传统的PLSR和BP神经网络算法模型进行对比,旨在探究一种高效准确的土壤pH值获取方法。
1 实验部分
1.1 数据来源
以欧洲统计局在2008年—2012年对欧盟23个成员开展的土地利用及覆盖面积统计调查研究(European Commission Land Use/Cover Area frame Statistical Survey,LUCAS)所采集的土壤养分及可见光近红外光谱样本为研究对象,共计19 936个样本点。土壤样本分为矿物质和腐殖质两类,主要包括耕地,林地,草地等多种土壤类型,样本的取样深度为土壤剖面的0~20 cm范围,采用十字交叉法在采样点2米范围内取5份土样约500 g进行混合[11]。土壤pH值依照ISO 10390—1994标准进行检测,使用FOSS XDS近红外光谱分析仪进行光谱采集,光谱仪测量波长范围为400~2 500 nm,分辨率为0.5 nm。光谱预处理采用CAMO公司的The Unscrambler X10.3。使用Python语言调用Tensorflow工具包搭建基于CNN的回归预测模型。
选取了LUCAS土壤数据集中的矿物质土壤样本共计17 272个。其中随机选取15 000个样本作为建模集,剩余的2 272个样本作为测试集。土壤样本pH值统计信息如表1所示,其中建模集的pH值范围为3.430~10.080,测试集的pH值范围为3.510~8.770,建模集能够完整覆盖测试集中土壤样本的pH值范围。

表1 LUCAS土壤数据集pH值基本信息Table 1 Basic information of pH value in LUCAS soil dataset
1.2 光谱数据处理
pH值作为衡量土壤养分转化及土壤肥力的一个重要指标,是土壤养分管理项目中必测的内容之一,土壤的酸碱度主要与土壤有机质和微生物中的氢氧基团及土壤胶体中的Al+和H+浓度有关。LUCAS光谱的平均曲线及变异系数曲线如图1所示,由于受到土壤中氢氧基,羟基铝及甲基团的影响,光谱曲线在1 400,1 900,2 200和2 350 nm处出现明显的波峰。光谱仪在采集土壤样本时,会受到周围环境的影响,光谱中往往会掺杂各种噪声,因此光谱曲线出现中等变异,变异平均系数为0.217。为消除光谱中的基线偏移,提高信噪比,采用一阶求导和Savitzky-Golay平滑(多项式阶数为2,平滑点数为11)对光谱数据进行预处理,处理后的光谱图像如图2所示,后续的建模及预测都是基于图2数据进行。

图1 LUCAS土壤样本平均光谱曲线图Fig.1 Mean spectra of LUCAS soil samples

图2 经过预处理的土壤近红外光谱图Fig.2 Pretreated near infrared spectra of soil
1.3 卷积神经网络
卷积神经网络是一种端到端的有监督式神经网络,基本架构由输入层,卷积层,非线性激活层,池化层和全连接层五部分组成。其中卷积层是卷积神经网络中最重要的一层,即通过“局部连接,权值共享”的方式对输入光谱数据进行特征提取。卷积之后,通常会加入偏置,并引入非线性激活函数,经过激活函数后,得到结果
(1)

池化是一种非线性的降采样方法,主要是对卷积层输出的特征值进行降维,减少运算规模。目前,池化主要分为最大值池化和平均值池化两种方式,本工作则采用最大池化法来对模型进行降采样处理。
1.4 建立模型
整个模型的参数设置如表2所示,为避免在特征学习过程中出现梯度消失,神经元饱和的状况,将所有的激活函数均设置为线性整流函数(rectified linear units,ReLU)。经过四层卷积池化操作后得到128个宽度为260的光谱信号,然后将128个光谱信号进行扁平化处理,将得到的一维数据输入到全连接层,全连接层含有两个隐含层,为使计算机充分利用资源,全连接层两个隐含层神经元的个数分别为1 024和128,输出层含有一个神经元,用于实值回归。整个网络层的基本架构如图3所示。

表2 CNNR模型参数设置Table 2 Parameters of CNNR model

图3 CNNR模型基本结构Fig.3 Basic structure of CNNR model
网络模型采用信号前向传递,误差反向传播的方式进行训练,前向传递中初始化网络权重和偏置值分别为截断正态分布的随机值和固定值0.1,反向传播中采用的损失函数为均方误差函数,如式(2)所示
(2)

2 结果与讨论
2.1 训练次数及卷积层数对模型的影响
在使用建模集样本对模型内部参数进行调节中,为探究训练次数对CNNR模型的影响,将测试集样本每隔100次迭代输入到训练模型中,用于检验模型的训练效果。如图4所示,随着训练次数的不断增加,模型的均方误差逐渐减小,模型的精度不断提高,模型在2 400次训练后达到最佳状态。由于训练集样本数据量大,数据复杂性高,因此在前期迭代训练中,模型特征学习不足,模型的测试损失小于训练损失。当训练次数大于2 500次时,模型的测试损失与训练损失之间的距离不断变大,模型开始出现过拟合现象,因此为防止出现过拟合现象,模型可以在第2 500次训练之后停止训练。
为了探究卷积层数对模型预测性能的影响,在使用同一种土壤近红外光谱数据进行建模的情况下,分别采用三层、四层、五层卷积层对模型进行训练,模型的预测性能随卷积层的变化曲线如图5所示,由曲线对比可知,三种模型的预测结果大致相同; 在特征学习速度方面,3层卷积层的模型特征学习速度最慢,模型需训练1 500次后才能达到稳定预测状态,五层卷积层的模型特征学习速度最快,模型在1 000次训练后就达到了稳定,而四层卷积层的特征学习速度与五层类似,模型在训练1 000次左右达到稳定的预测状态。因此,本文选用具有四个卷积层的卷积神经网络对样本进行训练学习。

图4 CNNR模型训练损失和测试损失Fig.4 Training loss and test loss of CNNR model
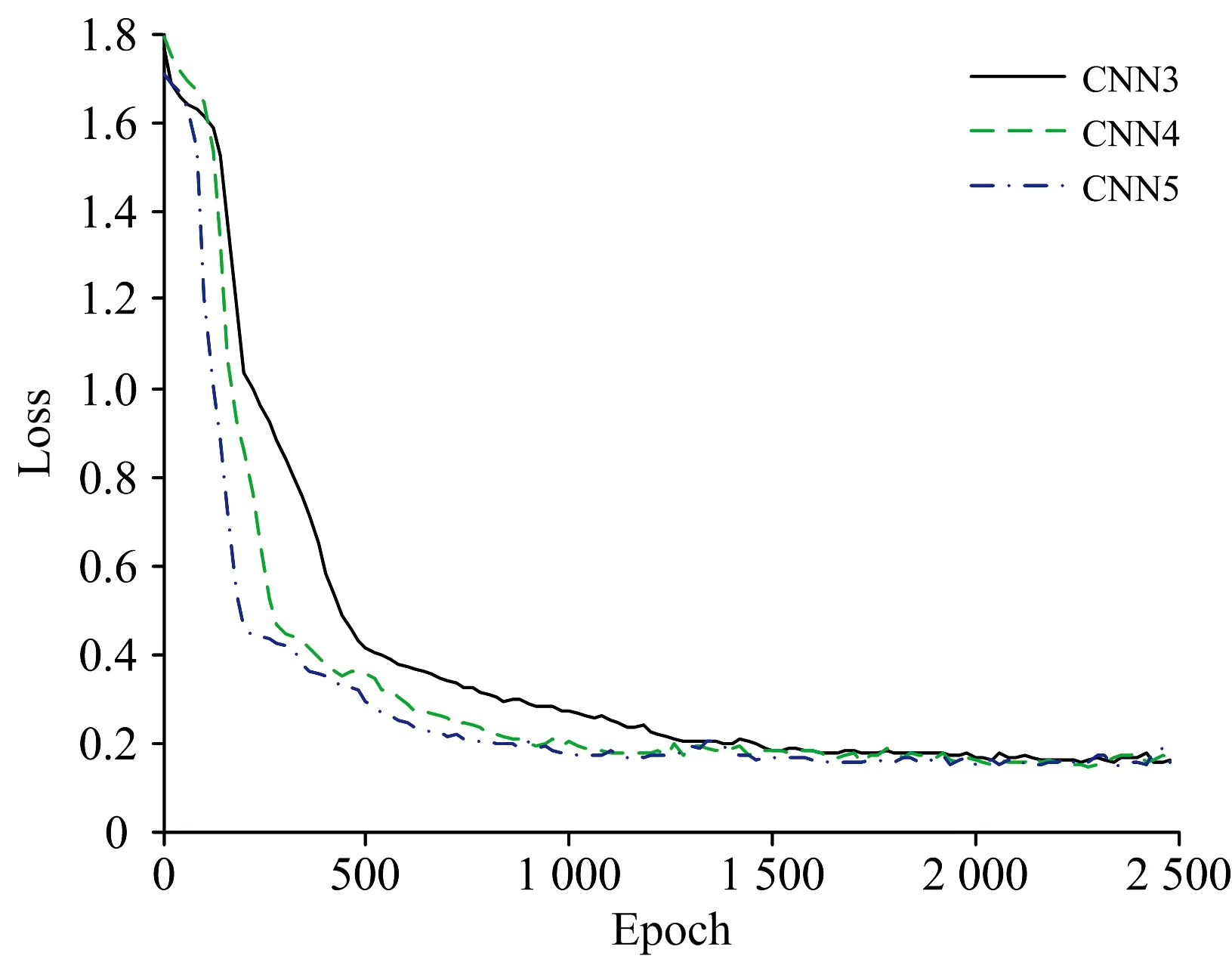
图5 CNNR模型不同卷积层测试损失Fig.5 Test loss of different convolutions of CNNR model
2.2 不同模型性能比较
为了了解CNN网络模型的优劣性,选用了目前较为常用的PLSR和BP神经网络两个模型作为对比。BP神经网络设置隐含层为75个神经元的单隐层结构模型。由于LUCAS土壤样本数据量比较大,不适用于PLSR建模,因此将数据集分成7组进行计算,每组从LUCAS数据集中随机选取2 100个样本用于PLSR建模,随机选取367个样本用于预测,各组数据之间独立不交叉。设置PLSR模型的最大成分数为7,得到7个PLSR模型,选择最优模型为最终的PLSR建模结果。三种模型预测结果如表3所示,在使用同一种土壤近红外光谱数据训练模型的情况下,CNN模型的效果要优于传统的BP神经网络和PLSR模型。

表3 三种模型的预测效果对比Table 3 Comparison of the predictive effects of three models
图6、图7和图8分别为三个模型测试集的预测值与真实值的散点拟合图。由图对比可以看出,三种模型中CNN模型的预测效果最好,数据点密集地集中在拟合直线的两侧,而BP模型和PLSR模型的数据点分布较分散。因此,利用深度学习的卷积神经网络模型对土壤pH值进行预测的方案要优于传统的PLSR和BP神经网络模型。
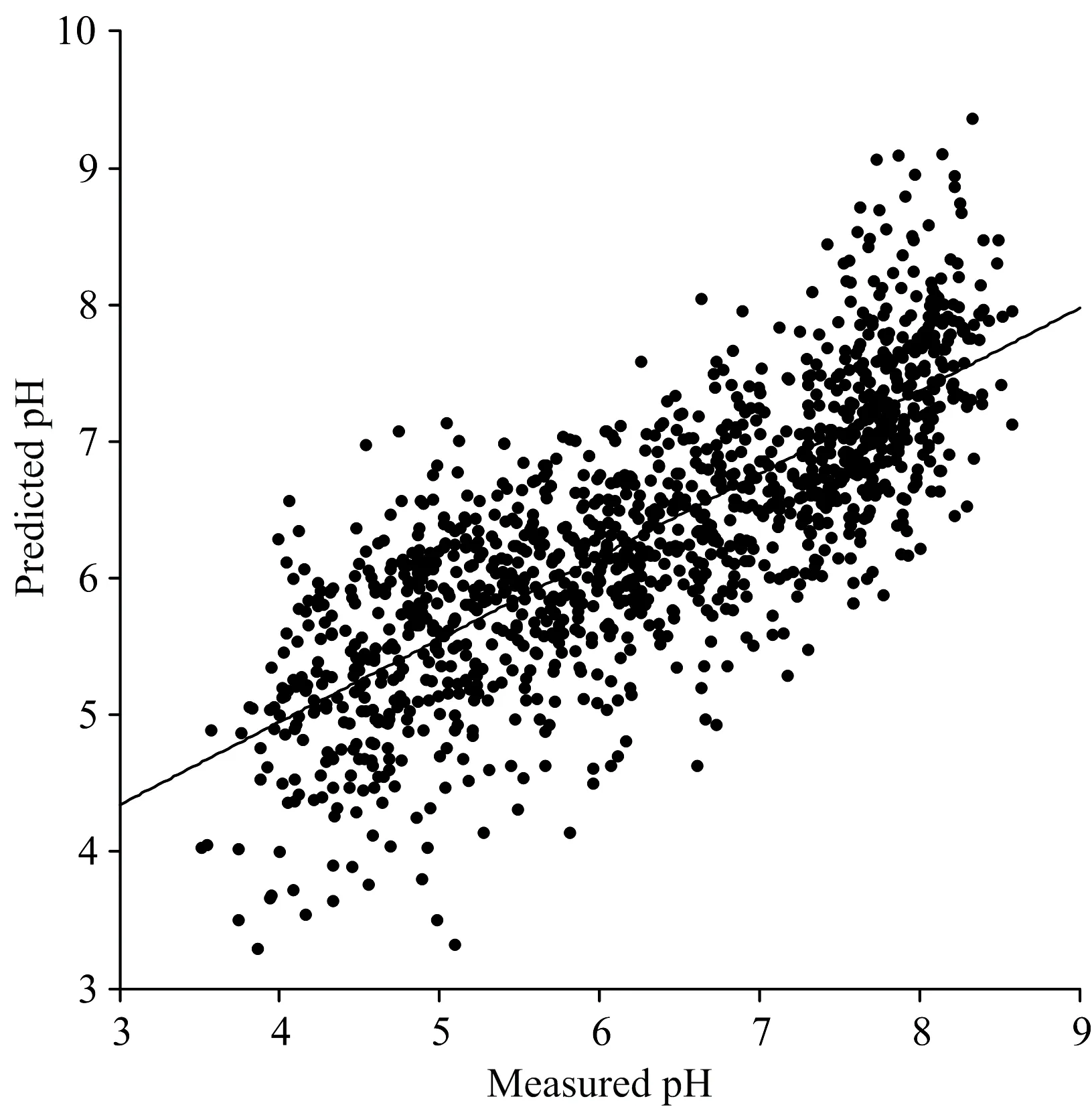
图6 BP模型对土壤pH值的预测结果Fig.6 Prediction of soil pH value by BP model
Yang[13]等利用LS-SVM,ELM等机器学习方法对可见-近红外光谱原谱数据进行建模,对土壤pH值进行预测,预测模型的决定系数皆为0.740; 而本文使用BP和CNN模型实现对土壤pH值的预测,其结果分别为0.792和0.909,本文所使用的方法预测精度有所提高。可见,神经网络模型较SVM和PLSR等传统模型在非线性建模方面具有一定的优势。而基于CNN的神经网络模型能够利用其独特的内部结构实现对土壤近红外光谱的特征提取与学习,通过多次的卷积与池化操作,不断降低光谱中无关数据的干扰,从而获得更加细致的光谱特征,利用这些特征实现对土壤pH值的高效预测,比传统的机器学习算法具有较高的拟合水准。
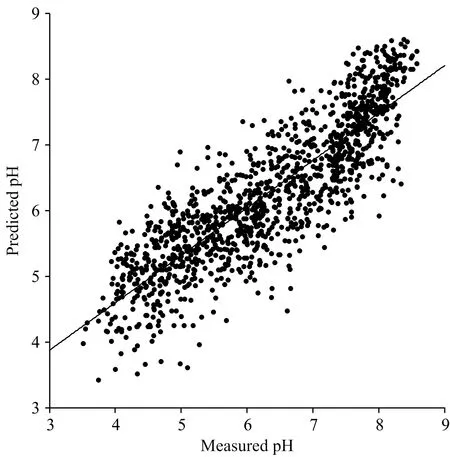
图7 PLSR模型对土壤pH值的预测结果Fig.7 Prediction of soil pH value by PLSR model
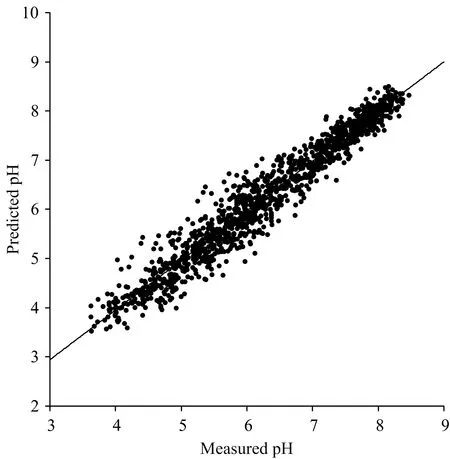
图8 CNNR模型对土壤pH值的预测结果Fig.8 Prediction of soil pH values by CNNR model
王璨等利用卷积神经网络对土壤近红外光谱进行建模,实现对土壤含水率的预测,并与传统的BP,PLSR,LS-SVM方法得到的模型进行对比,所得结论与本文基本一致,从而充分证明了CNN模型的特征学习能力。Padarian[14]等利用二维卷积神经网络对LUCAS土壤数据进行建模,实现对土壤pH值的预测,测试集的决定系数为0.870,而本文采用一维CNN模型实现对土壤pH值的预测,结果为0.909,可见使用一维卷积神经网络对土壤近红外光谱进行建模相比于二维卷积不仅能够有效简化光谱数据的预处理过程而且还能够使模型具有较高的泛化学习能力。
综上所述,卷积神经网络能够用于土壤近红外光谱的回归分析建模中,并在土壤pH值预测方面相比于传统模型具有更高的拟合和预测能力。研究表明卷积神经网络模型能够直接对一维光谱信号进行高效的特征抽取,并能利用这些特征不断的调节修正模型内部参数,从而使土壤pH值回归具有较高的性能。此外,在卷积神经网络模型中运用池化层对光谱数据进行降维,不仅能够有效减少模型的内部参数,提高运算速度,还增强了模型提取特征的鲁棒性和泛化能力,使模型具有更稳定的光谱预测效果。由于本工作是对欧洲土壤的近红外光谱进行pH值预测研究,因此数据具有一定的区域局限性,下一步工作将进一步研究如何获取更多地区特别是国内的土壤近红外光谱数据,从而充分挖掘模型潜力,提高模型检测精度和适用范围。
3 结 论
利用近红外光谱结合卷积神经网络模型对土壤的pH值进行预测,LUCAS土壤样本作为研究对象,建立能够检测土壤pH值的CNN模型,分析结果表明: (1)利用卷积神经网络对近红外光谱进行建模可实现对土壤pH值的高效准确检测; 使用卷积神经网络模型能够直接对一维光谱信号进行特征提取。(2)利用测试集对搭建好的模型进行性能评估,评估结果表明,本模型能够准确地对土壤pH值进行预测,模型的拟合优度比传统的PLSR模型高。利用本模型可以对不同地区的耕地pH值进行检测,对耕地的资源管理及农作物的精准栽种具有指导意义。(3)本模型方法可应用到其他土壤养分信息建模研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
中国光学(2015年5期)2015-12-09
海军航空大学学报(2015年4期)2015-02-27
食品工业科技(2014年23期)2014-03-11
