
基于网络编码和深度学习的云3D虚拟试衣技术
2021-03-09 11:00:58门禹彤
绥化学院学报 2021年2期
牛 牧 门禹彤
(1,绥化学院发展规划与政策研究中心 黑龙江绥化 152061;2,绥化学院信息工程学院 黑龙江绥化 152061)
远程虚拟试衣是近年来兴起的一个新的研究领域[1-3]。随着线上购物的兴起,顾客希望在网上挑选自己喜爱的衣服,这样可以省去实体店店员雇佣费用和房租等线下成本。但是,直接通过浏览服装图片的方式,顾客通过网上试衣时很难对衣服的尺码、效果等有精准的把握,所以,虚拟试衣技术应运而生。摄像系统抓取顾客三维形体数据,结合虚拟现实等技术,生成顾客和衣服的虚拟图像,利用该图像,顾客可以评判衣服是否合适。但是现有的图形学技术、3D虚拟现实技术还无法提供真实线下试衣的体验,虚拟图像和真人的真实尺寸、体型、脸型的还有诸多区别。目前工业界的虚拟试衣技术研究虽然方兴未艾,但还不能实际落地使用,如国内深圳的云之梦科技、俄罗斯的虚拟试衣镜都还不能替代线下真实试衣。
从上述介绍可知,目前的虚拟试衣技术路线主要依赖3D图形虚拟技术,但因为图形学、虚拟现实技术的目前进展还不足以提供真实线下试衣水平的技术要求,所以研究者需要开辟新的研究路径。最近两年来,深度学习技术的进展非常迅速,很多相关应用已经能工业落地。其中,在传统上被认为具有巨大研究难度的自然语言处理领域,深度学习也带来了重要进展。谷歌公司2017年提出的transformer模型大幅度提高了机器翻译、自动应答的应用水平。目前出现的一系列具有重要应用前景的自然语言理解新模型如bert(Bidirectional Encoder Representations from Transformers)、xlnet[4],本质上都是基于transformer模型的,该模型具有在大数据集上进行精确分类的强大能力,是深度学习研究的一个重要里程碑[5,6]。transformer模型一般被应用在具有序列特征的自然语言理解领域,但作为一个优秀的分类器,其也有潜力在其他领域带来重要进展。本文旨在利用transformer模型替代虚拟现实技术,避开图形学、虚拟现实技术的研究瓶颈,不再将虚拟试衣系统的重心放在提高服装和人体的三维虚拟数据精确度上,而是将不很精确的人体数据作为transformer模型的输入数据,利用该深度学习模型强大的分类判别能力,由机器系统自动为顾客挑选最合适的服装,该思路替代了传统的虚拟试衣系统研究路径。
作为云端线上虚拟系统,网络传输的数据相应速度对顾客的购物试衣体验也尤为重要。这里在transformer模型的基础上,利用网络传输加速技术--网络编码来提高系统的响应速度[7]。在网络接收端,传统上网络编码需要一次解码操作,但这里可以用transformer模型的正向传播直接替代网络编码的解码操作,这一设计使二者有机融合,降低了运算负载。
一、基础技术
(一)随机线性网络编码。网络编码的核心思想就是允许并提倡网络的中间节点对信源消息进行中间的加工。通过Jaggi-Sanders算法可以实现确定性网络的网络容量的上限[7]。通过随机网络编码算法可以实现非相干网络的多播容量上限[8]。网络编码技术是信息论的一个大发展,也是一种突破[9]。
整个网络编码过程如下:1.数据包分组。信源将要发送的消息分组,每组的前面加上包头,包头存储的是网络编码向量,信源处的编码向量是单位向量。2.中间节点再编码。中间节点收到消息后重新再编码,也就是将每个包前面乘以一个随机系统,算出新的包头编码向量,然后发送给下游节点。3.译码。信宿节点收到足够多个线性独立的包之后就可以进行译码,解出信源处的信息。网络编码原理如图1所示。
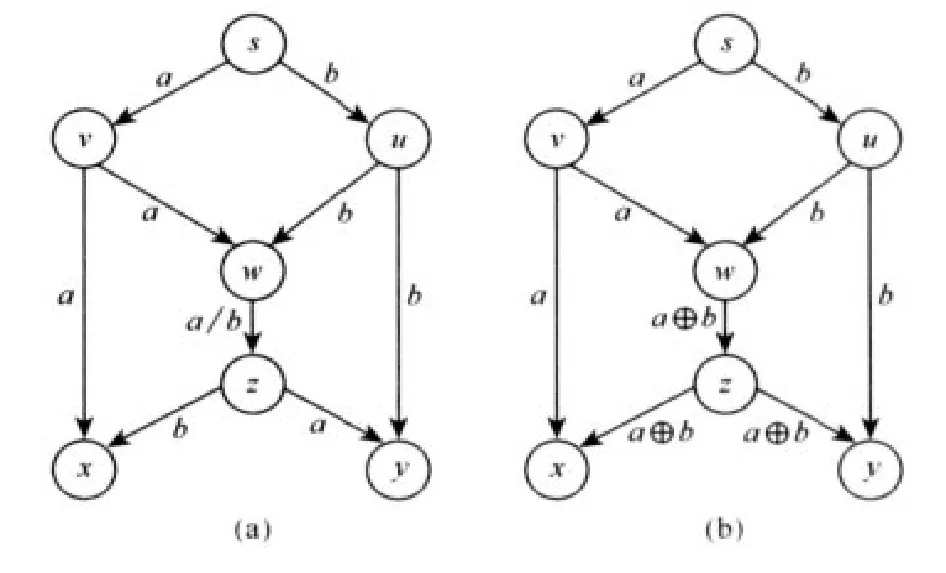
图1 蝴蝶图
网络编码的应用范围已经扩展到很多领域[7-12]。在有线网络中可以提高网络的吞吐量[13];无线网络中可以减少重传次数,进行复杂环境下的纠错等[15-17]。
(二)transformer模型简介。Transformer模型2017年由Google团队的《Attention is All You Need》提出,有一个完整的Encoder-Decoder框架,其主要由attention(注意力)机制构成。Transformer模型抛弃了以往深度学习任务里面使用到的CNN(卷积神经网络)、RNN(循环神经网络)。这个模型广泛应用于NLP领域,例如机器翻译,问答系统,文本摘要和语音识别等等方向,因其出色性能,也有学者将其引用到别的研究领域。
模型分为编码器(Encoder)和解码器(Decoder)两部分,包含内部结构的总体结构如图2所示。

图2 transformer内部结构图
transformer模型本质上是一个样本分类器,充分使用了attention注意力机制,其在污染数据的恢复方面有较好效果。
二、基于网络编码和深度学习的云3D虚拟试衣具体技术方案
(一)总体方案。训练阶段:云3D服务器端以自己库存衣物为标签,以大量人体三维形态数据作为输入数据,训练生成transformer神经网络模型,得出此神经模型的最优参数。
测试阶段:各客户端通过摄像机拍照取得实际试衣人的三维形态数据,利用网络编码技术实时将数据传输至云端服务器,服务器将该客户形体数据输入之前训练阶段得出的transformer神经网络模型,该模型通过正向传播得出客户最适合的衣服编号。
在测试阶段,网络编码技术和transformer模型的正向传播有机结合起来,并不需要配置额外系统资源。从transformer模型的角度来看,客户端传输过来的数据会有一定的“偏差”。“偏差”来自于两部分,一部分来自于网络编码的错误扩散,另外一部分是因为真实测试的人体三维数据和模型采用的训练样本不是完全相同的。一般情况下,网络编码的纠错需要额外的机制去解决,如密码学和信息论技术。而在本文方案中,transformer深度学习模型的正向传播能自然地纠正一部分“偏差”,所以其能替代网络编码纠错中的纠错机制部分,并不需要额外提供诸如密码学和信息论的纠错技术模块,即本方案无缝融合了网络编码和transformer模型,能同时达到数据传输提速和提高人体三维形态数据精确度的目标。
下面将阐述这两部分的方案细节。
(二)transformer模型技术细节。根据不同的任务特点,图2所示的transformer模型中的参数需要不同的设置数值。根据实验,本方案中参数设置如下。基础参数部分:词向量维度为256,encoder、decoder模块的神经网络层数都为6,多头数为8,默认不采用attention_dropout。训练参数部分:batchsize=32,可选用三种优化器(Optimizer=SGD/RMSprop/Adam),epoch_size=300000,多进程数num_workers=10。测试参数部分:采用集束搜索,beam_size=1。
(三)网络编码方案。虽然本方案将用于提速的网络编码和用于人体形态估计的transformer模型结合起来,但这两种技术的自身特点使得二者自然的无缝自然融合,所以在具体方案实现上,二者可以分开描述。从网络编码角度来看,传输的人体姿态数据和普通数据没有任何区别,都是通信数据,所以关于网络编码模块这里仅仅从通信传输角度进行描述,而不关注其所传数据为深度学习模型transformer的输入的客观特点。
将分发的文件分成m份,每份有n个字符。字符为选定有限域F上的一个元素,F的大小采用经典的数值256,即一个字节大小的8次方[4]。证明在此有限域下,解码成功率可以达到99%以上,已经足够工程实践的要求。256也是最近很多网络编码具体实现方案经常采用的有限域大小。m的值这里根据具体情况选择,一般来讲,跟节点的计算能力有很大关系,如果CPU运算能力强,m值可以大一点,比如可以取50,反之,就要小一点,有时采用m=10,这时解码求逆矩阵的运算量不至于太大。信源节点在每个数据包的包头加上随机编码的向量,在信源节点就是m个标准基。中间节点随机选取编码系数,和接受的数据包包头的编码向量进行运算,得到新的针对原始消息的编码向量,将这个新的编码向量插入到生成的数据包的包头部位,然后连同数据本身组成新的数据包,然后传输到下游节点。信宿节点收到新的数据包之后,取出包头的编码向量,检查他们的独立性,直到收到m个彼此独立的信息包,就可以通过解方程的形式解码出原始消息。整个单轮的传输周期结束。
因为用transformer模型的正向传播替代了网络编码的纠错解码模块,所以,除了网络编码本身的提速外,也因为节省了一次网络编码解码操作,所以,系统的响应速度会进一步提高。
三、仿真
云3D虚拟试衣技术目前还处于理论研究阶段,理论和工程实践都还有许多难点待以解决,距离可供工业使用的标准还有很远的距离,所以这里没有给出原型系统级别的测试。本方案将从数据传输速率和人体形态数据识别准确度两个角度对本方案进行仿真。数据集采用H3D Dataset(伯克利大学人体3D数据库),H3D(人体3D)是一个标注人体数据集。标注包括:关节和关键点(眼、耳、鼻、肩、肘、腕、踝、膝和踝)。3D姿态由关键点推导而得。但因为H3D Dataset的标签和本方案的标签不一致,而目前并没有匹配本方案的公开数据集,所以,这里在该数据集的基础上人工标注。标签为库存衣服编号,方案会为输入样本标注一个最“合适”的标签,即会为样本选择一件最合适的衣服。在此修改后的数据集上,训练集、验证集、测试集尺寸比例为9:1:1。transformer模型的参数设置参见前文“transformer模型技术细节”部分。人体三维数据示例如图3所示。

图3 三维人体形态数据示例
针对识别准确率,本文采用RNN和CNN网络模型作为transformer模型的对比方案。三者准确率对比如表1所示。

表1 三种模型对应准确率
准确性实验讨论如下。实验表明,相对于RNN和CNN网络模型,transformer模型在提高三维试衣识别准确性方面具有明显优势。但该实验采用数据集和3D试衣真实场景具有较大差别。在真实场景中,标签表明人对衣服的审美结果,但不同地区、年龄、文化教育背景对审美结果有很大差异,所以,如没有特别机制,真实场景中识别准确度可能会下降。另外,因为人口数目的庞大,即使训练数据集非常大,其也难以覆盖测试样本顾客数据的主要特点,这些因素同样可能会导致真实场景识别率会下降。
针对数据传输速率实验,这里将云端服务服务器分布式训练节点数目设置为3,这样,网络编码的最小割为3。 将未采用网络编码的路由转发机制作为对比方案。假定路由转发机制速率为1,二者速率对比如表2所示。

表2 传输速率对比
传输速率实验分析如下。表2表明网络编码技术可以极大提高网络传输速率,这对云端3D试衣系统非常重要。在云端3D试衣真实场景里,客户上传到服务器的数据需要尽可能小的延迟,否则会很大程度上影响顾客的试衣体验。理论上,在三个分布式节点情况下,相比于路由转发机制,网络编码方案的速率是路由转发方案速率的3倍。但因为真实数据传输时不可避免的遇到网络编码的错误扩散,同时因为测试数据和训练数据具有一定“偏差”,这里在应用层又直接将数据送至transformer模型进行正向传播以进行解码,而没有在输入模型之前进行传统的网络编码纠错,所以,网络编码的速率性能增益并没有达到理想值3。但因为用transformer模型的正向传播替代了网络编码的纠错解码模块,总体速率会进一步加大。同时因为减少一次网络编码的过程,运算负载也会降低。
四、结语
本文将网络编码技术和深度学习里的transformer模型相结合以实现云端3D试衣方案,以深度神经网络的正向传播充当网络编码的解码器从而降低通信时延和运算负载。实验结果表明,此方案有效的提高了3D试衣识别准确率和数据传输速率。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
电子制作(2018年18期)2018-11-14 01:47:56
中国连锁(2015年5期)2015-06-17 22:42:04
