
贾平凹小说汉英平行语料库建设
2021-03-09 05:34冯丽君
商洛学院学报 2021年1期
冯丽君
(商洛学院人文学院,陕西商洛 726000)
贾平凹著作颇丰,长篇小说目前已有18部,但在20世纪末到21世纪初的二十多年间,贾平凹小说的英译一直处于相对沉寂的状态,期间只有《浮躁》一部译作产生。近几年来贾平凹小说英译本井喷式出版,仅2016年以来,就有《废都》《高兴》《带灯》《土门》《极花》 等五部长篇小说英译本问世。译作的出现促进了贾平凹小说在国外的传播,也为其译介和传播研究提供了丰富的研究资料。
目前,有关贾平凹小说的英译研究成果,多是基于单译本的个案研究或质性研究,量化和实证性研究不足,语料库研究视角缺乏。在CNKI数据库中,以“贾平凹”和“语料库”作为主题和关键词搜索,只有王瑞和黄立波合作的一篇论文,该论文以贾平凹的15篇中、短篇小说英译本为主要语料,从数据统计、文本呈现等方面分析了贾平凹小说译入和译出文本的文体风格差异[1]。此外,国内外目前缺乏专用的贾平凹作品汉英平行语料库。黄立波2012年左右建设的“中国现当代小说汉英平行语料库”中收录有贾平凹的作品[2],但主要是中、短篇小说,长篇小说只有《浮躁》一部。2016年以来,贾平凹长篇小说英译本逐年增多,要想系统、全面地研究贾平凹小说的英译情况,有必要创建贾平凹小说汉英平行语料库。
语料库(corpus,复数corpora)是指按照一定的科学采样标准采集的,能够代表某种语言、语言变体或文类,主要用于语言研究的电子文本集或数据库[3-4]。语料库按照不同的分类标准可分为不同的类型。常见的分类如:根据领域,可分为通用语料库和专用语料库;根据语体,可分为书面语语料库和口语语料库;根据语种,可分为单语语料库、双语语料库和多语语料库;根据对应关系,可分为可比语料库和平行语料库[5]6-7。
本研究所谓的平行语料库指“收录某一语言文本和与之对应的翻译文本的语料库”[5]4。建设平行语料库需要搜集相对应的双语或多语文本,然后进行深层次对齐处理。因此,双语或多语平行语料库建设比单语语料库建设更为艰难和复杂。本研究主要介绍贾平凹小说汉英平行语料库创建的关键环节。
一、CEPCOJN语料库的设计
本研究创建的语料库是贾平凹小说汉英平行语料库(Chinese-English Parallel Corpus of Jia Pingwa's Novels),简称CEPCOJN。建库的主要目的是对贾平凹小说的英译情况进行相关研究,重点是基于该语料库进行贾平凹小说方言、俗语等特色语言信息的英译研究。
建库的原则:第一,CEPCOJN语料库属于专用语料库,语料库中只收录已正式出版发行的贾平凹小说英译本,以及相对应的汉语原作,不包括改编、改写、编译、改译等作品。第二,CEPCOJN语料库是汉英双语平行语料库,主要包括汉语和英语两种语言的语料,同时这两种语言的文本即原作和译作必须是相对应的。第三,CEPCOJN语料库以贾平凹现有长篇小说英译本及其对应的汉语原作为主要语料,语料库规模约为200万字词。第四,CEPCOJN语料库是一个特色语料库。通过对语料库中的方言、俗语等特色语言信息的标注,实现对贾平凹作品特色语言英译研究的目的。第五,CEPCOJN语料库是一个动态发展型语料库,后期贾平凹小说有新的译作出版,本语料库也会尽可能收录,从而不断地扩展和完善CEPCOJN语料库。
二、语料采集和预加工
语料的采集和录入是语料库建设的基础。平行语料库必须要有双语文本。CEPCOJN语料库创建首先要采集所有贾平凹长篇小说的英译本。截至2020年初,贾平凹长篇小说翻译成英文的共有六部,包括1991年Louisiana State University Press出版的《浮躁》(Turbulence)、2016年University of Oklahoma Press出版的《废都》(Ruined City)、2017年Amazon Crossing出版的《高兴》(Happy Dreams)、2017年 CN Times Books出版的《带灯》(The Lantern Bearer)、2018 年 Valley Press出版的《土门》(The Earthen Gate) 和 2019年 ACA Publishing Ltd出版的《极花》(Broken Wings)。 这六部长篇小说英译本及其相对应的汉语原作是CEPCOJN语料库目前收录的主要语料。其采集和预加工具体过程如下。
第一,通过亚马逊等国外图书网站购买到正版的上述英文译作,然后根据这些英译本购买或采集相对应的汉语原作。
第二,对采集到的汉英对应书籍纸质文本进行电脑录入和整理,即对文本进行数字化转换。纸质版的文本需要先扫描成图片或PDF格式,然后用OCR软件进行文字识别。本语料库的数据主要通过ABBYY FineReader软件进行文本格式的转换,在ABBYY FineReader OCR编辑器中,先对扫描的图片进行文本行矫直、增加分辨率等预处理,再用OCR文字识别功能将其转换成电子文本。在此过程中,纸质书的印刷质量参差不齐、扫描效果不佳等因素,都会影响OCR文字识别功能的发挥。常见的拼写识别错误如:将大写或小写字母“I”识别为数字“1”,“e”识别成为“c”等。单词拼写识别错误需要人工逐个校对。ABBYY FineReader OCR编辑器在文字识别的过程中,对疑似识别错误的地方会高亮提示,并提供原文对比如图1。利用此编辑器中的验证功能,人工对提示的错误逐个进行鉴别和修改,可以大大提高工作效率,如图2。

图1 文字识别
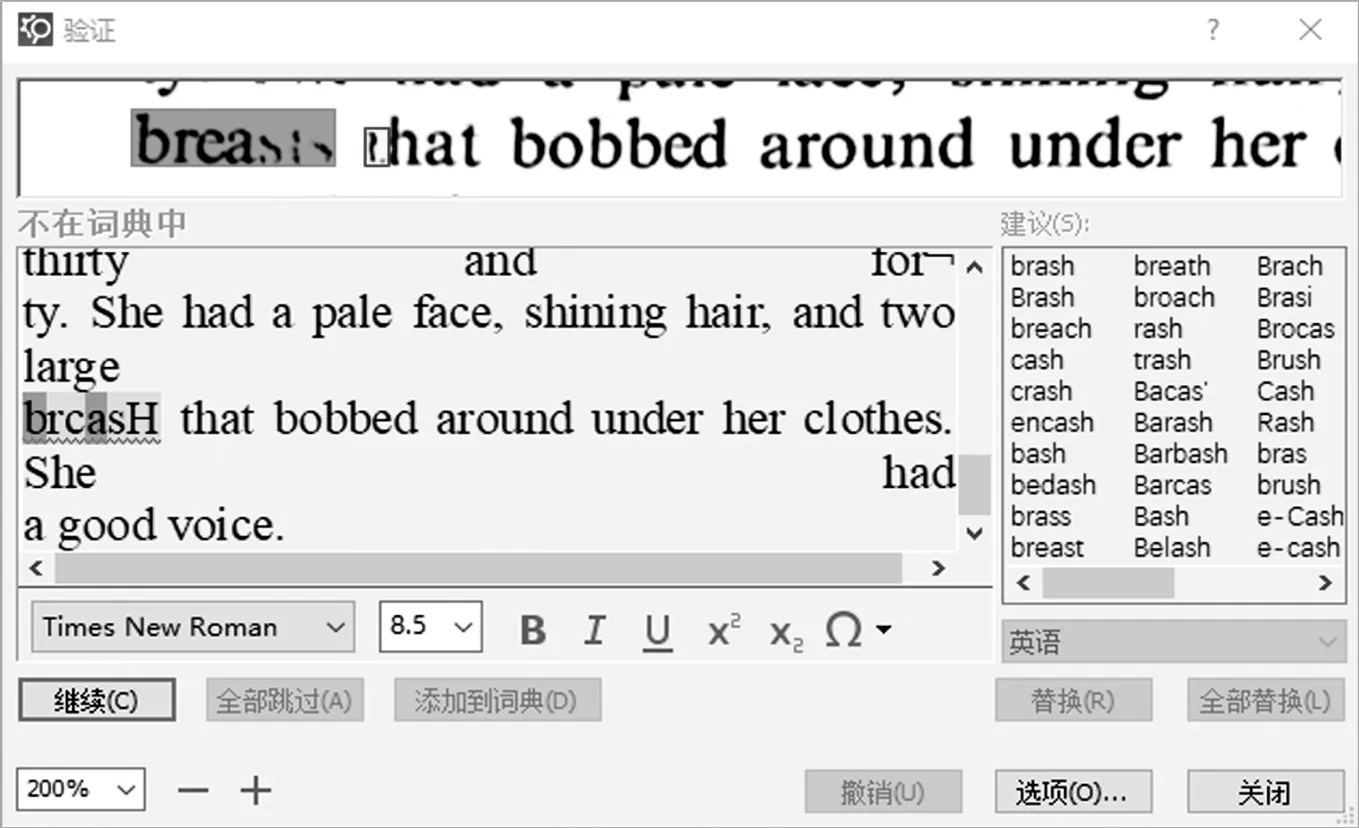
图2 文字校对和验证
第三,将OCR文字识别程序完成之后得到的WORD文档转换成TXT文本,初步形成“生语料”,即“未经任何技术处理的自然语料”[5]3。生语料在格式方面还会有很多问题,如标点符号错误、多余空格、换行、分节、连字符等。
第四,对生语料进行预加工或粗加工,即利用软件辅助人工对语料中的错误进行清洗和除噪(data cleaning)[5]2。 例如,对于标点和格式方面的错误,可以借助WORD里面的“查找和替换”功能进行清洗,也可以在文本编辑器软件(如Notepad++,EditPro,EmEditor等)中通过正则表达式进行批量查找和替换[6]。具体文本中出现的问题不尽相同,需要先观察问题,然后再选择正确的正则表达式进行清洗降噪。无法批量替换的地方,还需要人工进行逐一勘校。清洗之后的文本按照一定的格式命名,转换成统一格式(常用UTF-8格式)的纯文本储存。这一阶段处理完成之后,就生成相对纯净的中英文粗加工语料,可以进行语料库规模的统计(汉语原作也可以先分词再进行词数统计)。
CEPCOJN语料库目前的规模约为235万字词的中英文平行语料库。其中,六部英文译作总词数约为108万(英文单词数统计正则表达式为[a-zA-Z0-9-]+)。对应的六部汉语原作总字数约为127万(中文字数统计正则表达式为[u4e00-u9fa5]|[a-zA-Za-z A-Z0-90-9.%%]+),统计所用软件是PowerGREP。
三、语料对齐和调整
语料的对齐加工是平行语料库建设非常重要的一个环节。语料的对齐是指将源语文本和译语文本按照一定的单位建立对应关系[7]。语料对齐的单位包括篇章、段落、句子、词块或词汇[5]2。篇章和段落对齐较容易,但研究价值有限;由于汉英两种语言的差异很大,词汇层面的对齐基本难以实现,因此,语料对齐中最常见的对齐单位是句子[5]6。句子层面的对齐一方面有标点符号做参照,边界清晰,容易确定;另一方面句子层级对齐基本可以满足后续各种标注和研究的需要。本研究创建的CEPCOJN语料库以源语文本为基准、以句子为基本单位,对原作和译作进行了句子层级的对齐。
语料对齐是非常耗时费力的工作,必须借助软件来辅助完成。目前有很多软件(例如Tmxmall、雪人 CAT、ABBYY Aligner、Trados、wordsmith 等)都可以实现双语自动对齐,所以首先需要选择一款合适的软件进行初步对齐工作。本语料库的建设主要采用了Tmxmall和雪人CAT对齐软件,其对齐界面如图3和图4所示。
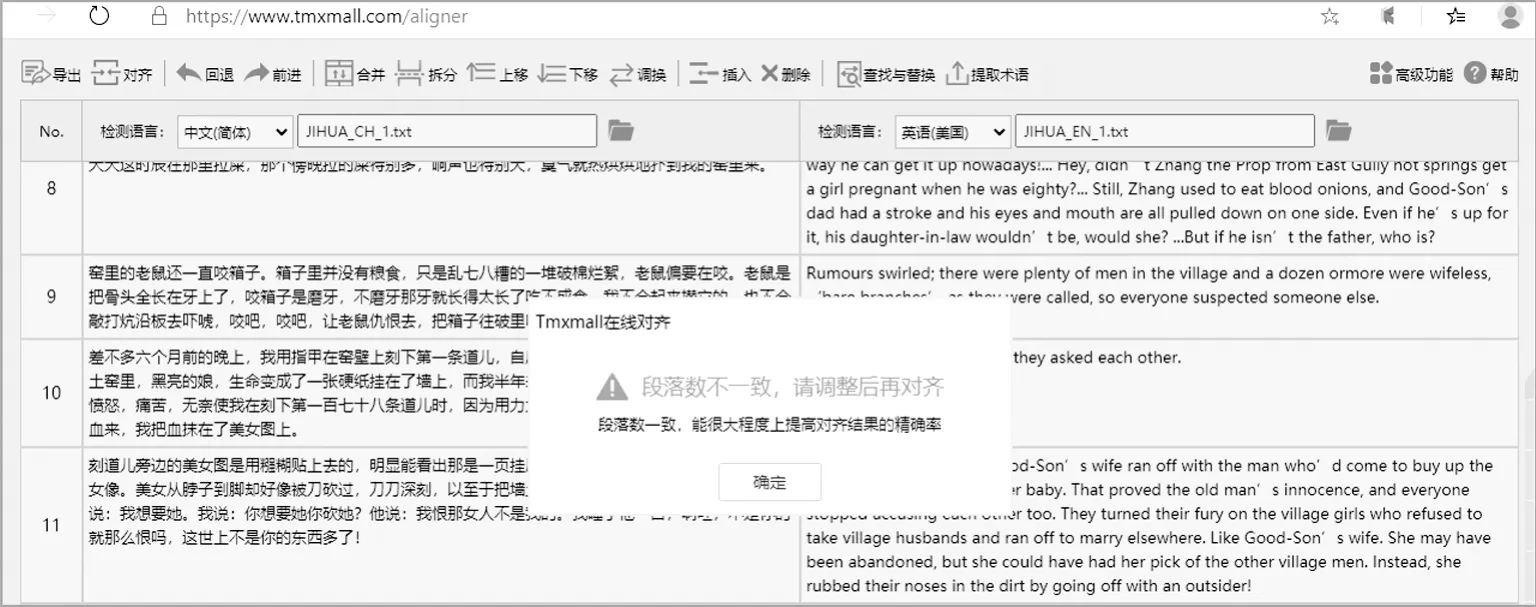
图3 Tmxmall软件双语对齐界面

图4 雪人CAT软件双语对齐界面
不同的软件进行自动对齐的原理和要求有所不同。Tmxmall是一款在线对齐软件,界面清晰明了是很多语料库建设者进行双语对齐的首选[8]。但是,Tmxmall要求句对齐之前先进行段落对齐。贾平凹小说的很多英译本和原作在段落上不仅不对应,而且差别很大[9]。比如《废都》译作中,葛浩文将原作中的对话都拆分成了段落,葛浩文在译者前言中就提到过这一点[10]。Tmxmall语料对齐工具需要先进行人工调整至段落对齐,才能运行句对齐,之后再次进行人工校对调整。雪人CAT对齐软件不需要先进行段落对齐,但是对齐后的结果不能直接保存为纯文本或表格文件,需要借助雪人对齐助手。文学作品的翻译策略相对灵活,译作中会有大量的拆句、合句、增译、减译或省译现象,再好的软件用来对齐文学作品的双语文本,自动对齐率一般都不高。语料的对齐直接影响语料库的质量,进而影响后期信息提取和研究的准确性。因此,在软件初步对齐之后,必须要逐句进行人工校对和调整。语料对齐之后,将对齐的语料按照统一的格式命名,保存为TXT文本,最好分为汉英混排平行文本,以及汉语和英语文本分开储存的平行文本,以满足不同检索软件的要求。
四、语料分词和标注
语料对齐之后,接下来就是根据研究的需要对语料进一步精加工。分词和标注是两种主要的精加工模式。分词主要用在汉语文本中,就是将连续书写的汉字按照有意义的词单元进行切分,以利于后期的检索。分词可以借助一些软件实现自动分词,人工辅助校对。标注就是“把各种表示语言特征的附码标注在相应的语言成分上,以便于计算机的识读”[11]。详细准确的信息标注,是提高语料库利用价值的关键。但是标注也不是越多越好,过多的标注也会影响文本的纯洁性,干扰读者理解文本[12]。目前只有POS词性赋码可以实现软件自动标注,其它具体语言特征和信息标注主要还是依靠人工进行。因此,建议根据研究的需要进行适当标注即可。本研究创建贾平凹小说汉英平行语料库的主要目的是研究贾平凹小说中方言词汇的英译现象,因此,本语料库主要进行了汉语文本的分词、词性赋码和方言词汇等几方面内容的标注。分词和词性赋码运用CorpusWordParser软件辅助进行,人工校对。
CEPCOJN语料库标注的重点和难点是对方言、俗语等特色信息及其翻译策略的标注。方言的运用是贾平凹小说语言的特色,也是其作品翻译的难点[13]。方言和俗语属于特色语言信息,目前尚无软件可以实现自动标注,必须人工逐个辨识和标注。人工标注耗时费力,但标注完成之后其研究价值远高于自动标注的信息。贾平凹小说中的方言俗语主要来自其故乡陕西省商洛地区方言,属于中原官话中的一个分支关中片。因此,CEPCOJN语料库方言词汇的标注主要参考《陕西方言集成(商洛卷)》[14]、《商州方言词汇研究》[15]和《现代汉语方言大词典》[16]等工具书中的方言词汇及其分类,结合贾平凹小说中方言词汇的实际情况对其进行标注,并通过检索软件找出对应的英语译文,对译文的翻译策略进行标注和统计分析。标注完成的语料和未加标注的语料分别存放,以方便后期不同研究的需要。
五、结语
本研究主要介绍了贾平凹小说汉英平行语料库(CEPCOJN)创建过程中的关键环节,包括语料库设计、语料采集、语料清洗、语料对齐、分词和标注等。尽管每个环节都可以借助一些相关软件辅助进行,但是大量的人工投入必不可少。每个环节都是下一个环节的基础,一个环节稍不认真出现差错,就会增加下一个环节的工作量,甚至会影响整个语料库的质量。因此,语料库建设的每一步都需要研究者有足够的耐心和非常认真的态度,同时要借助科技的力量,选择合适的软件辅助人工工作,这样可以大大提高双语平行语料库建设的效率和质量,保障下一步的语料库检索和研究有较高的科学性和准确性。CEPCOJN语料库建设的主要目的之一是进行基于该语料库的贾平凹小说方言英译研究。在满足建库目的的同时,CEPCOJN语料库的建设还尽可能考虑到语料库的可发展性,提高语料库的可利用率,为该语料库后期的发展和基于该语料的相关研究打下基础。
猜你喜欢
小学生优秀作文(高年级)(2022年9期)2022-10-08
意林彩版(2022年2期)2022-05-03
通信技术(2021年12期)2022-01-25
英语世界(2021年13期)2021-01-12
西部大开发(2018年5期)2018-07-03
快乐作文·低年级(2017年9期)2017-10-11
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
长江学术(2016年3期)2016-08-23
汽车维修与保养(2015年7期)2015-04-17
外语教学理论与实践(2014年2期)2014-06-21
