
基于DT-KNN-FDA建模的车漆光谱无损鉴别
2021-03-08 06:00颜文杰陈俊明宋亚军贾振军
激光技术 2021年2期
颜文杰,陈俊明,宋亚军,孔 昊,贾振军*
(1.中国人民公安大学 侦查学院,北京 102600;2.中国人民公安大学 治安与交通管理学院,北京 102600)
引 言
在交通肇事案件中,执法人员经常会在肇事现场、受害人衣物上发现并提取到车漆碎片。通过对车漆进行分析与鉴定,进一步确定其品牌、生产厂家等信息,进而追溯肇事车辆,从而为确认或排除嫌疑人和嫌疑车辆提供一定的线索,为案件的诉讼和判决提供一定的证据。因此,车漆的检验鉴定对侦破交通肇事案件具有十分重要的意义。
不同品牌和生产厂家的车漆有不同的配方和工艺,即在成分和其含量上均存在一定差异。即不同品牌的车漆样本间存在一定差异,对这一差异的挖掘将有助于执法人员推断并确定现成提取的碎片检材的品牌和生产厂家。目前,车漆检验主要有光学显微镜法[1]、扫描电镜法[2]和光谱成像技术[3]等。光学显微镜法只能对车漆碎片的形态学特征进行初步解读,这易受主观因素影响,且耗时耗力;扫描电镜法在确定车漆中元素含量上有一定优势,但对其品牌和生产厂家信息的解读不够全面。高发的交通肇事案件和提取到的大量车漆碎片物证给执法人员的工作带来了极大的挑战。如何降低鉴定所需的时间精力等成本,提高鉴定效率,实现对车漆碎片的快速无损鉴定,是当下执法人员关注的重点之一。
鉴于此,实验中借助红外光谱分析技术,通过对特征波数的选择,建立基于决策树分析(decision tree,DT)、k近邻分析(k-nearest neighbor,KNN)、Fisher判别分析(Fisher discriminant analysis,FDA)的车漆样本光谱分类鉴别模型,从而实现对车身油漆品牌较为准确区分与归类,为法庭科学中车漆无损、准确地检验鉴定提供一定的参考和借鉴。
1 实 验
1.1 实验样本
从市场上收集了常见的诚得利等4种品牌共计60个不同品牌和生产厂家的车漆样本。采集车身前部、两侧、后部共计4处位置的车漆碎片,为避免采集过程中人为因素带来的误差,每处随机采集3份样本。首先,将采集的样本用酒精棉擦拭样品,从而除去样本表面残留的灰尘等污物;而后将样本放入盛有去离子水的烧杯中,并超声清洗2次,每次10min;最后用酒精棉将样本擦拭干净,进样检测。
1.2 实验设备
采用Nicolet 5700型傅里叶变换红外光谱仪(Thermo Fisher Scientific公司),配有衰减全反射附件(Thermo Fisher Scientific公司)[4-5]。光谱数据处理软件OMNIC 8.2,光谱采集范围为4000cm-1~400cm-1,每个样本均采集3次,取其平均值作为实验数据[4-5]。
2 结果及分析
2.1 光谱预处理
实验中获取的数据维度较高,重复信息较多,会增加后期建模计算的时间和复杂度,也会降低模型的精度,这对快速准确地区分各样本有一定影响。因此,筛选并提取特征波数,剔除重复信息十分有必要[6]。ZHOU等人[7]提出了一种基于小波耦合k近邻的特征提取方法建立分类模型用于发霉茶的分类研究。实验中基于不同的小波函数,采用5层小波分解预处理光谱数据,同时借助线性判别分析构建分类模型,有效提取了特征波长并实现了对不同霉变程度的干茶有效分类。ZHENG等人[8]采用主成分分析进行特征提取,缩小光谱数据的维数,同时借助支持向量机,线性判别分析和k最近邻分析建立了分类模型,实现了对高肾素高血压93.5 %地准确筛查,实验结果较为理想。
实验中采用相关性分析来剔除重复信息,筛选特征波数,通过计算样本数据间的Pearson相关系数和R值来判断样本数据间的相关程度[9-10],以0.95和0.01分别作为Pearson相关系数和R值的阈值。经过反复比较与分析,实验中发现,R值无法较好确定样本数据中信息重复的数据,而Pearson相关系数则较好地区分出了重复数据。因此选择Pearson相关系数为参考基准,开展对特征波数地筛查和提取工作。表1中列举了其中诚得利品牌一个样本经过筛选后的56组特征波数及其光谱数据。
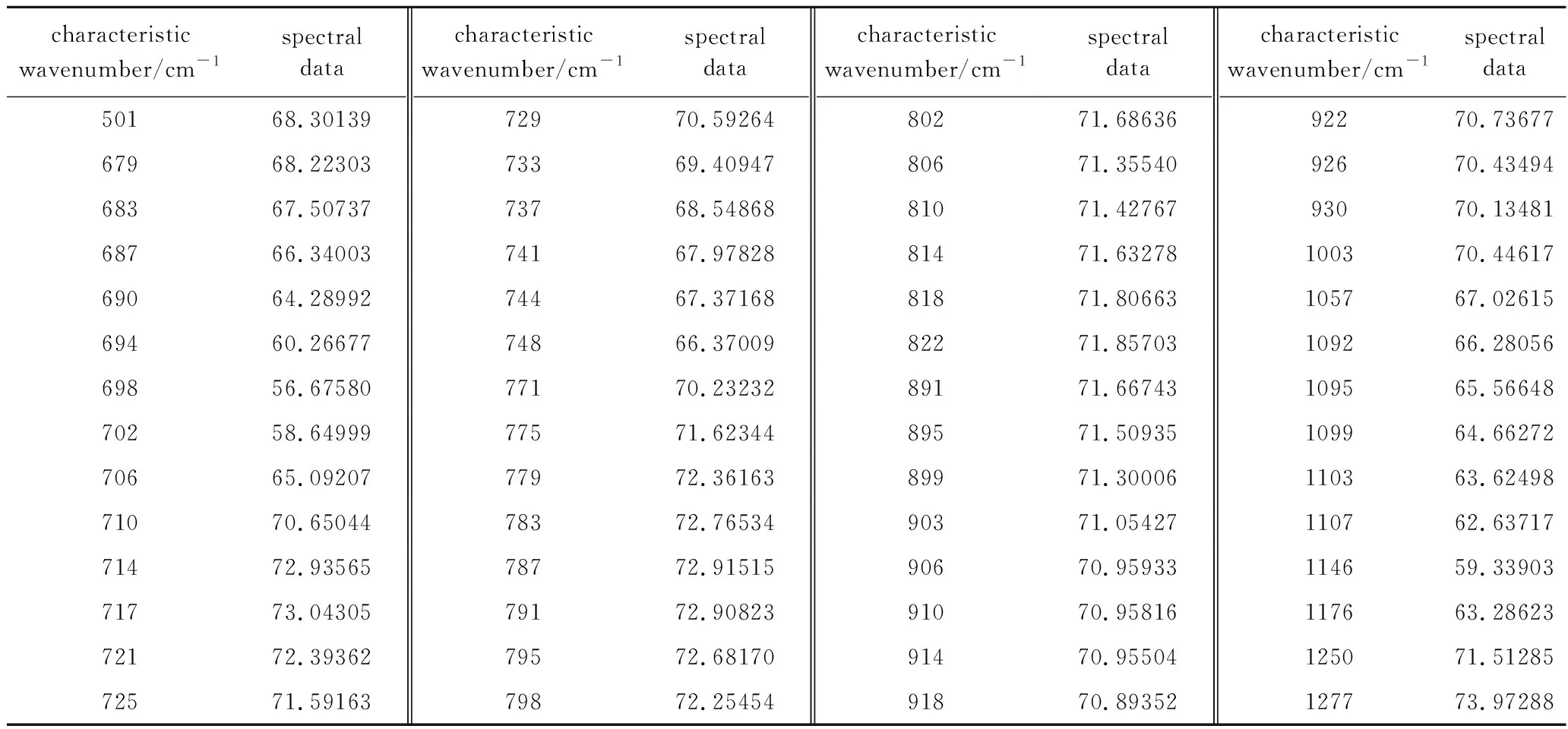
Table 1 56 characteristic wavenumbers and its spectral data of a sample from Chengdeli were selected by correlation analysis
以经过关性分析筛选后的56组特征波数光谱数据为基础,建立基于DT、KNN和FDA的分类模型,开展对不同品牌和生产厂家样本的分类工作。
2.2 决策树分析
DT分析是一种较为有效的分类算法,其分类结构相对简单、明确和直观,不对输入数据的分布做任何假设,并且对于输入要素和类标签之间的非线性和嘈杂关系,具有灵活性和鲁棒性[11]。
以品牌为单位,采用DT构建分类模型,得到了各样本的分类结果(见表2)。

Table 2 Classification results of 4 brand samples by DT
由表2可知,DT分类模型对不同品牌的样本分类情况均不一样,其中“Munchsett”品牌的样本实现了100.00%的准确区分;“Sanhe”品牌的样本区分准确率为94.30%;“Chengdeli”和“Sangmei”品牌的样本分类正确率均为0.00%。DT分类模型总体分类正确率为77.80%。
2.3 k近邻分析
KNN分析是一种基于距离度量的有效分类方法,主要原理是从训练集中找到和新数据最接近的k条记录,根据其主要分类决定新数据类别,分类过程中只与近邻几个样本相关,不使用额外数据,不需要事先确定类别数量便能达到理想分类效果[12-13]。
以品牌为单位,采用KNN构建分类模型,得到了各样本的分类结果(见表3)。

Table 3 Classification results of 4 brand samples by KNN
由表3可知,KNN分类模型对不同品牌的样本分类情况均不一样,其中“Chengdeli”和“Munchsett”品牌的样本分类正确率均为0.00%;“Sanhe”品牌的样本区分准确率为96.80%,“Sangmei”品牌的样本分类正确率均为25.00%。KNN分类模型总体分类正确率为72.31%。
2.4 Fisher判别分析
FDA分析主要思想是将多维数据投影到某个方向上,将类与类之间尽可能分开,类内尽可能聚合,然后选择合适的判别规则对未知样品进行分类判别[14]。
以品牌为单位,构建Fisher判别分析模型,得到了各样本的判别函数摘要(见表4)。
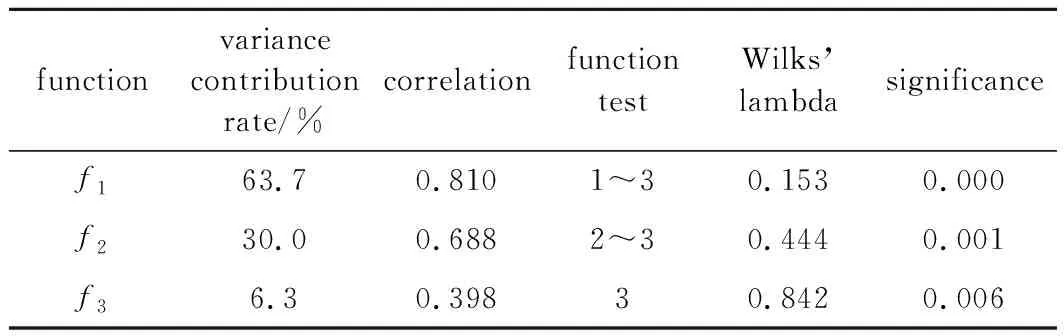
Table 4 The abstract of FDA functions about 4 brand samples
“variance contribution rate”即方差贡献率,指在此判别函数上各样本的可区分度。“correlation”即相关性,指不同分组与各个函数之间的相关性,相关性越强,则组别在此维度上的差异越大[15]。“Wilks’ lambda”是组内平方和与总平方和之比,其值越小,说明某个量对于模型的影响越显著[15]。“significance”即显著性,若 0.01 其中f1方差贡献率最高(63.7%),在f1上各样本的可区分度较高,其次为f2(30.0%)和f3(6.3%)。f1和f2的相关性均高于0.65,表明不同分组与f1和f2的相关性较强。函数检验中,f1和f2的Wilks’ lambda分别为0.154和0.842,表明函数1和函数2对模型影响的显著性较高。f1,f2以及f3的significance均小于0.01,表明差异极显著,能很好解释各样本的分类情况。综上所述,同时选择f1,f2以及f3作为判别函数,构建判别分类模型,得到了4个品牌样本的判别分类图(见图1)。 Fig.1 Distribution of 4 brand samples under FDA model 由图1可知,不同品牌的样本分布情况各有不同。其中“Sanhe”品牌的样本数据聚敛程度较高,分布较为集中;“Chengdeli”、“Munchsett”和“Sangmei”3个品牌的样本分布相对分散。Fisher判别分类模型对“Chengdeli”品牌的样本实现了100.00%的准确区分,“Munchsett”品牌的样本区分准确率为75.00%,“Sanhe”品牌的样本区分准确率为88.14%,“Sangmei”品牌的样本区分准确率为70.00%。各样本的总体区分准确率为85.00%,分类结果相对较为理想。相对于DT和KNN分类模型,Fisher判别分类模型准确率更高,对各样本的区分能力更强。其对样本光谱数据的分类效果优于DT和KNN分类模型。 本文中采用红外吸收光谱与DT-KNN-FDA方法,实现了对车漆样本较为准确地分类与识别。通过相关性分析筛选出58组的特征数据,以此为基础构建分类模型。DT分类模型、KNN分类模型和FDA分类模型对各样本的总体区分准确率分别为77.80%,72.31%和85.00%。综上所述,红外吸收光谱结合相关性分析及FDA模型可较好地实现对车漆不同品牌间较为准确地区分,且分类结果较为理想。本实验中在一定程度上消除了传统鉴别方法中因主观判断造成误差、人工鉴别效率较低以及对检材损耗较大的缺点,为车漆的分类鉴别提供了一种新的参考思路,同时,本方法也为其它鉴别手段提供了一定的借鉴。值得注意的是,车漆是多组分样本,对多组分分析是一个挑战,因为不同的分子可能导致相似的光谱形状,使它很难从一个复杂的系统中分离出某些分子信息。因此,如何改进红外光谱技术以满足日益增长的物证分析需求,是今后研究的热点之一。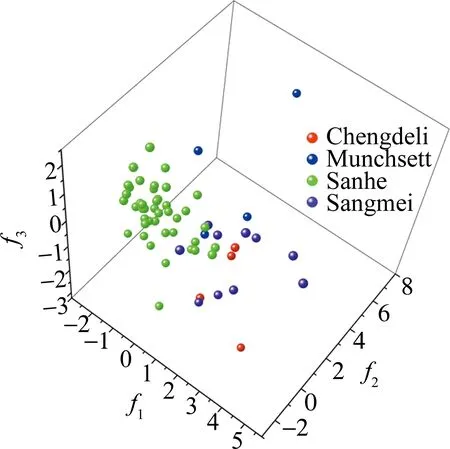
3 结 论
猜你喜欢
中学生数理化·八年级物理人教版(2023年3期)2023-03-21
北京航空航天大学学报(2022年8期)2022-08-31
九江学院学报(自然科学版)(2022年2期)2022-07-02
汽车维修与保养(2020年11期)2020-11-23
汽车与驾驶维修(汽车版)(2017年4期)2017-11-09
中学生数理化·八年级物理人教版(2017年6期)2017-11-09
百科探秘·航空航天(2016年5期)2016-11-07
中国光学(2015年5期)2015-12-09
汽车维护与修理(2015年6期)2015-02-28
中国检察官(2015年12期)2015-02-27
