
改进和声搜索算法在梯级水库群优化调度中的应用
2021-03-05 01:47王丽萍,吴月秋,张验科,王渤权
人民长江 2021年2期
王 丽 萍,吴 月 秋,张 验 科,王 渤 权
(1.华北电力大学 水利与水电工程学院,北京 102206; 2.南京南瑞水利水电科技有限公司,江苏 南京 210000)
近年来,我国水电能源作为一种占比较大的可再生能源,在我国电力系统中发挥着越来越重要的作用[1]。随着水电能源的不断开发,我国已经形成了许多大型梯级水库群。这些梯级水库群之间不仅存在着水力联系,还存在着电力联系,这使得梯级水库群优化调度成为一个多约束、多阶段、耦合性强的复杂非线性问题,其复杂性对求解方法的要求也越来越高[2-4]。为了解决这一问题,很多学者开展了相关研究,并取得了一系列成果,如传统优化算法和智能进化算法。逐步优化算法(Progressive Optimization Algorithm, POA)[5]、逐次逼近法(Dynamic Programming with Successive Algorithm,DPSA)[6]、并行动态规划法[7]等传统优化算法虽然在一定程度上缓解了维数灾,但是POA和DPSA对初始解的依赖性比较强,且随着变量维数和离散状态的增加计算效率会较低;而并行动态规划算法虽然可提高计算效率,但其受多核运算硬件平台规模的限制。智能进化算法如遗传算法[8]、模拟退火[9]、水循环算法[10]等,算法模型简单、容易实现,但受初始种群影响,再加上多种随机因素的存在,算法解的稳定性有时较差。
和声搜索算法(Harmony Search Algorithm,HSA)是一种新的智能优化算法[11],具有模型简单、容易实现的优点,并在解决多维函数优化问题上展示了较遗传算法、模拟退火算法等更好的优化性能[12]。该算法模拟了音乐创作中乐师们凭借自身记忆,通过反复调整各乐器的音调,最终达到美妙和声状态的过程。该模拟过程类似于水库群优化调度模型的求解过程,对于提升梯级水库群优化调度模型的求解精度和效率具有重要意义。HSA对初始记忆库(初始解)的依赖性比较强[13],初始解的分布不均和步长调整策略导致算法在进化后期盲目搜索[14],不能有效地调整解的结构,使初始解的多样性逐渐消散,容易陷入局部最优。为此,本文提出加入均匀设计法和混沌机制的改进和声搜索算法(Improved Harmony Search Algorithm,IHSA),并将其应用于梯级水库群发电优化调度模型求解,验证该算法的可行性和有效性。
1 改进的和声搜索算法
HSA是一种将随机与局部搜索相结合的启发式优化算法,具有参数少、计算简单等优点,在解决复杂、多约束、非线性等优化问题上具有明显的优势。针对和声搜索算法对初始解的依赖性比较强和容易陷入局部最优的缺点,本研究的改进之处可概括为两点:一是采用均匀设计法生成初始解集,以增加初始解的多样性和有效性;二是搜索过程中引入了混沌机制,以提高算法的全局搜索性能,避免陷入局部最优。
1.1 算法改进
1.1.1基于均匀设计生成初始解
由于HSA主要是基于邻域搜索的,初始解的质量对搜索性能影响较大。在可行域内随机生成初始解的方式,将导致部分个体不满足约束条件而被淘汰,这也降低了初始解集的多样性和算法的搜索效率。因而,本文在初始解生成时引入了均匀设计 (Uniform design,UD)的思想。UD[15]仅考虑试验点在试验范围内的均匀散布,是一种基于数论和多元统计学的新型实验方法,选取的试验点更有代表性,更能反映样本系列的主要特征。该方法与正交设计试验方法相比,保留了正交设计的数据均衡分散性,但不考虑数据的整齐可比性,这大大减少了试验次数,提高了试验效率。均匀设计表由因素和水平两要素组成,每个因素每个水平的试验次数为一,任意两个因素每行每列的试验点具有唯一性,试验次数等于最大水平数。初始解生成的过程可看为一个试验过程,而各个解生成的过程即为试验点选择过程。由此可见,种群规模越大,初始解的多样性越强,且生成的初始解都为有效解,具体初始解生成的步骤可参见文献[16]。
1.1.2基于混沌生成机制的全局搜索
混沌搜索看似随机但其内部结构非常精致,能在一定范围内按照自身的“规律”不重复遍历所有状态[17]。由于HSA在迭代搜索时主要是通过向最优和声不断靠近来更新和声记忆库。这种更新策略可能造成和声记忆库中较差的解向量在迭代很多次后也没有得到更新,容易过早陷入局部最优。引入混沌序列,利用混沌搜索的随机性、遍历性和规律性来增加和声记忆库的多样性,以增强算法的全局最优性。本文采用Tent映射来生成混沌序列,Tent映射生成的混沌序列比较均匀,多样性较强,其生成公式见式(1)。生成混沌序列的方法是先把变量从解空间映射到[0,1]空间以生成混沌序列,再将混沌序列映射回优化空间:
(1)
式中:ck为第k次混沌迭代的混沌变量;k=1,2,3,…,M;M为总的混沌迭代次数。
1.2 IHSA计算步骤
IHSA算法的具体计算流程如图1所示,可分6个步骤完成,依次详细介绍如下。
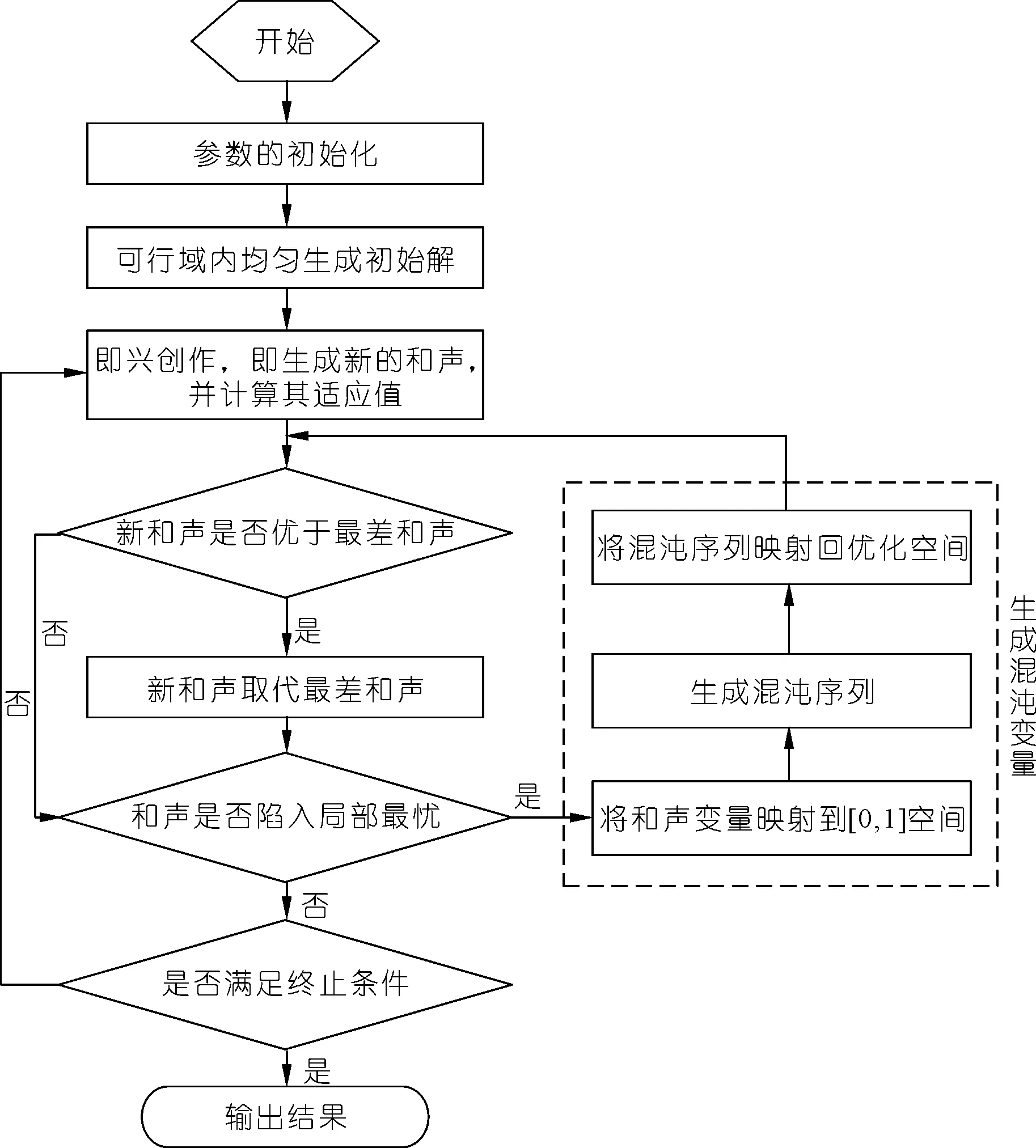
图1 IHSA计算流程Fig.1 Calculation flow of IHSA
步骤1:参数的初始化,包括和声记忆库HMS大小、和声记忆库取值概率HMCR、音调微调概率PAR、音调微调带宽BW、最大迭代次数Tmax。本文PAR和BW[13]取值采用动态调整的方法,具体实现方法如下:
(2)
(3)
式中:PARmax和PARmin分别是最大、最小微调概率;t为当前迭代次数;Tmax为最大迭代次数;BWmax和BWmin分别是最大、最小调整幅度。
步骤2:采用均匀设计法在可行域内生成初始和声记忆库。
步骤3:即兴创作,根据和声记忆库生成新的和声。具体数学关系式如下:
xnew(i)=
(4)
式中:xnew(i)为新生成的和声(即解向量);xr(i)为初始和声记忆库中的任意一个;rand(i)为[0,1]之间生成的随机数;Xmax、Xmin分别为和声记忆库的上、下限。
如果xnew(i)是从当前和声记忆库中选取的,还需要通过调整音调进行微调。具体微调方式[18]如下:
(1)连续型决策变量:
(5)
(2)离散型决策变量:
(6)
式中:xr(i)为选取初始解集中的任意一个解;xr(i+k)为xr(i)的临近值。
步骤4:计算每个和声的适应度Ei,并更新和声记忆库。更新的准则为贪婪准则,即如果Enew>Eworst(Enew为新和声的适应度,Eworst为最差和声的适应度),新和声Xnew代替最差和声Xworst,否则不变。根据最优和声的信息更新和声记忆库,也即更新种群。
步骤5:判断是否陷入局部最优,陷入局部最优的判别条件是连续N次Enew 步骤6:判断是否满足终止条件,即是否达到最大迭代次数。若是则计算结束,输出结果;否则返回步骤3。 IHSA在水库群优化调度模型计算中具有通用性,为了验证算法的可行性和有效性,本文仅以梯级水库群中长期发电调度为例进行研究和分析。 2.1.1目标函数 梯级水库群中长期发电优化调度优化准则可定义为:在各水库各时段来水已知和满足约束条件的情况下,使调度期内梯级总发电量最大。 (7) 式中:P为调度期内梯级总发电量;Ni,j为j时段i电站的出力;Δt为时段长度;T为调度期的总时段数;M为水库总数。 2.1.2约束条件 梯级水库群中长期发电优化调度的约束条件主要包括水量、水位、流量等约束。 (1)水量平衡方程: Vi,j+1=Vi,j+(Qi,j-qi,j)Δt (8) (2)水库蓄水量约束: Vi,j,min≤Vi,j≤Vi,j,max (9) (3)水库下泄流量约束: qi,j,min≤qi,j≤qi,j,max (10) (4)水电站预想出力约束: Ni,j,min≤Ni,j≤Ni,j,max (11) (5)边界条件的约束,主要指水库调度期初、末水位的限制。 (6)非负约束,即计算所用公式中的变量均为非负值。 上述式中:Vi,j,Vi,j+1分别表示水库i第j时段初、末的蓄水量;Qi,j表示水库i第j时段的来流量;qi,j表示水库i第j时段的下泄流量;Ni,j,min,Ni,j,max分别表示水库i第j时段的最小、最大库容限制;qi,j,min表示水库i第j时段下游综合利用要求的最小下泄流量;qi,j,max表示水库i第j时段的最大下泄流量要求;Ni,j,min表示第i个水库电站的最小出力;Ni,j,max表示第i个水库电站第j时段的预想出力,预想出力与发电水头一一对应。 对于水库调度来说,不同的库容离散点对应不同的水位值,一个调度方案即为一组满足各种约束条件的水位值。采用IHSA进行求解时,和声Xi可表示为N个水库T时段内的水位过程,具体见式(12)。和声Xi中水库i的均匀设计示意见图2,m为离散点数。 (12) 图2 水库初始解的均匀设计示意Fig.2 Uniform design of reservoir initial solution 模型的求解步骤如下: 步骤1:参数的设置,包括和声库的大小、最大迭代次数、最大最小微调概率、最大最小调整幅度及和声记忆库取值概率。 步骤2:在可行域内采用均匀设计法生成初始和声记忆库。调度期内所划分的时段数为均匀设计试验的因素数,库容离散点数为试验的水平数,一个调度方案相当于一个试验点。 步骤3:即兴创作,根据和声记忆库生成新的和声,生成新和声时要考虑水位、流量、出力等约束条件。水库调度计算时一般把决策变量作为离散型处理,故对新和声进行音调微调时按照离散方式处理。 步骤4:更新和声记忆库。如果新和声的发电总量Pnew比和声记忆库中最差和声的发电总量Pworst大,新和声代替最差和声,否则不变。 步骤5:判断每个和声是否陷入局部最优。若是,则生成混沌变量并返回步骤4,否则直接进入步骤6。 步骤6:检查是否达到迭代终止条件(即最大迭代次数Tmax)。如果是输出调度结果,包括qi,j、Vi,j、E总等;否则返回步骤3,直到达到迭代终止条件。 为了验证算法的可行性和有效性,本文选取李仙江流域的崖羊山与石门坎两座梯级水库为实例研究对象,进行编程计算,选取1a为调度周期,以月为调度时段。这两座水库都具有较好的调节性能,主要特征参数如表1所示。 表1 梯级电站基本参数Tab.1 Basic parameters of cascade hydropower stations 采用IHSA对梯级水库群优化调度模型求解,并将结果与HSA和动态规划法(DP)的结果进行对比分析。各种算法的具体参数设置如下:初始种群规模都为150,最大迭代次数都为200,PARmax和PARmin分别取0.9和0.4,BWmax和BWmin分别取0.1和0.001,HMCR=0.9; DP法的离散点个数为100。为了避免智能优化算法的随机性,将程序独立运行10次,取平均值和标准差来进行比较分析。 由表2可知:① 从发电量上看,IHSA的最优值与DP法的值仅相差0.037亿kW·h,比HSA的最优值提高了0.191亿kW·h;表明IHSA的值接近于全局最优解,全局性能比HSA好,改善了HSA容易陷入局部最优的缺陷。② 从结果稳定性上看,IHSA的标准差比HSA的标准差降低了98.22%,优化结果更趋于稳定;这主要是因为初始解的分布比较均匀且后期加入混沌序列避免算法陷入局部搜索。③ 从计算时间上来看,这3种算法中,IHSA的寻优时间分别比DP法和HSA减少了1 092 s和2 s,提高了计算效率。这主要是因为DP法随着水库数目的增加呈指数增加,即容易出现“维数灾”,而IHSA模型相对比较简单,计算规模随着水库数目的增加呈线性增加。总体来说,相比HSA来说,IHSA既增加了发电量,又提高了结果的稳定性和计算效率,优化效果明显优于HSA。 表2 不同方法的优化结果Tab.2 Optimization results of different methods 当最大迭代次数取200,不同种群规模下的优化结果见图3。由图3可知,两种方法的发电量都随着初始种群的增加而不断增加,但IHSA在种群规模为50时就能找到最优解,而HSA在种群规模为80时才能找到最优解。这主要是因为IHSA中初始解的生成采用均匀设计的方法,增加了初始解的多样性和有效性。由此可以看出采用均匀生成初始解可以提高算法的搜优效率。 图3 不同种群规模的优化结果Fig.3 Optimization results of different population sizes 为了分析不同改进策略对算法结果的影响,对HSA和IHSA的收敛过程进行了对比(见图4)。从图4可知,IHSA寻优过程比较平稳,且收敛速度比较快。这主要是因为动态调整PAR、BW和加入混沌序列增强了算法的收敛性能,使算法能快速向全局最优解收敛。 图4 不同迭代次数的优化结果Fig.4 Optimization results of different iterations (1) 本文针对HSA的缺点,结合均匀设计和混沌理论对其改进,提出了计算速度更快且精度更高的IHSA,尤其适合于对时效性要求更高、系统更为复杂的梯级水库群智慧调度研究的更深一步探索。 (2) 实例研究虽然验证了IHSA应用于梯级水库群优化调度的优越性,同时IHSA算法具有其他算法的通用特性,在单库和混联水库群等优化问题求解中同样具有一定的普适性。 (3) 梯级水库群多目标优化调度由于各目标之间的不可公度性,其计算起来较为复杂,如何将IHSA应用到梯级水库群多目标优化调度非劣解的获取,还有待进一步深入研究。2 基于IHSA的梯级水库群发电优化调度
2.1 梯级水库群中长期发电优化调度模型
2.2 模型求解

3 实例研究
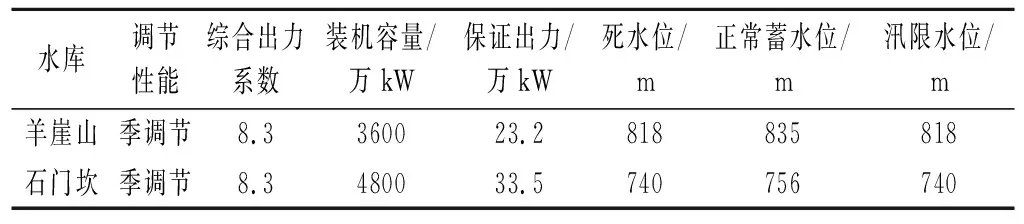
3.1 梯级水库群概况
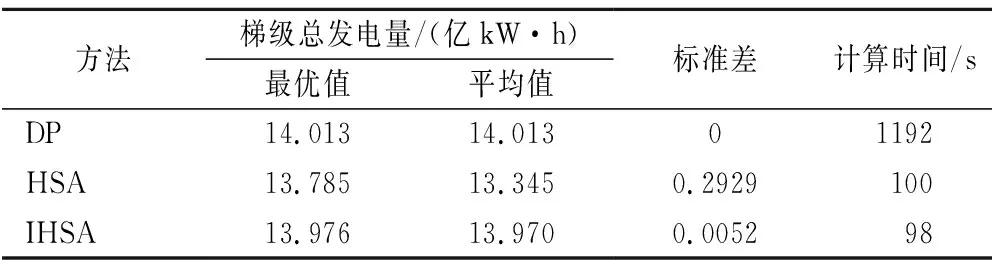
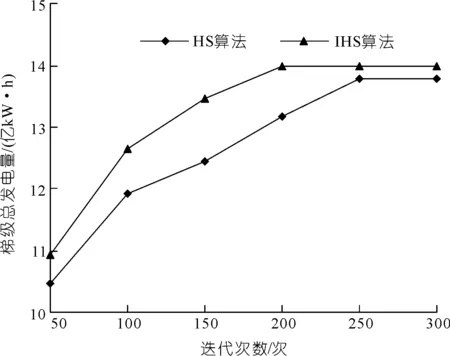
3.2 结果分析

4 结 论
猜你喜欢
中国科技纵横(2022年23期)2022-02-10
智能建筑电气技术(2022年2期)2022-02-06
苏州市职业大学学报(2021年3期)2021-10-19
商用汽车(2021年4期)2021-10-13
商品与质量(2021年20期)2021-04-22
数学物理学报(2020年6期)2021-01-14
基层中医药(2020年7期)2020-09-11
中国生殖健康(2019年8期)2019-01-07
通信电源技术(2018年3期)2018-06-26
中学生数理化·中考版(2017年12期)2017-04-18
