
基于点云与图像交叉融合的道路分割方法
2021-02-28 00:46:10黄影平郭志阳
光电工程 2021年12期
张 莹,黄影平,郭志阳,张 冲
基于点云与图像交叉融合的道路分割方法
张 莹,黄影平*,郭志阳,张 冲
上海理工大学光电信息与计算机工程学院,上海 200093
道路检测是车辆实现自动驾驶的前提。近年来,基于深度学习的多源数据融合成为当前自动驾驶研究的一个热点。本文采用卷积神经网络对激光雷达点云和图像数据加以融合,实现对交通场景中道路的分割。本文提出了像素级、特征级和决策级多种融合方案,尤其是在特征级融合中设计了四种交叉融合方案,对各种方案进行对比研究,给出最佳融合方案。在网络构架上,采用编码解码结构的语义分割卷积神经网络作为基础网络,将点云法线特征与RGB图像特征在不同的层级进行交叉融合。融合后的数据进入解码器还原,最后使用激活函数得到检测结果。实验使用KITTI数据集进行评估,验证了各种融合方案的性能,实验结果表明,本文提出的融合方案E具有最好的分割性能。与其他道路检测方法的比较实验表明,本文方法可以获得较好的整体性能。
自动驾驶;道路检测;语义分割;数据融合

1 引 言
道路检测是自动驾驶中环境辨识的重要内容,是车辆实现自动驾驶的前提。目前,自动驾驶车辆大多采用多传感器数据融合的方式实现对道路的检测。其中最为常见的是将激光雷达数据与RGB图像数据进行融合,现有的研究表明将这两种传感器的数据进行融合,可以提高道路检测精度。最新的融合方法是采用卷积神经网络(convolutional neural network,CNN)作为融合工具对两种模态的数据进行融合,采用语义分割的方式实现对道路的检测。然而,如何将两种传感器数据更好地融合仍是本研究领域亟待解决的问题。针对上述问题,本文提出了像素级、特征级和决策级多种融合方案,尤其是在特征级融合中设计了四种交叉融合方案,对各种方案进行对比研究,得到最佳的融合方案。在网络构架上,采用编码解码结构的语义分割卷积神经网络作为基础网络,将点云深度图以法线图的方式来表示,法线图特征与RGB图像特征在不同的层级进行交叉融合。此方法可以更好地学习到激光雷达点云信息与相机图像信息的关联性,交叉补充点云和图像信息以及减少特征信息的丢失。
本文主要贡献如下:1) 提出了基于CNN的点云与图像数据融合的像素级、特征级和决策级多种融合方案,实现对交通场景中道路的检测。尤其是在特征级融合中设计了四种交叉融合方案,对各种方案进行对比研究,得到最佳的融合方案。2) 使用KITTI数据集进行实验评估,并对多种融合方式的实验结果进行对比分析。实验结果表明,本文提出的最佳融合方法(交叉融合方案E)可以显著提高道路的分割效果。
2 相关工作
传统的路面检测方法是依据场景中的几何性质将路面与直立目标加以区分,以实现路面检测的目的。近年来,CNN强大的特征提取能力与表征能力使其成为路面分割的主流方式。深度学习CNN的道路分割方法又分为基于图像的语义分割方法和基于激光雷达¾图像融合的语义分割方法。
1) 基于图像的语义分割方法
基于图像的语义分割是将道路检测看做一个语义分割任务。语义分割网络多采用编码器¾解码器结构。编码器提取有效特征,解码器对特征进行复原,再通过全连接层综合所有特征及优化函数实现对道路的分割(分类)。U-Net[1]是编码器¾解码器结构中常见的一种分割模型,现如今已经有许多基于U-Net[1]结构而设计的新型卷积神经网络。U-Net++[2]针对U-Net中解码器的连接方式作出改进,增加了类似于DenseNet[3]中的密集连接机制,对精度的提升有所贡献。理论上增加网络深度,可以进行更加复杂的特征提取,分割性能也会变得更好。但是网络的加深往往会带来退化问题,并且会出现过拟合现象。Res-UNet[4]受到ResNet[5]原理的启发,通过短路机制加入残差单元,极大地消除了深层神经网络所带来的退化过拟合问题。Chen 等人[6]使用DeepLabv3作为编码器模块和一个简单有效的解码器模块细化分割结果,并将深度可分卷积应用于ASPP模块和解码器模块中,得到一个更快、更强的编解码器网络进行语义分割。SegNet[7]在解码器中使用编码器中进行最大池化的像素索引来进行反池化,从而省去学习上采样的需要,节省了计算时间,并用Softmax分类对每个像素输出一个类别的概率。
OFA Net[8]使用一种"1-N替代"的策略进行训练,探讨了检测任务和语义分割之间的相互增强效果,极大地解决了数据集过少带来的一系列问题。MultiNet[9]提出了一种将分类、检测和语义分割联合起来的方法,三个任务的编码器阶段是共享的,利用深层的CNN产生能够在所有任务中使用的丰富共享特征。这些特征再被三个以任务为导向的解码器使用,解码器实时产生结果,共享计算降低了执行所有任务所耗时长,性能方面还有待提高。RBNet[10]同时进行道路检测和道路边界检测,研究道路之间的语境关系结构及其边界排列,然后通过贝叶斯模型同时估计图像上像素的概率属于道路和道路的边界,消除了边界以外的潜在误判。Multi-task CNN[11]提出了紧凑的多任务CNN架构,在嵌入式系统的计算资源约束下,有效检测和估计物体以及基本汽车环境模型的可干燥地形,并引入了基于检测解码器和分析几何的简单扩展的3D边界框估计方案。
2) 基于激光雷达与图像融合方法
多传感器融合是对多源的信息数据利用一定的方法、准则进行处理,以实现所需要的估计决策。在自动驾驶领域,大多采用激光雷达传感器、相机等数据信息进行融合,以感知周围环境。Schlosser等人[12]将激光雷达的3D点云数据预处理成了HHA(水平视差、地面高度、角度)数据,与RGB图像一同输入,在CNN网络的不同特定层采用像素相加的融合方式,证明了在网络的中间层融合会得到最强的效果。LidCamNet[13]采用了特征融合的方式,采用可训练的线性叠加,将实验结果与前期、后期融合的结果进行对比。可训练的参数在数据融合时有一定的灵活性,较为良好的分割结果进一步验证了该思路在语义分割领域的可行性。Chen等人[14]采用了渐进式激光雷达自适应级联融合结构,用激光雷达数据去辅助图像数据进行道路分割,使用可训练参数的同时将激光雷达特征与RGB特征进行自适应处理,在强光或者强阴影条件下达到更好的融合效果。Neven等人[15]提出了以RGB图像为指导,利用其目标信息去纠正点云信息的预测的融合方式,降低了点云的误判概率。Wang等人[16]利用激光雷达传感器和立体双目相机,用两种增强技术的立体匹配网络来估计深度,而不是直接融合,一定程度上提高了检测精度。
Zhang等人[17]采用了基于深度学习的RGB-D深度图补全的方法,输入RGB-D图去预测RGB图中所有平面的表面法线和物体边缘遮挡,用深度图作为正则化,求解全局线性优化问题,最终得到补全的深度图,为自动驾驶环境感知提供了更好的数据信息。文献[18]为了能够同时提取RGB图像和深度图特征,将两者融合,并将融合后的图像变成HHG图像。文献[19]提出了一种基于双传感器信息融合的三维物体姿态估计¾视锥体PointNet目标定位算法,进一步证明了多数据融合的可行性。SNE-RoadSeg[20]采用编码器¾解码器结构,在编码器部分对双传感器数据输入进行特征融合,实现精准的自由空间检测。并提出了将点云深度图转换为法线特征图的方法,将表面法线估计问题转化为最小二乘平面拟合估计问题,对三维曲面上的每个点估计法线,难点在于道路和人行道上三维点具有非常相似的表面法线。
3 本文方法
网络基础结构如图1所示,由采用残差网络(ResNet[5])的编码器、采用密集连接的跳跃连接的解码器(如图2所示)、表面法线估计器(surface normal estimator,SNE,如图3所示)组成。输入图像为RGB-D图,激光雷达深度图经过表面法线估计器处理为法线图;两路输入信号经两路编码器提取特征,解码器还原特征,最后使用sigmoid激活函数生成道路分割结果。
法线的作用在于丰富特征信息并矫正光源产生的阴影和其他视觉效果,深度图只有单层的少量深度特征信息,处理得到的法线图根据每个点所处平面不同、表面法线方向也不同的原理,更好地区分路面与非路面。RGB编码器和表面法线编码器的主干为ResNet[5],它们的结构彼此相同。如图1所示,输入数据先经过一个初始块(由卷积核7´7、步长2的卷积层,批量规范化层(BN)和ReLU激活层组成),然后依次使用一个最大池化层和四个Res-layer来逐渐降低分辨率并增加特征图通道的数量,四个Res-layer分别由个bottleneck block构成,bottleneck block由卷积核分别为1´1、3´3、1´1的三个卷积层组成。ResNet[5]有多种体系结构,本文采用ResNet-152,特征映射通道的数量c_0~c_4分别为64、256、512、1024、2048,四个Res-layer的bottleneck block数目分别为3、8、36、3,代表图像输入的分辨率。

图1 网络基础结构图
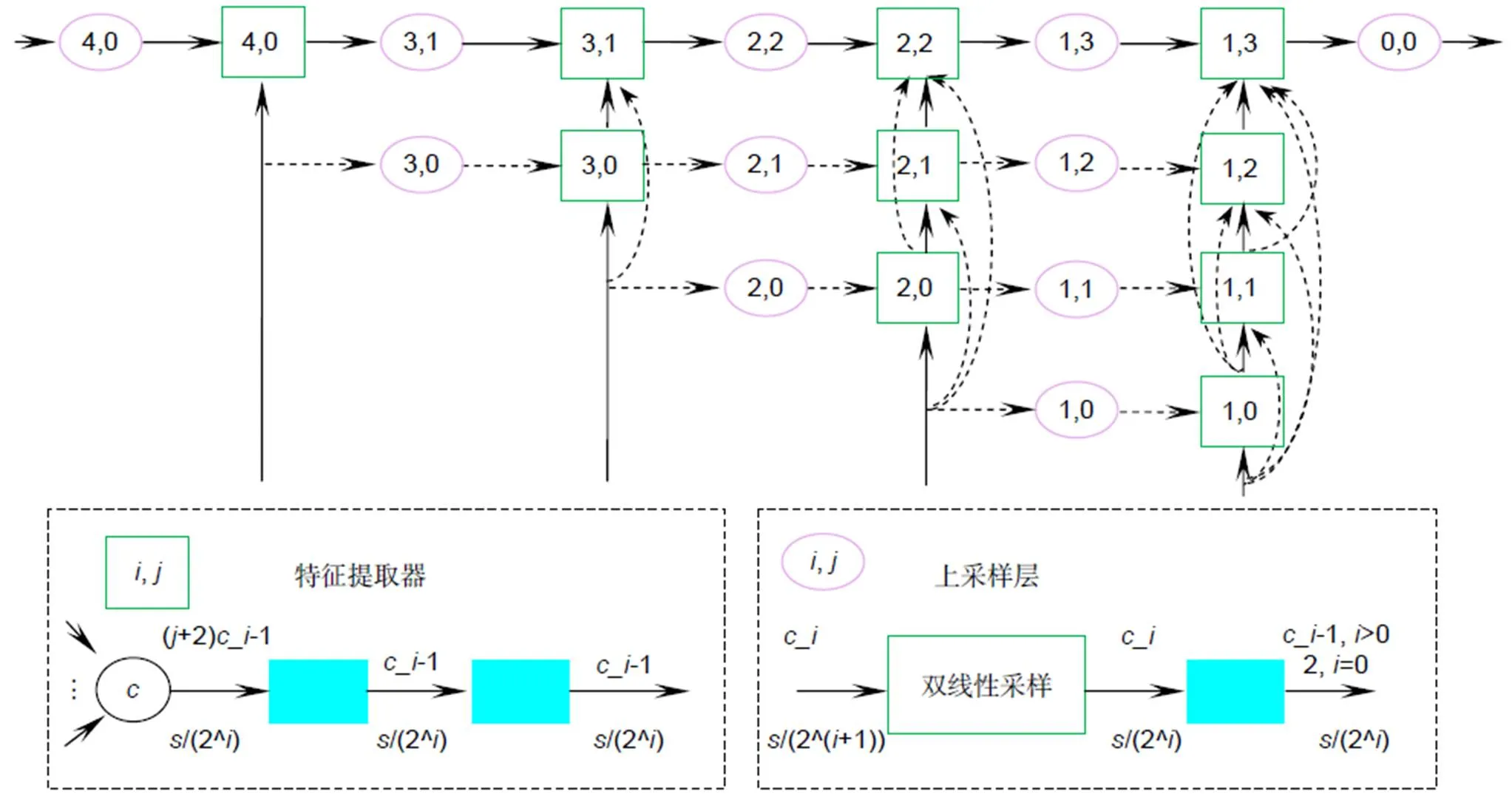
图2 解码器结构图
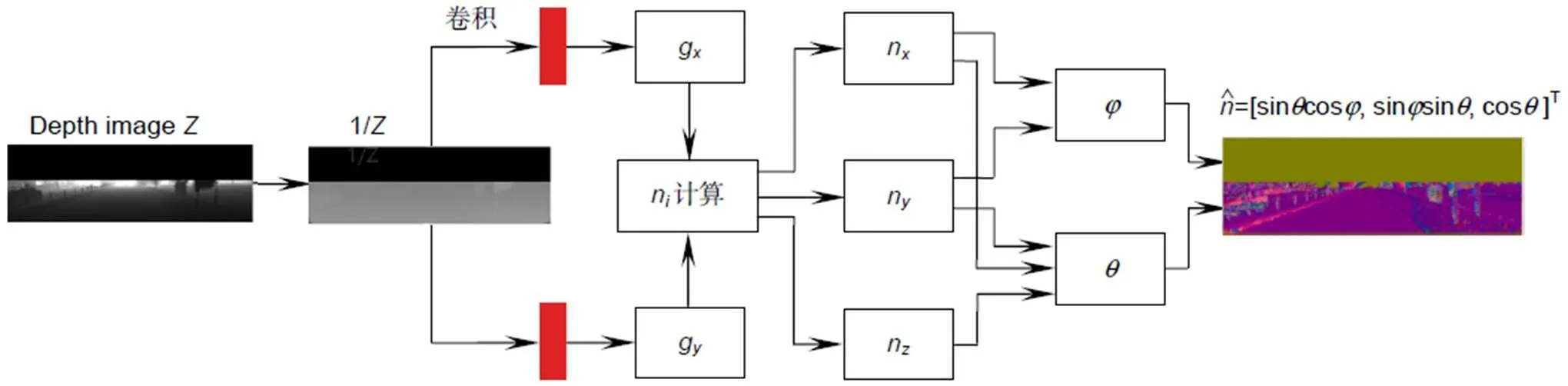
图3 表面法线估计器
解码器(图1中decoder方形块)如图2所示,由两种不同类型的模块组成——特征提取器和上采样层,对编码后的特征图进行解码,以恢复特征映射的分辨率。在解码器的每一层分别引入相应的编码阶段产生的特征层,它们紧密连接以实现灵活的特征融合。曲面箭头表示跳跃连接,自下而上的直箭头表示引入编
码阶段产生的特征图。利用特征提取器提取特征,并确保特征图分辨率不变,利用上采样层提高分辨率和减少特征图的通道数。特征提取器和上采样层共有的矩形框由卷积核为3´3、步长1、padding1的卷积层、BN层和ReLU层组成。
3.1 表面法线估计器
曲面法线是几何表面的重要属性,是指经过曲面上一点并与该点的切平面垂直的直线(即向量)。曲面法线在三维建模中应用较为广泛,可以矫正光源产生的阴影和其他视觉效果。将深度图处理成法线图,可以更好地区分不同平面不同高度的物体。
曲面法线的计算,可以通过对逆深度图像或视差图像执行三个滤波操作,即两个图像梯度滤波器(分别在水平和垂直方向)和一个平均/中值滤波器。表面法线估计器(surface normal estimator,SNE)如图3所示,由3F2N[21]的方法发展而来,文献[20]中多次实验证明采用这种深度数据处理方式可以得到更好的分割效果。而对表面法线的估计,可以转化为最小二乘平面拟合估计问题,对三维曲面上的每个点估计在该位置与表面相切的平面的法线。
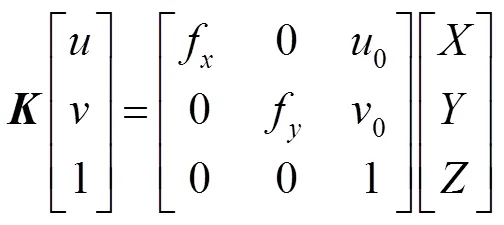


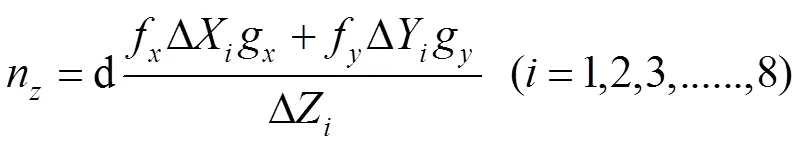

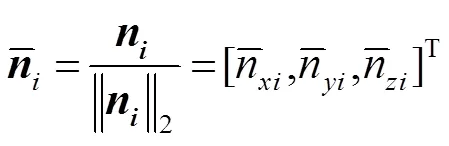
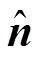

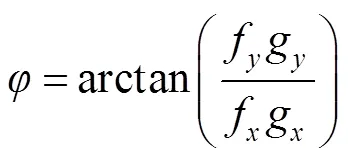

3.2 融合方式
在多传感器信息融合中,按其在融合系统中信息处理的抽象程度可分为三个层次:像素级融合、特征级融合和决策级融合。针对采用怎样的方式以及在什么阶段融合能得到更优效果的问题,本文设计并实验了多种融合策略(如图4所示)。
像素级融合属于底层数据融合方法(如融合A),将两路传感器的原始观测信息在数据预处理结束后直接进行通道融合,以六通道观测数据进入编码器¾解码器结构,提取特征并进行判断识别。
特征级融合属于中间层次级融合(如融合B、C、D、E),先从两路传感器的原始观测信息中提取代表性特征,选择合适的特征进行交叉融合:
融合B:将原始数据分别进入编码器结构中提取特征,然后将编码后的两路特征数据进行融合,再将融合后的数据送进解码器部分得出分割结果;
融合C:将原始数据分别进入编解码网络结构,在编码器五个阶段采用交叉方法1(图4中的菱形框),如图5中的(a)所示,对RGB特征图进行信息补充;
融合D:将原始数据分别进入编解码网络结构,在编码器五个阶段采用交叉方法2(图4中的椭圆框),如图5中的5(b)所示,对RGB特征图进行信息补充。
融合E:将原始数据分别进入编解码网络结构,在编码器五个阶段采用交叉方法3(图4中的圆角矩形框),如图5中的5(c)所示。该融合方法是方案C,D的综合,单从一路数据讲就是将法线特征与RGB特征通道拼接,通过训练学习到、两个参数,根据这两个参数得到转换后的法线数据特征图,与RGB特征图叠加得到转换后的RGB特征图,同理得到转换后的法线特征图。然后将转换后的法线特征图与可训练参数b再次相乘,最后与转换后的RGB特征图再次叠加得到新RGB特征图。另一路同理可得融合后的新法线特征图。然后将两路融合数据均送入解码器结构还原,最后在Sigmoid层再次进行融合。
决策级融合属于高层次级融合(如融合F),输出是一个联合决策结果,理论上这种联合决策比基于单传感器的决策要更优。将两路传感器数据信息分别进入编解码网络,在解码后拼接,然后在sigmoid层进行融合,得出分割结果。

图4 采用不同融合策略的网络结构
4 实验结果
实验数据来自KITTI的道路数据集,包含三个子集:训练集(289张图像),验证集(32张图像),测试集(290张图像)。
验证集是训练集中留出的用于模型验证的图像集,KITTI提供真值,用于调整模型的超参数和评估模型的能力。
测试集仅用于评估最终模型的性能,KITTI不提供真值,需要研究者提供检测结果,由KITTI将检测结果与真值进行比较,这样可以保证不同方法比较的公正性。KITTI图像序列包含三种场景:UU(城市无标记)、UM(城市标记)、UMM(城市多条标记车道)。实验结果采用KITTI的评价方法,性能评估有五个常用的指标:准确率(Accuracy,cc),精确度(Precision,),召回率(Recall,),F1值(F1-score,1),PR曲线():
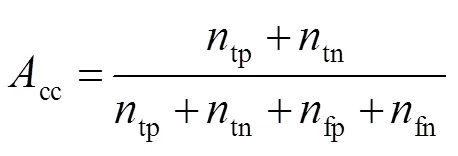
, (8)
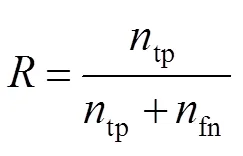

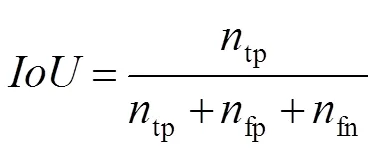
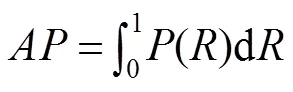
此外,采用随机梯度下降动量(stochastic gradient descent with momentum,SGDM)优化器最小化损失函数,初始学习率设置为0.1。在验证子集上采用了早期停止机制,以避免过度拟合,然后使用测试子集对性能进行量化。
实验主要分两个部分:第一,在同一基础网络结构上比较不同的融合方式的分割结果,确定最佳融合方法。第二,比较本文方法与其他道路分割方法的分割效果,验证本文提出的方法对道路分割性能的提升。
4.1 各种融合方案的实验结果比较
各种融合方案的比较是在验证集图像上进行的,由我们自己与真值进行比较得到各项指标。网络的输入数据均为相机采集的RGB图像和激光雷达得到的深度图像,在数据预处理中实现了对深度数据的表面法线估计,采用不同的融合方式,对特征信息进行补充,利用编码器¾解码器结构提取特征并进行道路分割。
表1给出了采用不同融合方式在验证集上得到的实验结果性能指标和loss值。对比像素级融合(融合A)和决策级融合(融合F),融合A的accuracy、precision、F1-score及IoU分别比融合F高0.2%、2.5%、0.6%、1%,仅recall低了1.4%。在所有的特征级融合方法中,融合E各方面性能指标均有非常不错的表现,Loss只有0.022,Accuracy提升至99.4%,Precision提升至97.9%,Recall提升了1.9%,F1-score提升了2.8%,IoU值提升至96.8%。

表1 不同融合方式之间的性能比较
现有的2D道路分割方法多采用激光雷达的数据信息去补充RGB图像信息,交叉方法3可以对两路特征信息都进行补充,将两路传感器数据置于同等重要的地位。原始特征的组合形式特征增加了特征维数,提高目标分割的准确率,解决了像素级融合易受环境噪声干扰的不稳定以及算法实现的费时。决策级融合有很好的纠错性,可以消除单个传感器造成的误差,同时具有很好的分割速度。将两者结合,提高分割的准确率,同时有很好的纠错性。
图6为同一张道路图不同融合方式的分割结果示例。通过多组图片对比,可以看出本文提出的融合E分割结果与真值图最为接近,道路轮廓分割较为完整,并没有过多的误检区域。对于处于同一水平面的人行道、远处的路口区域以及车辆周围的区域,融合E对于非道路区域的剔除最干净。

图6 不同融合方式实验结果示例
4.2 与其他方法的比较
4.2.1 定性分割结果比较
图7给出了对于KITTI数据集中几个典型场景的测试结果,将本文提出的最佳融合方法(融合E)与OFA Net[8]、MultiNet[9]、RBNet[10]、multi-task CNN[11]、SNE-RoadSeg[20]进行比较。其中第一列为OFA Net[8]的分割结果图,第二列为RBNet[10]的分割结果图,第三列为multi-task CNN[11]的分割结果,第四列为SNE-RoadSeg[20]的分割结果图,第五列为LidCamNet[13]的分割结果,第六列为融合方案E的方法的分割结果图。图7(a)、7(b)为UM场景,图7(c)、7(d)为UMM场景,图7(e)、7(f)为UU场景,绿色区域为正确的驾驶区域(真阳性),蓝色区域对应于缺失驾驶区域(假阳性,即错检区域),红色区域表示假驾驶区域(假阴性,即误检区域)。
对比UM场景,对于图7(a),OFA Net[8]检测出绿色区域更为完整,红色误检区域很少,但是道路边缘有一圈蓝色错检区域;SNE-RoadSeg[20]蓝色错检区域最少,有少量红色误检区域;融合E在阴影处有少量蓝色错检区域,在接近车辆位置有少量红色误检区域,绿色区域较为完整。对于图7(b),虽然融合E对于车辆下方的人行区域产生了误判,但是绿色区域是最为完整,与右边车辆交界处处理得也很好,其他方法都有少量红色或者蓝色区域。对比UMM场景,对于图7(c),各方法检测结果都较为理想,误检与错检区域都非常少。而对于图7(d),融合E、OFA Net[8]、RBNet[10]、LidCamNet[13]检测结果最好,对于铁轨区域基本完全剔除。
对比UU场景,对于图7(e),可以看出融合E对于车辆与道路交界位置处理非常好,绿色道路区域绕着车辆的边缘,基本没有红色误检区域;其他方法或多或少存在一些误检区域或者错检区域。对于图7(f)是同样的,右边部分检测较为完整,虽然左边有少量人行区域的错检。而multi-task CNN[11]的每次检测结果虽然也比较完整,但是蓝色错检区域太多。综合考虑,融合E对于道路与车辆交界处处理非常好。

图7 KITTI数据集实验结果示例
融合方案E采用可训练参数交叉融合,对图像和法线数据进行特征级融合,综合利用图像数据密集纹理信息和法线数据的方向信息,对两路传感器分割信息进行融合,有效降低了道路分割的误检率。
4.2.2 定量比较
与其他方法的定量比较是在测试集图像上进行的,将我们对测试集图像的分割结果提交KITTI,由KITTI与真值进行比较得到各项指标。将本文提出的最佳融合方法(融合E)与KITTI road基准上发布的OFA Net[8]、MultiNet[9]、RBNet[10]、multi-task CNN[11]、SNE-RoadSeg[20]、LidCamNet[13]在不同的场景下进行比较,输入数据均为深度数据、RGB图像数据、融合数据。表2中给出了几种方法在测试集上的定量比较。其中,OFA Net[8]、MultiNet[9]、RBNet[10]、multi-task CNN[11]属于单纯基于图像的分割方法,SNE-RoadSeg[20]、LidCamNet[13]和我们的融合E方法属于点云与图像融合的方法。
Precision表示模型检测出的目标有多大比例是真正的目标物体,Recall代表所有真实的目标有多大比例被模型检测出。由表中数据可看出,基于图像分割的OFA Net[8]、multi-task CNN[11]在recall方面很高,UMM场景下可达百分之九十八点几,而precision方面却不尽人意,说明基于图像的分割方法检测正确的道路像素数很多,但出现了很多误判情况;而基于点云¾图像融合的分割方法在MaxF(max F1-score)、AP(average precision平均精度)、Precision等方面均有不错的表现,Recall方面略有逊色,说明多数据融合模型检测出的道路是真实道路的比例更高,存在少量漏检情况。结果对比,证明了多数据融合对于道路的误判有显著降低。
在基于点云¾图像融合的分割方法中,对比使用特征融合的LidCamNet[13],我们的融合E(交叉方法3)UM和UU场景下各方面性能均有所提升,而在UMM场景下AP提升了0.28%,Recall提升了0.22%,Precision降低了0.95%,MaxF降低了0.37%;对比SNE-RoadSeg[20],我们的融合E方法在各场景的AP值均为最高,在UU场景下recall方面不相上下,其他方面均有不足。Precision反映了被模型判定为道路的正例中真实道路的比重,体现了检测的准确度。融合E的precision低于SNE-RoadSeg[20],说明被判断为道路的像素中有不少误判的情况。Recall反映了被正确判断为道路的正例占总的真实道路的比重,体现了检测的完整性。两个方法均为95.83%,说明被正确判断为道路的像素数基本一致。对于道路检测任务而言,Precision和recall往往是此消彼长的,AP是两者的结合,AP越高代表检测失误越少。Precision的降低,说明我们的融合E方法出现了道路误检的情况。从图7(a)、7(b)可以看出,在UM(城市标记)场景下,高度与道路一致的非道路区域出现车辆的情况,检测结果出现了严重偏差。从图7(c)、7(d)可以看出,在UMM(城市多条标记道路)场景下,路面情况较为复杂时,检测结果较为良好。而且融合E在AP方面有所提高,说明交叉方法3对于模型性能有所改善,但对于个别道路与人行道高度一致且有混淆因素(车辆)的情况仍有不足。
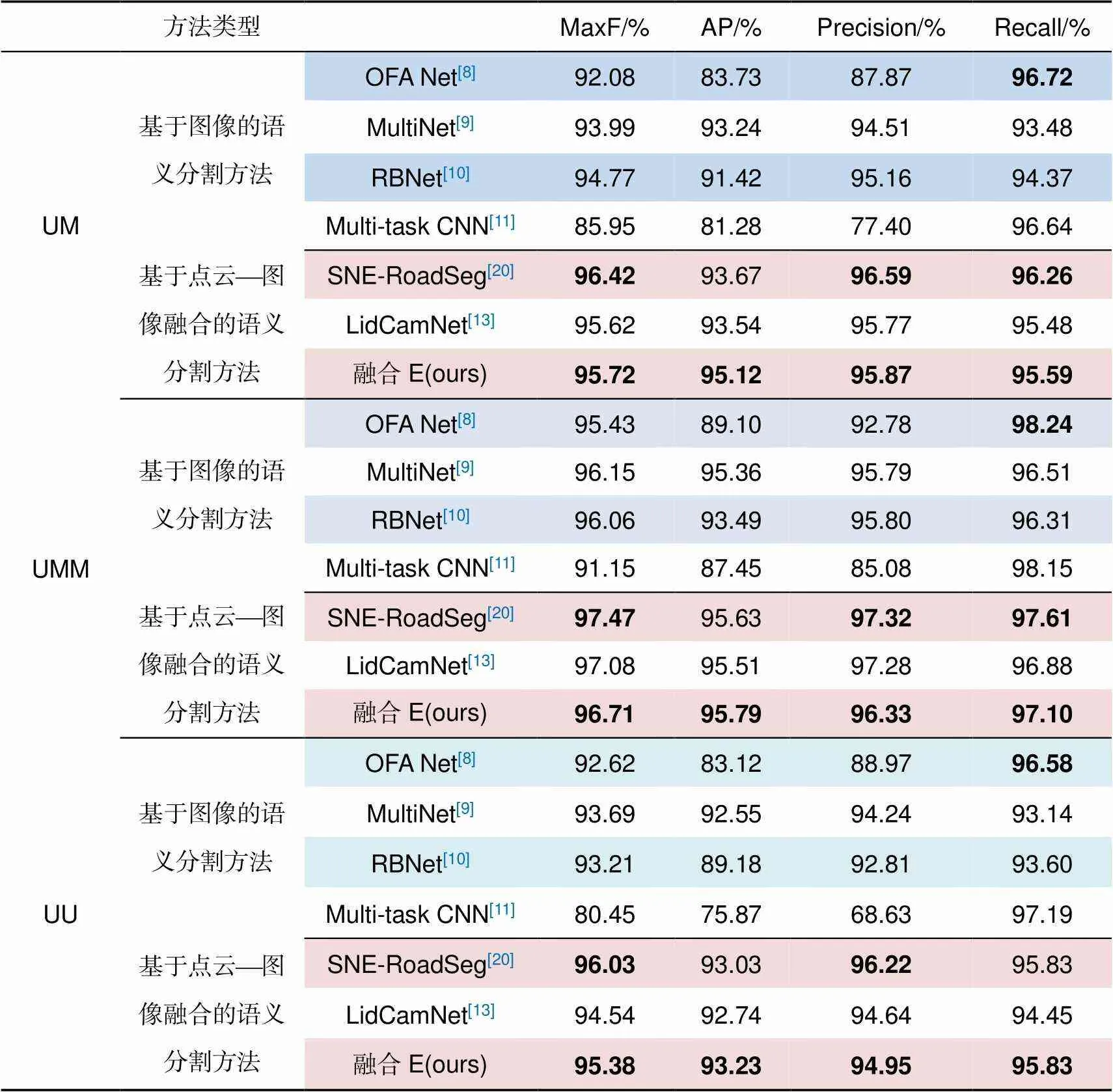
表2 KITTI道路基准测试结果
5 总 结
本文研究基于点云与图像数据融合的道路分割方法,设计了像素级、特征级和决策级多种融合方案,尤其是在特征级融合中设计了四种交叉融合方案。采用KITTI数据集进行多种融合方式的实验验证,融合方案E能够更好地获取图像和法线的特征信息,具有最佳的道路分割效果。对比其他多种道路检测方法,本文提出的最佳融合方法表现出平均检测精度上的优势,具有较好的整体性能。
[1] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//, 2015.
[2] Zhou Z W, Siddiquee M R, Tajbakhsh N,. UNet++: a nested U-Net architecture for medical image segmentation[C]//, 2018.
[3] Huang G, Liu Z, van der Maaten L,. Densely connected convolutional networks[C]//, 2017.
[4] Xiao X, Lian S, Luo Z M,. Weighted Res-UNet for high-quality retina vessel segmentation[C]//, 2018.
[5] He K M, Zhang X Y, Ren S Q,. Deep residual learning for image recognition[C]//, 2016.
[6] Chen L C, Zhu Y K, Papandreou G,. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//, 2018.
[7] Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]., 2017, 39(12): 2481–2495.
[8] Zhang S C, Zhang Z, Sun L B,. One for all: a mutual enhancement method for object detection and semantic segmentation[J]., 2020, 10(1): 13.
[9] Teichmann M, Weber M, Zöllner M,. MultiNet: real-time joint semantic reasoning for autonomous driving[C]//, 2018.
[10] Chen Z, Chen Z J. RBNet: a deep neural network for unified road and road boundary detection[C]//, 2017.
[11] Oeljeklaus M, Hoffmann F, Bertram T. A fast multi-task CNN for spatial understanding of traffic scenes[C]//, 2018.
[12] Schlosser J, Chow C K, Kira Z. Fusing LIDAR and images for pedestrian detection using convolutional neural networks[C]//, 2016.
[13] Caltagirone L, Bellone M, Svensson L,. LIDAR–camera fusion for road detection using fully convolutional neural networks[J]., 2019, 111: 125–131.
[14] Chen Z, Zhang J, Tao D C. Progressive LiDAR adaptation for road detection[J]., 2019, 6(3): 693–702.
[15] van Gansbeke W, Neven D, de Brabandere B,. Sparse and noisy LiDAR completion with RGB guidance and uncertainty[C]//, 2019.
[16] Wang T H, Hu H N, Lin C H,. 3D LiDAR and stereo fusion using stereo matching network with conditional cost volume normalization[C]//, 2019.
[17] Zhang Y D, Funkhouser T. Deep depth completion of a single RGB-D image[C]//, 2018.
[18] Deng G H. Object detection and semantic segmentation for RGB-D images with convolutional neural networks[D]. Beijing: Beijing University of Technology, 2017.
邓广晖. 基于卷积神经网络的RGB-D图像物体检测和语义分割[D]. 北京: 北京工业大学, 2017.
[19] Cao P. Dual sensor information fusion for target detection and attitude estimation in autonomous driving[D]. Harbin: Harbin Institute of Technology, 2019.
曹培. 面向自动驾驶的双传感器信息融合目标检测及姿态估计[D]. 哈尔滨: 哈尔滨工业大学, 2019.
[20] Fan R, Wang H L, Cai P D,. SNE-RoadSeg: incorporating surface normal information into semantic segmentation for accurate freespace detection[C]//, 2020.
[21] Fan R, Wang H L, Xue B H,. Three-filters-to-normal: an accurate and ultrafast surface normal estimator[J]., 2021, 6(3): 5405–5412.
Point cloud-image data fusion for road segmentation
Zhang Ying, Huang Yingping*, Guo Zhiyang, Zhang Chong
School of Optical-Electronic and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China

Fusion scheme E detection results(right side)
Overview:Road detection is an important content of environmental identification in the field of automatic driving, and it is an important prerequisite for vehicles to realize automatic driving. Multi-source data fusion based on deep learning has become a hot topic in the field of automatic driving. RGB data can provide dense texture and color information, LiDAR data can provide accurate spatial information, and multi-sensor data fusion can improve the robustness and accuracy of detection. The latest fusion method uses convolutional neural network (CNN) as a fusion tool to fuse the LiDAR data and RGB image data, and semantic segmentation to realize road detection and segmentation. In this paper, different fusion methods of LiDAR point cloud and image data are adopted by encoder-decoder structure to realize road segmentation in traffic scenes. Aiming at the fusion methods of point cloud and image data, this paper proposes a variety of fusion schemes at pixel level, feature level, and decision level. In particular, four kinds of cross-fusion schemes are designed in feature level fusion. Various schemes are compared and studied to give the best fusion scheme. As for the network architecture, we use the encoder with residual network and the decoder with dense connection and jump connection as the basic network. The input image is RGB-D, and the LiDAR depth map is processed into a normal map by a surface normal estimator. The normal map features and RGB image features are fused at different levels of the network. The features are extracted through two input signals generated by two encoders, restored by a decoder, and finally road detection results are obtained by using sigmoid activation function. KITTI data set is used to verify the performances of various fusion schemes. The contrast experiments show that the proposed fusion scheme E can better learn the LiDAR point cloud information, the camera image information, the correlation of cross added point cloud, and image information. Also, it can reduce the loss of characteristic information, and thus has the best road segmentation effect. Through quantitative analysis of the average accuracy (AP) of different road detection methods, the optimal fusion method proposed in this paper shows the advantages of average detection accuracy, and has good overall performance. Through qualitative analysis of the performance of different detection methods in different scenarios, the results show that the fusion scheme E proposed in this paper has good detection results for the boundary area between vehicles and roads, and could effectively reduce the false detection rate of road detection.
Zhang Y, Huang Y P, Guo Z Y,Point cloud-image data fusion for road segmentation[J]., 2021, 48(12): 210340; DOI:10.12086/oee.2021.210340
Point cloud-image data fusion for road segmentation
Zhang Ying, Huang Yingping*, Guo Zhiyang, Zhang Chong
School of Optical-Electronic and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China
Road detection is the premise of vehicle automatic driving. In recent years, multi-modal data fusion based on deep learning has become a hot spot in the research of automatic driving. In this paper, convolutional neural network is used to fuse LiDAR point cloud and image data to realize road segmentation in traffic scenes. In this paper, a variety of fusion schemes at pixel level, feature level and decision level are proposed. Especially, four cross-fusion schemes are designed in feature level fusion. Various schemes are compared, and the best fusion scheme is given. In the network architecture, the semantic segmentation convolutional neural network with encoding and decoding structure is used as the basic network to cross-fuse the point cloud normal features and RGB image features at different levels. The fused data is restored by the decoder, and finally the detection results are obtained by using the activation function. The substantial experiments have been conducted on public KITTI data set to evaluate the performance of various fusion schemes. The results show that the fusion scheme E proposed in this paper has the best segmentation performance. Compared with other road-detection methods, our method gives better overall performance.
autonomous driving; road detection; semantic segmentation; data fusion
10.12086/oee.2021.210340
TP391.41
A
the Shanghai Natural Science Foundation of Shanghai Science and Technology Commission, China (20ZR14379007), and National Natural Science Foundation of China (61374197)
* E-mail: huangyingping@usst.edu.cn
张莹,黄影平,郭志阳,等. 基于点云与图像交叉融合的道路分割方法[J]. 光电工程,2021,48(12): 210340
Zhang Y, Huang Y P, Guo Z Y,Point cloud-image data fusion for road segmentation[J]., 2021, 48(12): 210340
2021-10-30;
2021-12-13
上海市自然科学基金资助项目(20ZR1439007);国家自然科学基金资助项目(61374197)
张莹(1996-),女,硕士研究生,主要从事计算机视觉、机器学习的研究。E-mail:192420365@st.usst.edu.cn
黄影平(1966-),男,教授,主要从事汽车电子、计算机视觉的研究。E-mail:huangyingping@usst.edu.cn
猜你喜欢
装备制造技术(2022年5期)2022-09-06 03:42:46
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
数学教学通讯·高中版(2018年11期)2018-01-15 10:23:12
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
楚雄师范学院学报(2015年9期)2015-06-19 06:06:18
