
单目相机在无监督学习多任务场景理解中的应用
2021-02-28 06:49华东理工大学信息科学与工程学院童云斐陈俊咏李佳宁潘泽恩
电子世界 2021年22期
华东理工大学信息科学与工程学院 童云斐 陈俊咏 李佳宁 潘泽恩
为了解决场景理解在无标签数据时难以适用的情况,以及无监督学习的场景理解存在的鲁棒性差、未能满足多任务需求等缺点,基于Mask R-CNN、struct2depth、SfMLearner模型,通过模型训练、图像预处理、多任务耦合等方法,用拍摄的实景视频验证模型效果,并和原模型处理结果作对比。实验结果表明,进行预处理后的图像结果前景轮廓更加清晰,我们的模型实现了多任务的场景理解,而原模型仅实现了单一任务。改进的无监督学习多任务场景理解算法不仅提升了鲁棒性,而且直接反映了物体到相机的距离,同时提高了深度估计的精度。
随着汽车行业的快速发展,为提供更便利安全的驾驶服务,无人驾驶技术开发已经成为汽车及信息行业的热门研究对象。场景理解是辅助驾驶中关键性环节,常见的场景理解任务包括深度估计、目标识别、语义分割等。本课题拟对无监督单目相机场景理解技术的实现展开研究。基于无标签图像的场景理解算法无需价格高昂的标签数据,应用范围广泛;除外,还可同时实现多种任务的耦合训练,提高算法精度并降低训练难度,有很好的研究前景。
1 场景理解
本文完成的场景理解任务包括目标识别、运动分割和深度估计。目标识别任务旨在检测前景中的物体对象,并对其进行识别分类,得到对象的属性信息。由于使用到分类算法,此部分网络模型是有监督地训练的。运动分割模块是为了将前景中可能运动的物体分离出来,方便后续单独进行深度估计,减小误差。深度预测网络使用卷积自编码器,将原图像经过编码解码得到深度信息图。通过单目序列图像前后帧间视差可以推导相机的运动情况,结合运动信息训练深度估计网络,得到好的估计模型。场景理解网络结构图如图1所示。
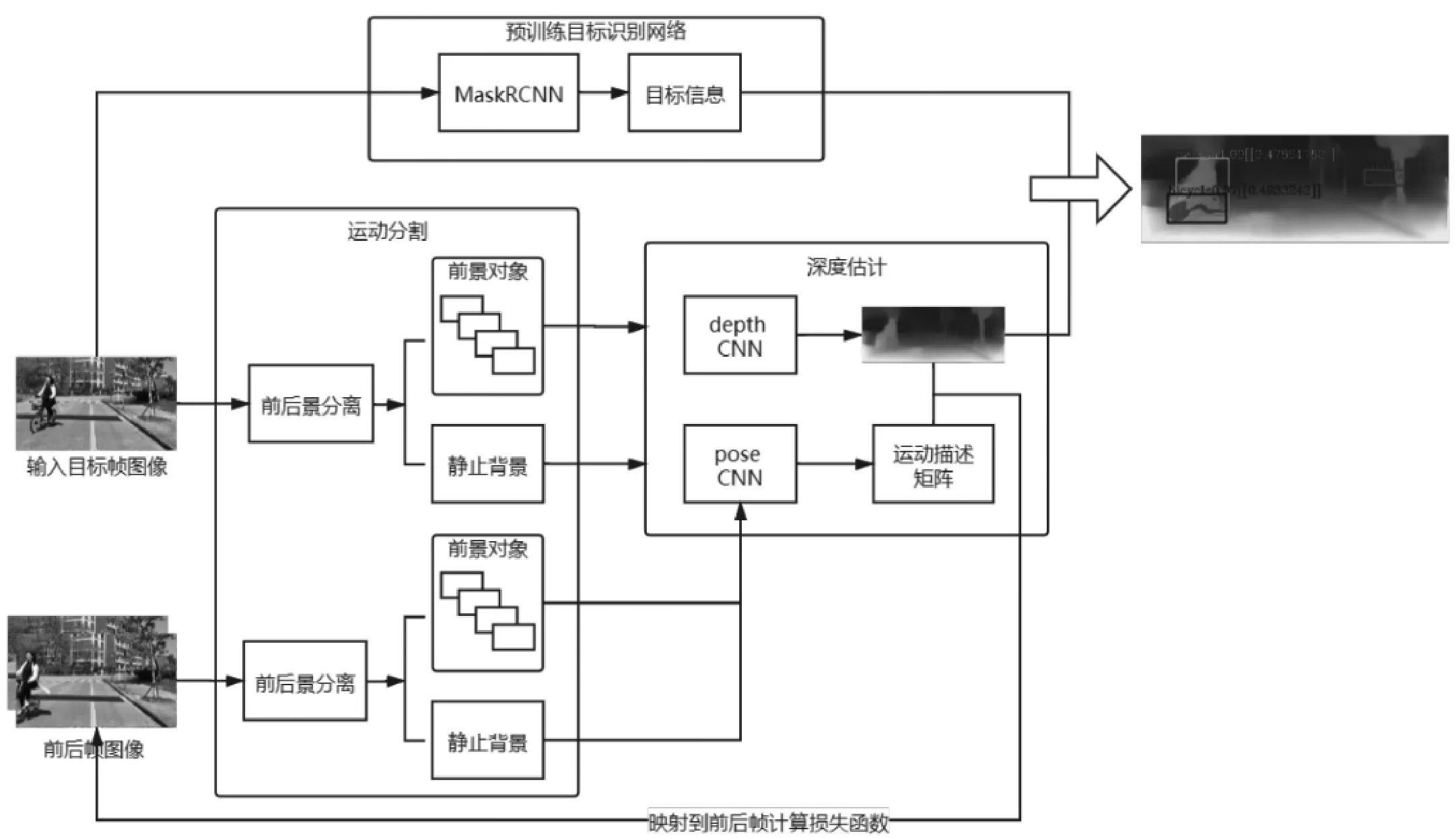
图1 场景理解网络结构图
1.1 目标识别
对于目标识别任务,我们使用了一个预训练的监督模型。参考Mask R-CNN的方法,此网络预先进行单独训练,独立于深度模型。在目标识别网络训练完成后,输入图片序列,该网络会将图片调整为神经网络需要的大小并做归一化处理,在上述操作完成后,目标识别网络会对图片中可能存在的对象做预测,提供识别出来的对象的掩膜信息、对象边界框的位置及大小信息、对象类型的预测结果以及该预测结果的置信度。本文设置了显示在图像上的预测对象置信度的阈值,限制了只有置信度高于90%的预测结果,才会将相应的掩膜和边界框添加到图像上。
1.2 运动分割
本文使用的方法参考的是Casser等人提出的struct2depth模型。在图像输入深度网络进行学习之前,分析图像的结构信息,对场景中的单个对象建模,分离可能运动的前景物体和静止背景。摄像机自我运动和物体运动都是通过单目图像序列帧与帧之间的视差来进行学习的。对于场景中的任意一点,根据其与相机的相对运动关系,可以反推出该点的运动参数,由此可对前景中识别到的对象进行单独的运动建模。
1.3 基于单目序列图像的深度估计模型
与单目相机相比,双目设备可以利用两个视点的位置视差对图像进行立体的理解。本文使用的方法参考了Zhou等人提出的SfMLearner模型,通过利用单目序列图像前后帧由相机运动产生的视差对图像场景进行深度估计。模型由两个网络组成,深度估计网络Depth CNN以及用于得到相机自运动矩阵的Pose CNN。
深度估计网络使用的是多尺度卷积自编码器,其是一种常见无监督卷积神经网络模型,也被多次应用到无监督深度估计任务中。模型由编码器和解码器组成,生成多尺度的目标图像。Pose CNN以连续的2帧图像作为输入,生成相机位姿变换矩阵,描述相机在两帧图像前后的运动情况,包括视角旋转和位置移动。将相机运动情况在世界坐标系中建模,可以将其在拍摄两帧图像时刻的前后位置变化分解成六自由度运动参数。
2 应用实验
2.1 数据预处理
对于进行预处理后的图像,其特征被增强,轮廓更加清晰,实验效果更好。本项目中对图像进行了自适应对比度增强(Adaptive Contrast Enhancement,ACE)。不同于全局的图像增强,本项目对图像对比度弱的部分做增强,得到的效果更好。
具体实现方法如下:
首先,计算图像中每个点的局部均值M(i,j)和局部标准差σ(i,j)。像素值计算公式如式(1),其中,I(i,j)是增强后的像素值,f(i,j)是该点的像素值,M为全局均值,α是一个系数参数,一般取值在0到1之间。
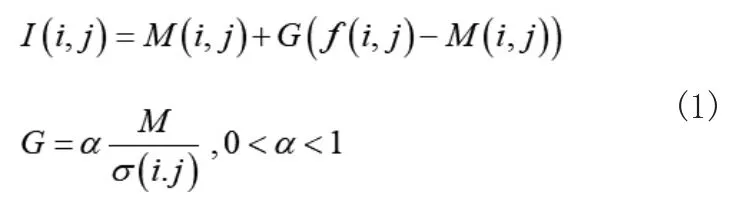
对于彩色图像,本方法将图像转到YUV色彩空间,增强Y通道明亮度后再转回RGB空间。
2.2 实验结果
将本文实验结果与我们参考的深度估计邻域的另外两个模型进行对比。
如实验结果图如图2所示,SfMLearner模型可以大致估计场景的深度前后关系,对前景物体有识别,但是不够鲁棒、准确。struct2depth模型可以识别前景中的对象,对前景中的行人和树木都有实例分割的效果。我们在图像进入模型推断前加上特征增强的预处理过程,使得前景轮廓更加明确了。最后,加上预训练的目标识别模块,可以分割并识别前景中的对象类别。我们还在图像中添加了方框和文本信息帮助理解,方框标出实例对象,文本标注其类别、置信度以及深度估计值。

图2 结果对比图
3 结语
本文针对目前无监督学习场景理解算法存在的模型鲁棒性不足、未能满足多任务需求等问题,提出改进的结合Mask R-CNN的无监督学习多任务场景理解方法。我们在结合相机自运动的深度理解模型基础上,在数据预处理阶段加入了自适应对比度增强算法以增强图片对比度,在目标识别阶段加入了掩膜以降低静态物体或者场景对后续深度估计造成的干扰,并且更便于观察深度预测图中物体所在位置。实验结果表明,本文方法在深度预估精度上有一定的提高,且对对象的识别更加准确。但目前存在一部分静态目标或场景被错误识别为对象,如何改善模型以去除这些错误识别的对象是我们后续研究的方向。
猜你喜欢
建材发展导向(2021年6期)2021-06-09
今日农业(2020年17期)2020-12-15
中国外汇(2019年11期)2019-08-27
中国生物医学工程学报(2019年6期)2019-07-16
中国惯性技术学报(2019年1期)2019-05-21
电子制作(2018年12期)2018-08-01
北京航空航天大学学报(2017年4期)2017-11-23
光学精密工程(2016年4期)2016-11-07
自动化学报(2016年3期)2016-08-23
太空探索(2016年10期)2016-07-10
