
FRDet:一种基于候选框特征修正的多方向遥感目标快速检测方法
2021-02-27 01:29:40涂鑫,王滨
计算机与现代化 2021年2期
涂 鑫,王 滨
(华北计算技术研究所基础四部,北京 100083)
0 引 言
遥感图像中的船、飞机等目标通常可以传达出非常有价值的语义信息,因此,遥感图像的目标检测在计算机视觉领域引起了越来越多的关注。以前的研究[1-4]中利用滑动窗口或具有手工特征设计的组件占据主导地位,这种方法将任务划分为一系列独特的步骤,充分利用自底向上的策略对目标进行搜索。尽管这些方法已显示出较好的性能,但由于遥感场景实例的多样性和较差的图像质量,这些方法的使用会受到限制。随着深度学习技术在自然场景目标检测领域的快速发展,遥感图像的目标检测纳入了通用的目标检测框架。这些目标检测框架可以分为2大类:基于proposal驱动的two-stage方法和基于proposal-free的one-stage方法。虽然two-stage的方法目前在各类公开数据集上有着更高的准确率,但是one-stage的方法在速度与精度上具有更好的平衡。
two-stage检测方法可以通过proposal和region pooling操作对在任何位置出现的具有任何形状的目标进行分类。而one-stage检测方法则严重依赖高密度的候选框去覆盖目标所在的区域,尤其是在遥感场景中,通常采用的实现高覆盖率的方法是使用多种尺度和宽高比的候选框。例如,TextBoxes++[5]基于SSD[6]检测网络定义了7种特定的宽高比(包括1、2、3、5、1/2、1/3和1/5)的候选框。DMPNet[7]添加了几个旋转框,合计12个(6个常规和6个倾斜)用以完全覆盖任意方向的目标。DeepTextSpotter[8]跟着YOLOv2[9]利用训练集上的k均值聚类(k=14)框以自动找到合适的候选框,而不是手动设计候选框。
以上检测网络的候选框设计方法会带来3个问题:1)必须针对不同的检测物体的外观预先定义候选框的形状和尺度,一旦设计错误会对检测性能造成极大的损害[10];2)大量的候选框会消耗较高的计算成本,尤其是当检测网络的分类层和回归层有较多参数的时候该现象更为明显;3)大量anchor的生成通常需要花费较多的时间。
在简单的网络架构和高计算效率的吸引下,本文研究上面提到的one-stage检测方法中的候选框设计问题。受到two-stage检测方法中leaned proposal启发,本文利用通过回归操作所获得的候选框来代替原来的框进入最终的分类层和回归层,并且将特征图的每个位置设置为仅与一个候选框关联。值得注意的是,与two-stage中能把候选框数量降低至1000到2000的RPN不同,本文方法仍然保持原始的数量不变,此外仍能保持one-stage中的其余检测架构不变。为了进一步降低网络计算复杂度,本文采用Mobilenetv2[11]作为主干结构,并最终提出一个高效快速的遥感图像目标检测器,名为FRDet(Fast Rotation Detector)。本文方法在DOTA数据集上飞机的检测率可达96.8%,虚警率为6.7%,mAP值达0.87,并且具有完全的实时结果。不仅如此,本文方法的性能超越了许多基于候选框特征提取的one-stage方法。
1 基于候选框特征修正的遥感目标快速检测方法
1.1 Focal Loss
在one-stage目标检测方法中,OverFeat[12]是第一个基于深度神经网络的one-stage目标检测器,近年来研究者提出的SSD[6]和YOLOv2[9]重新引起了人们对one-stage方法的兴趣。它们的关键思想是在特征图每个位置的正中央预定义候选框,并根据这些预定义框出最终预测[13]。图1显示了通用的目标检测框架,其中loc回归指的是候选框位置坐标回归,RP表示候选区域(Region Proposal),SS表示选择性搜索算法(Selective Search)。one-stage方法的基本结构是基于全图的特征抽取的骨干网络和2个并行的子网络,其中一个子网络用来预测每个候选框的类别概率分布,另外一个用来预测每个候选框离最近的ground truth的位置偏移量。
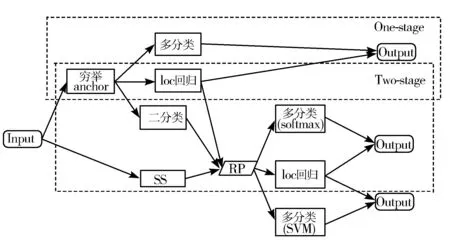
图1 2种通用检测方法对比
与图1所示的two-stage的模型(如R-CNN系列)相比,one-stage方法会跳过候选区域提取步骤直接基于原始的候选框给出最终预测。然而,它的检测精度通常落后于two-stage的方法,主要原因之一是one-stage检测网络必须处理在整个图像进行采样的大量背景候选框,因此one-stage会遇到前景与背景类别不平衡的问题,并最终影响到模型的性能。所以在本文方法中,采用FL(Focal Loss)来解决类别不平衡问题。FL是由CE损失函数修改完成的。其中CE损失函数如下:
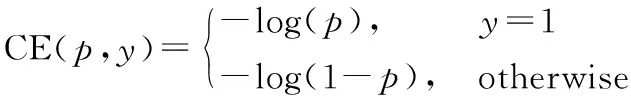
其中,y=1代表样本的标签ground-truth,p是在[0,1]区间的概率值,类别t的预测概率值pt定义如下:
令CE(p,y)=-log(pt),则分类损失函数可以定义为:
Lcls=FL(pt)=-αt(1-pt)γlog(pt)
其中,αt是权重平衡因子,γ是focusing参数。在本文的实验中,取αt=0.25,γ=2.0。
1.2 旋转框回归
在遥感图像中,大量目标如舰船、飞机、车辆等往往多方向密集并排停靠。使用矩形框回归会产生大量的背景噪声以及会框选到多余目标导致网络的检测性能受到极大损失,如图2所示。

图2 正矩形框会框选到除船体之外的多余噪声
因此,本文采用旋转矩形框去覆盖遥感场景的各种目标。每一个旋转框由一个五维的向量进行描述。设x、y代表中心点,w、h代表宽、高,θ代表矩形的旋转角度。旋转框回归操作的目标是将含有待检测目标的候选框的位置回归到与它最近的ground truth。为了保证回归过程中的尺度不变性和平移不变性,距离向量Δ=(δx,δy,δw,δh,δθ)定义如下:
δx=(gx-bx)/bw,δy=(gy-by)/bt
δw=log(gw/bw),δh=log(gh/bh)
δθ=tan(gθ)-tan(bθ)
其中,b、g分别代表候选框、ground-truth(例如bx代表候选框中心点横坐标,gx代表ground-truth的候选框中心点横坐标)。同时回归层的损失函数定义如下:
Lloc=smoothL1(Δt-Δp)
其中,smoothL1表示L1范数,Δt表示真实值的距离向量,Δp表示预测值的距离向量,这有助于加快检测网络模型的收敛。
1.3 候选框修正
通常情况下,one-stage检测网络[17-20]需要从数千个候选框中搜索到正样本框,并调整位置和形状,使得正样本框和真实值更加紧密接近。由于数千个候选框中混合有正样本框和负样本框,从这些框中快速搜索出正样本框比较困难。在实际算法中,通常采用ground truth和候选框IoU值快速配对的方式去解决该问题。在正框回归中,如下公式经常用于筛选正样本:
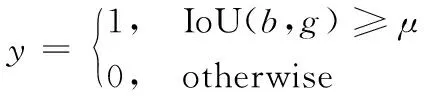
其中,μ为筛选正样本的IoU阈值。但是该式中的IoU计算方式并不适合旋转框回归任务。
同时由于原始的anchor往往是由人为预设固定的长宽比和尺度得到的,这些参数往往不是最优的。而在two-stage的检测网络中,候选区域都是通过网络学习得到的,它不仅减少了网络的搜索空间,还优化了候选区域的特征。受到该方法的启发,本文在回归层的前面添加一个候选区位置修正模块,通过学习对候选框进行修正后,再将修正后的anchor送入到分类层和回归层。
正如Wang等人[10]提到的,anchor的一个重要设计原则是anchor的中心与待检测目标的中心对齐,即让生成的anchor的中心尽可能与待检测目标的中心接近,使得anchor能充分覆盖住目标。因此可以仅修正位置参数Δ′=(δw,δh,δθ)。修正损失定义如下:
Lref=smoothL1(Δ′t-Δ′p)
其中,Δ′t表示修正位置真实值,Δ′p表示修正位置预测值,通过在各种公开数据集上的评估发现,与未修正前相比,目标的覆盖程度有了较大范围的提升。整个网络总的损失函数为:
L=λrefLref+λlocLloc+λclsLcls
在实验中,λref、λloc、λcls的值分别取0.5、0.5、1.0。
2 实验及结果分析
2.1 实验参数设置
网络的主干结构是在ImageNet数据集上充分预训练,网络是用Adam优化器训练。由于硬件资源的限制,batch size设置为4,学习率初始值设置为10-4。随机从SynthText[14]中选取100,000张图像做5个epochs的预训练,然后在DOTA数据集上微调25个epochs,在微调15个epochs后将学习率设置为10-5。训练过程中随机从480~800的范围内改变输入图像的尺寸,同时采用随机翻转对数据进行增强。
为了更多地获取含有目标的候选区域,在特征修正阶段,将IoU值设置为0.3。在前向测试阶段,置信度值设置为0.3,将NMS时的阈值设置为0.3。整个目标检测算法由Pytorch框架实现,硬件配置为Intel i7-6800k和单张NVIDIA TITAN Xp。
2.2 消融实验
为了验证方法的有效性,进行了多个消融实验,所有的模型都是在DOTA数据集和HRSC2016数据集上进行实验。

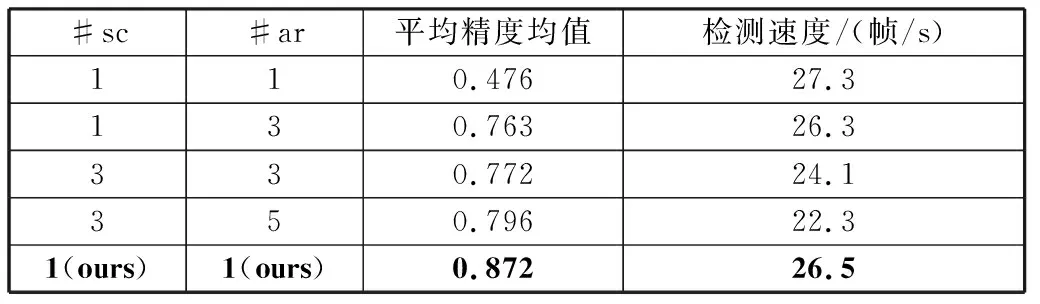
表1 不同anchor设计参数对网络性能的影响
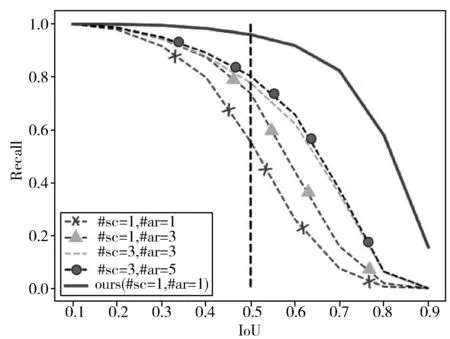
图3 IoU阈值变化曲线
2)修正模块数量。和Cascade R-CNN类似,本文增加了多级anchor修正模块去研究对网络检测性能的影响。在每个anchor修正模块逐渐增大IoU值,结果见表2。增加多个级联模块并不会带来精度的提升,甚至会有精度的下降。同时,多个级联模块会降低网络的运行速度,因此,将网络修正模块的个数设置为1,可得到最好的实验结果,是较好的选择。
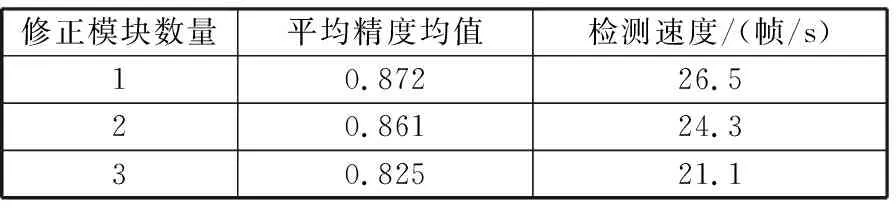
表2 修正模块数量对网络性能影响
2.3 与其他网络的比较
在几个公开数据集上评估本文的方法,并与多个state-of-the-art模型作比较,表3、表4展示了每个数据集的测试结果。
1)DOTA数据集。基准DOTA数据集用于航空图像中的目标检测,它包含了来自不同传感器和平台的2806幅航空图像,图像大小从800×800像素到4000×4000像素不等,包含显示各种比例、方向和形状的对象。这些图像由专业人士使用15种常见的物体类别进行标注。完整注释的DOTA基准测试包含188,282个实例,每个实例都由一个任意四边形标记。该标记有2种检测框:水平边界框(HBB)和旋转边界框(OBB)。在本实验中,选取旋转边界框。采用飞机目标随机选取一半的原始图像作为训练集,1/6作为验证集,1/3作为测试集。将图像分成600×600子图像,并将其缩放到800×800。从表3可以看出,本文方法在DOTA数据集上具有最高的检测精度,mAP值能达到0.87,而且检测速度能达到26.5帧/s。该算法在DOTA数据集上的检测结果如图4所示。

表3 DOTA数据集检测结果

图4 DOTA数据集飞机检测结果
2)HRSC2016。该数据集包含2种场景的图像:海上船舶和近岸船舶。所有图片都是从6个著名港口收集的。图像大小从300×300像素到1500×900像素。训练集、验证集和测试集分别包含436幅图像、181幅图像和444幅图像。实验用800×800图像比例尺进行训练和测试。从表4可以看出,在HRSC2016数据集上,本文方法的检测精度超过了SSD、YOLOv3、Textboxes++等,且具有最快的速度。该算法在HRSC2016数据集上的检测结果如图5所示。

表4 HRSC2016检测结果

图5 HRSC2016数据集检测结果示意图
3 结束语
本文提出了一种基于候选框特征修正的快速检测算法,它具有每个特征图仅设置一个候选框的特点。在各种公开数据集上的实验结果表明,该方法检测精度优于SSD、YOLOv3等各种基于候选框特征提取的one-stage检测方法[21-23],同时,该方法还具有实时性的效果。由于该方法可以较少考虑候选框的先验设计,因此可以广泛适用于其他检测任务,即插即用,具有良好的适应性。在今后的工作中,笔者将研究将该方法迁移到其他检测任务中,进一步验证该方法的有效性。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
Journal of Palaeogeography(2022年1期)2022-03-25 04:17:00
计算机工程与应用(2022年1期)2022-01-22 07:46:48
快乐语文(2021年35期)2022-01-18 06:05:30
计算机工程与科学(2021年4期)2021-05-11 01:59:36
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
法律方法(2019年4期)2019-11-16 01:07:28
火力与指挥控制(2018年3期)2018-04-19 11:43:39
数学物理学报(2017年5期)2017-11-23 07:51:31
