
基于LightGBM的航空发动机剩余使用寿命预测
2021-02-27 08:53宋海龙黎明苟江赵庆贺
现代计算机 2021年35期
宋海龙,黎明,苟江,赵庆贺
(中电科航空电子有限公司,成都 611731)
0 引言
航空发动机作为飞机的“心脏”[1],其可靠性和安全性至关重要,也是日常航空维修作业中的重点关注对象。故障预测与健康管理(prognos⁃tics and health management,PHM)[2]技术能够突破传统航空维护技术的瓶颈,改变传统的维修保障方式,提高设备维修保障效率。
从工程应用和技术研究角度来看,发动机剩余使用寿命预测主要有三个方向:基于物理模型、基于数据驱动和融合预测[3]。其中,基于数据驱动的机器学习的预测方法,能够根据发动机的历史数据和状态数据信息,通过特征提取、趋势预测等技术,构建剩余使用寿命预测模型,预测得到发动机的剩余使用寿命,为预防性维修提供技术支撑,也是目前行业研究的主流方向。
周俊[4]研究了基于退化轨迹相似性、基于相关向量机和基于随机过程的剩余寿命预测方法,并对多种预测方法进行融合;唐王[5]研究了基于改进循环神经网络(LSTM-NN)模型的发动机非线性剩余寿命预测;于会越[6]运用多种机器学习方法(SVR、CNN、CNN-LSTM和GBDT)实现了发动机剩余寿命预测;马忠等[7]采用改进的卷积神经网络(CNN)方法对发动机剩余寿命进行预测;车畅畅等[8]采用一维卷积神经网络(1D-CNN)和双向长短时记忆神经网络(Bi-LSTM)建立航空发动机剩余寿命预测模型;李杰等[9]提出了一种将卷积神经网络和长短期记忆网络相融合的数据驱动模型。
但目前的研究主要集中在算法层面,通过利用不同的、先进的机器学习算法对剩余使用寿命进行预测,缺乏在数据层面对已有模型进行优化的研究。在此基础上,本文采用基于LightGBM的机器学习预测方法对航空发动机进行剩余使用寿命预测,同时提出一种基于时间窗口的特征衍生模型优化方案,通过实例分析研究,对于提升预测模型的精确度有非常好的效果。
1 LightGBM
LightGBM是微软亚洲研究院(MSRA)于2017年提出的一种快速的、分布式的、高性能的基于决策树算法的梯度Boosting框架,可以用在分类、回归等机器学习任务中。LightGBM在训练速度和内存方面做了优化,具有快速、高效、降低内存、支持并行化和GPU学习、能够处理大规模数据等优点。
1.1 梯度提升
梯度提升是在不断的迭代过程中,通过对模型不断的增加子模型,但同时保证最终的损失函数值不断的下降。GBDT是一种梯度提升决策树,是由多个决策树组成,利用损失函数的负梯度在当前模型的值作为回归提升树算法的残差的近似值,来拟合一个回归树[10-12]。
假设每一个单独的子模型为fi(x),复合模型为:

损失函数为L(Fm(x),Y),每一次对模型中添加新的子模型后,使得损失函数不断趋于0。
1.2 LightGBM原理
LightGBM是在传统的梯度提升树(GBDT)上使用直方图算法(histogram-based algorithm)[11]。在一个要分裂的结点上,为每一个特征构建直方图。具体地,先将特征值做分箱处理,然后按照分箱值构造一个直方图。遍历结点中的每一个样本,在直方图中累积每个bin的样本数和样本的梯度之和,当遍历完一次数据后,直方图就累积了需要的统计量。
对于每个特征,根据构建的直方图,遍历每一个bin值寻找最优分裂特征及bin值。同时使用带深度限制的Leaf-wise的叶子生长策略,经过一次数据可以同时分裂同一层的叶子,具有易进行多线程优化、易控制模型复杂度、不易过拟合[10,13]等特点。
2 数据来源
本文采用美国国家航空航天局NASA公布的涡扇发动机退化仿真数据集[14]作为此次剩余使用寿命预测的研究对象。该数据集共有3个操作参数和21个传感器监测参数组成。其中各参数含义如表1所示。

表1 涡扇发动机各参数
3 模型建立
3.1 探索性分析
本文将重点研究数据集train_FD001,在该数据集中,所有发动机都出现同一种故障。首先对数据做探索性分析,该数据集共包含100个发动机的20631条数据,数据均为数值型,无缺失值。
分析该数据集中发动机运行时间周期,了解发动机在发生故障之前平均运行的周期数的信息。其中发动机最大运行周期(max_cycle)数据分布如表2所示。

表2 发动机最大运行周期数据分布
绘制最大运行周期的直方图以了解其分布,如图1所示。
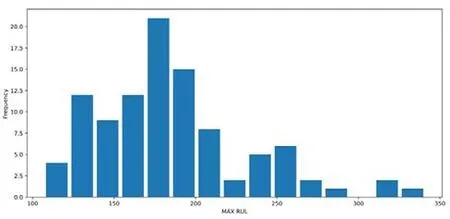
图1 最大运行周期数据分布
分析发动机最大运行周期时,发动机的最早失效是在128周期之后,最长是362周期,平均发动机在199~206周期之间发生故障,但是46周期的标准偏差也相当大。直方图也可以确认大多数发动机在200个循环左右发生故障,该分布是右偏的。
3.2 计算剩余使用寿命
计算“剩余使用寿命”(RUL)的目标变量,既作为可视化分析和相关性分析的目标变量,又作为机器学习回归模型的目标变量。
假设RUL随时间线性下降,并且在发动机的最后一个时间周期的值为0。使用发动机最大运行周期(max_cycle)减去当前运行周期(cycle)计算所需的RUL,给每个样本添加RUL标签。
3.3 特征选择
对监测的传感器参数数据做描述性统计分析,分析记录数、均值、标准差、最小值、最大值和(1/4、1/2、3/4)分位数指标,进一步了解数据分布情况。其中参数T2、P2、epr、farB、Nf_dmd、PCNfR_dmd的最大值与最小值相同,数据没有波动,不含任何有价值的信息,做丢弃处理。
Pearson相关系数[15]是用来衡量两个连续变量间的相关关系。假设随机变量X和Y的样本数据分别为x1,x2,…,xn和y1,y2,…,yn,则 Pearson相关系数r为:
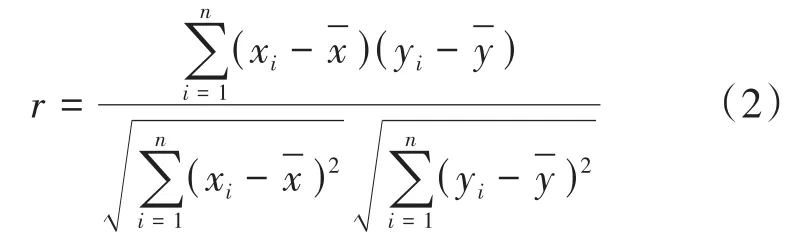
r的取值范围在-1~1之间。其绝对值|r|表示两个变量间相关关系的强弱,越接近1,表明相关程度越高。r>0表示正相关,r<0表示负相关,r=0表示不相关,r=1表示完全相关。
发动机各参数与RUL的Pearson相关系数如表3所示。
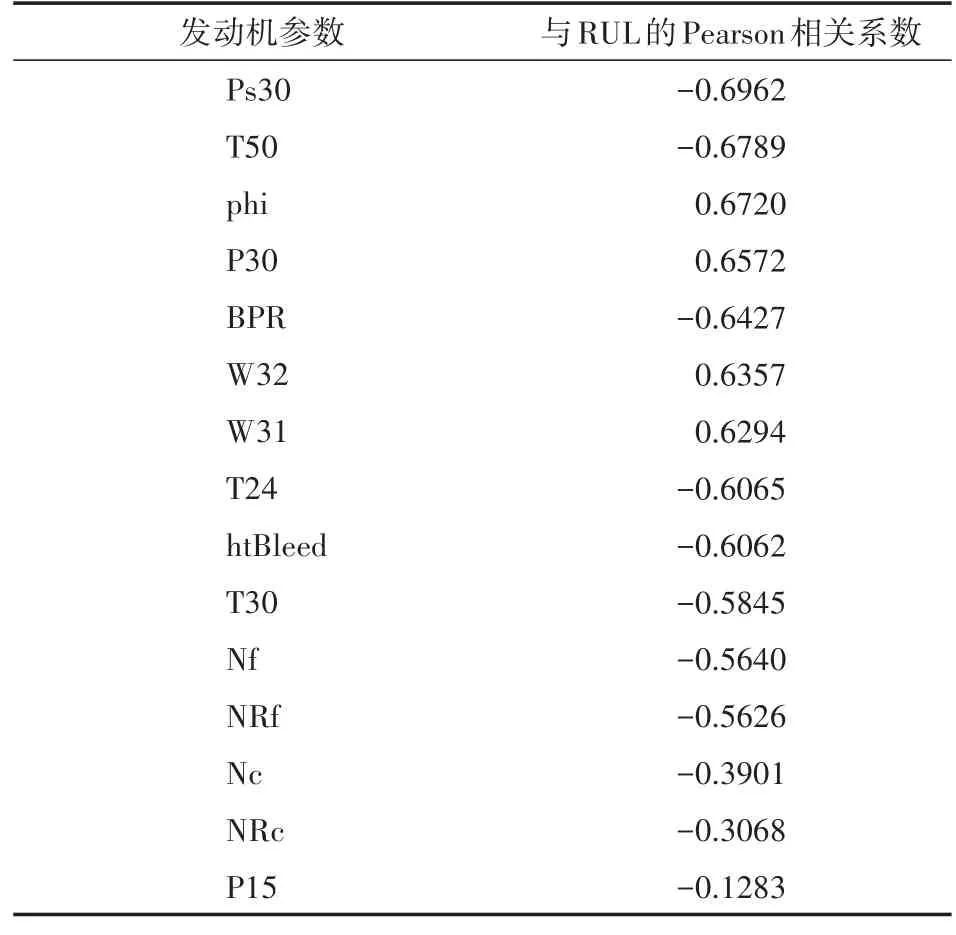
表3 发动机各参数与RUL的Pearson相关系数
其中参数P15与RUL的Pearson相关系数仅-0.1283,关系极弱,可以认为不相关。
再结合可视化分析,随机选取3个发动机,绘制这3个发动机P15参数随RUL变化的折线图,如图2所示。

图2 参数P15随RUL变化折线
作为对比,再绘制Ps30参数随RUL变化的折线图,如图3所示。综合相关性分析和可视化分析的结果,P15与RUL关系极弱,做丢弃处理。

图3 参数Ps30随RUL变化折线
3.4 数据归一化
不同的传感器往往具有不同的量纲和量纲单位,为了缩小数值之间的差异,消除量纲的影响,达到数据优化目的,采用最小-最大值归一化,将数据归一化在0~1范围内。归一化公式[16]为:

其中xmax为传感器参数数据的最大值,xmin为传感器参数数据的最小值。
3.5 模型评估与分析
为确保预测模型的可用性,本文采用回归类模型通用的评估方法,从而完成对模型的综合评估。评估指标[10]如下:
●平均绝对误差(MAE):预测值x′i与真实值xi之差的绝对值之和除以预测次数作为误差度量。公式为:

●均方根误差(RMSE):预测值x′i与真实值xi逐点求差的平方和,与预测次数相除的平方根作为误差的度量。公式为:

●判定系数(R2):预测值x′i与真实值xi的回归平方和在总平方和中所占的比例。R2的取值范围在0~1之间,越接近1,模型的拟合优度越高。公式为:

划分训练集和测试集,随机选train_FD001数据中80%的数据作为训练集,用于模型的训练与学习;20%的数据作为测试集,用于评估算法的性能及优化。利用Python 3.8.8工具建立航空发动机剩余使用寿命预测模型。使用MAE、RMSE和R2作为对LightGBM模型的评估指标,评估结果如表4所示。

表4 LightGBM模型评估结果
此外,LightGBM模型还可输出特征重要性定量评价结果,便于更进一步的特征筛选,得分越高,说明该特征对模型预测性能影响越大。特征的重要性排序结果如图4所示。

图4 参数对模型预测性能影响的重要性
3.6 模型优化
发动机机械部件的磨损是一个基于时间序列的动态变化过程,时点数据仅能反映当前的状态,而无法真实反映部件的全部信息。对于具备时间特性的数据而言,具有一定长度的序列既包含前后趋势、波动的变化,又能减少因某次数据异常对结果的影响。但时间窗口长度过长也会出现湮没短期变化特征的可能,同时也会降低有效数据的记录数,因此也不能将时间窗口的长度设置过长。
假设T为时间窗口的长度,为衍生时点i(i>T)的特征指标,需考虑时点i及前T个时点的状态数据,时点i≤T的数据因无法衍生特征,将不能参与模型的训练和预测。衍生的指标包括均值、趋势和波动,计算公式如表5所示。
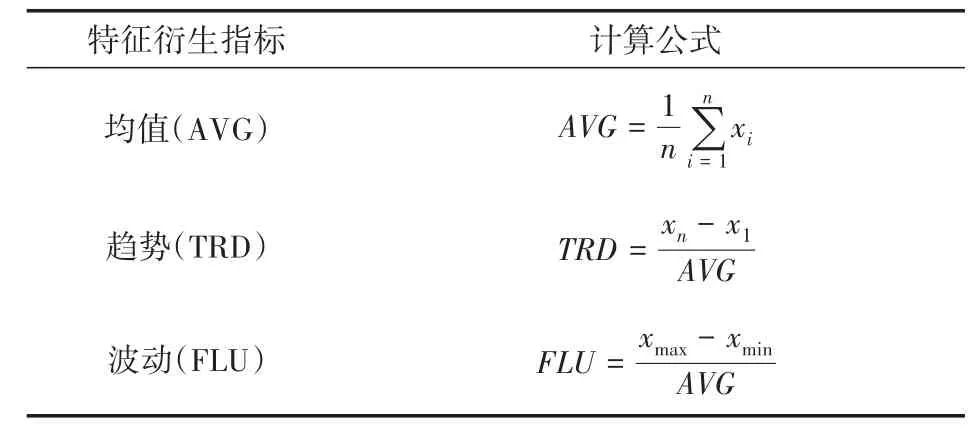
表5 特征衍生指标
对每个传感器的参数数据都进行均值、趋势和波动的特征衍生,根据数据集采样数据记录次数的大小,选取时间窗口长度T=20,优化后的模型评估结果如表6所示。

表6 优化后模型评估结果
通过基于时间窗口的特征衍生模型优化方案对LightGBM模型进行优化,测试集的判定系数提升了30.8%,具备非常好的优化效果。
随机选取编号20、66的发动机,使用Light⁃GBM预测的RUL和实际RUL对比结果如图5、图6所示,预测效果良好。

图5 20号发动机LightGBM的RUL预测结果

图6 66号发动机LightGBM的RUL预测结果
4 结语
基于多个传感器参数的航空发动机仿真退化数据,通过对数据进行探索性分析、描述性分析、相关性分析、可视化分析、特征选择、归一化等数据处理环节,不断提升数据质量,然后采用LightGBM建立机器学习模型实现了对发动机RUL的预测,并对模型进行分析与综合评估,同时提出一种基于时间窗口的特征衍生模型优化方案。实例分析结果表明:测试集的判定系数提升了30.8%,说明该方案在模型优化方面的有效性。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
装备环境工程(2022年4期)2022-05-06
影像视觉(2018年12期)2018-11-29
中学生数理化·高一版(2017年2期)2017-04-25
初中生世界·八年级(2017年3期)2017-03-24
金点子生意(2014年4期)2014-04-10
中学生英语高效课堂探究(2008年9期)2008-11-17
科学启蒙(2006年4期)2006-05-11
