
面向AI的语音数据采集服务平台的设计与实现
2021-02-26 16:53王子韵钮辰洋
电脑与电信 2021年11期
王子韵 钮辰洋
(中国传媒大学信息与通信工程学院数字媒体技术系,北京 100024)
1 引言
人工智能的细分领域众多,比如大家最为熟知的视觉人工智能与语音识别[1],其中语音识别在近几年发展迅速,特别是深度神经网络的出现[2],使语音识别正确率达到了98%以上,语音识别也在语音输入、语音机器人[3]、智能客服[4,5]等众多领域大显身手。识别能力方面,以科大讯飞为例,除支持中文普通话和英文外,还支持35 个语种、24 种方言和1 个民族语言的语音识别。
语音识别中一大难点是方言和少数民族语音识别[6]。海量的语音数据是语音识别模型获得高识别率的关键。由于中国地域辽阔,方言众多,每个省份都有可能有多种方言口音,同种方言的个体发音也有所区别,如果单靠人工主动收集各种方言语音数据,难度极大,数据覆盖面和样本分布很难做到均衡。因此,如何有效拓展语音数据收集渠道,扩大数据覆盖范围,如何对数据进行高质量的标注[7],从而获得精准的有价值的语音数据也是目前语音AI亟待解决的问题。
本文设计开发的面向AI 的语音数据采集服务平台,旨在提供万众参与的语音,特别是方言语音的数据采集方式,平台采用游戏方式采集语音数据,同时设置竞争性任务对语音数据进行交叉校验和标注,提升语音数据采集的质量和可用性。同时,平台具备定制化的语音采集功能,可以实现定向采集某种方言语音数据,使语音数据采集更加方便、高效,同时降低企业的数据采集与标注成本。
2 语音数据采集服务平台的设计
2.1 功能模块设计
语音AI 数据采集与服务平台总体分为三个功能子模块,包括基础服务、语音数据收集服务、数据集服务。
基础服务模块用于提供用户管理、数据标签管理、公告管理、客服交流、积分管理等基础服务,如图1所示,以提供系统的基础数据管理功能,保证系统基本功能的正常运行。

图1 基础服务模块功能
语音数据收集服务的目的在于以较低的成本获取较高价值的语音样本数据。该模块又可分为语音数据收集、语音数据管理两个子模块。
数据收集模块提供的主要功能有:语音游戏、定制任务、出题答题、交叉纠错和数据标注。用户可以参与系统提供的各种有趣的游戏,结交朋友,领取任务,赚取积分与奖励。在用户参与游戏过程中,后台采集和存储用户的语音相关数据,例如方言音频、方言文字等信息,对其进行保存和处理,是语音数据的主要来源。

图2 语音数据收集服务模块功能
语音数据管理模块提供语音数据相关的管理功能,包括语音数据保存、审核、打包下载等功能。
2.2 语音游戏设计
2.2.1 谁是卧底
该语音游戏围绕具体文字来设计游戏规则,通过游戏获取语音数据,游戏规则如下:系统随机匹配7 个不同地区玩家,然后随机选择6个相同词语和1个发音相近词语(用方言读不容易分辩,如饺子、轿子)给7个玩家,玩家每轮都用各自方言读出词语,结束后投票,票数最多的出局,如果卧底到最后一轮则卧底获胜。游戏过程如图3所示。

图3 语音游戏“谁是卧底”的基本流程
2.2.2 多人正规赛
“多人正规赛”的设计目标是产生带有精准标签的语音数据,减小人工审核和管理的压力。
游戏题目由后台决定,因此后台可以收集任意想要的语音数据。在游戏过程中,后台将文字题目发给出题录音玩家,该名玩家查看题目后,录音上传语音数据,后台保存语音数据和标签,同时将题目中的文字打乱后发送给其他玩家,玩家击败对手赢取积分,兑换奖励。游戏流程如图4所示。

图4 语音游戏“多人正规赛”的基本流程
2.2.3 个人秀
语音游戏“个人秀(方言秀)”的主要功能是收集同一段文本所对应的不同的方言数据,具体功能设计如下:用户可以主动发起一个话题,格式不限,可以是文本、歌曲、古诗等等,并为其配音,经过审核后展示出来,供其它用户欣赏,其它用户可以发起新的话题,或者为已有的话题配音,以此获得该段文本所对应的不同方言数据。
2.3 其他主要功能
2.3.1 出题答题
出题答题的模式是用户出题,用户答题。用户不仅可以回答来自五湖四海的方言题目,还可以自己出题,让其他的用户回答。这样可以丰富方言题目类型及方言题库,增加游戏的新鲜度,同时提高用户参与的积极性和游戏的趣味性,增强用户黏性。
2.3.2 交叉纠错
交叉纠错任务要求任务领取者对他人发送的音频和文字做审核,检查音频中的方言是否正确,也可以在审核过程中上传正确的语音数据,目的是为了解决大量语音数据审核的问题,通过有效的奖励机制让大量用户参与到数据审核工作中,利用纠错功能可以对数据库中还未审核的方言语音数据进行人工审核,提高语音数据及其标注数据的可靠性。
2.3.3 数据标注
每份数据需要多种不同的标注才能具备相应的价值。有效标注越多,越准确,数据具备的价值将会越高。系统通过完善用户的基本信息,将用户通过游戏和活动所产生的数据自动加上尽可能多的有效标注,比如方言类型、地域、性别等。同时系统为用户提供更改数据标注的服务,用户对数据的标注有异议,可以更改数据的标注。平台为积极参与数据标注工作的用户提供奖励。
2.3.4 定制任务
可定制的数据采集任务能够满足客户的个性化语音数据采集需求,可以按照语音类别、地域、目标人群等属性设置定制语音采集需求。系统也会根据具体的属性设置将任务定向发放给满足要求的用户进行语音数据采集。
3 语音数据采集服务平台的实现
3.1 开发框架
3.1.1 Vue.js框架
Vue.js是一种渐进式UI设计框架[8],它提供了简易的、响应式的数据模型与视图层之间的状态管理机制,当数据模型状态发生改变,视图就会做响应式更新。Vue的核心组件只关心视图层,在本系统中主要用于Web页面的开发。
3.1.2 Spring Boot
通过简化配置,Spring Boot使得Spring应用的搭建更为简单,能够更好地解决之前存在的多个框架依赖包之间的版本冲突问题[9]。开箱即用、约定优于配置是Spring Boot 框架的两个重要策略。Spring Boot中嵌入了Tomcat、Jetty等服务器容器,不用单独安装web服务器就能运行。
3.1.3 Spring MVC
Spring MVC 框架是一款轻量级的、优秀的MVC(Model,View,Controller)框架[10]与Spring框架无缝集成,具有优越的性能,是业界主流的Web开发框架。
Spring MVC 中的控制器负责接收请求,并调用相应的模型进行处理,最后将处理结果返回。控制器可以调用相应的视图组件对处理结果进行渲染,并将其通过响应返回给客户端。Spring MVC 的组件结构具有高度可配置性,具有很好的灵活性和可扩展性,开发效率较高。
3.1.4 MyBatis
MyBatis是一种基于Java的数据持久层框架,简单易学,不依赖第三方组件,能够将SQL 语句与代码分离,提供业务逻辑和数据访问的逻辑分离,使得系统设计更加清晰,可维护性更好。
3.2 技术框架设计
平台技术框架设计如图5 所示。客户端分为Web 客户端、Android手机APP和微信小程序。客户端与服务端以HTML、XML和JSON三种数据格式与服务端进行数据通信。

图5 平台采用的技术框架
服务端使用Spring Boot、Spring MVC 等技术进行搭建,通过MyBatis完成数据持久化访问,数据保存在MySQL数据库中。服务端应用部署在Tomcat服务器上。
3.3 数据库设计
数据设计与系统的功能需求及其数据需求密切相关,语音数据采集服务平台的功能较多,设计完成了用户基本信息表、出题记录表、答题记录表、多人赛人员匹配表、多人正规赛队伍信息表、多人正规赛轮次信息表、语音采集数据表、积分明细表等25个数据库表。其中语音采集数据表的设计如表1所示。

表1 语音采集数据表结构
3.4 主要功能实现
下面以多人正规赛游戏为例介绍一下相关系统实现。
3.4.1 多人正规赛在Android APP中的实现
游戏实现的功能界面如图6所示。

图6 Android APP中的游戏界面
定义碎片类MultimatchFragment,该类中定义了一些匿名多线程类的对象,完成游戏计时等功能,如表2所示。

表2 多线程对象的定义
此外,多人正规赛游戏的功能主要在该类中定义实现,负责加载游戏界面、初始化游戏数据、进行游戏功能的控制,包括:录音、播放录音、提交录音、游戏倒计时等功能,该类的主要方法定义及其功能如表3 所示。其中实现录音功能的startRecording()方法定义如下:

表3 MultimatchFragment中的方法定义

3.4.2 多人正规赛在微信小程序中的实现
微信小程序中的多人正规赛的功能由四个文件来实现,分别是:team_battle.js、team_battle.wxm l 和team_battle.wxss,其中的wxss 文件用于设置样式,wxm l 文件用于设置页面布局,js 文件用于定义实现功能的各种JavaScript 函数,如表4所示。

表4 team_battle.js中的函数定义
按下录音按钮时进行录音的startHandel函数定义如下:


多人正规赛游戏在微信小程序中的功能界面如图7所示。
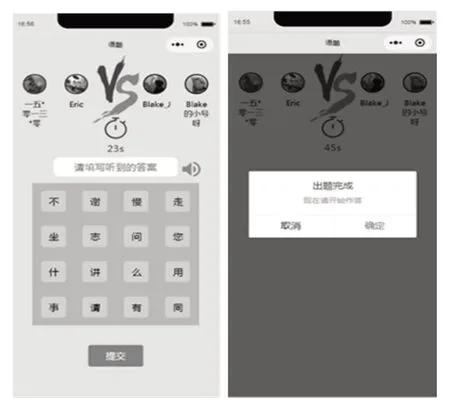
图7 微信小程序中的游戏界面
4 结语
本文针对目前语音AI 面临的语音数据采集问题,提出基于移动客户端的语音数据采集与服务平台,通过各种语音游戏的方式吸引用户参与,并通过游戏机制的设置获得语音数据收集、校验、标注的功能,定制任务能够很好地进行定向语音数据采集,可以较好地解决个别方言数据不均衡的问题,为语音识别提供更为有效的语音数据。
猜你喜欢
东方少年(2022年28期)2022-11-23
小资CHIC!ELEGANCE(2022年1期)2022-01-11
今日农业(2021年15期)2021-11-26
数学物理学报(2020年3期)2020-07-27
新世纪智能(高一语文)(2019年11期)2020-01-13
新世纪智能(高一语文)(2019年11期)2020-01-13
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
