
基于空间关系的维吾尔文图像关键词检索
2021-02-25 05:51:44徐学斌阿里木江阿布迪日依木朱亚俐阿力木江艾沙库尔班吾布力
计算机工程与设计 2021年2期
徐学斌,阿里木江·阿布迪日依木,朱亚俐, 阿力木江·艾沙,库尔班·吾布力+
(1.新疆大学 信息科学与工程学院(网络空间安全学院),新疆 乌鲁木齐 830046;2.新疆维吾尔自治区科技项目服务中心 项目服务部,新疆 乌鲁木齐 830002;3.新疆大学 教师工作部,新疆 乌鲁木齐 830046)
0 引 言
随着文档图像的规模越来越大,快速准确度检索此类文档逐渐成为研究热点。对于中文、英文等语言,ORC[1](光学字符识别)技术已非常成熟,检索速度快,准确率高。对于我国新疆地区常用的少数民族语言维吾尔语而言,投入的研究资源较少,并且字符的黏连特性加大了字符的识别难度,因此目前尚无较成熟的维吾尔语OCR技术[2]。近来有学者提出针对文档图像的关键词检索方法,首先对文档图像进行单词切分并提取特征,然后将输入单词图像与切分后的单词图像库中的单词图像逐一进行特征匹配,返回相似度较高的单词图像的页码等信息。关键词检索无需对构成单词的字符进行精确切分和识别,大大降低了检索系统的复杂度,对于不易进行字符切分和识别的文档,如字符粘连型语言文档、手写体文档、古籍文档等文献的检索有重要意义。周文杰等用形态学梯度算法对维吾尔文档图像进行单词切分[3],然后根据切分后单词图像的LBP(局部二制模式)等特征来实现关键词检索[4]。李静静[5]提出基于层级匹配的维吾尔文关键词检索,将匹配过程分为粗匹配和精匹配两个阶段,来提高检索效率。喻庚等[6]提出了基于索引的快速手写体中文文档检索方法,通过提取文本的候选切分-识别网格来生成索引文件,然后在索引文件中查找对应关键词。白淑霞等[7]提出了基于线性判别分析主题模型[8,9]的关键词检索方法,实现了蒙古文古籍文献的检索。
基于空间关系的维吾尔文关键词检索方法首先对印刷体维吾尔文档图像进行单词切分,生成单词图像集合,然后提取单词图像中各连体段之间的空间关系特征并生成特征文件,提取输入单词图像的特征并在特征文件中查找与其相似的特征,返回该特征对应的文档信息,从而实现印刷体维吾尔文档图像的关键词检索,检索系统框架如图1所示。
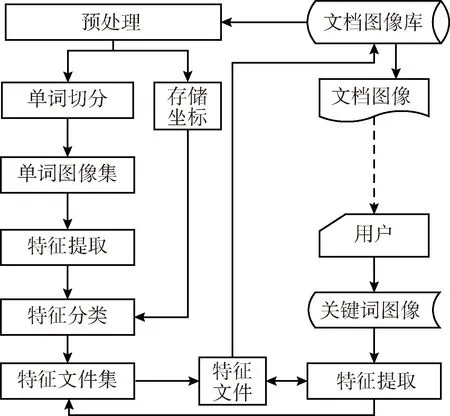
图1 系统框架
1 维吾尔文单词图像切分
1.1 图像预处理
单词切分的准确性直接影响关键词检索的效果,为了更好执行单词切分任务,在切分之前需要对文档图像进行预处理,主要包括图像去噪、倾斜校正[10]、亮度调整以及灰度化二值化[11]等。预处理工作的目的是使图像中文字的笔画信息更加清晰,突出文字像素和背景像素之间的差别,同时减小不同图像之间的亮度和对比度差别。
1.2 单词图像切分
单词图像切分[12]主要分为文本行图像切分、连体段切分[13]以及合并属于同一单词的连体段。首先对预处理后的文档图像进行水平投影,得到每一行的行像素累加值。经过预处理后图像中有文字信息的黑色像素点的像素值为0,空白像素点的像素值为255,所以文本行的行像素累加值明显小于空白行的行像素累加值。根据文本行和空白行的行像素累加值的大小,通过设定阈值,并将每一行的像素累加值与阈值比较大小,大于设定阈值则说明此行没有文字信息,为空白行,反之则说明此行为含有文字信息,属于文本行。阈值的大小设为空白行的行像素累加值减去300,即可区分文本行和空白行,减去300的目的是减小二值化过程中引入的噪声对判别的干扰。由于文本行和空白行在垂直方向上都有一定的连续性,不会单独出现一行,根据这一特点即可找出所有文本行在垂直方向上的始末位置,从而将其准确切分出来。完成文本行切分后,需要对文本行图像进行连体段切分。连体段的切分原理同文本行切分原理相同,通过对文本行图形进行垂直投影,根据列像素累加值的差异性,即可将文本行图像中连体段之间的空白列与包含文字信息的文本列区分出来,从而找到所有连体段在文本行中水平方向的始末位置,将其切分出来,投影示意图如图2所示。

图2 文本行和连体段切分效果
完成文本行图像中的连体段切分后,需要对属于同一单词的连体段进行合并才能获得完整单词的位置坐标,从而实现单词图像切分。由于在维吾尔文中,单词之间的空白间隙与单词内部连体段之间的空白间隙有明显的不同,根据此差异性,设置合理的阈值来区分不同的空白间隙。根据维吾尔语的书写规则,连体段的合并从右往左进行,若连体段间的间隙值小于设定阈值,则说明此间隙属于单词内部,将与此间隙相邻的连体段的位置进行合并,反之则说明此间隙属于单词之间的间隙,记录此间隙右侧经过合并的连体段的位置,此位置即为一个完成单词的位置。以此规则从右往左依次进行,即可找出文本行图像中所有单词的位置,从而将其切分出来。由于任意文本行中的空白间隙由单词内部的间隙与单词之间的间隙组成,当单词的字体、字号等不同时,间隙的值也会发生相应变化。通过对文本行中的间隙进行K-means聚类[14]处理来获得判别阈值,来减小上述变化对设置阈值的影响。设间隙判别阈值为M,则M的计算公式如下
M=(A+B)/2+1
(1)
其中,A与B分别为对文本行中所有间隙采用K-means聚类时获得的两个聚类中心,完整的单词切分效果图如图3所示。

图3 单词切分效果
1.3 单词位置信息
在单词切分中,获得单词图像在文档图像中的位置信息后,将单词图像单独保存在文件中,同时需要将单词图像的位置信息保存在文件中,使其能够在最终返回给用户的文档图像中用矩形框标注出检索出的目标单词。为此,首先将单词图像按一定规则命名,如文件名为“3_12_6.bmp”的单词图像表示第三张文档图像的第12行中从右往左数第6个单词。然后创建“.csv”文件来保存对应单词的位置信息,格式如“3,12,6,264,740,61,25”,前三位代表单词图像的文件名称,后四位为该单词图像在该页文档中的位置坐标信息。
2 特征提取与查询
2.1 空间关系特征
中文和英文等大多数语言中单词都是由轮廓大小基本一致的字或者字母排列组合而成,不同单词中字符的轮廓大小与位置都有着相同的规律,很难作为分类特征。维吾尔语中单词由不同数量的连体段构成,每个连体段由一定数量的字母黏连书写而成,构成连体段的字母数量可以是一个或者多个。由于每个连体段的宽度、高度不同,空间位置也不按规则排列,所以与其它语言相比,维吾尔语单词具有丰富的空间关系。本文提取的针对维吾尔语单词的空间关系特征包括连体段的宽度、高度以及在单词图像中的水平方向坐标、单词图像中垂直方向的顶部和底部位置的坐标,每个连体段的空间关系特征由上述5个位置信息构成。本文中将单词图像的上述特征统称为空间关系特征,这种特征的优点是对图像的细节变化不敏感,因此对不同质量的图像有很强的鲁棒性,但是对于单词图像的空间尺度变化较为敏感。单词图像的空间关系特征如图4所示。
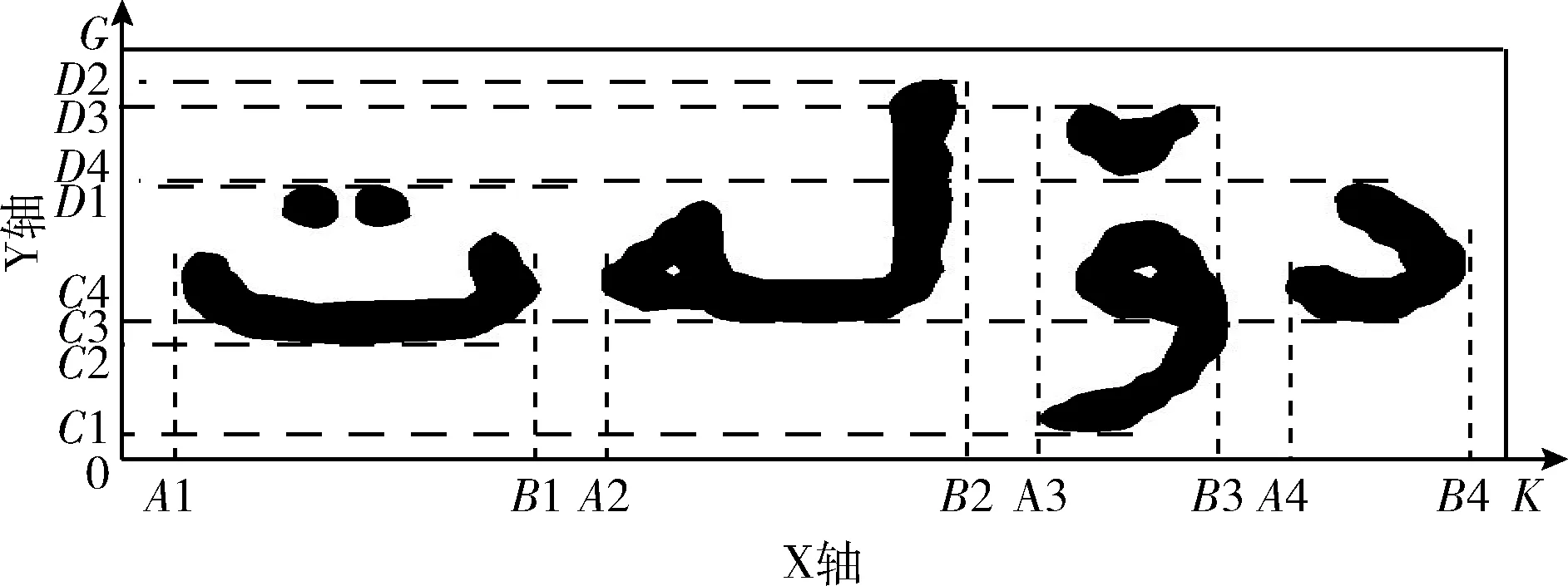
图4 单词空间关系特征
如图4所示,图中展示了一个由4个连体段构成的单词的特征示意图,我们以单词图像的下边界为X轴,左边界为Y轴建立坐标系,根据坐标轴中标出的坐标即可求出单词图像的所有空间关系特征。每个连体段的特征由5维向量构成,加上单词图像的宽度信息,一个由4个连体段构成的单词将会产生一个21维的特征向量。单词的特征向量的维数会随着构成单词的连体段数目的变化而变化,连体段数目越多,则特征向量维数越高,特征信息越丰富。图4中构成单词的每个连体段均由单个字母构成,而维吾尔语中单词内部的连体段一般都由多个字母通过不同的顺序与连接方式书写而成,这种特点使连体段的宽度、高度、空间位置等信息变化多样。构成单词的各连体段以不同的顺序排列组合后进一步丰富了单词的空间关系特征,使我们能够用这种空间关系特征来表征对应单词。
对于连体段数目较少的单词,比如由一个连体段构成的单词,这类单词只能提取6维的空间关系特征,由于特征维数较少,很难用空间关系特征直接表征这类单词。由一个连体段构成的单词,连体段中字母的数量通常较多,连体段的宽度也较宽。因此对这类单词的连体段按照一定规则进行拆分处理,使其拆分后由若干个不完整的连体段构成,这样按照上述规则提取其空间关系特征,将会成倍增加单词的特征维数,使提取的特征更易于表征单词。
2.2 特征提取
采用投影法来获取连体段的对应坐标,通过坐标求得该连体段的空间关系特征。设图4中单词图像的第一个连体段的5维特征分别为A、B、C、D、E,首先对单词图像进行垂直投影,得到水平坐标A1、B1。然后根据此坐标,将第一个连体段图像在垂直方向切分出来,对切分后的图像进行水平投影,得到垂直坐标C2、D1,该连体段的5维空间关系特征计算公式如下

(2)
同理可求得其它连体段的空间关系特征,将所有连体段的特征依次排列即可生成完整单词图像的特征向量。
对于只有一个连体段构成的单词,由于连体段数目太少,在使用上述方法提取特征之前,对单词图像进行基线置白处理,仅保留单词图像中垂直方向比较突出的部分,将其看作一个连体段并按照上述规则提取特征,来扩充单词图像的特征信息,单连体段单词基线置白如图5所示。

图5 单连体段单词基线置白
从图5中可以看出,单连体段单词如果直接进行特征提取,则只能提取5维空间关系特征,经过基线置白后的单词图像可以看作由6个连体段组成的单词,能够提取30维的空间关系特征,特征数据量扩充了6倍。
2.3 特征文件
生成的特征文件中每个单词图像的特征向量由包含单词不同方面信息的4部分构成,第一部分为单词的宽度信息,因为维吾尔语单词的宽度变化范围较大,根据宽度信息可以非常快速地筛选出与其宽度相似的单词,大大减小查找范围。第二部分为单词的空间关系特征,由5个小部分构成,每个部分包含了单词中不同连体段的同一特征,用于单词的精确匹配。第三部分为单词图像的页码信息,页码格式如“23,12,6”表示单词属于第23页第12行从右往左的第6个单词。由于在单词切分后的单词图像的文件名的命名规则与此相同,因此可以直接从输入单词图像的文件名中获得单词的页码信息。第四部分为单词图像的位置信息,即在对应文档图像中最小外接矩形框的坐标,用于返回给用户检索结果时标注单词,单词图像的位置信息需要在单词切分后生成的单词位置信息文件中读取。
为提高查询速度,预先将所有单词图像的特征信息生成特征文件。单词图像的连体段数目不同,则单词的特征向量的维数也会有很大差异,为便于查询,建立多个“.csv”文件来存储不同连体段数目的单词图像的特征,如文件名为“LTD3.csv”的文件中存储所有连体段数目为3的单词图像的特征。建立8个“.csv”来分别存储单词图像的特征,表示最多能存储到连体段数目为8的单词图像的特征,8个文件中每一行的数据维数分别为13、18、23、28、33、38、43、48,其中“LDT1.csv”中存储经过基线置白后仍旧只有一个连体段的单词图像的特征向量。
2.4 关键词查询
在开始查询前将已生成的6个单词特征文件分别读取到计算机内存当中。查询时首先将输入的待查询关键词图像进行水平方向和垂直方向的等比例缩放,缩放后的单词图像与单词图像库中的单词图像高度相同。然后对单词图像进行预处理,并进行水平投影,得到单词图像的连体段数目。若单词图像的连体段数目为1,则对该单词图像进行基线置白处理后再提取其空间关系特征,若连体段数目大于1,则直接进行特征提取。提取单词图像的空间关系特征后,根据预处理后单词中包含的连体段数目,在相应的特征文件中寻找与其特征相似的单词图像。寻找过程分为两步,第一步寻找与其宽度相似的单词,根据经验略去那些与其宽度之差大于10的单词图像。第二步为对宽度与其相似的单词图像,逐一比对二者的空间关系特征,若二者空间关系特征对应位置的数据差值大于3,则停止与该单词比对,继续寻找下一单词,反之则继续下一位比对。最后返回与其单词图像宽度只差不大于10,且相对应的每一位空间关系特征的差值都不大于3的单词图像的页码信息。
3 实验结果与分析
本文实验所用电脑配置为64位win7系统,处理器为Intel core i3 4150,4 GB内存。检索性能的评价指标有准确率(precision)、召回率(recall)、F值和检索耗时,上述指标的计算公式如下

(3)
文档图像库的来源为新疆大学出版社出版发行的书籍《马列主义经典著作选编》的维吾尔语版本,为模拟不同的办公环境,用不同型号的打印机将纸质书籍扫描为文档图像,尺寸为716*1011,100 dpi。从扫描后的文档图像库中随机抽取了115张文档图像进行关键词检索实验,经过单词切分后生成24 460张单词图像,单词图像库中不同连体段数目的单词统计结果如图6所示。
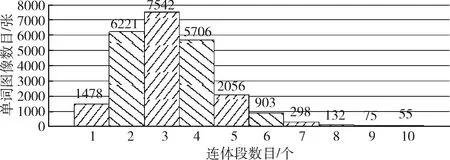
图6 不同连体段数目的单词统计结果
从图6可知,维吾尔语常用单词的连体段数目集中在1至6之间,其中连体段数目为2、3、4的单词图像最多。单词的连体段数目不同时,单词图像的特征维数也会不同,为了验证单词图像的连体段数目对检索结果的影响,在单词库中分别找出连体段数目为1至6且出现次数较多的单词图像各3张作为输入关键词进行实验,分别统计每张单词的查询结果的准确率,查询结果见表1。
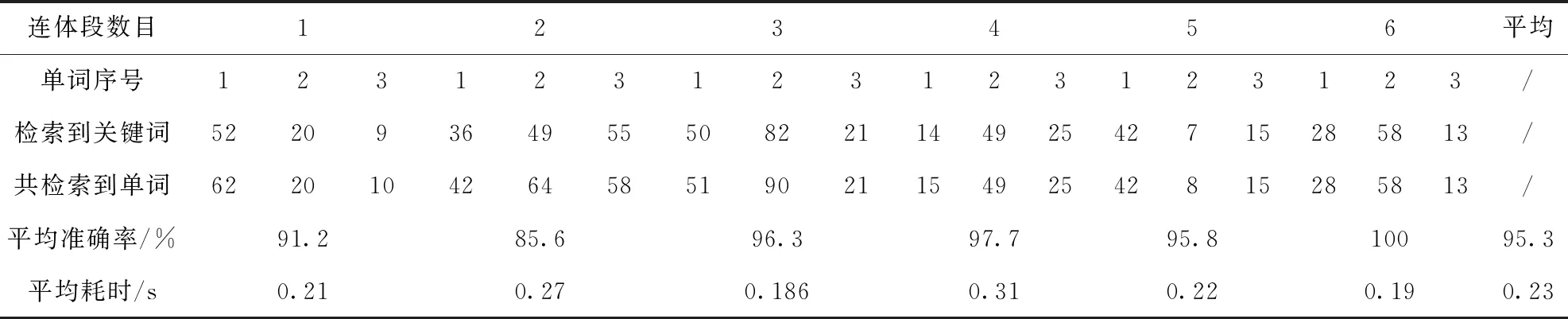
表1 不同连体段数目的单词检索结果
从表1中可知,连体段数目为1和2时,输入的3张关键词图像的查询准确率相对较低,分别为91.2%和85.6%。当连体段数目介于3到6之间时,输入关键词的的查询准确率都在95.5%以上,尤其是当连体段数目分别为4、5、6的9张输入单词的查询结果中总共只有两张分类错误,原因是随着单词的连体段的数目的增加,单词图像的特征维数也在增加,所以查询结果的准确率较高。对于连体段数目为1和2的单词,虽然对其连体段进行了拆分处理使其特征维数在20维以上,但由于拆分过程存在误差,所以关键词查询结果的准确率相对较低。其中连体段数目为1的输入关键词查询结果的平均准确率反而高于连体段数目为2的关键词,原因是一般由一个连体段构成的单词的连体段都比较宽,包含的字母较多。而某些连体段数目为2的单词,其内部连体段可能较窄,经过拆分处理后的连体段总数反而少于原本连体段数目为1的单词拆分后的数目。从表2还可以看出18张输入关键词图像的平均查询时间为0.23 s,查询速度较快。
为了综合评价提出的针对维吾尔文档图像的关键词检索系统的性能,在切分好的单词图像库中随机选取了10张在出现频率较高且有丰富词意的单词,如“国家”、“世界”、“生活”等,并人工统计了每个关键词在115张文档图像库中的出现的次数。10张关键词的检索结果见表2。

表2 本文方法对10张关键词图像检索结果
由表2可知在选取的10张关键词检索实验中,除第二张关键词准确率相对较低为73.3%,其它单词的准确率都在97%以上。在召回率方面,第五张关键词的召回率最低为87.5%,其余关键词召回率都保持在90%以上。分析第二张关键词图像查询结果准确率较低的原因时发现,第二张单词由3个连体段构成,召回错误的单词与输入单词极为相似,有两个连体段完全相同,只有一个连体段的辅助标点不同,说明本文方法对于外部轮廓及空间位置都相似而内部有细微变化的连体段区分能力较差。10张单词图像查询结果的平均准确率达到了96.47%,平均召回率达到了93.74%,综合性能为95%,平均检索耗时0.25 s,验证了本方法在维吾尔文档图像检索中的有效性。为进一步验证该方法的性能,用相同的数据库与测试单词图像分别在已有的上采样+BHPF+MB-LBP+OSVM[4]的检索方法与模板匹配+HOG+SVM[5]的检索方法中做了对比实验,3种方法的准确率和召回率的对比分别如图7、图8所示。

图7 3种方法对10张关键词图像检索结果的准确率对比
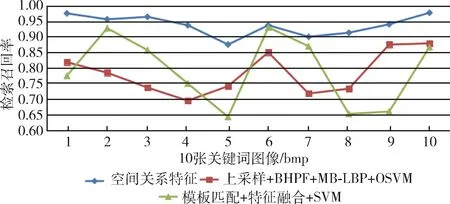
图8 3种方法对10张关键词图像检索结果的召回率对比
由图7、图8可知,基于上采样+BHPF+MB-LBP+OSVM的检索方法的平均检索准确率为86.7%,平均召回率为78.3%。基于模板匹配+HOG+SVM的检索方法的平均准确率为91.14%,平均召回率为79.31%。两种基于经典特征与SVM的方法都存在准确率和召回率波动较大的问题。基于空间关系特征的检索方法与以上两种方法相比,检索结果的准确率和召回率都有很大的提高,且针对不同的单词,检索性能基本保持稳定,波动较小。在检索耗时方面,以上两种检索方法的平均检索时长都大于10 s,而基于空间关系特征的检索方法平均检索时长仅为0.25 s,在时间性能方面有较大优势。
4 结束语
针对维吾尔文档图像的检索问题,提出一种基于单词内连体段的空间位置关系的检索方法,特征提取简单,系统复杂性低,并且保持较高的检索准确率与召回率以及较短的检索耗时。该方法无需知道单词图像中笔画的全部细节,只需知道每个连体段的空间位置与大小,因此对带有不同噪声的文档图像适应性较强,召回率较高。同时提出了特征分类存储检索框架,根据单词连体段的数目寻找特定的特征文件进行查询,进一步降低了查询时间,给用户较好的检索体验。但该方法也有多处不足之处,针对连体段数目为1和2时特征较少而进行的连体段拆分处理方法仍然需要改进,检索系统对单词中被连体段包裹在内部的附加标点符号变化不敏感。因此下一步的工作中将寻找新的特征与本文特征进行融合来克服检索系统的这方面的缺点。同时,单词切分方法也有待改进,实验中测试关键词的数目以及文档数据库的规模都需要进一步扩展来验证方法的有效性,降低偶然因素对检索结果的影响。
猜你喜欢
中学化学(2024年4期)2024-04-29 22:54:35
中国新闻周刊(2021年26期)2021-07-27 04:02:12
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
信息安全研究(2016年4期)2016-12-01 06:06:54
专利代理(2016年1期)2016-05-17 06:14:36
中国民族医药杂志(2016年5期)2016-05-09 07:43:50
作文大王·低年级(2016年3期)2016-03-11 00:48:53
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
电脑迷(2012年4期)2012-04-29 06:12:13
质量与标准化(2010年5期)2010-05-03 04:15:40
