
基于多核学习卷积神经网络的稀疏数据推荐
2021-02-25 05:51霍雨佳
计算机工程与设计 2021年2期
霍雨佳,左 欣,张 虹
(1.贵州理工学院 人工智能与电气工程学院,贵州 贵阳 550003;2.贵州省教育厅贵州省人工智能与智能控制特色重点实验室,贵州 贵阳 550003;3.贵州师范学院 继续教育学院,贵州 贵阳 550018;4.贵州财经大学 外语学院,贵州 贵阳 550025)
0 引 言
推荐系统的目标是通过分析用户与项目的互动数据,发现并预测用户对其它项目的兴趣,目前最为经典且有效的是基于协同过滤的推荐系统[1]。基于用户和基于项目是协同过滤系统的两种类型,两者思想基本一致,以基于用户的协同过滤系统为例,其核心思想是通过用户评分数据评估用户间的相似性,通过计算相似用户对目标项目评分的加权调和值来预测未知的评分。此类算法在稀疏数据集难以准确建立用户间的相似性,导致推荐的准确率较低[2]。
目前针对稀疏数据推荐系统较为有效的措施主要有基于矩阵分解模型[3]、基于集成学习方法[4]和基于深度学习[5]。在基于矩阵分解模型的方法中,文献[6]在用户矩阵中引入了用户关系的隐特征矩阵,极大地提高了对稀疏数据的预测效果。在基于集成学习的方法中,文献[7]使用多种相似性度量方法产生多个弱预测模型,然后通过集成算法将弱预测模型组合成强预测模型。在基于深度学习的方法中,被研究的神经网络模型包括了卷积神经网络[8]、深度信念网络[9]、长短期记忆网络[10]和自编码器[11]等。深度学习技术能够学习数据的深度特征,在特征提取能力方面具有较好的性能,但目前深度学习模型的超参数难以确定,且训练难度较大。
为了利用深度学习技术的优势,同时降低模型的训练复杂度,提出了一种基于多核学习卷积神经网络的稀疏数据推荐系统。不同于上述基于深度学习的推荐方法,本文利用结构简单的卷积神经网络(convolutional neural networks,CNN)提取辅助信息的特征,为了保证简单CNN结构的特征提取效果,通过多核学习技术对神经网络中间层进行核学习和组合,丰富特征向量的类型。此外,为了避免潜在因子矩阵的负入口所造成的信息损失,改用非负矩阵模型预测用户对项目的评分。
1 稀疏数据推荐系统框架
本文模型考虑了项目描述这一关键的辅助信息,如:商品介绍、电影剧情、歌曲介绍以及新闻摘要等,将辅助信息经过CNN处理生成文本潜在因子。图1是推荐系统的完整结构。本文以电影推荐系统为描述对象,将电影作为项目,电影的情节作为项目的描述。首先在预处理阶段,删除辅助信息中的显著性较低的内容,如一些标点符号和辅助词。然后使用Word2Vec模型[12]将辅助信息转化成密集分布的词表示,将词表示送入CNN学习密集向量的上下文特征,基于CNN输出的特征向量初始化非负矩阵模型的基础矩阵(项目潜在因子),非负矩阵模型预测出用户-项目矩阵的缺失评分。
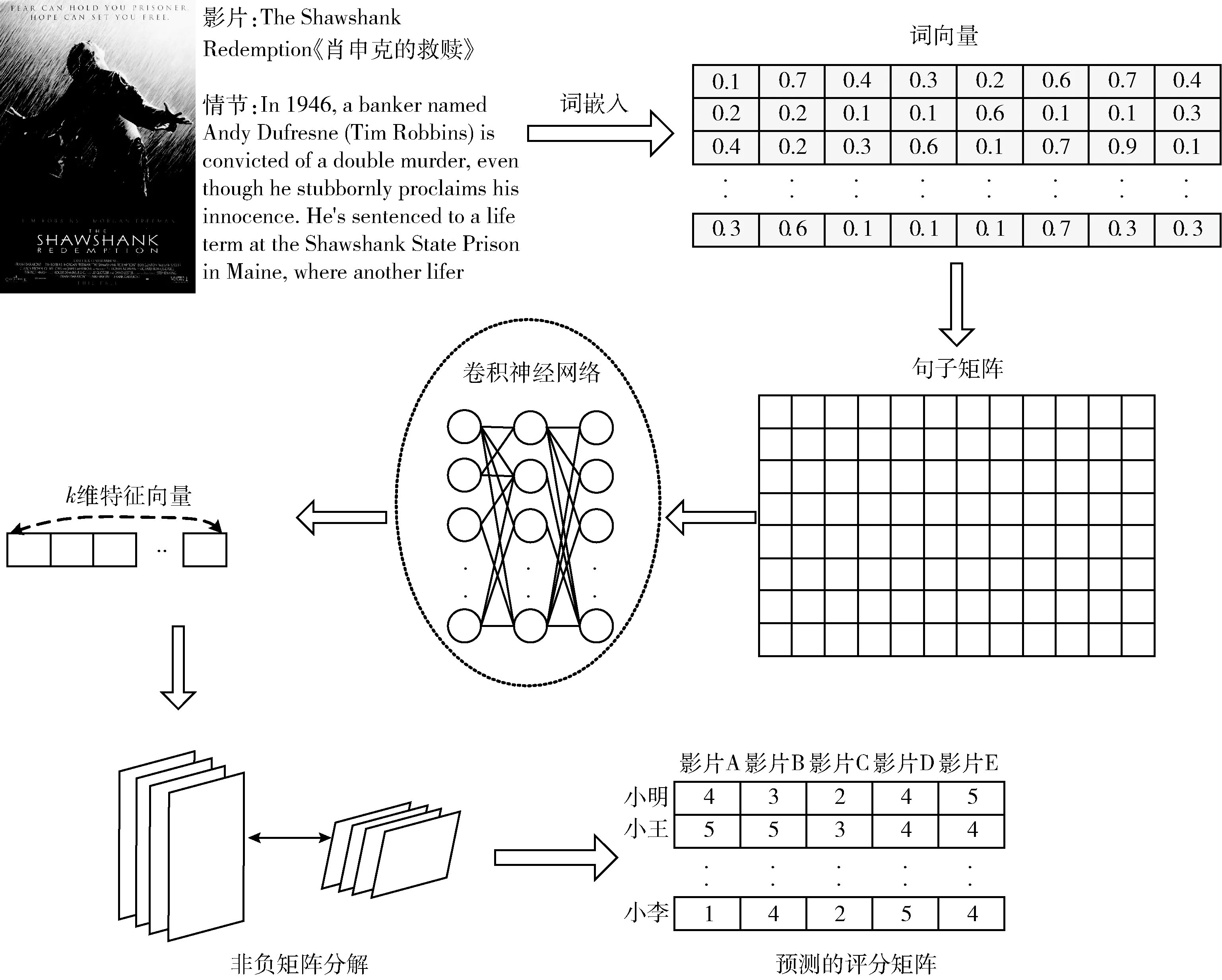
图1 推荐系统的完整结构
1.1 数据预处理
设U=[u1,u2,u3,…,um]为所有用户的列表,I=[i1,i2,i3,…,in]为所有项目的列表,将用户-项目评分矩阵表示为Rui∈[0.5,1,2,3,4,5]m×n,其中Rui表示用户u对项目i的评分,m为用户总数量,n为项目总数量。系统的目标是预测出缺失的评分R′ui,设G为项目描述信息,共包含l个词,记为w1,w2,w3,…,wl。基于n个项目的全部描述信息建立语料库C,表示为C∈{w1,w2,w3,…,wl,wl+1,…,wt},t为语料库C的词数量。
运用词嵌入模型Word2vec处理语料库C,生成s-维的词向量。Word2vec顺序地训练C中的词,最大化词的对数概率,其数学模型为
(1)
式中:|C|为语料库C的大小,c为训练窗口的大小。
采用层次Softmax[13]定义每个输出词的概率p(wt+j|wt),语义嵌入的维度应当和CNN的输入维度相等。CNN的输入层采用语料库的Word2Vec模型,将Word2Vec模型转化成辅助信息的密集矩阵,数学式为
(2)
式中:vti表示词向量t的第i个维度,s为向量的维数。将矩阵X的每个词向量直接级联,因此X保留了词之间的语义。设vi∈X为第i个词向量,将一个长度为l的句子表示为
v1∶l=v1⊕v2⊕…⊕vl
(3)
式中:“⊕”表示将向量级联。
1.2 卷积神经网络设计
图2是卷积神经网络[14]的结构。

图2 卷积神经网络的结构
卷积层对不同大小的窗口进行卷积运算,提取出词在辅助信息中的上下文信息。上下文信息中包含了词的顺序信息,卷积核的大小决定了目标词的周围词数量。假设h个词向量wi:i+h-1传入卷积核W,产生的特征设为ψi,那么卷积的计算式可表示为
ψi=f(Wh⊗X(:,vi:i+h-1)+b)
(4)
式中:“⊗”表示卷积运算,Wh表示大小为h的卷积核,b∈为一个偏置项,f为非线性激活函数。由于该卷积核的目标是分析词向量,因此核的一个维度保持与向量表示长度相等,另一个维度有所变化。卷积核处理的每个词向量为{v1:h,v2:h+1,v3:h+1,…,vn-h+1:n},生成每个词的上下文特征图为ψ=[ψ1,ψ2,ψ3,…,ψn-h+1]。
经过最大池化层计算特定filter特征图的最大值,选出特征图中最重要的特征。此外,池化方法通过池化操作将不同长度的句子统一成固定长度的特征向量,避免加入无关的上下文特征。每个filter被提取一个特征,通过多个filter学习文本的上下文特征集。最大池化层的计算模型为
Xf=[max(ψ1),max(ψ2),max(ψ3),…,max(ψn-h+1)]
(5)
上下文特征集送入全连接层,全连接层将Xf转化至k维的空间,构成协同过滤的潜在因子。在全连接层采用非线性投影生成k维的潜在因子向量,投影的数学模型为
Xv=tanh(Wf2{tanh(Wf1Xf+bf1)}+bf2)
(6)
式中:Wf1和Wf2均为投影矩阵,bf1和bf2分别为Wf1和Wf2所对应的偏置向量,Xv∈k。
1.3 协同过滤模型设计
基于非负矩阵分解(nonnegative matrix factorization,NMF)[15]实现评分预测,通过NMF将矩阵R∈R+m×n分解成两个子矩阵M∈R+m×k和N∈R+k×n,并且R、M和N的所有入口均为非负项,因此可获得以下关系:R≈M×N。在推荐系统的场景下,R+m×n表示m×n的非负矩阵,M可理解为项目,N为潜在因子,k为R的不可分解因子数量。因为在真实的推荐问题中,不存在负项的情况(项目、用户、评分),所以对M和N的非负约束提高了协同过滤系统的可解释性。
基于项目潜在因子对NMF进行初始化,模型的目标是找到两个排名较低的非负矩阵MXv∈R+m×k和N∈R+k×n来预测评分,计算式为:R=MXvN。将R和MXvN之间设立一个约束,作为目标函数
(7)
式中:MXv表示基于项目上下文特征初始化的潜在因子矩阵。
在预测过程中可能发生过拟合的情况,因此为目标函数加入F-范数正则项[16],目标函数改写为

(8)
式中:ρm为特征向量(MXv)u的正则项,ρn为Ni的正则项。
通过最小化目标函数获得特征矩阵MXv和N,数学模型为
(9)
式中:M>0且N>0。
将矩阵N初始化为k×n大小的随机矩阵:N=random[]k×n,k为评分矩阵的最小因子。通过迭代更新M和N计算目标函数的最小值,迭代的数学式为
(10)
用户u对于项目i的预测评分可计算为下式
R′ui=MuNi
(11)
式中:R′ui为预测评分。
算法1总结了本文推荐系统的算法,算法迭代更新两个潜在因子矩阵M和N,直至达到收敛。
算法1:基于非负最大矩阵的推荐算法。
输入:数据集的评分矩阵R,最大迭代次数Maxiter,阈值threshold。
输出:特征矩阵M和N。
(1)预处理电影辅助信息, 获得句子矩阵;
(2)采用CNN提取句子矩阵的特征向量;
(3)初始化:N=random[]k×n,M=Xv=MXv。
(4)forkfrom 1 toMaxiterdo
(5) forufrom 1 toMdo
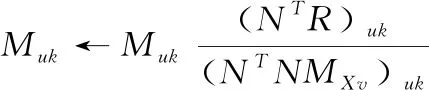
(7) endfor
(8) forifrom 1 toNdo

(10) endfor
(11)Rerr=RMSE(R-MN)2//计算目标函数
(12) ifRerr (13) break; (14) endif (15)endfor (16)Return。 为了保证简单CNN结构的特征提取效果,通过多核学习技术对神经网络中间层进行核学习和组合,丰富特征向量的类型。 采用多核学习将CNN每层的低显著性特征集组合成高显著性特征集,通过凸组合将每层的权重向量组合,组合的数学模型为 (12) 上述多核学习方法可以组合任意类型的核,本文将CNN每个中间层的表示向量作为一个核,对CNN进行多核学习,经过多核学习获得的多个核称为“组合核”,该机制类似于Boosting提升算法,通过组合多个弱分类能力的核来提高CNN的总体表征能力。 (13) 式中:ζr(x)=g(Wrx+b),Wr为权重矩阵,b为偏置向量,g为非线性元素函数,l表示网络中中间层的数量,“∘”表示矩阵乘法运算(在卷积层的矩阵之间为卷积运算),最终ζout把最高层的表示映射到输出。 CNN的卷积层输出是形状不同的矩阵形式,网络训练之后对CNN的中间表示进行压缩来建立每一层的核。将卷积层的表示压缩,与最小长度的表示矩阵对齐,删除多余的元素。假设φr(x)表示CNN网络第r层的表示。图3是对CNN每个中间层进行多核学习的网络结构图。 图3 KerNET程序具有CNN作为基础网络 传统CNN仅使用最后一个隐层的输出作为网络的表示,而在CNN的中间层也包含了输入数据不同角度的特征。本文采用多核学习组合中间层的表示,以期提高神经网络的泛化能力。本文的多核学习框架包含两个阶段:首先训练CNN,确定CNN的参数;然后使用每个中间层表示φr建立基础核kr(x,z)=<φr(x),φr(z)>。最终,通过多核学习(式(12))将基础核结合。算法2是多核学习CNN算法的伪代码。 算法2:多核学习CNN算法。 输入:输入数据矩阵X。 输出:多核特征表示kμ。 (1)训练CNN网络,获得网络参数; (2)获得CNN每一个中间层的表示φ0,φ1,…,φr(x)表示第r层的实例x; (3)将中间层表示转化为基础核:ki(x,z)=<φi(x),φi(z)>; (4)使用多核学习获得组合核:kμ(x,z)=∑rμrkr(x,z)。 本文的实验环境为PC机:Intel i7-9700 6核心处理器,16 GB内存,操作系统为64位 Windows 10操作系统。 采用2个在推荐系统领域广泛应用的benchmark数据集,分别为MovieLens 1M、MovieLens 10M。MovieLens 1M数据集包含1 000 209个显式评分,评分值为Rui∈{0.5,1,2,3,4,5},用户数量为6040,电影数量约3900部。MovieLens 10M数据集包含10 000 054个显式评分,评分值为Rui∈{1,2,3,4,5},用户数量为71 567,电影数量约10 681部。两个数据集的基本信息见表1,2个数据集均较为稀疏。 表1 实验数据集的信息 将电影的情节作为辅助信息,用于预测每个电影的评分。在其它应用场景下可将商品的介绍作为辅助信息,本文以电影推荐问题为研究目标。原数据集不包含每个电影的情节信息,利用IMDB提供的开放API,基于Python语言编写脚本检索每部电影的剧情信息。 对剧情信息进行以下预处理:首先,每个剧情文本的最大长度设为250个词,不足250个词的补充结束符。然后,计算每个词的TF-IDF(term frequency-inverse document frequency)[18],删除TF-IDF>0.5的词。词频(term frequency,TF)定义为词在剧情文本中出现的次数,逆向文件频率(inverse document frequency,IDF)反映了词在所有文档中的重要性。通过TF-IDF排除语料库中的相同词,选择TF-IDF值最高的8000个词构成语料库。将剧情文本中的非语料库词删除,保留语料库中的词。 应用Word2vec模型处理预处理后的剧情文本,生成电影项目的分布式表示。Word2Vec模型生成s维的特征向量,语料库和生成的词向量中包含了电影剧情的词特征和词的上下文特征。然后使用这些数据初始化卷积神经网络的输入层,即句子矩阵。经过卷积神经网络学习获得项目潜在因子向量,利用该向量初始化非负最大矩阵的项目潜在因素矩阵,最终生成对评分的预测结果。 将数据集的80%样本划分为训练集,剩余的20%为测试集。将根均方误差RMSE作为评分预测模型的评价标准,RMSE的数学式为 (14) 式中:R′为预测的评分。 采用精度、召回率、准确率和AUC也作为推荐系统的评价标准。基于项目的评分将项目分为相关类和不相关类,评分1-3作为不相关类,评分4-5为相关类。推荐系统的精度Pre、召回率Rec和准确率Acc分别计算为 (15) (16) (17) 式中:TP表示相关项被推荐,TN表示不相关项未被推荐,FP表示不相关项被推荐,FN表示相关项未被推荐。 AUC是精度和召回率两者间的权衡指标,评价推荐结果的总性能。采用5折交叉验证对评分预测模型进行训练,并生成对于缺失评分的预测。 (1)潜在因子参数 为了确定项目潜在因子的维度K值,通过试错法测试了不同K值的效果,K值分别为:50,60,70,80,90,100。图4是不同K值所对应的平均RMSE结果,图中可看出K值越高,RMSE越低,说明项目潜在因子的维度越高,评分预测的准确率也越高。下文实验中将潜在因子参数设为100。 图4 不同K值所对应的平均RMSE结果 (2)卷积神经网络参数 采用图2所示的卷积神经网络结构,卷积层设置3个区域大小3、4、5,区域的另一个维度等于项目的评分维度,即MovieLens 1M(0.5,1,2,3,4,5)的维度为6,MovieLens 10M(1,2,3,4,5)的维度为5。每个区域分别为2个filter,共6个filter。 通过试错实验测试卷积神经网络的输入(句子矩阵)维度对模型的影响。图5是不同输入维度下模型的预测性能,可看出输入维度越高,平均RMSE值略有下降,但是变化并非十分明显。考虑性能和计算复杂度之间的平衡,将输入维度设为200。 图5 不同输入维度下模型的预测性能 经过试错法将多核学习的μ值设为:卷积层=0.2,映射层0.1,池化层0.1,输出层0.6。 (1)评分预测实验 本文的主要贡献是提出了新的评分预测技术,用以解决稀疏性数据的推荐问题。首先对本文的评分预测性能进行验证,选择近年来的5个评分预测技术作为对比方法。文献[19]结合LDA主题模型和PMF技术对未知评分进行预测,LDA主题模型和本文所采用的词嵌入模型较为相似,因此将该方法作为对比方法来评价词模型的有效性,将其简记为LDAPMF。文献[20]结合将项目上下文信息输入PMF的项目潜在因子,对包含上下文信息的PMF进行统一运算,通过该算法验证本文CNN特征的有效性,将其简记为PMFLF。文献[21]是基于长短期记忆网络的未知评分预测方法,简记为LSTMRT;文献[22]是基于贝叶斯深度神经网络的未知评分预测方法,简记为BDNNRT;文献[23]是基于深度信念网络深度学习的未知评分预测方法,简记为DBNRT。文献[21-23]均为基于深度神经网络的预测方法,是近年来性能较好的预测方法,选择这3个方法可以验证本文方法的性能优劣。 图6是不同推荐系统对于评分预测的平均RMSE值,图中“本文方法1”表示在本文系统中采用常规CNN的模型,“本文方法2”表示在本文系统中采用多核学习CNN的模型。比较图中的结果可看出LSTMRT的预测性能略低于PMFLF,可见深度学习技术在评分预测问题上并未表现出明显的优势。本文方法1的预测效果好于LDAPMF、PMFLF、LSTMRT、BDNNRT和DBNRT方法,因此文中CNN卷积方法和辅助信息相结合的方法能够实现较好的评分预测效果。此外,“本文方法2”的预测效果也好于“本文方法1”,可看出本文通过多核学习技术能够有效地提高CNN网络的特征学习效果。 图6 不同推荐系统评分预测的平均RMSE值 (2)推荐系统实验 在LDAPMF、PMFLF、LSTMRT、BDNNRT和DBNRT 这5个对比方法中,LSTMRT的研究仅给出了预测评分的结果,并未提供推荐系统的推荐结果,因此将LSTMRT方法排除。图7是不同推荐系统基于预测评分的推荐性能,图7(a)和图7(b)分别为推荐系统的平均准确率指标和AUC指标。图中“本文方法1”表示在本文系统中采用常规CNN的模型,“本文方法2”表示在本文系统中采用多核学习CNN的模型。 比较图7中的结果可看出LDAPMF方法受到预测评分准确率的影响,其推荐性能明显低于其它推荐系统。本文方法1的推荐效果好于LDAPMF、PMFLF、BDNNRT和DBNRT方法,因此文中CNN卷积方法和辅助信息相结合的方法能够实现较好的推荐效果,增强推荐系统的性能。此外,“本文方法2”的推荐性能也好于“本文方法1”,可看出本文通过多核学习技术能够有效地增强推荐系统的性能。 图7 推荐系统的性能 本文利用结构简单的卷积神经网络提取辅助信息的特征,为了保证简单CNN结构的特征提取效果,通过多核学习技术对神经网络中间层进行核学习和组合,丰富特征向量的类型。为了避免潜在因素矩阵的负入口所造成信息损失,利用非负矩阵模型预测用户对项目的评分。实验结果表明了文中CNN卷积方法和辅助信息相结合的方法能够实现较好的评分预测效果,并且通过多核学习技术能够有效地提高CNN网络的特征学习效果。 虽然本文以电影推荐问题为描述对象,但是在许多实际应用中项目均包括简介、说明等文字信息,因此本文方法可以应用于其它各种类型的电子商务问题中。考虑到训练复杂度问题,本文主要采用了简单的CNN结构,未来将关注于不同神经网络结构在特定问题的预测效果。2 增强深度神经网络通过多核学习
2.1 多核学习
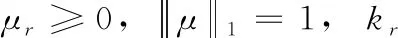
2.2 多核学习卷积神经网络


3 实验和结果分析
3.1 数据预处理

3.2 性能评价标准
3.3 模型的参数设置


3.4 实验结果和分析


4 结束语
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
大连工业大学学报(2015年4期)2015-12-11
