
基于自注意力的协同演进推荐
2021-02-25 05:50:40孙磊磊张宇翔肖春景
计算机工程与设计 2021年2期
孙磊磊,张宇翔,肖春景
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
个性化推荐系统的目标是从用户的历史交互数据中挖掘用户的兴趣,并向用户推荐最合适的项目。目前矩阵分解及其变体得到了广泛的应用,但是这些方法并没有明确考虑用户的兴趣偏好以及与项目特征属性的时序动态性。比如用户的兴趣和电影的受欢迎度是随着时间不断变化的。
时序推荐算法采用相应的序列处理技术(比如马尔科夫链、循环神经网络和注意力机制等)从用户的近期交互记录中挖掘用户短期的兴趣偏好。然而这类算法忽略了项目的特征也是随着交互而不断变化,即用户的兴趣和项目的属性是协同演进的。时序点过程有效地解决了用户和项目协同进化问题,但参数假设过多,违背了实际情况。近年来人们采用循环神经网络(RNN或者LSTM)分别表征用户以及项目的特征演进过程,但由于模型在每个时刻输入的信息太过单一,忽略了交互序列中项目之间的语义关系;其次由于参数共享,导致演进过程中的信息丢失,因此无法有效学习到用户以及项目的时序特征。
为解决上述协同演进过程中存在的问题,本文提出了基于自注意力的协同演进推荐模型(BSFRNN)。模型通过融合了自注意力机制提取的序列语义特征和基于RNN模型提取的时序特征有效解决了信息丢失和语义信息无法获取的问题。其次使用矩阵分解挖掘用户以及项目中长期不变的特征属性。将长短期特征进行融合得到用户以及项目当前时刻的隐向量。在预测层,使用多层感知机学习用户与项目的交互过程。
1 相关工作
矩阵分解方法是根据评分矩阵学习到两个低维的用户和项目的隐特征矩阵,最后通过內积的方式实现对未知项目的评分预测,但是当历史交互数据稀疏时,就会导致推荐的准确度降低。He等[1]使用多层感知机为矩阵分解引入了非线性的建模能力,一定程度上解决了冷启动的问题。然而这些传统的推荐算法将有序的交互数据独立处理,导致不能反映用户以及项目的时序动态性。
为使得用户以及项目特征属性随着时间不断变化,文献[2]引入了时序矩阵分解的方法,旨在使用用户的历史交互数据预测用户的未来行为。文献[3,4]使用RNN模拟用户近期的一般偏好,然后与一般的兴趣偏好进行有效的融合。Wang等[5]使用分层表示模型将用户序列行为表示的短期偏好与用户的一般偏好进行融合;特别的,Tang等[6]提出一个卷积序列向量推荐模型(Caser),模型使用卷积过滤器提取序列的时序信息,并与隐因子模型(LFM)挖掘的一般偏好进行融合,进而完成top-N的推荐。Zhang等[7]提出基于自注意力的度量学习模型(AttRec),模型通过自注意力模块提取用户交互序列中的时序信息作为用户近期的兴趣偏好,为避免內积产生的排序损失使用度量分解模拟用户长期的兴趣偏好。Kang等[8]提出SASRec模型,可以适应性的为用户交互历史分配不同的权重以预测用户的下一个行为。
上述推荐算法,片面的认为仅仅用户的兴趣满足时序动态性,而项目的特征属性是静态不变的。事实上,描述用户以及项目的特征属性是随着交互事件的发生而不断演进或者协同演进的。Wang等[9]使用时序点过程来学习用户以及项目的协同演进过程,但是方法中做了过多的参数假设,这些假设严重违背了实际。Dai等[10]提出了深层协同演进的推荐模型(Deep-Coevolve),该模型通过RNN模拟时序演进过程且重新定义了点过程的强度函数,有效提高了推荐准确性。Trivedi等[11]将这类思想应用于知识图谱,在之前的基础上融合了多种信息,解决了未来行为预测的任务。Chao等[12]在修正LSTM的输入的基础上,融合了一般矩阵分解模拟的静态特征。文献[13]提出LSIC-V4模型,模型在神经对抗的框架下,将RNN提取的特征与MF模拟的静态特征进行不同程度的融合,一定程度上增加了推荐的准确性。这些方法均采用RNN学习用户以及项目的时序动态性。但当仔细分析RNN的输入时,可以发现RNN的输入是顺序输入的,并没有考虑序列中项目之间的交互影响,这类影响(本文称为语义信息)对未来行为的预测是同样重要的。而基于self-attention的模型通过多头注意力机制可以有效获取序列的语义信息,但文献[14]通过实验表明self-attention能够用其高效的堆栈多头注意力机制有效获取语义特征,但提取长序列的信息时却弱于RNN。
本文提出的自注意力的协同演进推荐模型与上述协同演进方法所不同的是模型融合了自注意力提取的序列语义特征与RNN提取的时序演进特征,有效解决了单一模型导致的信息获取不完整的问题。其次,本文在RNN的输入端将用户当前时刻的近期交互序列作为输入,避免因参数共享而导致信息丢失。
2 基于自注意力的循环演进推荐建模
BSFRNN模型的框架,如图1所示。训练数据输入到模型之前,先根据交互对应的时间粒度分别提取用户以及项目近期的交互序列。模型可以分为用户和项目两个模块,两个模块是对称的,所不同的是项目的特征表现变化相对慢,因此每个时间粒度相隔时间较长。在每个模块中,将序列embedding化并分别输入LSTM以及自注意力机制中提取对应的时序信息,为了准确预测当前时刻用户以及项目的特征表现,模型将LSTM学习的和自注意力机制提取的特征进行融合。最后,将融合的特征按对应元素相乘并与矩阵分解表征的静态特征共同输入到MLP进行预测交互发生的可能性。

图1 t时刻行为预测
2.1 用户与项目的协同演进
假设U={u1,u2,…,uM}表示用户的集合,I={v1,v2,…,vN}表示项目集合,这里M和N分别表示用户以及项目个数。根据交互数据可以构建一个稀疏的用户-项目评分矩阵R,其中的Ru,v,t表示在时间t用户u对项目v的评分,评分值越高表示用户越喜欢该项目,不同于评分预测的任务,BSFRNN根据隐反馈数据向用户提供一个排序列表(top-N推荐)。
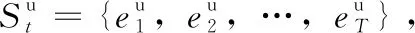
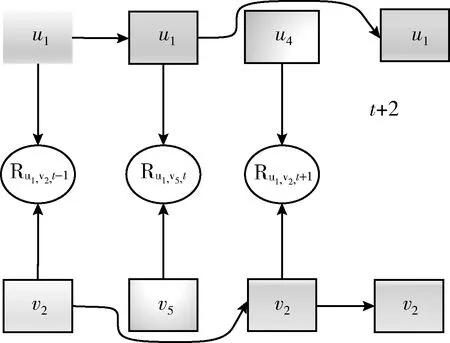
图2 用户以及项目时序演进
从图2中可以看出,用户的特征向量直接影响与之交互的项目的隐特征,而修正的项目特征向量会影响与之交互的未来的用户向量。因此可以看出这种协同演进的过程是事件驱动的。
2.2 循环自注意力

2.2.1 循环神经网络
基于RNN的模型主要用于从交互序列中提取用户或项目近期的隐特征,进而预测用户的下一次交互并向用户提供一个排序列表。特别的,这里使用RNN的变体LSTM获取用户以及项目交互序列中的时序信息。每个LSTM单元中是由记忆单元ct,输入门it,遗忘门ft和输出门ot组成。其中ft,it和ot是由过去的隐向量ht-1和当前时刻的输入所计算的,这里每个门所对应的权重参数和偏置不同,在这里使用W和b进行统一表示
[ft,it,ot]=σ(W[et,ht-1]+b)
(1)
其中,最为重要的贯穿交互始终的细胞状态ct(这里也叫记忆单元)通过LSTM中特殊的门结构有选择地记忆和遗忘
ct=ft⊙ct-1+it⊙tanh(V[et,ht-1]+bc)
(2)
一旦这些状态更新,t时刻的隐状态也就可以得到
ht=ot⊙tanh(ct)
(3)
其中,σ表示激活函数,如sigmoid和tanh。因此t时刻用户以及项目的更新函数可以表示为
(4)
(5)

2.2.2 注意力机制
在循环模型中,序列的信息需要递归的获取,以往采用双向的RNN可以更好挖掘序列信息,但忽略了序列中任意两个项目之间的交互影响(也可以叫语义信息),这种交互影响对理解用户以及项目细粒度特征是至关重要的。然而这种语义特征可以使用self-attention更好地提取。但一般的自注意力机制对序列中项目的顺序不敏感,仅是词袋模型。然而对时间序列的模型而言,顺序是一个很重要的信息,因此本文将从输入的序列向量中学习序列的位置向量
P2i(p)=sin(p/100002i/D)
(6)
P2i+1(p)= cos(p/100002i/D)
(7)
其中,D是向量的维度,p是当前项目在序列中的位置索引,Pi就是序列中的位置向量。然后将提取的位置向量与用户(项目)的序列向量进行拼接
(8)
(9)
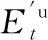
(10)
这里Zt∈RD作为自注意力机制的输出,认为是用户以及项目的近期特征,弥补RNN的不足之处。
为将LSTM和自注意力机制提取的特征信息能够有效的融合,本文尝试使用特征相加,对应元素相乘以及向量的直接拼接。在这些方式中,时序特征信息的拼接得到了更好的效果。可能的原因是其它的融合方式导致了隐特征中关键信息弱化,因而不能准确描述当前时刻用户和项目的状态。由此可知,用户以及项目t时刻的状态可以表示为
(11)
(12)

2.3 模型目标函数

(13)
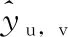

(14)
这里的Y表示明确交互的数据集,Y-是负采样本中的交互数据集,θ代表了模型的参数。模型参数使用Adam不断优化,这样可以使模型更快的收敛。
3 实 验
3.1 数据集概述
为验证本文提出模型的有效性,本文使用Movie-len100K公开数据集验证,包括943个用户,1682个项目,共100 000条有效评论数据,时间区间是1997年9月到1998年4月。在数据处理中,首先将数据集中明确的评分转化为隐反馈。其次,类似文献[7]将数据集中用户以及项目少于10次交互记录进行合理的过滤。最终,用户数943,项目1152个,有效的交互数据有97 953条。其中,每个用户最后一次交互的记录作为测试集,其余数据作为训练集。
3.2 模型设置及评估标准
对每个用户排序预测并排序所有的项目是相当耗时的,因此本文随机样本化50个用户未交互的项目,将测试数据与这50个样本共同参与排序。用户及项目的向量维度,使用均匀分布随机初始化。就用户以及项目时序特征表现的敏感性而言,用户的兴趣偏好更容易发生变化,而项目的特征演进相对缓慢。因而将每个交互记录按照发生时间的先后顺序将相关的用户以及项目划分到不同的时间粒度中,本文将用户以7天为一个时间粒度,项目以30天为一个时间粒度对当前的交互记录进行标识。针对特定时间的交互,根据用户此时的时间粒度来获取用户近期的交互序列,根据项目标识的时间粒度来获取项目近期的交互序列。
对本文提出的模型而言,使用均值为0,方差为0.01的高斯分布随机初始化模型的参数,模型的优化使用了Adam。为评估本文提出模型的性能,本文使用命中率(HR)和标准化折扣累积增益(NDCG)来评估推荐模型的表现力。HR明确表示测试项目是否出现在推荐列表中,NDCG用来计算命中项目在推荐列表中的位置。
3.3 对比方法
为了评估本文提出的推荐模型的有效性,将其与以下相关的推荐算法进行对比:
(1)贝叶斯个性化排序推荐模型(BPRMF)。采用BPR-Opt优化准则优化推荐列表。
(2)NeuMF。模型融合了多层感知机以及矩阵分解来学习用户以及项目得隐特征,并使用多层感知机替代內积过程。
(3)Caser。模型使用分层的以及垂直的卷积神经网络挖掘历史交互。
(4)循环推荐模型(RRN)。通过简单的特征融合方法融合了矩阵分解以及LSTM模拟用户以及项目的协同演进过程。
(5)注意力推荐模型(AttRec)。模型采用自注意力机制以及度量学习共同完成推荐任务。
在这些基础的算法中,BPRMF是基于传统的推荐模型。Caser、RRN和NeuMF是基于神经网络中不同网络结构的推荐算法。其中Caser是基于CNN来提取序列中的行为特征,RRN是使用LSTM获取时序特征来模拟用户以及项目的协同演进过程的,最后的AttRec模型是通过自注意力来模拟用户近期的行为表现。
3.4 对比结果及分析
模型中序列的长度l以及用户和项目的维度D对推荐的结果是有影响的,因此,本节首先对l和D的取值对模型的影响进行实验验证,在取得最优的推荐结果的基础上,与其它相关的算法进行对比。
3.4.1 序列长度l的影响
为了衡量l对模型的影响,本文将l取值为1,2,3,…9进行评估,为了消除维度对推荐结果的影响,将用户以及项目的隐向量维度分别取50、100和150进行实验,实验结果如图3和图4所示。从图3和图4可以看出随着序列长度的增加一定程度上会提高推荐的命中率,但是推荐的效果不是一直呈现上升的趋势,而是一个波动的过程。当l=8时推荐的命中率以及累计的增益总体上是最大的,当l<8时,推荐的评估指标将呈现下降趋势,主要是因为数据比较稀疏的缘故,如果将每个用户以及项目的总的交互个数提高,将会导致训练样本减少。

图3 不同序列长度l以及维度D取值对HR的影响
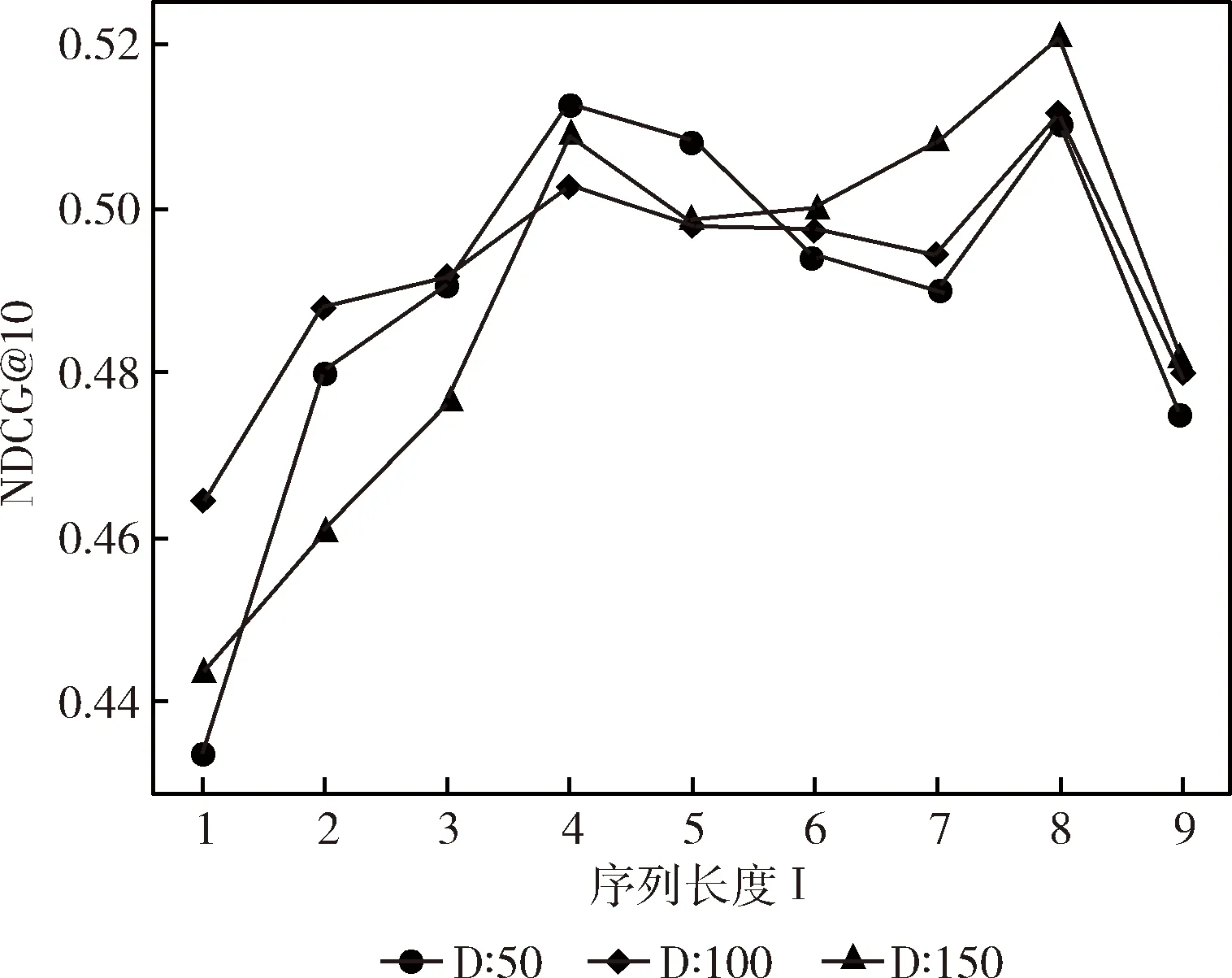
图4 不同序列长度l和维度D取值对NDCG的影响
3.4.2 维度大小的影响
图3和图4也展示了隐向量维度对推荐结果的影响,本文将D取值50、100和150进行实验,理论上增加隐向量的维度将会提高推荐的准确度,但是从图3和图4可以发现并不完全符合理论,只是在总得趋势上有一定的增长。可以看出,序列长度为8维度150时,评估指标达到了最大值,可见增加维度一定程度能够提高推荐的准确度,但也不能过大,过大将会使得模型出现过拟合的问题。
3.4.3 不同模型特征提取能力的对比
BSFRNN融合了LSTM提取的时序特征以及自注意力机制提取的语义特征。为了说明这两种信息对推荐结果的影响,给出两种BSFRNN模型变体BSFRNN-RNN和BSFRNN-SF,实验结果见表1。

表1 Movielen100K推荐性能评估
(1)没有自注意力机制的LSTM模型(BSFRNN-RNN)。仅仅使用循环神经网络描述用户以及项目近期的特征表现。
(2)没有RNN的自注意力机制(BSFRNN-SF)。使用自注意力机制描述用户以及项目的协同演进过程。
从表1中看出BSFRNN得到了更好的推荐效果,这说明将LSTM以及自注意力机制提取的序列特征进行融合是有效的。
表1中BSFRNN-SF的评估结果比BSFRNN-RNN相对好一些,主要原因是自注意力机制能够更加准确地挖掘到用户以及项目的时序隐特征。这并不能代表BSFRNN-RNN提取序列信息的能力就完全落后于BSFRNN-SF,从表1中BSFRNN模型的显示结果中可以看出,BSFRNN-RNN对进一步提升推荐的准确度有大的帮助,这就说明了BSFRNN-SF提取的序列信息并不完全包括BSFRNN-RNN提取的序列信息。
3.4.4 不同推荐算法的性能对比
表2列出了BSFRNN与其它推荐模型在top-N=5和top-N=10的推荐对比结果。从表2中可以看出BSFRNN在评估指标NDCG的取值上达到了最好的结果,也就表示BSFRNN预测用户的下一次行为的准确性更高,可将真实发生的交互项目排在推荐列表更靠前的位置。BSFRNN的高效性得益于融合了动态的和静态的特征表现,同时在学习用户以及项目动态特征表现时,精确挖掘和学习了交互序列中的时序特征和语义信息,有效提高了预测用户下一次行为的准确性。从表2可知尽管RRN在top-N=5时,HR比BPRMF相对更高些,但是NDCG的评估效果却低于BPRMF接近6%,原因是尽管RRN考虑了时间以及评分对特征动态性的影响,但是预测用户下一次行为时仅涉及前一次行为涉及的项目(用户),因此这种近期的交互之间的影响并不能有效获取到,其次模型参数共享的问题会导致一定信息的丢失。Caser相比于BSFRNN推荐结果不好的原因在于卷积神经网络在长序列问题上不如RNN,同时也在于本身序列语义信息提取能力不如自注意力机制。NeuMF虽然比BPRMF在top-N=5时的推荐效果好,但是并不是学习用户以及项目特征的时序动态性,因而其标准化折扣累积增益(NDCG)要比BPRMF低6.8%。从表2可知, AttRec的推荐效果要低于BPRMF,原因是仅使用自注意力机制提取了序列中用户的近期兴趣偏好,尽管融合了度量学习模拟的长期特征,但是却忽略了项目特征的动态性。从表2可知BSFRNN的推荐性能要明显高于BPRMF,主要原因是该模型是从矩阵分解角度完成推荐,然后使用BPR-Opt优化准则优化推荐列表,完全忽略了用户以及项目的时序动态性,因而推荐效果不明显。
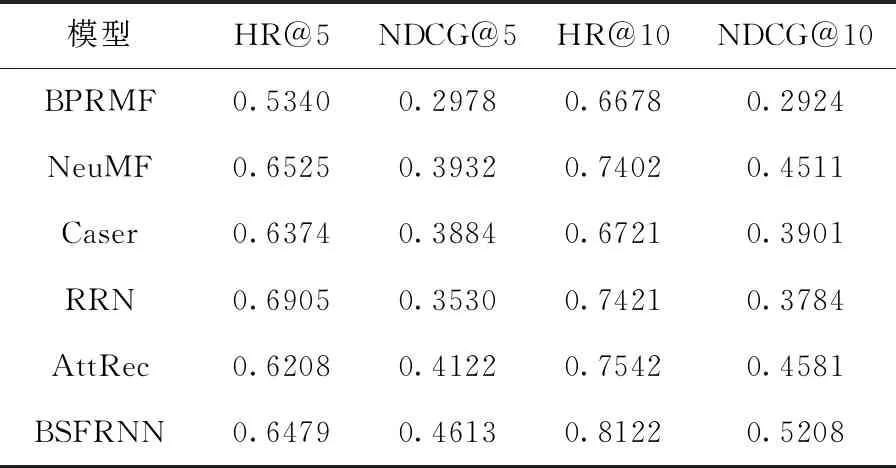
表2 不同推荐模型的性能评估
4 结束语
本文提出基于自注意力的协同演进推荐模型,模型使用两个LSTM分别表征用户以及项目的时序演进过程,其次,使用自注意力机制挖掘交互序列中的语义信息,并将其获取的语义信息有效融合到LSTM模拟的时序演进过程中。最后经上述实验验证,本文提出的BSFRNN能有效从用户和项目的时序演进过程学习到用户以及项目的时序动态性,并能准确预测用户的下一次交互。
本文提出的推荐模型经过在公开数据集上的验证,获得了较高的推荐准确性,但忽略了数据集中的辅助信息,比如评分、评论以及用户的社会关系等,这些信息将有助于准确描述用户以及项目属性。因而下一步工作将充分利用数据集中的数据,改善数据稀疏的问题并提高推荐的性能。
猜你喜欢
《学习方法报》历史中考版(2024年8期)2024-12-31 00:00:00
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中国农业信息(2021年3期)2021-11-22 06:44:48
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
传媒评论(2017年3期)2017-06-13 09:18:10
电子制作(2016年15期)2017-01-15 13:39:08
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
