
一种基于MDARNet 的低照度图像增强方法*
2021-02-25 12:16:36江泽涛覃露露秦嘉奇张少钦
软件学报 2021年12期
江泽涛,覃露露,秦嘉奇,张少钦
1(广西图像图形处理与智能处理重点实验室(桂林电子科技大学),广西 桂林 541004)
2(桂林信息科技学院,广西 桂林 541004)
3(南昌航空大学,江西 南昌 330063)
在照度低或逆光等光照环境差的情况下采集的图像,称之为低照度图像(low-light images,简称LLI),此类图像容易出现低质量现象,例如对比度低、颜色失真和细节信息模糊等.由于其低质现象,低照度图像往往会造成目标识别、检测和跟踪等计算机视觉任务算法性能的降低.低照度图像增强方法旨在通过一些技术手段和方法恢复原本低质图像的真实场景信息,以获得具有完整的结构和细节信息且视觉效果自然、清晰的图像.低照度图像增强方法主要分为传统增强方法和基于神经网络的增强方法.
传统图像增强方法可以分为以下4 类.
1) 基于直方图的增强方法.通过统计方法调整图像中的像素值,使图像直方图达到均衡状态,从而对低照度图像的亮度和对比度进行提升,如LDR[1],ERMHE[2]等.但此类方法的增强结果图中常出现难以平衡图像暗区恢复和亮区保留的问题,同时也容易出现色彩失真问题,具有较弱的鲁棒性;
2) 基于Retinex 的传统增强方法.受益于Land[3]提出的人眼视觉的亮度与色彩感知模型——Retinex 理论,众多学者在该模型的基础上提出了单尺度Retinex(SSR)、多尺度Retinex(MSR)、带颜色恢复的MSR(MSRCR)[4]、LIME[5]、RobustRetinex[6]和JED[7]等经典算法.此类传统方法能够有效增强图像亮度且较好保存如边缘和角落等高频信息,但它们无法有效避免对比度不均匀和颜色失真等问题;
3) 基于伪雾图的增强方法.Dong 等人[8]通过研究发现,低照度图像的转置图与雾霾图像的特征具有很高的相似性,由此提出对此类伪雾图应用去雾方法实现低照度增强的方法(Dehaze).此类方法只能有效改善部分图像的视觉效果,但是易产生边缘效应、光晕效应和不实际现象;
4) 基于图像融合的方法.该方法通过将多张不同照度的图像进行融合的方式提升低照度图像的质量,如Ying_CAIP[9],Ying_ICCV[10]等算法.然而此类方法通常需要采集同一场景下的不同曝光程度子图,或者通过其他技术手段获取系列子图才能实现较好的图像融合,这局限了该方法的应用.此外,该方法在对照度不均匀图像进行增强的过程中,无法有效地提升较暗区域的亮度.
随着卷积神经网络(CNN)在图像分类、目标检测、目标跟踪等计算机视觉领域取得了出色的成绩,越来越多的研究人员将CNN 运用到低照度图像增强领域.Shen 等人[11]通过结合卷积神经网络与MSR 算法,提出了MSRNet 低照度增强模型,学习暗图像到亮图像的反射分量,很好地将基于Retinex 传统方法与基于卷积神经网络的方法进行结合,增强效果显著.但MSRNet 会出现图像增强不均匀和色彩偏差的问题.Lv 等人[12]提出了一种基于深度学习的多分支微光增强网络(MBLLEN),该方法提取多个不同级别的丰富特征,通过多个子网应用增强功能,最后通过多分支融合生成输出图像.Tao 等人[13]通过卷积神经网络进行图像去噪,利用亮度通道先验实现照度增强;随后,他们又提出LLCNN[14]实现端到端的低照度图像增强网络.Wei 等人[15]通过联合生成对抗网络和图像质量评估技术,实现低照度图像增强方法.Wang 等人[16]提出了一个全局照明感知和细节保存网络(GLADNet),首先为低光输入计算全局照明估计,然后在估计的指导下调整照明,并使用与原始输入的串联来补充细节.Zhang 等人[17]受到Retinex 理论的启发,提出了一个简单而有效的网络(KinD).该方法将图像分解为两个部分:一部分(照明)负责调光,另一部分(反射)负责降解.以这种方式将原图像空间解耦为两个较小的子空间,以更好地进行正则化和学习.江泽涛等人提出一种利用改进的U-Net 生成对抗网络实现低照度图像转换为正常照度图像的网络(LLEGAN)[18];随后,该团队将低照度增强需要解决的多重失真问题转为两重增强,提出了一种多重构变分自编码器(MRVAE)[19],通过两个阶段的增强网络,分别解决多重失真.虽然上述方法都能在一定程度上解决低照度图像的低质问题,得到较好的亮度、色彩还原度,但难于在同一个网络中完全解决所有低质问题.如果仅用简单的卷积运算构建低照度图像增强模型,此时的模型是简单利用CNN 的学习能力直接学习如何将低照度图像映射正常照度图像.然而普通卷积对图像的每个像素或通道都分配以相同的学习权重,这将可能导致模型无法有针对性地实现低照度图像增强,容易出现增强图像亮度提升过于均衡、色彩失真等问题.此外,基于神经网络的方法需要大量的数据进行学习训练,因此,数据集的构建效果也同样严重影响着模型的最终增强性能.
为了解决上述问题,且有效实现低照度图像亮度的提升、对比度的增强、色彩信息的还原以及噪声的去除,本文将卷积神经网络强大的学习能力与图像构成模型Retinex理论相结合,提出了一种基于Retinex的低照度图像增强网络——MDARNet,其中,通过引入Attention 机制和密集卷积块来增强网络模型对图像特征的提取能力.首先,MDARNet 利用多尺度卷积实现对图像的初步特征提取;其次,通过密集卷积块对初步特征图进一步增强特征;然后,利用Attention 机制对特征图进行动态分配权重,实现有针对性的增强;最后,利用Retinex 理论将环境光照和噪声分量从低照度图像中除去,得到最终的增强图像.通过实验对比分析,MDARNet 与其他主流算法相比较,能够有效提升图像的亮度、对比度和色彩还原度,同时实现噪声去除.
1 相关理论
1.1 Retinex理论
Retinex 理论[8]指出,人眼视觉或摄像设备所感知的物体亮度由物体本身的反射分量和环境光照这两个因素构成,如图1 所示,其数学表达式为

其中,I(x,y)表示采集图像对应(x,y)坐标的像素,R(x,y)表示图像(x,y)坐标像素的反射分量,E(x,y)表示该位置的环境光照分量.
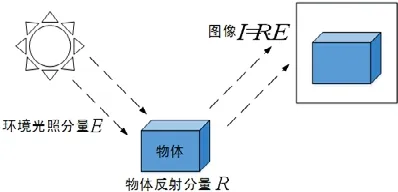
Fig.1 Form of image composition in Retinex theory图1 Retinex 理论中的图像构成形式
颜色恒常性理论指出:视觉感知到的物体颜色仅仅由物体本身的反射性能所决定,在不同波长的光线下感受到不同颜色仅仅取决于物体对该波长光的反射能力,而与该环境光无关.因此,若能够近似估计出采集图像时所处环境的光照强度分量E(x,y),我们就可以根据这一理论将环境光照对成像的影响去除,从而得到物体本身的反射分量R(x,y).为了简化计算,将公式(1)改写为

其中,log(·)表示对图像进行以自然对数或10 为底的对数运算,Ic(x,y)则表示输入图像中第c层通道图.
SSR 算法[9]是Jobson 提出的首个基于Retinex 理论的照度增强方法,该方法通过构造高斯环绕函数对环境光照分量进行估计,其数学表达式为

其中,*表示两张图像之间进行卷积运算,F(x,y)表示估计的高斯环绕函数,而F(x,y)的标准差为σ2、尺度为λ.其中,λ满足在整个概率域上的积分为1,即满足下式:

综合上述分析可知,将公式(3)的等号两边取对数后代入公式(2)汇总,即可得到SSR 算法的最终增强结果:
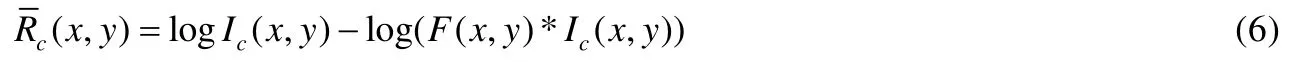

其中,N表示尺度数量,Rcn表示第n个尺度下第c层通道的SSR 估计结果图,为根据MSR 计算得到 的第c层通道的增强分量图,wn表示第n个尺度增强图在该层合成增强结果图中的合成权重.
1.2 Attention机制
注意力(attention)机制因其具有捕获长距离交互的能力被广泛应用于序列建模的计算模块,如机器翻译、自然语言处理领域[20].通俗而言,注意力机制就是对输入数据的各个部分按照其对结果的影响程度分配不同权重,然后再着重对重要部分进行特征提取.注意力机制模仿的是人类的行为惯性,无论在文字阅读还是视觉感受过程中,人们总会着重阅读或观察自己的感兴趣的部分.自注意力机制(self-attetion)是输入数据利用自身的特征,通过卷积运算等方式给自身各部分分配不同权重的机制[21].
近年来,许多学者在不同视觉任务的研究过程中引入注意力机制,以解决单一卷积存在的弱点.在计算机视觉中引入注意力机制的根本目的,是让网络学会在学习过程中给图像的不同信息分配不同的注意力,做到忽略无关信息,重点关注有用信息[22].在视觉任务中的注意力机制通常是通过使用注意力图(Attention map)的形式实现,通过构建的注意力模块学习到特征图中的关键特征,并形成Attention Map,然后再将输入的特征图与Attention Map 进行乘积运算,突出关键区域特征,完成对特征的区域关注[23].Hu 等人[24]提出了一种全新的图像识别结构SENet,该网络利用注意力机制对特征通道间的相关性进行建模,通过降低无关信息的影响和强化重要区域的特征,实现准确率的显著提升.Chen 等人[25]提出了基于通道注意的定向感知功能(SISR-CAOA)融合模块,采用通道注意力机制,自适应地将从不同通道中提取到的特征进行融合,从而实现了恢复精度和计算效率都更高的超分辨率模型.
在针对低照度图像增强的研究任务中,也有不少学者通过在CNN 增强网络中嵌入注意力机制的方式增强模型的性能.该方式促使模型更有效地处理低照度图像中多种导致图像低质的因素,包括亮度、对比度、色彩、噪声等.Wang 等人[26]在CNN 增强网络的基础上,考虑到特征通道及多层特征的重要性,构建了具有特征提取模块和特征融合模块两部分的增强网络.然而,该模型并未从像素的角度考虑图像中不同区域存在的照度、噪声不均等问题.Lv 等人[27]利用CNN 构建了两个注意力网络,分别学习获取用于引导亮度增强和去噪任务的掩膜(mask),通过mask 对亮度不均的区域和噪声分布不均的区域进行针对性的指导增强.然而,该模型在得到mask之后组建了多个分支子网络实现增强,网络结构相对庞大,且其将原本存在联系的图像亮度及噪声分开考虑的处理方式欠妥.
2 基于MDARNet 图像增强方法
2.1 基于Retinex的图像增强问题描述
为了能利用Retinex 实现低照度图像的增强,设X∈Rw×h为低照度图像,Y∈Rw×h为与之对应的正常照度图像,则根据公式(6)和公式(7)知,增强图像可表示为

当N=1 时,表示SSR 算法;当N>1 时,表示MSR 算法.若令:
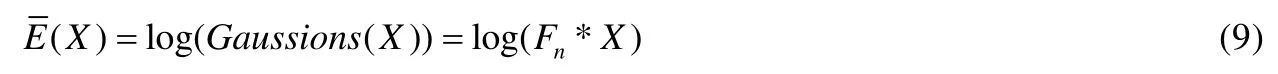
则最终增强图像可表示为
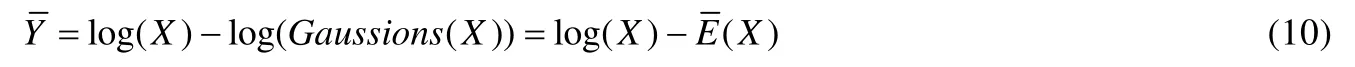
传统的Retinex 算法通常根据先验知识直接构建一个高斯环绕函数,与低照度图像X进行卷积运算后,得到 环境光照分量的估计图.然而在实际的应用中,通过先验知识进行估计运算的方法往往鲁棒性较差.因此,本文借助卷积神经网络能够很好地学习数据特征的特性,用于代替估计的传统方法[28].
2.2 MDARNET模型设计
针对上述基于Retinex 的图像增强问题,本文利用卷积神经网络对Retinex 理论中的分量进行估计.通过在网络中引入Attention 机制与DenseNet[29]模块,增强对图像有用特征的提取和降低干扰特征的影响.提出一种基于Retinex 与Attention 相结合的低照度图像增强网络——MDARNet(multiscale dense Attention Retinex network),该网络能够有效地对低照度图像的亮度、对比度以及色彩实现增强,当图像存在噪声时,同样能进行有效的降噪.MDARNet 的网络结构如图2 所示.
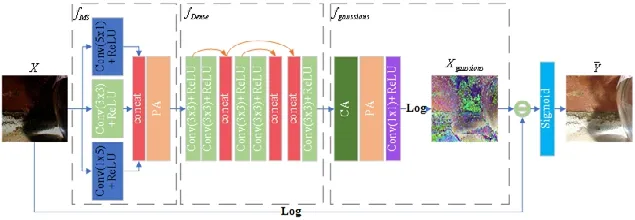
Fig.2 Network structure of low illumination image enhancement method based on Retinex and Attention图2 基于Retinex 与Attention 的低照度图像增强方法的网络结构
MDARNet 模型分为fMS,fDense,fgaussions这3 个子模块,分别进行多尺度特征提取、密集特征提取、环境光照与噪声分量估计.
首先,fMS通过将多个不同尺寸和形状的卷积核直接用于对原始输入的低照度图像进行多尺度特征提取,并将得到的多尺度特征进行连接;接着,利用像素注意模块(pixel-wise Attention,简称PA)进行特征筛选,得到初步图像特征fMS(X);其次,fDense利用多个跳跃连接对fMS(X)做进一步的特征提取,并将不同阶段输出的特征进行连接和通道压缩,得到特征图fDense(fMS(X));然后,通过构建的通道注意模块(channel-wise Attention,简称CA)和像素注意模块对特征进行筛选,再通过一个1×1 卷积将多通道特征图进行通道压缩,随后进行对数运算即可得到输 入图像的环境光照与噪声分量;最后,根据公式(10)计算得到增强结果图.
2.2.1 非对称卷积
Ding 等人[30]证明了:采用非对称卷积可以显著增强标准方形卷积核的表示能力,并且可以有效减小运算的复杂度.因此,本文采用如图3 所示的非对称卷积方式代替部分的普通卷积.MDARNet 将一个非线性映射(nonlinear mapping,简称NLM)运算H(·)定义为一个卷积运算和一个ReLU激活函数的组合,为了能够最大限度地保留图像的信息,本文均不采用批量归一化,即:

其中,W,b 分别表示该非线性映射层的权重与偏置,k×k表示卷积核的尺寸.由此,非对称卷积AConv(·)可表示为
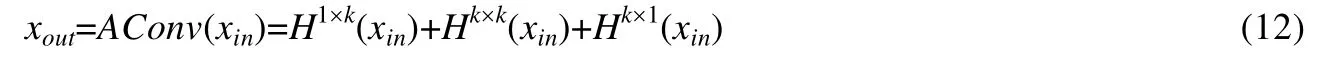
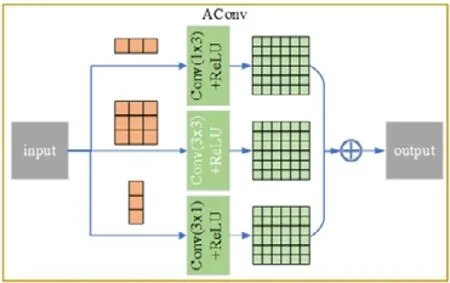
Fig.3 Asymmetric convolution AConv structure diagram图3 非对称卷积AConv 结构示意图
2.2.2 特征注意力机制
在绝大多数低照度图像增强网络中,将图像或提取到的特征图中每一个通道或像素对最终增强结果的贡献都视为是平均的.为了避免在低照度图像增强过程中常出现的局部亮度增强不足或过度增强、色彩失真、噪声放大等现象,本文通过增加基于像素和通道的两种注意力模块,分别对不同图像的特征情况给不同的像素区域或特征通道分配不同的学习权重,从而使得模型能够灵活的对特征进行取舍,避免上述失真问题.
1) 像素注意模块(PA)
像素注意模块是指对不同的像素点赋予不同的学习权重,从而使网络能够有针对性地应对低照度图像中光照不均匀及存在噪声的问题.如图4 的Pixel Attention-AConv 所示,PA 模块首先利用两个AConv对图像进行特征学习,然后利用一个Sigmoid激活函数将结果映射到(0,1),由此得到与输入尺寸相同的权重图(PAMap):

其中,S(·)表示Sigmoid函数.最后,将得到的PAMap与输入xin进行元素相乘,即可得到像素注意模块的输出为:


Fig.4 Characteristic attention mechanism network structure diagram图4 特征注意力机制的网络结构图
2) 通道注意模块(CA)
在提取到的特征图中,每张特征图所提取到的特征不尽相同,且所提取到的特征不一定都有利于进行照度增强.因此,本文引入了通道注意模块,其目的是通过学习给不同的特征图赋予合适的权重,从而提升具有明显特征的特征图所占的比例,降低对噪声等特征的学习.CA 结构如图4 的Channels Attention-AConv 所示.
首先,CA 对输入H×W×C大小的xin进行全局平均池化,实现对每一层通道的空间信息压缩,从而得到一个1×1×C向量vector:

然后,利用两个AConv对向量进行权重学习,同样采用Sigmoid激活函数将结果映射到(0,1),得到权重向量(CAVector):
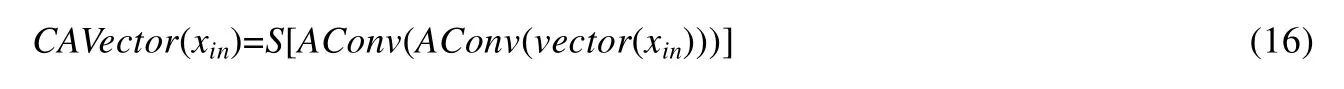
最后,将得到的基于通道的权重向量与输入xin的各个通道层进行相乘,即可得到通道注意结果为

2.2.3 多尺度特征提取模块
由于卷积操作的感受野有限,因此,采用固定尺度大小的单个卷积核对图像进行特征提取也局限了特征提取的结果.为了能够更好地提取到图像的特征,本文采用3 个不同尺度的卷积核分别对图像进行特征提取,然后将多个尺度的卷积结果进行通道拼接,如图2 的fMS所示.本文利用非对称卷积的优点,将多尺度卷积设计为二维的方块形卷积与一维的卷积相结合的形式,实现对图像的多维特征提取.由于此模块对原始图像进行初步特征提取,因此一维卷积采用大尺寸的卷积核,即,此处多尺度卷积核大小分别为一个3×3,一个1×5 和一个5×1.其次,为了能够最大限度地利用提取到的特征,此处将3 个不同尺度提取到的特征图进行通道连接:
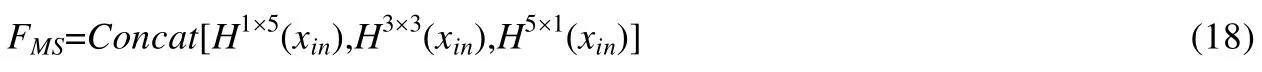
然后,利用像素注意模块对该多尺度特征图FMS进行加权学习,由此获得多尺度特征提取模块的输出结果XMS可表示为

2.2.4 密集特征提取模块
密集卷积神经网络(DenseNet)是Huang 等人[28]为了克服随着CNN 深度的增加而出现梯度弥散的问题而提出的一种网络结构,它确保了网络中各层之间的最大信息流,且能够有效缓解梯度消失问题、增强特征传播,大大减少了参数量,同时能够增强网络的泛化能力.本文设计的密集跳跃结构设计如图2 中的fDense模块所示,实现在多尺度特征提取模块的结果提取到更丰富、更高阶的特征,为后续的环境光照与噪声分量估计奠定特征基础.首先,为了更好地定义密集特征提取模块,将跳跃卷积单元(skip conv unit,简称SConv)定义为两个非线性运算和一个拼接层:

然后,fDense由N个跳跃卷积单元构成,且所有的跳跃卷积单元输出结果将被连接在一起,即:

其中,SConvi表示第i个跳跃卷积单元的输出结果.最后,用一个非线性映射对进行降维,得到密集特征提取模块fDense的输出结果:

公式(22)输出的结果XDense通过密集卷积进一步提取特征之后,具有比XMS更加丰富的特征.
2.2.5 环境光照与噪声分量估计模块
在密集特征提取结果XDense上,环境光照估计模块先通过一个通道注意模块和像素注意模块对特征图进行权重学习.通过基于通道注意力和像素注意力的结合,实现对特征图中不同通道和不同像素区域的关注学习,能够有效提取特征中的环境光照和噪声信息.然后,利用1×1 非线性映射对特征进行降维,得到三通道特征图后进行取对数运算,得到输入图像X的环境光照与噪声的估计为

由此,根据公式(23)可以得到环境光照与噪声信息的估计图.最后,结合公式(10)和公式(23)即可得到增强结果图.但为了避免在网络传播过程中出现像素点的值超出(0,1)范围,本文在输出结果图之前,使用Sigmoid函数进行像素值的映射,即:

2.3 MDARNet的损失函数
MDARNet 网络模型的训练目的是,将输入低照度图像X送入网络得到照度增强图像与对应的正常照度图像Y尽可能接近.目前,机器视觉任务中用于度量图像对应像素点之间差异的损失函数中,运用较为广泛的有均方误差(mean square error,简称MSE)损失函数和平均绝对误差(mean absolute error,简称MAE)损失函数:

其中,p表示像素点索引,P 则表示整张图像切片,N表示图像切片中像素总数,而分别表示正常照度图像Y和网络输出的照度增强图像在像素点p的值.虽然LMSE能够很好地度量两张图像像素之间的差距,但是LMAE能够更准确地反映实际预测误差的大小.在图像增强方面,由于LMAE不会过度惩罚图像的差距,因此在对比度、亮度方面效果要优于LMSE.
虽然直接使用LMSE或LMAE度量与Y之间差异的计算很简单方便,但是它并不符合人眼视觉的主观感受,因此,有学者提出将基于人眼视觉系统启发的结构相似度(structural similarity,简称SSIM)评价标准作为损失函数.像素级的SSIM数学表达式为
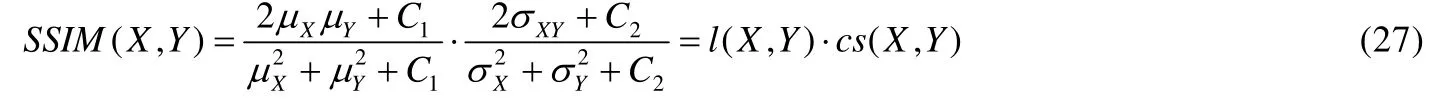
其中:μX,μY分别表示图像X与图像Y的像素平均值;则分别对应于图像的方差;σXY为两幅图像的协方差;C1=(k1L)2和C2=(k2L)2是两个用于维持函数稳定的常数,能够防止分母出现0 的情况,其中,L为像素值的动态范围,且k1=0.01,k2=0.03.
由此,基于SSIM 构建的损失函数可定义为

而根据卷积神经网络的性质,本文将上式改写为

由于SSIM 对图像质量的度量结合了图像结构失真与人眼感知两个方面,因此,基于SSIM 的损失函数的引入,能够更好地恢复图像的结构与细节.但是由于SSIM 对均值的偏差不敏感,因此得到的增强图像亮度与颜色的变换在视觉效果上偏暗.
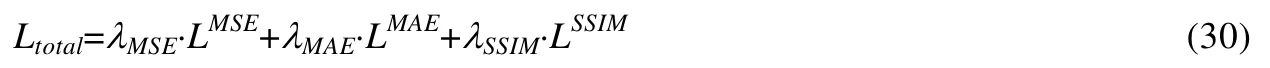
其中,λMSE,λMAE和λSSIM表示用于调整LMSE,LMAE与LSSIM损失权重的参数.采用不同训练的数据集不同时,可能会影响λMSE,λMAE和λSSIM的取值,但是其取值是平衡不同部分损失函数的量级和收敛速度,一般来说,先使用超参调整损失到同一量级,而本文的取值为λMSE=1,λMAE=2 和λSSIM=2.
2.4 伽马校正与Retinex理论构建数据集
无论是简单的线性降低图像亮度,还是单一的非线性伽马校正调整图像的亮度,都无法很好地模拟真实低照度图像的低亮度、低对比度.文献[27]对不同曝光程度的图像进行研究,提出将线性变换与伽马变换同时应用于合成亮度、对比度更逼近于真实低照度图像的合成图像,其数学表达式为
其中,α和β用于对图像进行线性变换,Iγ表示对图像I进行伽马变换,且这3 个参数服从均匀分布:α~U(0.9,1.0),β~U(0.5,1.0),γ~U(1.5,5.0).此外,本文分别通过对图像进行高斯模糊、添加噪声和伽马校正的方法来模拟真实低照度图像的特性,可表示为

其中,BG(μB,σB)表示用于模糊图像的高斯滤波器,NG(μN,σN)表示向图像中添加噪声的高斯函数.上述两个高斯函数的参数取值为:μB=0,σB~(0.8,1.6),μN=0,σN~(0,20).
综上,为了能够合成“低照度-正常照度图像”数据集,本文首先采用公式(31)实现低照度图像的亮度、对比度合成,然后采用公式(32)对图像进行高斯模糊和添加高斯模糊,实现对低照度图像出现模糊和存在噪声问题的仿真,合成过程如图5 所示.

Fig.5 Synthesizing process of synthesizing low-illuminance image data sets图5 合成低照度图像数据集的合成过程
为了更直观地显示合成数据集的合成效果,将正常照度图像与合成低照度图像在YCbCr 中的Y通道进行主观视觉效果比较并显示其直方图信息,如图6 所示.

Fig.6 Visual comparison and histogram of Y channel in normal illumination image and synthesized low illumination image in YCbCr图6 正常照度图像与合成低照度图像在YCbCr 中Y 通道的视觉比较和直方图
为了使模型学习到更好的图像增强效果,需保证训练图像的正常照度图像的质量.因此,本文从MSCOCO数据集和NIR-RGB 数据集中选取了1 800 张具有适当的亮度、丰富的色彩、细节丰富清晰的图像,将其中的 1 400 张图像用于合成训练集,余下400 张则用于合成测试集.针对训练集图像进行40 次随机切片为128×128大小的图像切片,构建包含56 000 对图像的训练集(GLN-trian).此外,为了使图像增强过程中能够得到更好的色彩还原,本文在训练集中增加16 对纯黑到纯黑、纯白到纯白的特殊图像对.而针对训练集进行一次随机切片出512×512 的图像切片,构建包含400 对的测试集(GLN-test).
3 实验结果及分析
3.1 实验参数设置
本文模型使用Tensorflow 框架实现,并在Windows10+NVIDIA GTX 960 GPU 的计算机上对网络模型进行训练.训练网络模型的实验将BatchSize 设为16,一共迭代10 个epoch,并在训练过程使用学习率为10-4的Adam优化器对训练过程进行参数优化.
3.2 网络结构评估
为了验证多尺度特征提取(MS)、跳跃连接结构(Dense)、光照与噪声分量的估计(Gaussions)及注意力机制(Att)的应用是否能够有利于提升图像增强结果,本文设计了多个不同的模型,分别对MS 和Dense 模块的设计单元进行评估实验,如图7 所示,对比模型在某些模块的不同设计以进行消融实验.用于对比评估的模型中,除图7所示的模块不同外,其余部分的模型设计和实验设置不变.这些模型训练后,对测试集(GLN-test)进行测试,得到的客观评价指标结果见表1,其中,MDARNet w/o PACA 表示在MDARNet 模型中去掉所有注意力机制.

Fig.7 Multi-scale feature extraction and evaluation model of jump connection structure图7 多尺度特征提取和跳跃连接结构的评估模型
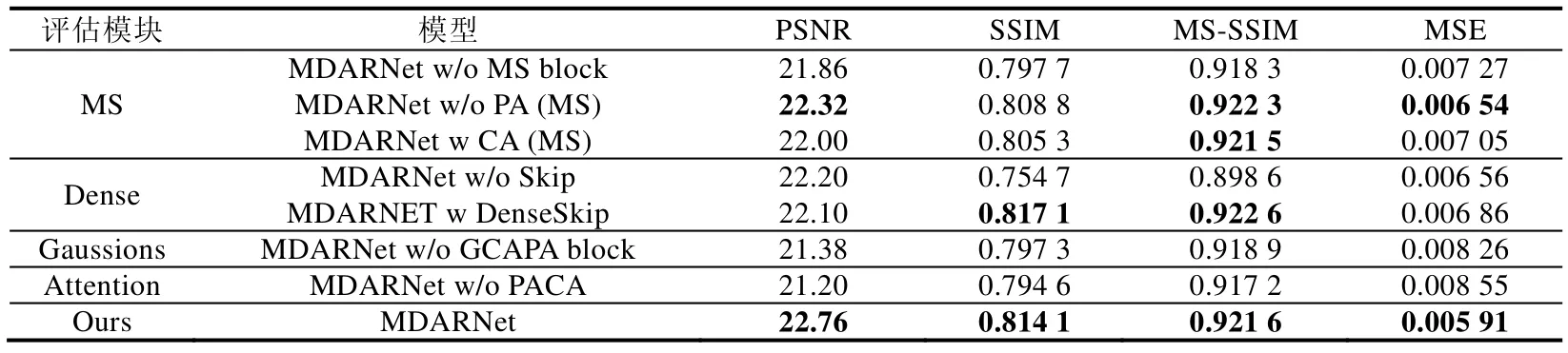
Tabel 1 Objective evaluation indicators of different network structure enhancement effects表1 不同网络结构增强效果的客观评价指标
如表1 结果显示:当对MS 模块评价时,无论是去除MS 模块、去除MS 中的PC 单元还是在MS 模块的基础上增加CA 单元,都降低了增强图像的PSNR,SSIM,MSE 指标.对Dense 模块评估时,通过去除跳跃连接(w/o skip)和增强跳跃连接构建两种对比模型与本文的跳跃设计进行性能对比分析,可以看出,没有跳跃连接的增强结果在各项评价指标得分上均差于MDARNet.虽然增加密集的跳跃连接的方式能够得到更高的SSIM 和MS- SSIM 值,但其PSNR 和MSE 的得分明显差于MDARNet,此外还增加了计算消耗.在Gaussions 模块的消融实验中可以看出:像素注意力和通道注意力的应用能够更有利于对图像环境光照和噪声分量的估计,能有效提升增强结果图的各项评价指标.通过对整个网络的注意力机制单元进行消融实验发现:注意力机制能够弥补简单卷积运算的缺陷,从而显著提升增强图像的质量.
3.3 联合损失函数评估
通过多组实验对联合损失函数的组合方式进行对比分析,实验结果见表2.
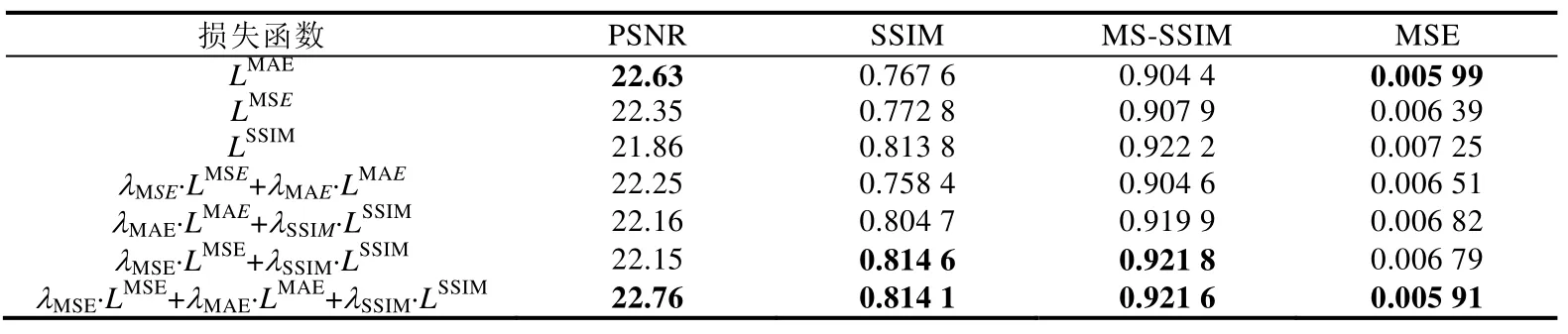
Tabel 2 Objective evaluation indexes of different joint loss function enhancement effects表2 不同联合损失函数增强效果的客观评价指标
可以看出:当只采用LMSE或LMAE时,可以得到很高的PSNR和MSE 值,但是SSIM 和MS-SSIM 值较低;而只采用LSSIM时,得到的评价指标则正好相反.此外,无论是LMSE,LMAE和LSSIM的哪两种损失函数的两两组合,得到的增强结果都比三者的组合效果差.虽然λMSE·LMSE+λSSIM·LSSIM的组合在 SSIM 和 MS-SSIM 的得分与λMSE·LMSE+λMAE·LMAE+λSSIM·LSSIM存在可忽略的差异,但在 PSNR 和 MSE 指标上的测试结果要明显比λMSE·LMSE+λMAE·LMAE+λSSIM·LSSIM的效果差.
3.4 不同照度增强方法评估
为了验证MDARNet 能够有效实现低照度图像增强,本文分别对通过合成低照度图像测试集和真实低照度图像测试集进行测试实验和对比分析.实验通过与一些流行低照度图像增强算法进行增强对比,包括非基于学习的LDR[1],LIME[5],RobustRetinex[6],JED[7],Dehaze[8],Ying-CAIP[9],Ying-ICCV[10]方法,基于学习的MSRNet[11],MBLLEN[12],LLCNN[13],GLADNet[16],KinD[17],LLEGAN[18]和MRVAE[19]方法.上述所有基于学习的增强方法均采用同MDARNet 相同的数据集和实验设置进行训练和测试.
3.4.1 合成低照度图像测试集增强结果对比
采用第2.4 节的合成低照度图像测试集(GLN-test)进行验证实验,其增强结果如图8 和表3 所示,表中数据为400 对测试结果的平均值.

Fig.8 Test result graph of the learning-based enhanced algorithm on GLN-test图8 基于学习的增强算法在GLN-test 上的测试结果图
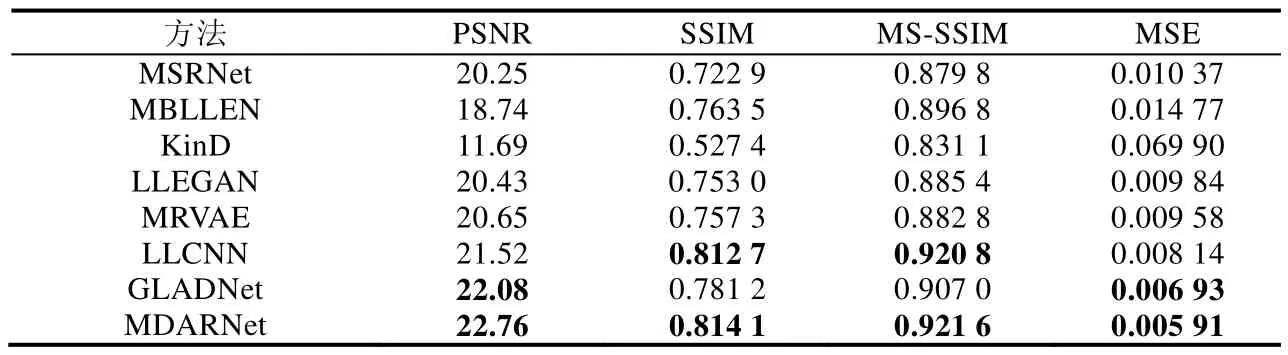
Tabel 3 Objective evaluation indexes of different methods in synthetic test set表3 不同方法在合成测试集的客观评价指标
从图8、表3 的结果可以看出:每一种照度增强方法均能对低照度图像实现照度上的增强,但也都分别存在不足之处.从细节图像可以看出,MSRNet,MRVAE,LLEGAN 和GLADNet 方法的增强效果存在不同程度的降噪效果差的问题.由于原始模型没有考虑图像的噪声问题,因此MSRNet 的去噪效果最差;此外,增强的图像细节不够清晰、出现图像整体泛黄的色彩失衡问题.虽然KinD 能够有效去噪,但是照度提升有限,故其各项客观评价指标也最差.MBLLEN 方法的细节与色彩信息恢复较KinD 更好,但是仍然欠佳.LLEGAN 和MRVAE 方法的噪声较少,但背景的还原效果与真实情况存在偏差,且客观评价得分较低.LLCNN,GLADNet 和MDARNet 在该测试集中的还原效果比较接近,且与对应的真实图像在视觉效果相差无几.但是MDARNet 在各项客观评价指标的得分均优于LLCNN,GLADNet,说明在客观评价方面,MDARNet 的增强结果更加接近于原始正常照度图像.综上所述,在相同的条件下,MDARNet 的增强结果相较于这几种增强方法,能得到更好增强图像.
3.4.2 真实低照度图像增强结果对比
为了进一步验证MDARNet 对真实低照度图像的增强效果,本文从图像数据库DICM[31],TID2013[32],VV[33],RGB-NIR[34],ExDark[35]中选取多张经典图像进行增强测试,其增强结果分别对应图9~图13.

Fig.9 Subjective visual contrast effect of different algorithms on DICM data set图9 不同算法在DICM 数据集上的主观视觉对比效果

Fig.10 Subjective visual contrast effect of different algorithms on TID2013 data set图10 不同算法在TID2013 数据集上的主观视觉对比效果

Fig.11 Subjective visual contrast effect of different algorithms on VV data set图11 不同算法在VV 数据集上的主观视觉对比效果

Fig.12 Subjective visual contrast effect of different algorithms on RGB-NIR data set图12 不同算法在RGB-NIR 数据集上的主观视觉对比效果
从图中对比结果可以看出,LDR 方法的增强效果较差,不仅亮度得不到明显的增强,而且图像细节丢失、色彩还原度差.LIME 方法的增强效果图在亮度、对比度方面表现很好,但是存在色彩增强过于鲜艳,且还原细节不够清晰的问题.Dehaze 方法会出现亮度不足,尤其是光照不均的图像中的逆光区域无法得到有效的亮度提升,但是Dehaze 在针对平均亮度较暗的图像进行增强时能得到较好的对比度.RobustRetinex 和JED 方法均有相近的增强性能,虽然亮度、对比度得到了一定在增强,但是色彩还原度出现比LIME 更严重的过度增强.Ying-CAIP增强的亮度不足,且细节还原度不够.Ying-ICCV 的增强结果是非学习类方法中性能最佳的,其增强结果图的亮度、对比度和色彩均从视觉效果上有很好的效果,但是在对亮度较低的超低照度图像的增强时,存在亮度增强不足的情况.从图中可以发现:传统方法的增强结果图在对比度方面均优于基于学习的方法,且在对逆光图像进行增强时,传统方法不会破坏图像背景的亮度、色彩等信息,如图9 和图11 的天空,但是传统方法增强的整体图像亮度低于基于神经网络的方法.
在基于神经网络的方法中,KinD 方法的增强结果图亮度增强效果最差,但其对比度较好,且在天空等区域的恢复与传统方法更接近.MSRNet 的增强效果图像亮度增强较好,但细节较模糊,且出现了色彩失真.MRVAE增强的亮度和细节较好,但存在对比度不足、噪声放大和伪影等现象,如图11 的人脸和图13 的房子.MBLLEN,LLCNN,GLADNet 方法的增强结果都较好,能够很好地提升图像的亮度、对比度和还原图像细节信息.但是MBLLEN 的增强结果亮度比MDARNet 低,且从图10 的细节图和图11 的天空看,色彩不够鲜艳;LLCNN 在逆光图像的亮光区域增强时色彩丢失更严重,且对比度欠佳于MDARNet 方法;而从图9 和图10 的细节图可以看出:GLADNet 在细节的亮度增强方面欠佳于MDARNet,且图11 中,GLADNet 的增强结果图的手臂上出现了伪影.LLEGAN 方法的增强结果图整体对比度较低,且在图13 的天空出现伪影.经过多组测试图像的对比分析可知:从整体图像的亮度、对比度、色彩、图像细节等多方面衡量,MDARNet 得到了比其他方法更好的增强效果.
4 结 论
针对低照度增强中亮度、色彩及噪声的增强问题,本文结合卷积神经网络、Retinex 理论、Attention 机制和密集卷积块,提出了一种基于Retinex 和Attention 的低照度图像增强网络——MDARNet.首先,MDARNet 利用非对称卷积和像素注意力模块对图像进行的多尺度卷积和特征融合得到多维度特征图,随后利用密集卷积块对特征图进一步提取特征,然后利用注意力机制在通道和空间维度上独立地完善卷积特征,最后根据Retinex理论将估计到的环境光照和噪声分量从低照度图像中减去,由此得到增强结果图.实验结果表明:MDARNet 能够有效地提升低照度图像的亮度、对比度,并得到与真实图像更接近的色彩增强和噪声抑制效果.从视觉主观效果和多项客观指标的结果可以看出,MDARNet 方法的增强效果优于一些主流经典的低照度图像增强算法.
猜你喜欢
燃气涡轮试验与研究(2021年6期)2021-08-01 03:09:10
海洋信息技术与应用(2020年4期)2021-01-18 06:21:36
中国生物医学工程学报(2019年5期)2019-07-16 07:56:50
光源与照明(2019年4期)2019-05-20 09:18:24
摄影之友(影像视觉)(2019年3期)2019-03-30 01:36:56
电子测试(2018年9期)2018-06-26 06:45:40
北京航空航天大学学报(2017年3期)2017-11-23 05:14:58
小天使·六年级语数英综合(2017年5期)2017-05-27 20:14:50
现代工业经济和信息化(2016年19期)2016-05-17 05:38:10
公民与法治(2016年23期)2016-05-17 04:21:08
