
一种基于CABAC的HEVC信息隐藏算法
2021-02-25 08:51:48王子晔封化民黄啸晨鱼海洋
计算机应用与软件 2021年2期
王子晔 封化民 刘 飚 黄啸晨 鱼海洋 葛 鸽
1(西安电子科技大学通信工程学院 陕西 西安 710071)2(北京电子科技学院 北京 100070)
0 引 言
信息隐藏技术是指利用人类感知及数字媒体的冗余,将特定的秘密信息嵌入到指定的文本、图像、音频或视频等数字化载体中。视频资源是现今网络上较为常见的一种多媒体资源,相比于图像音频等信息载体不但自身数据量大,而且具有更多的信息冗余。利用视频作为信息隐藏载体数据可以实现较大的信息隐藏容量。随着当下视频编码技术日益革新,处理高清乃至超清分辨率视频的需求日益增加,适用于处理高清视频的高效率视频编码(H.265/HEVC)成为了当下研究热点。与此同时,基于H.265/HEVC视频信息隐藏技术具有极大的开发价值,国内外研究学者也相继提出基于H.265/HEVC的视频信息隐藏算法。
根据视频编码的阶段,现有基于H.265/HEVC视频信息隐藏算法主要分为三类:(1) 基于预测阶段的信息隐藏,其中包括帧内预测和帧间预测,通过调整在预测过程中的相关参数可以完成秘密信息的嵌入;(2) 为基于变换与量化过程的信息隐藏,通过改变量化系数或整数变换后的DCT系数进行信息隐藏;(3) 基于熵编码的信息隐藏,利用熵编码的性质进行信息隐藏。
在基于帧内预测的信息隐藏算法中,王家骥等[1]在总结H.264/AVC中基于帧内预测的信息隐藏算法的基础上,选取纹理复杂度较高的4×4亮度块作为嵌入区域,建立拉格朗日率失真模型,选取对应的帧内编码模式进行嵌入,算法对视频质量影响较小。陈甬娜等[2]将相邻的一对4×4编码单元的预测模式编成一组,并改进菱形编码算法,将其应用于模式调制和信息嵌入,算法在视频码率上升不明显的情况下,较大地提升了嵌入容量。在基于帧间预测的信息隐藏算法中,李松斌等[3]结合HEVC编码标准的特点,针对运动向量集合与对应空间中点的性质关系,建立映射,在此基础上通过修改映射值完成信息隐藏,算法具有较高的嵌入率。Van等[4]通过修改运动向量差(MVD)和变换系数的语法元素进行秘密信息的嵌入,算法具有低复杂度的优点。
在基于变换量化的信息隐藏算法中,Swati等[5]通过修改量化变换系数(QTC)进行隐秘信息的嵌入,算法对视频质量影响较小但未考虑鲁棒性问题。Elrowayati等[6]提出了一种基于BCH校正码技术的信息隐藏技术,并选择量化DCT/DST系数作为嵌入目标,算法具有较高的鲁棒性。
在基于熵编码的信息隐藏算法中,Jiang等[7]选择基于上下文的自适应二进制算术编码(CABAC)中二进制化后的运动向量差语法元素作为嵌入目标,将信息嵌入到编码末位中,信息嵌入没有使编码视频产生比特率变化,但算法嵌入效率较低。此外,还有一些基于H.264/AVC编码标准的熵编码信息隐藏算法。Zou等[8]同样选择CABAC中二进制化后的MVD语法元素作为嵌入载体。Xu等[9]选择基于上下文的可变长度编码(CAVLC)作为嵌入目标,通过调制拖尾系数完成信息嵌入,但算法对视频质量影响较大。
在上述算法的基础上,本文提出一种基于CABAC的HEVC信息隐藏算法,通过分析熵编码过程中指数哥伦布编码后缀与语法元素值的相关性,阐述使用指数哥伦布编码后缀作为信息嵌入载体的可行性,并选择语法元素abs_mvd_minus2经过一阶指数哥伦布编码产生的后缀作为嵌入载体,结合矩阵编码修改后缀值完成秘密信息的嵌入。实验结果表明,算法对信息嵌入后视频编码重建图像的主客观质量基本没有影响,在减少了载体修改量的同时,得到了较大的嵌入容量和较高的嵌入效率。
1 CABAC
熵编码是一种利用信源随机过程统计特性的无损压缩编码方式,其位于编码过程的最后一步,将视频编码过程中的语法元素映射成二进制形式写入比特流中。H.264/AVC采用基于上下文的可变长度编码和CABAC两种熵编码方法,而H.265/HEVC采用唯一熵编码方法CABAC[10]。相较于H.264编码标准,H.265中的CABAC在部分技术上进行了改进,总体架构并没有变化。CABAC编码流程主要分为三步:语法元素二进制化、上下文建模与概率的自适应更新和二进制算术编码。
1.1 语法元素二进制化
二进制化是指将预测、变换、量化阶段产生的一系列语法元素映射为二进制符号(bin)。与H.264相似,H.265中采用一元码(U)、截断一元码(TR)、K阶指数哥伦布编码(EGK)和定长码(FL)这几种编码方式完成语法元素的二进制过程,具体取决于语法元素的类型和概率分布的特征[11]。实际编码过程中,大部分语法元素的值为二进制,不需要经过二进制化的步骤便可直接进行算术编码。
1.2 上下文建模与概率的自适应更新
上下文建模为二进制化后的语法元素值的每一个bin提供条件概率分布的估计[12],并通过之前处理的二进制符号集合进行概率模型的自适应更新。上下文建模涉及到两个主要参数:MPS(最大概率符号)和δ(概率的状态索引)。通过变量MPS和δ的值可以确定上下文模型的状态以及更新方式。
1.3 二进制算术编码
算数编码是一种基于区间的递归划分的熵编码方法[13]。首先将输入符号映射到[0,1)区间,再根据符号概率划分两个子区间并根据输入符号选取其中一个,不断递归得到小区间,最后选取区间内任意小数作为最终的编码输出。在二进制算术编码中,输入符号仅有0和1两种。在CABAC编码过程中,根据编码概率可将编码分为两类:常规编码(概率由上下文模型得到),旁路编码(等概率二进制算术编码)。
2 基于CABAC的信息隐藏算法
2.1 嵌入区域和载体的选择
在常规编码中,算术编码的编码概率通过语法元素的上下文建模得到,并根据实际编码值进行更新。上下文概率模型在影响二进制化后的语法元素的每个bin的同时,也会由于bin的改变而进行自适应更新。通过修改或插入bin值进行信息隐藏会对同种语法元素编码过程产生较大的影响[14]。因此难以通过修改常规编码中的二进制化后的语法元素值完成信息隐藏。而在旁路编码中,算术编码并未使用上下文模型与概率的自适应更新,所有bin均以0.5的概率进行编码,二进制化后的语法元素相互之间不会产生影响,因此可以选择使用旁路编码的语法元素完成信息嵌入。根据H.265标准[15],MVD的语法元素由前缀和后缀级联而成,其后缀即MVD值大于等于2的部分用语法元素abs_mvd_minus2表示,采用旁路编码模式完成熵编码。文献[7]指出,除了运动向量残差的后缀值以外,大部分可修改的语法元素为flag类,用于表示编码过程中的各类编码标志,强行修改会导致解码器无法正常解码。因此本文参照文献[7],选择二进制化的MVD后缀(abs_mvd_minus2)作为嵌入区域。
语法元素abs_mvd_minus2采用1阶指数哥伦布编码(EG1)完成二进制化。指数哥伦布编码分为前缀和后缀,在H.265中,阶数大于0的指数哥伦布编码结构为[M个1][0][INFO],其中:
(1)
INFO=X+2K(1-2M)
(2)
编码长度:
CODELEN=2M+K+1
(3)
后缀长度:
INFOLEN=M+K
(4)
式中:X表示非二进制无符号整数值;K表示哥伦布编码的阶数。
abs_mvd_minus2二进制化后的编码值如表1所示,括号内为EG1编码的后缀INFO。由式(1)、式(2)、式(4)可知,在编码阶数K固定的情况下,INFO值仅与语法元素数值X的大小有关,但前缀M的编码长度会影响后缀INFO的长度。因此,在保持INFO比特位数不变的情况下,通过修改INFO值进行秘密信息的嵌入,在解码时只会使解析出的语法元素的数值大小产生变化,不会产生EG1编码前缀M与后缀INFO长度不对应的情况,语法元素依旧可以被成功解析。与此同时,由于语法元素abs_mvd_minus2后续采用旁路编码,每个二进制符号以0.5的概率进行独立编码,不采用上下文模型进行概率更新,对其中单个EG1编码进行修改不会影响其他语法元素的编解码过程。相对于传统算法选择的编码末位[7],EG1编码的后缀位具有更大的嵌入容量。因此本文算法选择语法元素abs_mvd_minus2经过EG1编码后的后缀INFO作为嵌入载体,通过对INFO进行比特位替换修改嵌入完成信息隐藏。
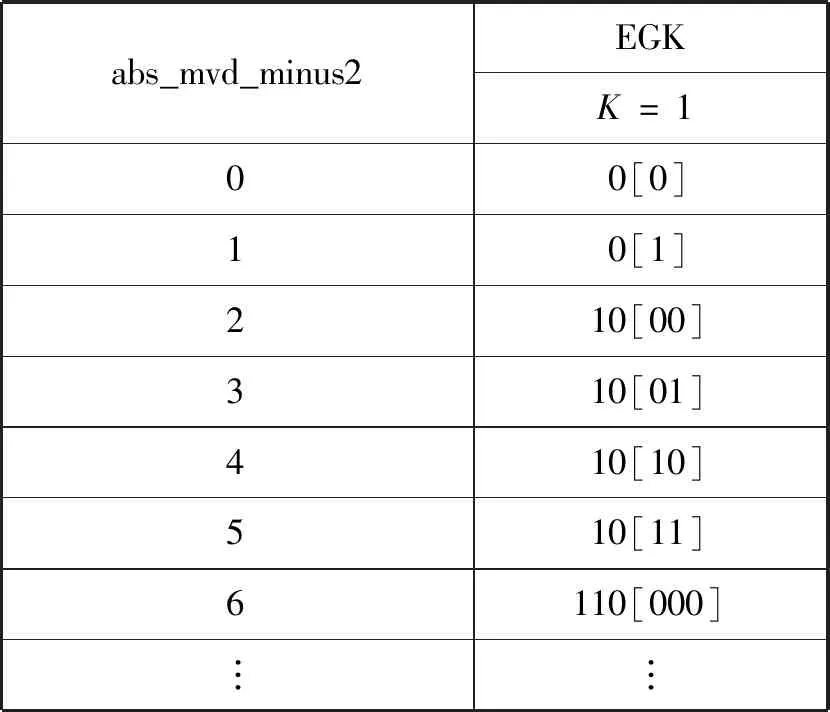
表1 语法元素值及其EGK编码值
2.2 矩阵编码
矩阵编码因为其较高的嵌入效率和较大的嵌入容量,在信息隐藏领域得到广泛应用。文献[16]首先提出矩阵编码的概念,文献[17]改进了矩阵编码并应用于离散余弦变换(DCT)后的交流系数中,通过修改编码末位完成多位比特的信息嵌入,相较于同类实验显著提升了秘密信息的嵌入数量,并减少了载体修改量。矩阵编码表现为元组(dmax,n,k),n=2k-1,意义为通过修改n比特载体信息中的dmax比特,完成最多k比特信息的嵌入。α=a1a2…an和β=b1b2…bk分别表示嵌入载体与待嵌入的秘密信息,具体嵌入步骤如下:
(1) 计算散列值:
(5)
(2) 计算嵌入位置:
s=f(α)⊕β
(6)
(3) 修改嵌入载体:
(7)
本文算法选择语法元素abs_mvd_minus2经过EG1编码产生的后缀INFO作为嵌入载体,结合F5矩阵编码方法,使用元组(dmax,n,k)=(1,3,2),通过修改载体信息中3比特位中的1位,完成2个比特的信息嵌入,在保证了嵌入容量的同时,减少了对载体的修改量,使算法具有较高的嵌入效率。
3 算法实现
3.1 信息嵌入算法
算法采取二次编码的方式,信息嵌入在CABAC熵编码部分完成,具体步骤如下:
(1) 为提高算法安全性,本文使用Logistic混沌序列对秘密信息进行加密预处理,生成2n比特待嵌入二进制序列M=(m1,m2,…,m2n),并将每两个二进制字符组成二进制字符串Mi=m1im2i。
(2) 进行第一次编码,提取所有语法元素abs_mvd_minus2经过EG1编码产生的后缀INFO的全部比特位,并保存为二进制字符串α=a1a2…al。
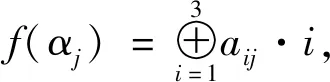
(4) 重复第3步,直至所有待嵌入信息嵌入完毕,得到修改后的二进制字符串α′。
(5) 进行第二次编码,将当前进行熵编码的语法元素abs_mvd_minus2经过EG1编码得到的后缀INFO的比特位数记为n,按顺序读取α′中n比特二进制字符并替换该INFO,将修改过的编码重新写入码流进行旁路编码。重复该步骤,直至字符串α′替换完毕。
3.2 信息提取算法
算法信息提取过程在熵解码部分完成,具体步骤如下:
(1) 提取所有语法元素abs_mvd_minus2经过EG1编码产生的后缀INFO部分,并保存为二进制字符串β=b1b2…bm。

(3) 重复步骤(2),直至所有信息转换完毕,最后对使用Logistic混沌序列加密过的信息进行解密得到嵌入的秘密信息。
4 实验与分析
实验在VS2015上使用HEVC参考软件HM16.9对本文算法进行仿真分析,选取不同分辨率的官方测试序列(BasketballDrive,BQMall,Kimono,PeopleOnStreet,RaceHorses)进行对比分析。编码视频帧序列结构为IPPP…,量化参数为27,其余参数均使用默认设置。编码端输入内容为YUV测试序列和秘密信息,输出内容为编码重建后的HEVC视频序列和载密二进制流,解码端输入内容为二进制流,输出内容为秘密信息及解码视频。
4.1 主观性分析
为了主观分析秘密信息对编码重建视频质量的影响,图1给出了秘密信息嵌入前后的第30帧的视频编码重建图像。从主观性角度分析,信息隐藏前后图像差别很小,信息隐藏后并未对编码重建后的HEVC视频图像造成明显影响。

图1 嵌入前和嵌入后重建图像对比
4.2 客观性分析
为了客观分析秘密信息嵌入前后对编码重建后的HEVC视频质量的影响,本文选择峰值信噪比(PSNR)、比特率(BR)、比特率变化率(BRI)对嵌入前后的视频质量进行客观评价。
(8)
式中:MSE表示原视频图像与编码后视频图像之间的均方误差。
(9)
式中:BR′和BR分别为信息隐藏前后的编码比特率。
图2、图3给出了在QP=22,27,32下,秘密信息嵌入前后,部分测试序列编码后视频的PSNR值随比特率的变化折线图。可以看出,嵌入前后的折线图基本重合,PSNR值随比特率变化情况基本一致,视频质量未产生明显变化。

图2 PSNR值随比特率变化图(RaceHorses)
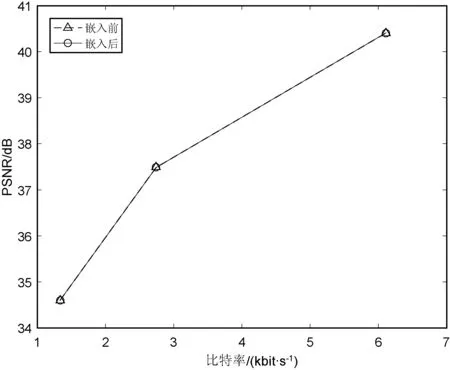
图3 PSNR值随比特率变化图(BQMall)
表2、表3给出量化参数QP=27时,在不同分辨率的测试序列下,本文算法在信息嵌入前后编码重建视频的PSNR、BR、BRI的数值对比。可以看出,秘密信息的嵌入并没有使PSNR值产生明显变化。与文献[7]算法类似,本文算法并没有引起信息嵌入前后的比特率变化。这是因为两种算法均选择在指数哥伦布编码过程中进行信息嵌入,仅对载体数据的部分比特位进行修改,并没有对编码长度产生影响,不会产生额外的比特位。由于熵编码是编码过程的最后一步,语法元素abs_mvd_minus2经过指数哥伦布编码后通过旁路编码写入比特流中完成编码,所有二进制符号均以0.5的概率进行编码,信息熵公式如下:

表2 PSNR测试结果对比

表3 比特率及其变化率测试结果
(10)
式中:H表示信息熵值;Xi表示随机变量,在本实验中表示单个二进制符号;P(Xi)表示每个二进制字符的出现概率。信息嵌入后不会改变进入比特流中的信息熵即平均信息量的大小。因此,使用本文算法进行信息嵌入后不会改变编码比特率,具有较好的客观不可感知性。
4.3 嵌入容量和嵌入效率分析
本文采用嵌入容量和嵌入效率测试分析算法信息隐藏效果。嵌入效率表示修改单位载体后嵌入的信息量[18]:
E=m/n
(11)
式中:m表示平均每个p帧嵌入的比特总数;n表示平均每个p帧修改的比特总数。
表4列出了当量化参数QP=27时,部分序列使用本文算法进行信息嵌入后平均每个p帧的秘密信息嵌入位数,最大载体修改位数和嵌入效率。为方便进行实验对比,在统计嵌入容量时,本文算法设置与文献[7]相同的阈值T,即选择数值大于等于T的语法元素abs_mvd_minus2进行信息嵌入。随着阈值T的提升,本文算法相较于文献[7]的嵌入容量提升比率也随之提高。并且本文算法对载体修改量较少,具有较高的嵌入效率。这是由于本文算法选择语法元素abs_mvd_minus2经过EG1编码产生的后缀INFO作为嵌入载体,相较于文献[7]选择的编码末位具有更多的载体比特位。又因为矩阵编码的引入,理论上,本文算法最多修改1个载体比特便可完成2比特信息嵌入,嵌入效率为2。在实际嵌入中,若嵌入信息与载体信息有较高的重合度,可以修改更少的载体比特,从而得到更高的嵌入效率。

表4 本文与文献[7]方法嵌入容量和嵌入效率测试结果对比
为了进一步评价本文算法的嵌入容量与嵌入效率,本文选择最新的HEVC信息隐藏算法[19-20]与本文算法进行对比。文献[19]选择修改PU分区模式进行信息嵌入,并采用不同嵌入级别完成对不同分辨率视频的信息隐藏,本文选择其测试视频分辨率范围最广且嵌入强度较高的算法的实验结果进行对比。文献[20]选择运动向量分量作为嵌入载体,同样采用不同的嵌入强度进行嵌入,本文选择其中嵌入强度较高的结果进行对比。如表5所示,在量化参数QP=32下,虽然本文算法在嵌入效率上略低于文献[20]的算法,但在信息嵌入量上明显优于文献[19]与文献[20]的算法,这进一步说明了本文算法较好地兼顾了嵌入容量和嵌入效率。
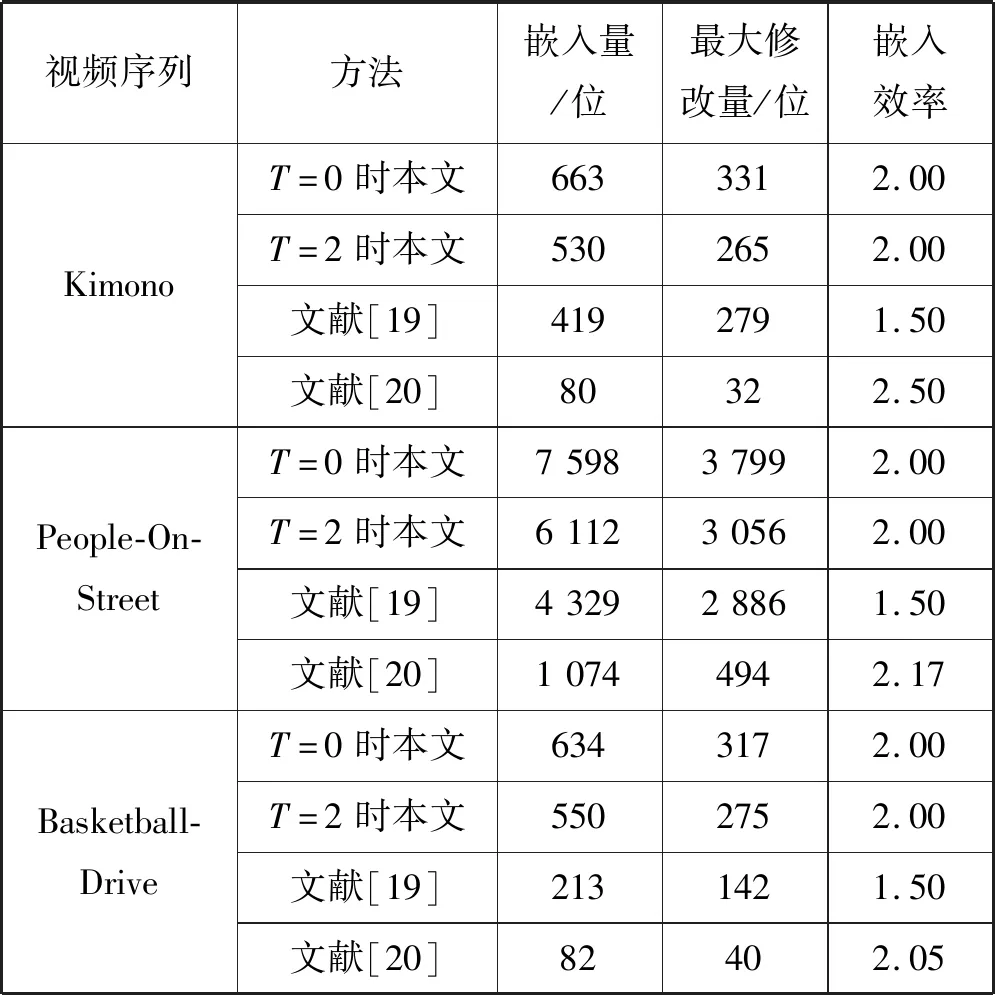
表5 本文与文献[19]、文献[20]的算法测试结果对比
5 结 语
本文提出一种基于CABAC的HEVC信息隐藏算法。通过阐述两种算术编码的性质以及指数哥伦布编码的特点,分析了将语法元素abs_mvd_minus2经过指数哥伦布编码产生的后缀作为嵌入载体的可行性,并采用矩阵编码的方法实现秘密信息的嵌入。为了保证算法的安全性,本文采用Logistic混沌加密完成对秘密信息的预处理。实验结果表明,本文算法在主客观上均有良好的不可感知性。与同类基于CABAC熵编码的信息隐藏算法相比,本文算法在嵌入效率上较文献[7]增加了1倍,在相同嵌入阈值下,嵌入容量也得到了大幅度提高。与其他类型的最新HEVC信息隐藏算法[19-20]相比,本文算法同样在嵌入容量上得到了较大的提高,并较好地兼顾了嵌入效率。
猜你喜欢
中等数学(2021年8期)2021-11-22 07:53:38
数学大王·低年级(2019年10期)2019-11-25 08:23:26
中等数学(2019年4期)2019-08-30 03:51:44
海峡姐妹(2017年10期)2017-12-19 12:26:20
三联生活周刊(2017年33期)2017-08-11 04:35:44
银行家(2017年1期)2017-02-15 20:27:20
现代语文(2016年21期)2016-05-25 13:13:35
意林(绘英语)(2016年5期)2016-04-09 10:55:20
辽金历史与考古(2016年0期)2016-02-02 01:34:10
电子与信息学报(2015年2期)2015-07-18 12:04:47
