
基于神经网络的集装箱船港口作业时间预测模型
2021-02-25 08:51:44韩宗垒
计算机应用与软件 2021年2期
韩宗垒 徐 斌 陈 佳
(大连海事大学辽宁省物流航运管理系统工程重点实验室 辽宁 大连 116026)
0 引 言
泊位是港口的重要资源,合理的泊位计划能有效提高港口生产效率,减少船舶在港时间,从而提高港口的竞争力。Imai等[1]釆用连续区位空间的方法对连续型泊位计划进行研究,建立了船舶等待时间和作业时间最小的数学模型并采用拉格朗日松驰系数算法进行求解。张煜等[2]考虑在泊位计划中岸桥的分配影响集装箱船的装卸作业效率,依据规则建立确定船舶集装箱装卸作业时间和分配岸边起重机的算法。秦进等[3]提出基于时间窗约束的离散型泊位计划模型,建立了模拟退火算法模型进行优化求解。韩晓龙等[4]在港口船舶的目标函数中加入了船舶作业时间,对船舶的服务时间和作业时间提出了时间窗约束,建立了以最小化卸船完工时间为优化目标的混合整数规划模型和约束规划模型。曾庆成等[5]用船舶装卸集装箱量除以岸桥装卸效率来预测集装箱船港口作业时间。
综上所述,大量的研究表明集装箱船港口作业时间对于制作科学高效的泊位计划是非常重要的,研究中用的是传统装卸集装箱量除以岸桥装卸效率的预测方法,预测精度较低,因此寻找一种科学的方法来预测集装箱船港口作业时间是非常有意义的。本文基于神经网络针对集装箱船港口作业时间预测的问题建立模型,通过与传统预测方法的对比验证了模型的可行性。
1 问题描述
在集装箱船实际到达港口之前,港口需要根据船期表制作泊位计划确定集装箱船靠泊的时间和位置。集装箱船港口作业时间(船舶开始装卸第一个集装箱到完成装卸最后一个集装箱的这段时间)是制作泊位计划的主要依据,而集装箱船港口作业时间的主要获取方法是预测,所以预测出精确的集装箱船港口作业时间可以提高泊位计划的效率。
传统的集装箱船港口作业时间预测方法是船舶待装卸的集装箱量除以岸桥的装卸效率。这种预测方法不灵活并且预测精度较低,集装箱船港口作业时间受多种因素的影响[6],如船舶类型、岸桥数、装卸集装箱量、天气等,并且存在复杂的非线性关系。考虑到集装箱船港口作业时间与影响因素之间复杂的非线性关系,本文选取了比较适用的BP神经网络建立集装箱船港口作业时间预测模型。模型的目标是预测出更加精确的集装箱船港口作业时间,从而保证制作的泊位计划更加科学高效。
2 模型建立
BP(Back Propagation)神经网络是一种多层前馈神经网络,由输入层、隐含层、输出层组成,可以以任意的精确度逼近任意一个连续的函数,所以经常被用于非线性建模、函数逼近和模式分类等方面。BP神经网络的主要特点:信号是前向传播的,误差是反向传播的。
2.1 网络的层数
1989年Robert Hecht-Nielson证明了对于任何一个闭区间内的函数,都可以用有一个隐含层的BP神经网络来逼近,所以一个三层(含一个隐含层)的BP神经网络可以完成任意的n维向m维的映射。在多数的实际应用中一般都取三层的BP神经网络来解决问题,所以本模型选取了三层的神经网络。
2.2 输入和输出层神经元个数
BP神经网络的输入和输出层的神经元个数完全根据使用者的要求进行设计。影响船舶港口作业时间的因素有很多,通过分析确定了船舶类型、岸桥数量、卸20尺箱量、装20尺箱量、卸40尺箱量、装40尺箱量、卸特种箱量、装特种箱量和天气作为模型的输入。本模型根据输入样本的维度,将输入层设置为9个神经元。集装箱船港口作业时间预测模型最后输出的是集装箱船港口作业时间,所以输出层神经元的个数为1。
2.3 隐含层神经元个数
隐含层对于整个神经网络的精度起着至关重要的作用,隐含层神经元个数的选取与输入、输出层神经元个数都有直接的关系。神经网络精度的提高可以通过增加隐含层神经元的个数来实现,隐含层神经元的个数较少时,神经网络就不能较好地学习,导致模型不能较好地拟合数据,训练精度和预测精度都不高,出现欠拟合的情况;隐含层神经元个数较多时,模型结构可能过于复杂,导致过度的拟合训练数据,而对测试数据的预测能力较差,出现过拟合的情况,所以选取准确的隐含层神经元个数是很重要的。隐含层神经元个数选取的方法很多,结合开发的神经网络生成器,本模型采用式(1)选取隐含层神经元个数[7]。
(1)
式中:p为隐含层神经元个数;n为输入层神经元个数;m为输出层神经元个数;a为1~10之间的常数。经过试算最终确定隐含层神经元个数为10。
2.4 激活函数
BP神经网络的激活函数有多种。其中Sigmoid函数对于网络不同输入,将其输出范围控制在(0,1)之间,公式如下:
(2)
Tanh(双曲正切)激活函数对于不同范围的输入,将其输出值范围控制在(-1,1)之间,公式如下:
(3)
线性激活函数Purelin的输入与输出值可取任意值,公式如下:
f(x)=x
(4)
本模型选取Sigmoid作为隐含层的激活函数,Purelin作为输出层的激活函数。
2.5 LM-BP算法
标准BP算法是根据梯度下降法来调整权值的:
Δw=-ηg
(5)
式中:Δw为权值阈值更新量;η为学习速率;g为梯度。
权值沿着与误差相反的方向移动,使得误差函数减小,缺点是神经网络收敛较慢,且学习速率不容易被确定。LM(Levenberg Marquardt)算法是一种利用标准的数值优化技术的快速算法,是梯度下降法和高斯-牛顿法的结合,既有高斯-牛顿法的局部收敛性,又有梯度下降法的全局特性,具有收敛速度快、鲁棒性好的特点。下面对LM算法做简要阐述:
设网络的误差函数为:
(6)

用wk表示在第k次迭代的权值和阈值,迭代完成后的权值和阈值组成的向量为wk+1,Δw是权值和阈值的改变量,则有:
wk+1=wk+Δw
(7)
牛顿法是通过最小二乘法求解误差函数E(w):
Δw=-[▽E2(w)]-1▽E(w)
(8)
式中:▽E2(w)是误差E(w)的Hessian矩阵,▽E(w)表示梯度,对Hessian矩阵进行近似计算,可以表明:
▽E(w)=JT(w)e(w)
(9)
▽E2(w)=JT(w)e(w)+S(w)
(10)
式中:J(w)是e(w)的Jacobian矩阵;S(w)是误差矩阵。
在靠近极值点时S(w)≈0,牛顿法可以修正为高斯-牛顿法,经过改进得到修正权值阈值的公式:
Δw=-[JT(w)J(w)]-1J(w)e(w)
(11)
LM算法将高斯-牛顿法经过改进得到修正权值阈值的公式:
Δw=[JT(w)J(w)+μI]-1J(w)e(w)
(12)
式中:I为单位矩阵;μ为大于0的常数。
系数μ的值很小时,LM算法就近似等于高斯-牛顿法,当μ的值很大时,就近似等于梯度下降法。每迭代成功一次μ就会除以比例系数β(β>1),这样在接近目标误差的时候就基本与高斯-牛顿法相等,计算速度快,精确度也高,否则μ乘比例系数β,LM算法利用近似二阶导数信息,比梯度下降法快得多。在实际应用中μ是一个试探性的参数,对于一个给定值,如果求得Δw能使E(w)降低,则μ降低,反之μ增加。
2.6 相关参数
(1) 权值和阈值。选取处于(-1,1)之间的随机数作为权值和阈值的初始值。
(2) 学习速率。神经网络权值每次的变化量都取决于学习速率的大小,如果学习速率选取较大,系统可能因此而动荡不稳定;学习速率选取较小则收敛速度慢,训练时间长,网络误差值与误差最小值更趋近的目标无法保障。实际应用中常选取较小学习速率给系统提供稳定性保障,所以学习速率的选取区间是[0.01,0.9]。本模型选取的学习速率为0.01。
(3) 其他。最大训练次数为1 000次,训练要求精度为0.000 1,极小值认定次数为50,μ的初始值为0.000 01,比例系数β为10。
3 算例分析
某港口近年集装箱船港口作业数据中包含船舶类型、分配岸桥数、装卸集装箱量、天气、计划作业时间、实际作业时间等。集装箱船的第一代和第六代相当少,这里只考虑第二至第五代的船型。因为原始数据中船舶类型和天气都是文字形式,所以需要对船舶类型和天气情况进行编码数字化。船舶类型和天气情况编码后的结果如表1和表2所示。

表1 编码后的船舶类型

表2 编码后的天气
随机选取1 000条集装箱船港口作业信息数据作为模型的训练集和测试集数据,由于数据量较大,这里只展示部分编码后的数据,如表3所示。

表3 编码后的船舶信息
1) 传统的集装箱船装卸集装箱量除以岸桥装卸效率的预测方法可以根据式(13)计算:
(13)
式中:h为集装箱船港口作业时间;Y为装卸集装箱总量;v为单个岸桥装卸效率;n为分配岸桥数。
港口单个岸桥装卸效率为35箱/h,用传统预测方法计算集装箱船港口作业时间结果如表4所示。

表4 传统方法预测作业时间
2) 用神经网络模型预测集装箱船港口作业时间:为了消除各参数由于单位等的影响,并且样本不一定包含极大和极小值,所以对数据用式(14)做规范化处理,使规范化后的数据范围为 [-1,1]。
(14)
式中:y为规范化后的数值;ymax=1;ymin=-1;xmax为每一属性中的最大值;xmin为每一属性中的最小值;x为需要规范化的数据值。
模型训练学习过程如下:选取样本中的3条数据如表5所示,规范化后的样本数据如表6所示,模型的输入为x1,x2,…,x9,输出为y。

表5 样本数据

表6 规范化后的样本数据
(1) 设定好网络的期望误差值ε=0.000 1,系数β=10,μ=0.1,学习速率η=0.01,以及权值和阈值的向量:
(3) 计算Jacobian矩阵:

(4) 通过式(12)、式(6)计算出Δw:
Δw=

E(wk)=0.014 06
(5) 如果E(wk)<ε,转到式(10),否则,用wk+1为权值和阈值计算误差E(wk+1)=0.011 37。
wk+1=

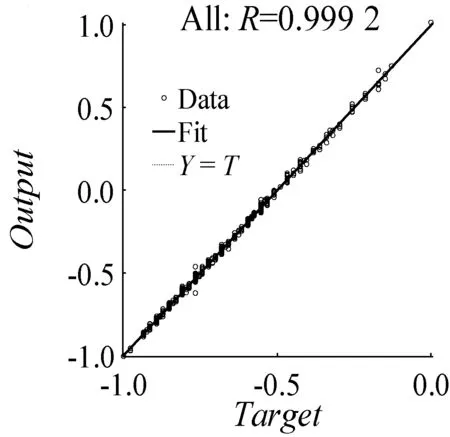
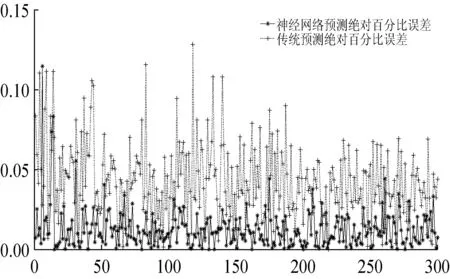
(6) 如果E(wk+1) (7) 结束。 选取数据的70%作为模型的训练数据,数据的30%作为模型的验证数据,运用MATLAB平台进行集装箱船港口作业时间预测模型实验[8]。通过神经网络模型的拟合效果,神经网络模型和传统方法预测值的绝对百分比误差(Absolute Percentage Error,APE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)的对比,评价模型的优越性。 (15) (16) 经过多次训练学习取得最好一次结果。从图1可以看出,随着神经网络迭代次数的增加,网络的误差逐渐变小并且趋于稳定。从神经网络收敛效果看,当网络训练的次数达到87次后网络收敛,网络的均方误差为0.000 27,基本达到误差的设置要求,模型训练效果优秀。 图1 神经网络迭代图 图2横坐标为模型输出的期望目标值,纵坐标为模型对数据拟合实际输出的目标值,当模型实际输出的值满足在期望值上下0.001(output≈1×Target±0.001)误差的范围内,则说明该数据可以被模型解释。R为被模型解释的数据量占总数据量的比例,Fit实线表示网络对数据训练学习将非线性关系转化成的线性关系,Y=T虚线代表模型拟合数据的期望线性关系。可以看出,整个网络的数据拟合度达到99.92%,通过网络对数据的拟合效果可以验证该网络模型的可行性。 图2 神经网络迭代图 根据式(13)计算测试集的集装箱船港口作业时间,根据式(15)和式(16)分别计算APE和MAPE。 通过神经网络预测模型输出测试集的集装箱船港口作业时间预测值,根据式(15)和式(16)分别计算APE和MAPE。 两种预测方法对比如下: 从图3中可以看出,神经网络预测集装箱船港口作业时间的APE均明显低于传统方法预测集装箱船港口作业时间的APE。从表7中可以看出,传统预测方法的最大APE是10.3%,MAPE是4.5%;神经网络模型的最大APE是7.1%,MAPE是1.6%,这说明了用神经网络预测集装箱船港口作业时间比传统方法更精确。 图3 神经网络和传统方法预测值的APE 表7 测试集最大APE和MAPE % 本文基于传统预测集装箱船港口作业时间方法的预测精度低、不灵活等问题,分析了集装箱船港口作业时间受多种因素的影响、存在非线性的特点,结合神经网络非线性拟合能力强的特点,构建神经网络集装箱船港口作业时间模型。通过与传统预测方法预测效果的对比,展现了本文模型的优越性,提高了预测的精度,为制作科学高效的泊位计划奠定了基础。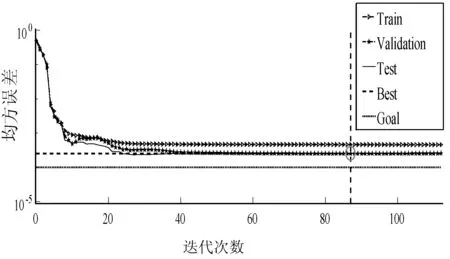

4 结 语
猜你喜欢
百科探秘·海底世界(2024年6期)2024-06-27 23:10:58
军事文摘(2023年14期)2023-07-28 08:39:46
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
军事文摘(2018年24期)2018-12-26 00:57:56
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
自动化学报(2017年7期)2017-04-18 13:41:02
