
基于最优化数据质量的图书馆大数据动态清洗策略研究
2021-02-24 05:18马晓亭兰州财经大学信息工程学院
图书馆理论与实践 2021年6期
马晓亭(兰州财经大学信息工程学院)
目前,图书馆界已进入大数据时代。大数据具有数据体量巨大(Volume)、处理速度快(Velocity)、价值密度低(Value)、数据类型繁多(Variety)的4个“V”特性[1]。据统计,大型数据库中数据的错误率约为5%[2],且数据清洗时间约占大数据分析总时间的60%~80%[3]。大量脏数据(Dirty data)的存在,严重影响了图书馆数据分析、知识发现和数据决策的正确与实效[4]。因此,如何精准、高效、实时和低成本地完成对图书馆大数据库中脏数据的清洗,是关系提升图书馆大数据价值密度和可用性,增强智慧服务决策科学性与读者个性化服务质量的关键。
1 图书馆脏数据的定义、产生原因与数据清洗的目的
1.1 图书馆脏数据的定义
脏数据(Dirty Data)是指源系统中的数据不在给定的范围内,或对于实际业务毫无意义,或是数据格式非法、过时、不完整、不准确的任何类型的电子数据,或者源系统中存在不规范的编码或含糊的业务逻辑。图书馆中的脏数据可能是由于数据采集错误、人员录入错误、未能定期更新数据或重复采集而产生的。脏数据的存在严重降低了图书馆大数据的价值密度、决策科学性和经济性,以及读者个性化阅读服务的智能化、实时性和专属定制水平[5]。图书馆脏数据的类型与表现种类如表1所示。

表1 图书馆脏数据的类型与表现分类表
脏数据主要由缺失数据、错误数据、数据重复、不一致数据、噪声数据等5部分组成,是关系图书馆大数据决策智慧化水平和读者个性化服务满意度的关键。因此,图书馆必须加强脏数据的管理与清洗工作。
1.2 图书馆脏数据产生的原因
“摩尔定律”告诉我们,集成电路芯片上所集成电路的数目,每隔18个月就翻一番。同时,微处理器的性能每隔18个月提高一倍,而价格下降一半。因此,数据采集与处理设备性能的提升和采购价格的大幅下降,在提升了图书馆大数据获取能力的同时,有效降低了数据获取的成本,支持图书馆全方位、不间断地采集相关大数据,最终提升了图书馆大数据库的数据总价值与大数据决策的能力,但也导致图书馆大数据总量呈现指数级增长和价值密度急剧下降的现象[6]。
图书馆主要通过视频监控设备、传感器网络、个人数字阅读PDA、网络服务器、视频监控设备等采集大数据,所采集的数据除包括图书馆企业资源计划数据、财务管理系统数据、数字文献管理信息系统数据、读者信息与服务管理系统数据等结构化数据之外,还包括诸如网页、文本、图像、视频、语音之类的非结构型数据,且非结构化数据占据图书馆数据总量的80%以上,错综复杂的数据采集对象、方式和环境是图书馆脏数据大量产生的主要原因。具体原因有以下几方面。①图书馆通过大量的射频识别(RFID)设备实现了对读者身份认证、个人移动路径、读者地理位置信息、查阅管理和图书馆安全管控等数据的不间断采集,物理电磁复杂环境和设备使用人员的不规范操作导致脏数据的产生[7]。②视频监控设备、传感器网络、个人数字阅读PDA、网络服务器、视频监控设备等大数据采集设备的标准化程度、设备故障、人为原因,以及异构系统的系统兼容性、友好性与可操控性也是导致图书馆脏数据产生的原因。③所采集大数据的标准化、科学性、传输与存储方法合理性、异构系统的兼容性等,也是导致脏数据产生的重要因素。
1.3 图书馆脏数据的清洗目的
1.3.1 将不规整数据转化为规整数据
图书馆大数据采集终端设备存在着设备类型多样、数据采集标准不统一的特点,且设备网络拓扑结构以分布式结构存在,所采集的数据在数据结构、类型和逻辑上呈现不规整的状态。因此,必须依据图书馆大数据决策需求和读者个性化智慧阅读场景需要,通过科学的数据清洗流程对所采集的大数据在数据格式、标准、逻辑和处理流程上进行统一,并对存在于规整数据中的随机噪声数据进行平滑、过滤和删除,只有这样才能确保决策大数据高价值、标准化、可应用和无差错。
1.3.2 对数据进行审查和校验
图书馆在大数据的采集中,由于数据采集设备和用户阅读终端的多样性,导致大数据库中部分数据呈现重复叠加的现象,这些重复数据不但增加了大数据库的存储负荷,也增加了大数据处理、分析和决策系统的应用负担,最终导致图书馆大数据决策的准确性、实时性、经济性和可控性降低。因此,必须有效删除大数据库中的重复数据。此外,图书馆不同的大数据决策分析对数据的类型、结构和精确度要求不同,因此必须以图书馆大数据决策需求为依据,在不影响数据一致性、精确性、完整性和有效性的前提下,通过对数据的审查和校验来消除数据异常,最终实现数据的集成、清洗与标准化。
1.3.3 标准化数据的格式与类型
图书馆大数据决策具有海量、实时、快速和动态的需求,其大数据库数据格式与类型标准化的程度直接关系大数据处理、挖掘、分析、机器学习、决策、可视化等流程的正确、实时和可用。因此,必须通过对大数据的科学分解、重组和标准化处理,才能得到标准、干净、实时和连续的大数据资源[7]。
标准化数据所涉及的内容主要包括数据来源统一、格式统一、类型统一、表现形式统一、单位度量统一、存储与调用方式统一、处理与分析流程统一等方面,而其中最大的挑战与难点是海量流数据格式与类型的统一。流数据具有海量、动态、多源异构、高维度和强时空相关性的特点,是读者个性化智慧阅读实时服务最重要的决策依据,其数据标准化水平的高低直接关系图书馆大数据决策的科学性、准确性、高效性、即时性和个性化的程度,因此必须通过流数据的动态、实时、快速和准确清洗,才能保证读者具有较高的个性化阅读满意度[8]。
2 基于大数据决策质量反馈控制的数据清洗流程设计
2.1 大数据清洗流程设计
图书馆大数据的清洗应坚持从数据的生命周期流程管理出发,以图书馆大数据决策科学性、智慧性、实时性和经济性为目的,保证清洗后的大数据准确、完整、一致、唯一、合理、适时、可用和高价值,如此才能够为图书馆大数据决策提供高质量的数据支持。本文设计的基于大数据决策质量反馈控制的图书馆大数据清洗流程如图1所示。
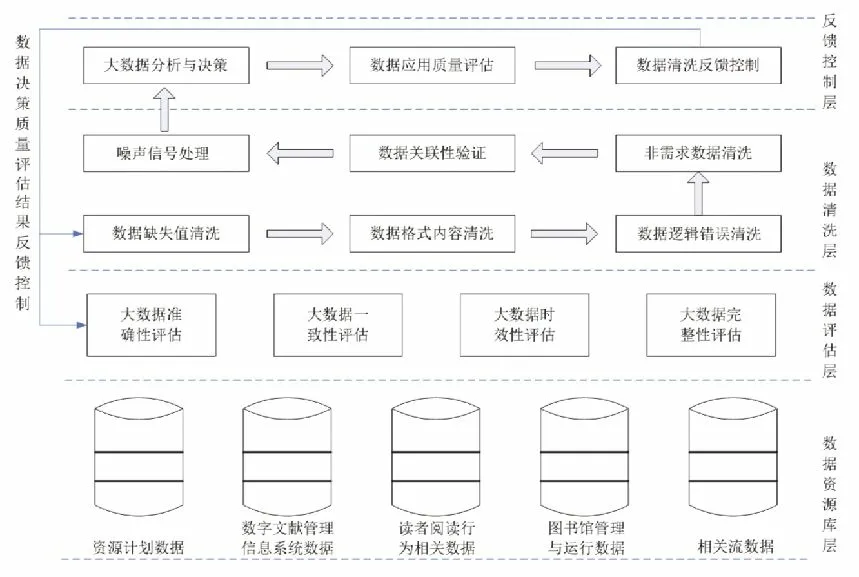
图1 基于大数据决策质量反馈控制的图书馆大数据清洗流程图
从图书馆大数据决策生命周期管理流程划分,数据清洗的层次结构可分为数据资源库层、数据评估层、数据清洗层和数据决策质量评估反馈控制层等四个层次。
(1)数据资源库层是大数据资源的存储层,依据图书馆大数据的结构模式、价值属性、决策类型、存储方式和安全管理需求,分别以分布式存储于资源计划数据库、数字文献管理信息系统数据库、读者阅读行为相关数据库、图书馆管理与运行数据库、相关流数据库中,同时确保大数据存储安全、高性能、易扩展和低功耗[9]。
(2)大数据评估层位于系统的第二层,负责完成大数据清洗前的数据质量评估。数据评估层主要依据图书馆大数据应用实际需求,对大数据的准确性、一致性、时效性和完整性等四个方面进行评估。评估内容主要包括数据是否异常与错误、格式是否统一、能否实时动态反映当前的系统服务与读者阅读情景、数据是否存在缺失值。数据评估标准是随着图书馆大数据决策的智能化、个性化、实时性、经济性需求变化而动态变化,数据质量评估标准的高低与图书馆大数据清洗的效果成正比例关系,而与数据清洗系统的资源损耗和经济性成反比例关系。
(3)第三层是数据清洗层。首先,按照大数据标准化模式要求对缺失的数据内容进行填补,以增强缺失大数据的价值属性。其次,通过内容清洗、数据逻辑错误清洗、非需求数据清洗、数据关联性验证、噪声信号处理等操作,将清洗后的标准大数据传输给大数据应用系统,为图书馆大数据决策与读者个性化智慧阅读服务提供可靠的数据支持。数据清洗层的清洗规则和程度是随着图书馆大数据应用要求的不同而动态变化的,复杂的数据清洗规则将会消耗更多的清洗时间和系统资源。因此,图书馆必须制定恰当的数据清洗策略,才能确保清洗流程在效率、质量、时间和成本方面的综合评估结果最优化[10]。
(4)反馈控制层为系统的第四层。经过清洗的干净数据传输到大数据决策与应用层并进行数据的处理、分析、价值提取、大数据决策后,数据应用质量评估层结合读者对个性化阅读服务的满意度,对大数据决策的科学性、有效性、经济性和实时性进行评估,并将评估结果传输到数据清洗反馈控制模块。如果评估结果不能满足图书馆大数据决策需求,数据清洗反馈控制模块则通过反馈控制来修改、完善大数据的评估标准和数据清洗规则,并通过二次清洗进一步提高决策大数据的数据质量、可用性和安全性。
2.2 数据清洗应重视的关键问题
2.2.1 大数据缺失值的清洗
图书馆大数据的缺失主要是由数据终端采集设备采集过程中的数据丢失、人工录入数据失误而发生的缺失,以及数据在传输、存储和调度等过程中发生的缺失等情况造成。终端采集数据的缺失可通过对终端设备完善、升级和软件优化等措施避免,人工录入数据缺失可通过错误码校验、必填项控制及人工补录等方式完善。
在图书馆大数据应用中,缺失值的存在是不可避免的,特别是当缺失值非随机出现且变量之间强相关性时,不同的数据清理处理策略会得到不同的数据质量。因此,对于无效缺失值或者低价值、低样本比重、弱相关性的缺失值可以直接删除缺失值。如果缺失数据呈现高价值、高相关性和多维度时,可采取人工填补遗漏值、利用均值填补遗漏值、预测值填补遗漏值的方式,确保缺失数据完整、高价值、可应用和可控制。
2.2.2 大数据格式与内容的清洗
图书馆为了提升读者个性化阅读服务推送的精准性、时效性,必须大量采集读者每日的移动路径信息、阅读终端信息、阅读内容信息、阅读习惯信息、阅读时间信息、地理位置信息等,通过对每日阅读大数据的清洗和关联计算,预测未来某日、某时间段读者的阅读需求,进而自动选择相应的阅读内容和阅读模式向读者实时推荐,来满足读者的阅读需求和提升阅读满意度。图书馆采集的读者个人阅读数据具有多终端采集、多模式和离散性强的特点。因此,图书馆必须依据读者个性化阅读大数据决策的需求,将数据进行标准化统一,并为不同的数据变量分配相应的权重比例,通过每个数据点减去所有数据平均值的方法处理离群点,防止离散数据偏差而导致大数据决策准确性降低[11]。其次,对于多终端、多人员、多对象采集的数据,应通过格式清洗的方式确保数据在时间、日期、数值、全半角等显示格式上一致,并删除数据在格式内容上不存在和多余的字符。再次,对于多终端采集或者人员多次录入的重复数据,可采取相同的关键信息匹配方法去重,也可以通过主键进行去重。
2.2.3 异常大数据的清洗
在图书馆大数据应用过程中,过度超出数据采集范围区间、规律、规则,或者与平均数据差异较大的数据称为异常数据。如,图书馆某日采集的一位读者阅读兴趣数据,该读者的阅读内容、时间、习惯等与平日采集数据均值有较大差异性,这可能是他人利用该读者的阅读终端与用户账号登录服务系统而产生的数据,此类数据对判定该读者的阅读行为没有参考价值和统计意义。又如,某日网络监控设备发现图书馆服务器TCP队列满,并且CPU负荷快速升高、内存过载而导致服务器宕机,严重影响了服务器的服务性能,而这种远远超出日常在线用户平均数的统计大数据则十分有价值,通过大数据分析可以得出服务器可能正在受到DDoS攻击,因此可由大数据决策系统构建相应的防御策略进行防御[11]。对于异常大数据的清洗可以通过构建相应的规则库实现,规则库必须以常识性规则、业务规则和数据关联规则等进行科学判定,而不是对大幅度偏离平均值的数据简单删除或者修改。此外,异常大数据的清洗规则必须随着大数据决策系统的智慧自主学习而动态变化,并不断提升数据清洗的智能和自动化水平。
2.2.4 噪声大数据的清洗
图书馆大数据采集具有多终端、多用户、不间断和全方位的特点,图书馆大数据除具有大数据的4“V”特性外,还具备高维度、多变量数据、大规模和高增长的特性。由于采集设备、方法、对象、时间、流程和软件程序科学性的缺陷,所采集的大数据存在着错误、失真、异常和无关的数据,这些数据大幅度增加了数据存储、处理、分析和决策的难度,也将大幅度影响决策大数据的收敛速度,降低图书馆大数据决策模型的科学性、准确性和可靠性。因此,图书馆必须加强对噪声数据的清洗[1]。①对于图书馆数据库中存在的与大数据决策无关,甚至明显错误的数据,可由图书馆工作人员依据自身的业务知识人工处理即可。②对于正态分布的大数据,可以利用3个标准差原则进行去噪,或使用四分位差进行去噪。③对于偏态分布数据可以采用分箱处理的方法,按照属性值划分子区间。如果一个属性值处于某个子区间范围内,就把该属性值放进这个子区间所代表的“箱子”内。把待处理的数据按照一定的规则放进一些箱子中,考察每一个箱子中的数据,采用某种方法分别对各个箱子中的数据进行规则处理,最后再对每个箱子中的数据进行平滑处理。④图书馆员可将类型、结构和决策对象相同的数据,按照数据的内在性质将数据分成一些聚合类,每一聚合类中的元素尽可能具有相同的特性,而不同聚合类之间的特性差别尽可能大。这些聚类集合之外的数据即为噪声数据,应对这些孤立点进行删除或替换。⑤对于两个或者多个相关变量数据,可通过构造回归函数的方式,确保该函数能够更大程度地满足两个变量之间的关系,并使用这个函数来平滑数据。
3 结语
为了精准、高效、实时和低成本地完成图书馆大数据的清洗工作,图书馆首先必须认识到数据治理工作的重要性、复杂性和长期性,应构建标准化、动态和持续优化的数据清洗流程,同时根据图书馆大数据决策系统资源配置实际,制定恰当的大数据清洗流程与标准,并依据大数据应用决策需求变化对数据清洗算法、数据清洗对象、清洗精确度进行完善与优化,才能保证图书馆在大数据分析决策需求、系统资源损耗、决策实时性和总体经济性上最优;其次,图书馆必须坚持人工清洗和设备自动化清洗相结合的原则,利用数理统计、数据挖掘、语义分析或预定义的清理规则,提升对特殊脏数据清洗的效率与准确性;再次,图书馆在数据清洗关系模型的设计中,应坚持简单、高效和低系统资源损耗的原则,实现数据清洗模型的复杂性、资源损耗率、时效性和数据分析结果准确性之间的最佳平衡。
猜你喜欢
纺织科学研究(2021年9期)2021-10-14
文苑(2019年20期)2019-11-16
决策(2018年8期)2018-12-10
决策(2018年11期)2018-11-28
文苑(2018年17期)2018-11-09
决策(2018年10期)2018-11-07
小天使·四年级语数英综合(2018年1期)2018-07-04
小太阳画报(2018年1期)2018-05-14
领导决策信息(2018年50期)2018-02-22
小天使·一年级语数英综合(2014年8期)2014-06-26
