
基于Kubernetes的铁路客运营销深度学习平台的设计与实现
2021-02-23 02:04:16郝晓培单杏花王炜炜
铁路计算机应用 2021年1期
郝晓培,单杏花,李 永,王炜炜
(1. 中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;2. 北京经纬信息技术有限公司,北京 100081)
随着人工智能及铁路信息技术的快速发展,深度学习在铁路客运营销中得到了广泛的应用,为铁路客运流量预测,客运广告推荐,12306互联网售票系统异常用户识别等提供了大量的解决方案以及业务指导[1]。
理想的深度学习训练模型需要综合考虑训练数据的选择及处理,模型算法选择、参数的调试、训练资源分配、模型训练速度等诸多问题。算法工程师需要花费大量的时间进行深度学习集群部署(扩容)、框架安装及硬件资源的分配等繁杂的工作,严重影响了铁路客运营销深度学习模型训练结果的效率及准确性,亟需研究新方案提高深度学习模型开发的效率及硬件资源的利用率。
目前,国内外在深度学习及容器云计算方面得到了广泛的应用,翁湦元等人成功地将铁旅App迁移到Kubernetes云平台,有效提高了研发效率并降低了运维成本[2];Google推出支持分布式训练的TensorFlow深度学习框架有效的提高了单机深度学习模型的训练效率等[3],在学术界以及工业界取得了重大的成果,已经成为各科技公司主流研发方向。本文在前人研究的基础上结合铁路客运营销[4]深度学习平台的需求及特点,将容器云技术与深度学习相结合进行部署,实现了平台资源隔离,动态部署,模型统一化管理等功能,提高了平台的资源利用率,降低深度学习模型的开发周期。
1 相关技术
1.1 深度学习TensorFlow
深度学习计算模型采用多个数据处理层进行训练,在语音识别、图像识别、自然语言处理、分类预测、产品推荐等众多领域发挥着巨大的作用。TensorFlow作为谷歌开源的第二代人工智能学习系统,其创建了神经网络算法库,提供了深度学习模型快速便捷的构建方式[5],受到学术界以及工业界的广泛关注。
目前,铁路客运深度学习平台基于TensorFlow构建,随着铁路客运业务需求及数据样本的复杂化,为保证深度学习模型的有效性,其对应的结构包含的层次越来越多,从而训练速度逐渐成为制约业务预测分析发展的阻力,提高模型训练速度的需求与日俱增。虽然TensorFlow从1.4版本已经提供了分布式并行相关的API,但其仍然具有无法完成资源隔离、缺乏资源调度、样本数据及训练好的模型难以保存、进程遗留、数据读取效率低、扩容难度大等缺点,因此,急需研究并设计一套完善的深度学习平台以提高模型训练速度。
1.2 容器云技术
容器技术近几年得到了快速的发展,已经成为业界广泛使用的服务器资源共享的方式。与传统的虚拟化技术相比,容器技术以应用为中心,与宿主机共用内核,使各应用资源利用率更高,同时各个容器之间资源相互隔离,保障了应用运行的独立性,为应用运行周期的管理提供了便利。
随着容器技术的广泛使用及容器数据的剧增,谷歌开源了Kubernetes[6]为大规模容器的编排提供了方案,可以基于业务需要,动态调整容器数量,实现计算资源的快速扩容或缩减以调整计算资源,提高计算资源的利用率。Kubernetes集群具有容器资源相互隔离、资源灵活调度、容器API接口管理、兼容多种分布式存储系统、创建快捷等优点,能够解决目前铁路客运营销深度学习平台TensorFlow所面临的问题。
2 平台架构设计
2.1 整体架构
基于Kubernetes的客运营销深度学习平台整体框架,如图1所示,主要包括访问控制层、应用服务层、Kubernetes 平台即服务(PaaS)层及物理资源管理层。

图1 基于Kubernetes的客运营销深度学习平台整体架构
(1)访问控制层:支持Http接口接入、SDK登录及SSH登录3种接入方式。对平台中的用户进行鉴权及权限控制,提供统一的用户登录访问接口,获得相应权限的用户可以使用Kubernetes PaaS层相应的服务,包括TensorFlow容器部署、任务提交引擎管理、模型设计等。
(2)应用服务层:主要部署深度学习平台相应的应用程序,包括深度学习框架TensorFlow、内部服务通信模块消息队列MQ、Kubernetes集群管理服务、深度学习模型训练API服务等。
(3)Kubernetes PaaS层:将深度学习平台相关的API服务、消息队列、TensorFlow等应用进行容器化,将其部署到基于Kubernetes的PaaS层中,实现应用服务资源分配、生命周期等统一化管理控制。
(4)物理资源管理层:为PaaS提供硬件计算资源,包括物理机、虚拟机等。
2.2 Kubernetes PaaS平台架构
Kubernetes集群负责平台相关服务的部署及运行,用户可以自定义创建Tensorflow容器云集群、接口访问控制服务集群等,使各个服务环境配置更加简单,方便容器化服务的创建、扩容、管理和更新,在一定程度上起到了负载均衡的作用。
为了保证客运营销深度学习平台安全可靠的运行,Kubernetes集群进行高可用部署,其元数据管理信息存储介质采用ETCD集群模式以解决ETCD单点宕机带来的影响[7],基于深度学习平台的应用方式,Kubernetes中需要运行大量不同种类的容器,容器运行的基本单位为Pod,在Pod中运行的容器之间共享物理机,其架构图,如图2所示。
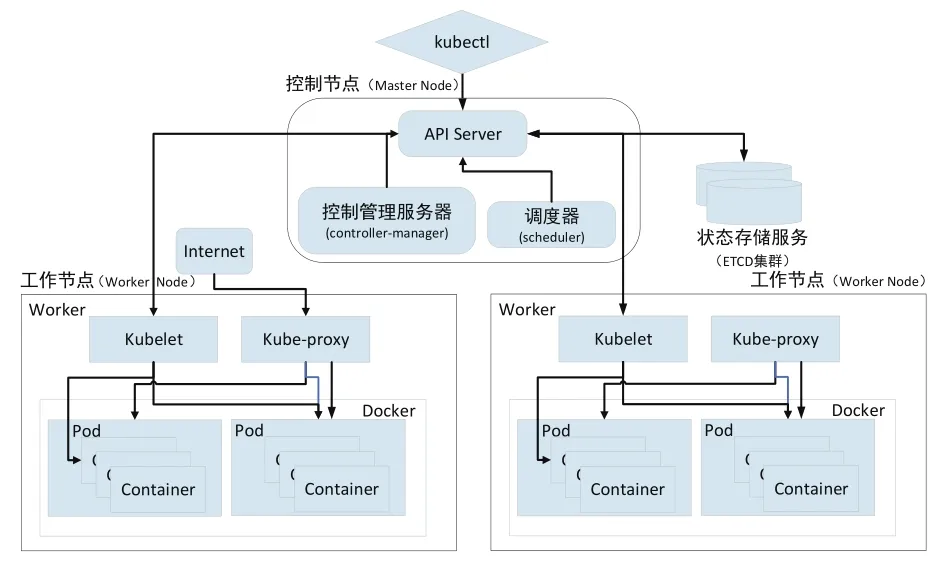
图2 Kubernetes 基本架构
(1)API Server:客户端访问集群 Node、Pod及Service的通道,处理相关业务逻辑并将其相关的结果状态实时保存到ETCD集群中。
(2)ETCD集群:存储Kubernetes集群的状态信息及访问API Server返回的结果状态信息。
(3)Controller-manager:包含多种控制器,实现集群级别的功能,包括生命周期管理、API业务逻辑、服务发现、路由等功能。
(4)Scheduler:基于调度策略经过Node预选,Node优先实现Pod的自动化部署。
(5)Kubelet:负责驱动容器执行层,管理Pod、容器、镜像、数据卷等,实现集群对节点的管理,并实时同步运行状态到API Server。
(6)Kube-peoxy:提供服务到Pod的负载均衡。
3 功能模块设计
基于Kubernetes的客运营销深度学习平台的应用服务层包含多个模块,最主要的是深度学习任务处理引擎,深度学习模型操作API服务,具体功能模块设计,如图3所示。
3.1 深度学习模型操作API服务
深度学习模型操作API服务主要接收经过访问控制层鉴权的用户访问请求,为其提供想用的服务,该服务进行容器化处理并部署到Kubernetes集群中,以容器的形式通过PaaS平台为用户提供模型服务,主要操作流程,如图4所示。
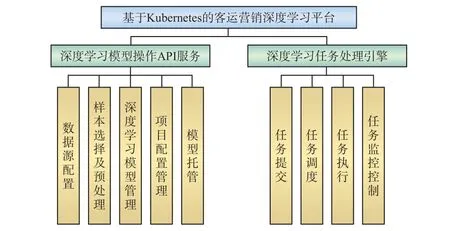
图3 功能模块设计

图4 深度学习模型操作 API服务流程
目前,铁路客运数据存储在多种数据库中,有的数据库与Kubernetes集群兼容性较差,为了满足深度学习平台样本数据的统一化管理,选择与分布式集群TensorFlow兼容较好的HDFS作为样本的存储介质,开发深度学习模型操作数据样本抽取API服务,通过基于Demio的DAAS平台实现样本数据的采集,将其抽取到HDFS中,以实现Kubernetes集群对外部数据的使用。
以ClusterFS作为Kubernetes中高可用的分布式存储主要存储用户提交的TensorFlow模型代码,模型训练的日志、训练模型的导入和导出。ClusterFS分布式存储系统具有良好的扩展性和存储能力,并且与Kubernetes集群兼容性较高,能够部署在Kubernetes集群中,将底层限制的存储资源集中起来提供服务,提高了存储资源利用率。
深度学习模型操作API服务主要包括以下模块。
(1)数据源配置
铁路客运营销数据采用多种类型的数据库,存储不同维度或分区的数据,数据源配置针对不同类型的数据设计统一的管理及访问接口,实现客运营销数据透明访问。
(2)样本选择及预处理
分析业务需求,基于客运营销数据挑选样本数据及样本特征;设计深度学习样本处理引擎及基于不同处理方式的处理器,对样本特征进行预处理,并将其集中存储到统一的数据库中,提高样本数据质量以样本提取速度,从而为模型训练提供数据保障。
(3)深度学习模型管理
针对基于TensorFlow的深度学习进行模块化开发,实现数据处理、模型代码上传、参数控制、优化方案、结果存储等可配置任务构建,提高数据分析工程师模型开发效率。
(4)项目配置管理
针对业务需求及模型训练任务进行管理,包括需求、脚本、配置、任务的管理,基于该模块可以查看平台所有的业务需求及模型训练任务,并对业务需求及任务的新建、修改、删除等提供基本的操作。
(5)模型托管
将平台训练好的模型以gRPC的形式对外提供服务,以减少模型上线周期,综合考虑现有方案,采用Google主导的开源项目TensorFlowServing实现[8],该项目支持多种形式(包括定制)的Serving服务方式,用户只需要编写客户端,通过gRPC调用训练好的模型服务即可获得相应的结果。
3.2 深度学习任务处理引擎
深度学习任务处理引擎是与深度学习框架Tensor-Flow交互的唯一通道,通过深度学习模型操作API服务进行相应的任务提交、任务查询等操作,处理引擎对模型操作提交的信息进行解析并调用Kubernetes中的API Server,并将创建过程及相关数据信息存储到CluserFS中,返回实时的任务信息,主要流程,如图5所示。
深度学习任务处理引擎进行容器化处理并将其部署到Kubernets集群中,其通过Kubernetes集群的API Server动态的创建或者删除TensorFlow深度学习任务,基于提交任务的工作难度通过Controller Manager及Scheduler进行TensorFlow容器的扩容及编排[9]。

图5 深度学习任务处理引擎工作流程
深度学习任务处理引擎主要包括以下模块。
(1)任务提交
对外提供HTTP接口,接收用户提交的模型训练任务,将训练任务的模型类别、样本信息、训练参数等存储到数据库中,并进行任务正确性校验任务以及调度方式选择,将校验通过的任务添加到对应的调度队列中。
(2)任务调度
基于模型训练任务特点,设计不同的任务调度策略以及调度队列,如快速队列、慢速队列等,将队列中的任务进行调度消费,基于不同的策略从队列中获取未执行的任务,并基于任务的特点进行分发,将任务提交到任务执行模块进行处理。
(3)任务执行
基于模型训练任务的特点,将任务拆分成多个子任务,利用Kubernetes虚拟化技术,将拆分后的任务提交到Kubernetes集群中,基于自身需要的资源申请相应的Pod,每个Pod执行一个子任务,保证子任务相互隔离,从而实现模型训练任务的分布式执行,提高资源利用率以及训练速度。
(4)任务监控控制
任务在Kubernets集群中运行的同时,需要利用Kubernetes自带的监控服务,实时采集Event和Pod详细信息至自定义队列中,并对其进行消费解析,对任务可能遇到的问题(如挂载失败、node分配失败等)进行实时监控,基于任务监控采集到Event与Pod信息,任务控制对其进行解析,针对不同的情况设置不通的处理器,将任务的运行状态及相应的Event的信息回传到深度学习模型操作API服务平台,并更新任务状态。
4 验证及结果
为验证该方案的有效性,根据实际情况,选择5台物理机进行部署,其配置如表1所示,主要软件环境为:Kubernetes 2.0,Tensorflow 2.0,Python 3.6 等。
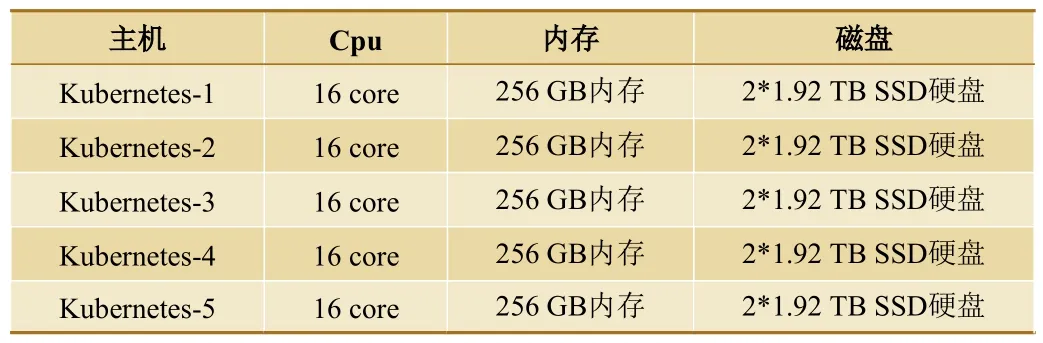
表1 物理机配置
在5台物理机上部署Kubernetes集群,将各个应用以容器的形式部署在Kubernetes集群中。开发基于用户画像系统的高价值用户分析模型,通过深度学习模型操作API服务将样本数据进行处理并提交模型代码到不同的Kubernetes节点。任务提交之后,平台自动创建5个TensorFlow容器节点进行模型训练,同时,本文主要对TensorFlow单机部署及相同环境的分布式部署进行了测试,测试结果,如表2所示。

表2 运行情况对比
综上所述,容器化部署缩短了集群的部署调试时间,减少了TensorFlow分布式节点部署的流程,实现了资源的动态透明调度及所有操作的Http接口服务,为算法工程师简化了操作流程。
5 结束语
本文基于Kubernetes容器技术及TensorFlow深度学习框架进行研究,结合铁路客运业务的特点,设计并实现了一套基于容器的深度学习平台。基于Kubernetes优秀的资源调度及管理框架,实现了TensorFlow深度学习集群,以及其他应用服务的自动化部署、计算资源动态扩容,解决了客运目前面临的数据量大,计算复杂等深度学习问题。实践证明,该平台极大地提高了算法工程师的开发效率和模型的训练速度,具有良好的应用前景。
猜你喜欢
阅读(快乐英语中年级)(2022年11期)2022-05-30 10:48:04
中国特种设备安全(2021年8期)2021-02-10 06:04:48
读者·校园版(2019年24期)2019-12-10 06:44:03
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
上海铁道增刊(2017年3期)2018-01-22 03:01:05
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
汽车与安全(2016年5期)2016-12-01 05:21:59
海峡科技与产业(2016年3期)2016-05-17 04:32:19
