
基于Storm平台的多任务分组调度策略与实现①
2021-02-23 06:30:40王中华柴小丽
计算机系统应用 2021年2期
王中华,柴小丽
(中国电子科技集团公司第三十二研究所,上海 201808)
随着信息科学和云计算技术的飞速发展,智能设备的持续普及,存储设备性能的提升和网络带宽的增长为大数据的存储和流通提供了物质基础,云计算技术通过将分散的数据集中在数据中心,从而可以更为集中有效地处理和分析大数据信息.云计算技术为海量数据存储和分散的用户访问提供了必要的空间和途径[1].大数据主要有4 种计算模式,分别是批量计算,流式计算,图计算和交互计算.其中,适用于大数据分析的计算模式主要是批量计算和流式计算这两种,并且由于批量计算和流式计算针对的数据流类型不同,所适用的大数据应用场景也不一样[2].
批量计算会将先将数据信息统一收集起来,然后把大量的数据信息存储到本地或云端地数据库中,最后对数据进行批量的处理.由此可见,批处理适用的数据一般是静态数据,即保存在本地或云端数据库中的信息,任务可一次性完成.因此,批量计算一般应用在实时性要求不高,离线计算的场景下,进行数据分析或实现离线报表等[3–5].
数据流是一组有序的,有起点和终点的字节的数据序列,一般包含输入流和输出流,在实时通信领域中,数据的价值与时间成反比,即处理数据的时间越短,数据的价值越大.因此,必须对实时的数据信息给出毫秒级的响应.流式计算就是应用在实时场景下,或对时效性要求比较高的场景,如实时推荐,业务监控[6–9].
Hadoop是一个由Apache 基金会开发的分布式系统基础架构,实现了一个分布式文件系统HDFS,提供高吞吐量来访问应用程序的数据,适合有着超大数据集的应用程序,HDFS为海量数据提供存储,MapReduce为海量数据提供计算[10].Apache 开发Flink 开源流处理框架,核心是用Java和Scala 编写的分布式数据流引擎,Flink 通过支持数据并行和流水线方式,可执行任意流数据程序[11],Flink的流水线运行方式支持系统执行批处理和流处理程序,同时支持迭代算法的执行.Twitter 开发了Storm 框架提供分布式的,高容错的实时计算系统,支持多语言:Java,Python,Ruby 等[12],可实现亚秒级的低延迟.Storm 提供较高的可靠性,所有信息都可保证至少处理一次,确保不会丢失信息.
由于在项目研发过程中,需要8 台机器对视频流执行解码任务,另外8 台执行目标识别的推理任务,并且由于两组机器都缺乏硬件条件完成其他任务.传统的平均分配和单机任务指定策略不能满足项目需求,本文通过设计新调度算法来实现对两组机器的任务分配.
1 Storm 模型架构
如图1所示,Storm 集群采用主从式架构,集群中的节点主要分为以下4 类[13]:
主节点(Master node):通过运行Storm nimbus 命令启动Storm的主节点,nimbus是Storm 系统的主控节点,主要用于向集群中提交作业,通过读取ZooKeeper的工作信息分配集群的任务,以及监控整个集群状态(有进程级的也有线程级别的).
工作节点(Worker node):通过运行Storm supervisor命令启动Storm的工作节点.通过设定的端口与Zoo-Keeper 进行信息交互,读取主控节点分配的任务信息,下载作业副本,管理属于自己的Worker 进程,如启动,暂停或撤销任务的工作进程及其线程.一个工作进程中可运行多个线程,每个线程中又可运行多个任务(task).
控制台节点(Web console node):通过运行Storm ui 命令启动用户界面服务节点,默认的服务端口号为8080,可在storm.yaml 中设定ui.port 进行修改.可以在ui 界面上查看已提交的作业状态,包括集群的整体状态,已使用的节点数,每个节点的运行情况和作业的执行状态,支持手动停止正在执行的作业.
协调节点:通过运行ZooKeeper server start 命令启动ZooKeeper 进程的节点,实现numbus和supervisor之间的协调管理,包含分布式状态维护和分布式配置管理等.

图1 Storm 模型架构
2 ZooKeeper
Storm 使用ZooKeeper 来保证集群的一致性.Storm的所有的状态信息都是保存在ZooKeeper 里面,nimbus通过在ZooKeeper 上面写状态信息来分配任务[14].
Supervisor,task 通过从ZooKeeper 中读状态来领取任务,同时supervisor,task 也会定期发送心跳信息到ZooKeeper,使得nimbus 可以监控整个Storm 集群的状态,从而可以重启一些停止的task.
在每台机器上设置myid 文件来分配机器在集群中的id,如图2所示,51 表示式第几台服务器,10.0.0.1表示服务器的IP 地址,2888:3888 表示服务器中与集群中leader 交换信息的端口.
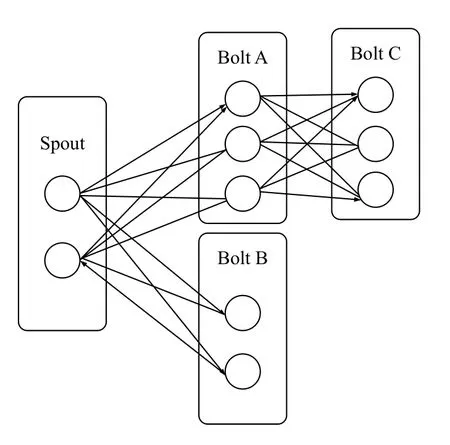
图2 拓扑结构
3 Topology 结构
Topology是Storm 中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构[15],如图2所示.主要由以下几部分组成:
Spout:在一个topology 中产生源数据流的组件.通常情况下spout 会从外部数据源中读取数据,然后转换为topology 内部的源数据.Spout是一个主动的角色,其接口中有个nextTuple()函数,Storm 框架会不停地调用此函数,源源不断地发送数据.Spout 另一个重要的方法时ack和fail,Storm 监控到tuple 从spout 发送到toplogy 成功完成或失败时调用ack和fail,保证数据的可靠性.
Bolt:在一个topology 中接受数据然后执行处理的组件.Bolt 可以执行过滤,函数操作,合并,写数据库等任何操作.Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作[16].
Tuple:Storm spout,bolt 组件消息传递的基本单元(数据模型),Tuple是包含名称的列表,Storm 支持所有原生类型,字节数组为Tuple 字段传递,如果要传递自定义对象,需要实现接口serializer[17].
Stream:源源不断传递的Tuple 就组成了stream.
4 任务调度
4.1 传统任务调度
Storm 集群默认的调度器是EventScheduler[18–21],采用轮询策略来搜索集群中所有拓扑结构的工作节点,将资源较为均匀的分配给任务进程.具体分配流程如下:
先由nimbus 来计算拓扑的工作量,及计算多少个task,task的数目是指spout和bolt的并发度的分别的和nimbus 会把计算好的工作分配给supervisor 去做,工作分配的单位是task,即把计算好的一堆task 分配给supervisor 去做,即将task-id 映射到supervisor-id+port 上去,具体分配算法如算法1.
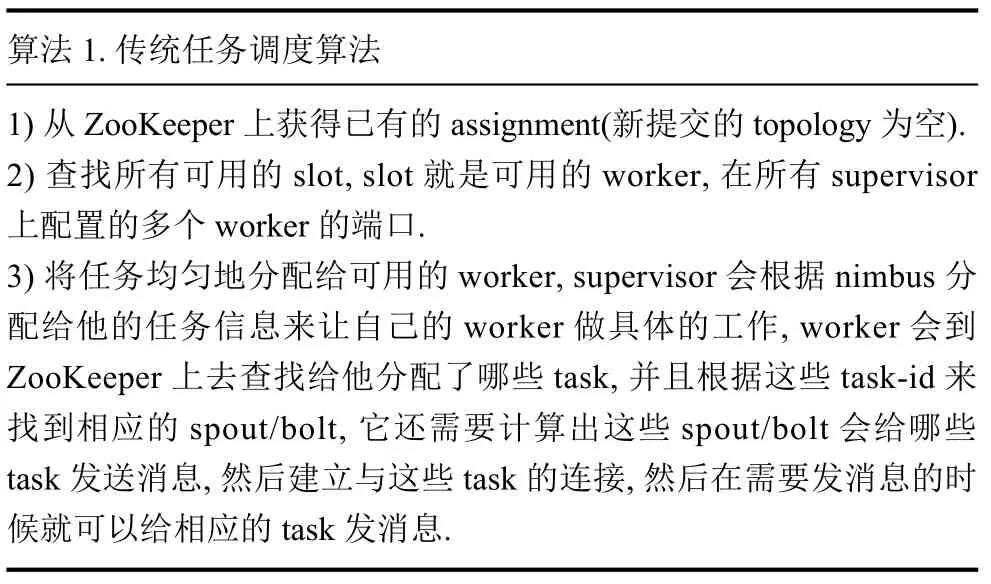
算法1.传统任务调度算法1)从ZooKeeper 上获得已有的assignment(新提交的topology为空).2)查找所有可用的slot,slot 就是可用的worker,在所有supervisor上配置的多个worker的端口.3)将任务均匀地分配给可用的worker,supervisor 会根据nimbus 分配给他的任务信息来让自己的worker 做具体的工作,worker 会到ZooKeeper 上去查找给他分配了哪些task,并且根据这些task-id 来找到相应的spout/bolt,它还需要计算出这些spout/bolt 会给哪些task 发送消息,然后建立与这些task的连接,然后在需要发消息的时候就可以给相应的task 发消息.
4.2 多任务分组调度策略
而在当前项目应用过程中,需要将视频解码和目标识别任务分别运行在两组机器上,并且由于任务的硬件需求,解码的任务不能在处理目标识别的机器上运行.
为了实现多任务分组调度,实现了算法2.

算法2.多任务分组调度算法1)从ZooKeeper 上获得已有的assignment(新提交的topology为空).2)在配置集群时为每台机器设置supervisor 名称,如下图所示,通过supervisor.scheduler.meta 设置节点名称.3)采用循环的方式,通过判断meta.get(“name”)==”supervisor51”或meta.get(“name”)==”supervisor52”等得到匹配的supervisor 列表.4)通过componentToExecutors.get("decode")获得解码任务的线程数.5)通过getAvailableSlots 函数提取上述指定supervisor的所有可用节点.6)构建map<WorkSlot,List<ExecutorDetails>>将可用节点与线程情况相匹配.7)通过cluster.assign 函数将匹配情况提交给集群,集群将按照对应关系分配线程,其余任务采用平均分配,由于已经将解码机器组的可用节点全部占满,剩余的推理任务将自动均匀地分配到推理机器组.
5 实验环境与结果
5.1 实验环境
实验共使用16 台服务器,且均使用Linux 系统,其中8 台服务器作为视频解码组,搭载Arm v8 多核处理器和中科睿芯解码卡;另外8 台服务器作为推理组,搭载Arm v8 多核处理器和寒武纪MUL100 加速卡.
Storm 集群由1 个nimbus和16 个supervisor 节点组成(为了实现资源充分使用,其中一个服务器既作为nimbus 用来分发任务和监控集群状态,也用来处理任务).
拓扑结构:
Spout:用于读取视频文件作为输入,组件命名为filename-reader,共8 个线程;
Bolt1:用于实现视频解码任务,组件命名为decode,共23 个线程;
Bolt2:用于实现推理任务(目标识别),组件命名为inference,共32 个线程.
5.2 实验结果
(1)任务分配情况
由表1可知,视频解码组同时执行文件读取和视频解码任务,推理组全部执行推理任务(目标识别),具体ui 结果如图3所示.其中,在视频解码组中预留一个节点,用于预防解码任务时可能出现的节点阻塞.
(2)作业执行情况
由图4知整体拓扑的数据处理情况,10 分钟时处理了48 685 条数据,3 小时处理了872 481 条数据.整个拓扑运行24 小时并未发生中断,可见调度算法的稳定性.
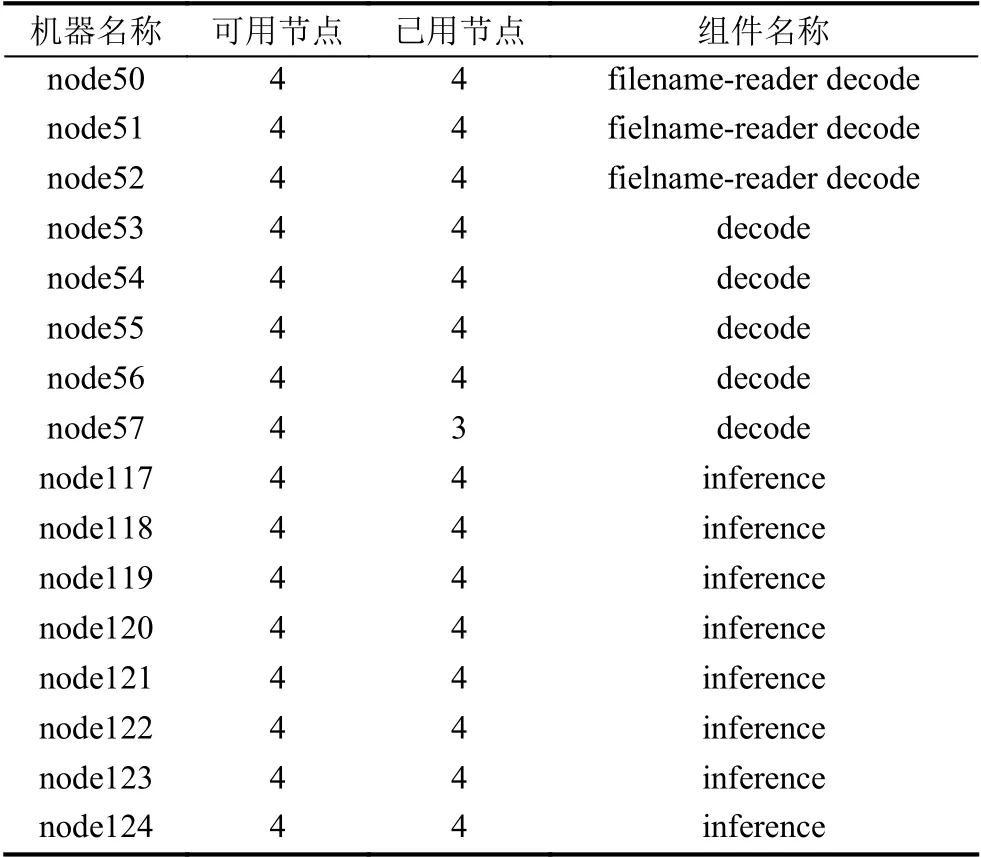
表1 集群任务分配情况
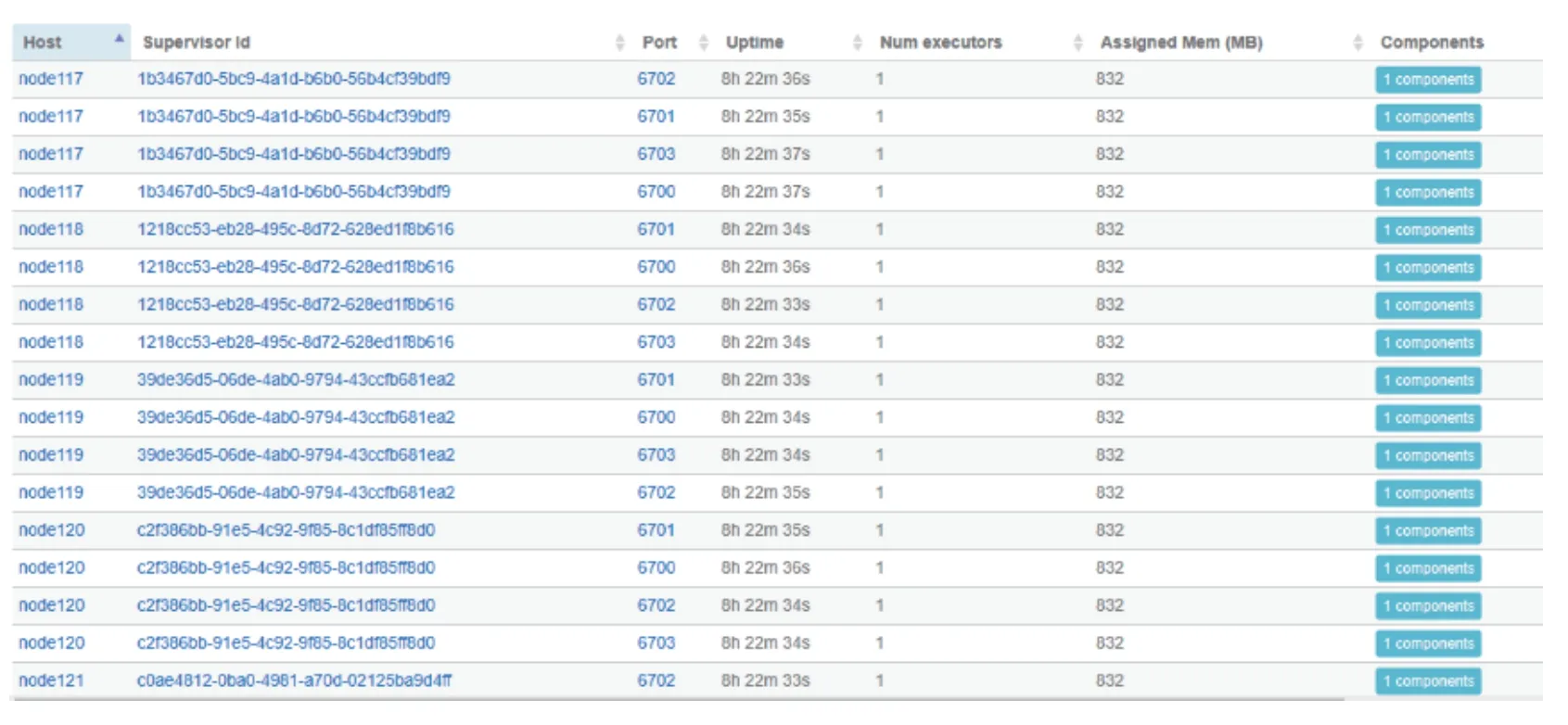
图3 多任务分组调度结果
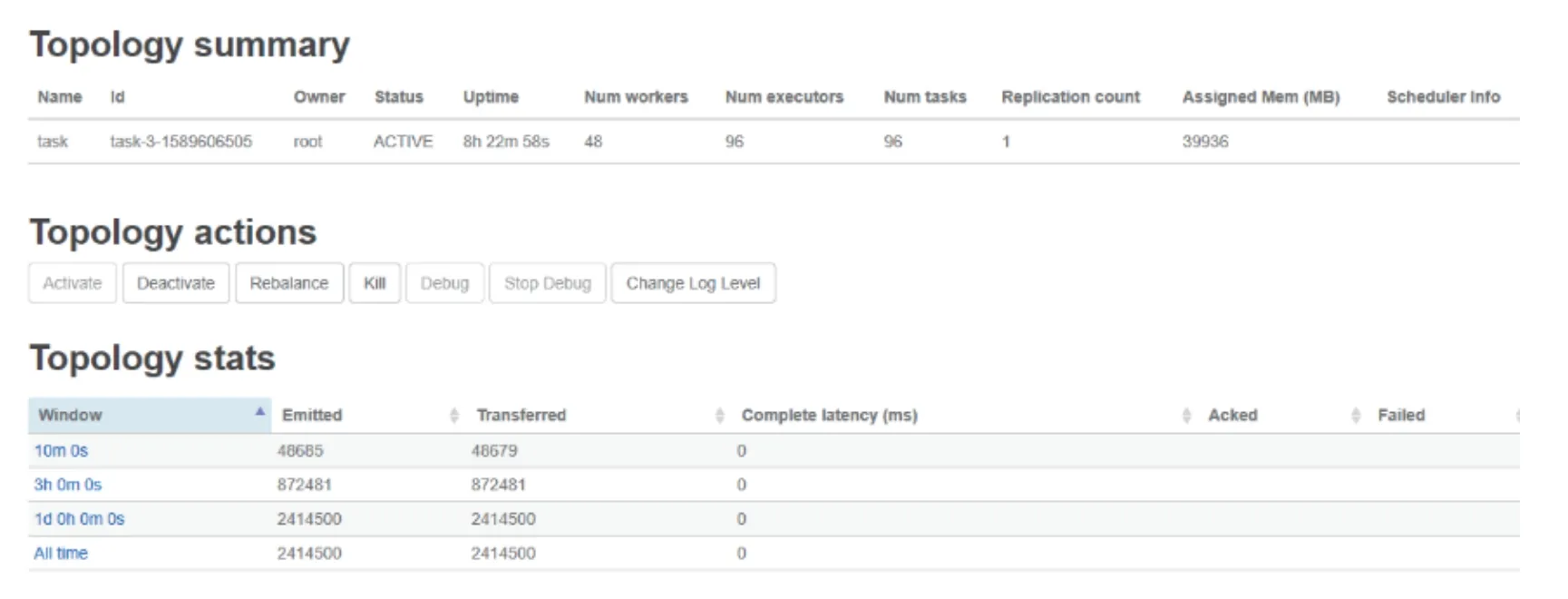
图4 作业执行情况
6 结束语
本文研究了Storm 环境下,多任务在两组机器上分别运行并存在信息交互的情况,提出了多任务分组调度策略,该机制可以将存在不同需求的两个任务分别分配到对应的机器群组中,以达到运行和资源分配最优情况.实验证明,该调度机制可实现视频解码和推理任务的分组运行,并且通过持续运行拓扑24 小时,验证了该调度机制的稳定性.后续的工作将继续完善该调度机制,当存在3 个或更多任务需要指定机器群组资源运行时,能够实现多个指定任务分配到指定机器群组中,以实现资源的正确分配与最优分配.
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
中国外汇(2019年19期)2019-11-26 00:57:32
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
环球市场(2017年36期)2017-03-09 15:48:21
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
计算机工程(2014年6期)2014-02-28 01:26:17
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
