
基于改进YOLOv3的自然场景人员口罩佩戴检测算法①
2021-02-23 06:30程可欣王玉德
计算机系统应用 2021年2期
程可欣,王玉德
(曲阜师范大学 物理工程学院,曲阜 273165)
佩戴口罩是一种隔离和遏制新型冠状病毒、预防新冠肺炎的有效方法.为保护人民的身体健康与生命安全,最大限度地降低和消除因疫情对生产经营造成的影响,需要对复产复工人员规范佩戴口罩进行的监督和提醒.依靠肉眼观察是否佩戴口罩,不仅耗费人力物力,而且有极大的漏检风险和近距离接触的感染风险,因此,需要一种基于图像处理的高精度高速度的口罩佩戴检测算法.
牛作东等提出了一种改进RetinaFace的自然场景口罩佩戴检测算法,该算法基于ResNet-152 网络,FPS(每秒传输帧数,Frames Per Second)较低,不适用于实际的检测环境[1].YOLOv3 算法利用回归思想,通过CNN 网络一次性生成目标位置边框和目标类别,这种方式使得检测速度更快、模型泛化能力强,同时可以减少背景错误产生,因此本文选择该方法进行检测.国内对该方法已有了成熟而广泛的应用,如郑秋梅等在交通场景上使用该方法进行车辆检测[2],王毅恒等使用该方法对农场环境下的奶牛进行检测[3],孟本成等使用该方法对行人进行检测[4]等.YOLOv3 算法虽然检测速度快,但小目标漏检的风险相对更高,鉴于上述问题,本文提出改进目标边框损失的YOLOv3算法对自然场景下人员是否佩戴口罩进行检测,更好地做好人员防护.
1 基本原理
YOLOv3 算法是Redmon 等在2018年提出的[5],改进了网络结构、网络特征及损失计算3 个部分,在保持速度优势的前提下,进一步提升了对小目标的检测能力和检测精度.
1.1 DarkNet-53 网络
YOLOv3 结构由骨架网络DarkNet-53和检测网络两部分组成,用于特征提取和多尺度预测[6].YOLOv3网络结构如图1.
DarkNet-53 网络共有53 层卷积层,最后一层为1×1 卷积实现全连接,主体网络共有52 个卷积.52 个卷积层中,第一层由一个32 个3×3 卷积核组成的过滤器进行卷积,后面的卷积层是由5 组重复的残差单元(resblock body)构成的,这5 组残差单元每个单元由一个单独的卷积层与一组重复执行的卷积层构成,重复执行的卷积层分别重复1、2、8、8、4 次;在每个重复执行的卷积层中,先执行1×1的卷积操作,再执行3×3的卷积操作,过滤器数量先减半,再恢复,共1+(1+1×2)+ (1+2×2)+ (1+8×2)+ (1+8×2)+(1+4×2)=52 层.
YOLOv3 模型的输出为3 个不同尺度的特征层,分别位于DarkNet-53 网络的中间层、中下层和底层,用于检测不同大小的物体.如图1所示,对3 个特征层进行5 组卷积处理,可输出该特征层对应的预测结果.
1.2 网络性能分析
DarkNet-53 特征提取网络通过大量的3×3和1×1 卷积层构成,该网络在ImageNet 数据集下测试,网络性能比ResNet 网络更好[3],结果如表1.
通过表1我们可以看到,在图像分类的准确率以及检测速度等方面,DarkNet-53 网络与其他3 种网络模型相比,表现更加优越.DarkNet-53 网络在满足检测实时性的同时比DarkNet-19 具有更高的精度,并且在网络性能相差无几的情况下,网络的速度约是ResNet-152 网络的2 倍.
2 损失函数改进
2.1 GIoU 损失函数
在原始YOLOv3 算法中,使用均方误差作为目标定位损失函数来进行目标框的回归,均方误差函数对尺度较为敏感,并且无法反应不同质量的预测结果,故大量使用YOLOv3 算法的工作中,常使用预测框和真实目标框的IoU 值来衡量两个边界框之间的相似性,虽然改善了这两个问题,却也带来了新问题.首先,当预测框和真实框之间没有重合时,IoU的值为0,导致优化损失函数时梯度也为0,意味着无法优化.其次,即使预测框和真实框之间相重合且具有相同的IoU 值时,检测的效果也具有较大差异.
Rezatofighi 等于CVPR2019 上提出了GIoU(Generalized IoU,广义IoU)目标边界框优化方法,GIoU针对IoU 无法反应不重叠的两个框之间距离和重叠框对齐方式的问题进行了优化,图2中3 幅图的IoU 均为0.33,GIoU的值分别是0.33,0.24和−0.1,这表明如果两个边界框重叠和对齐得越好,那么得到的GIoU 值就会越高[7].
图2中黑色框为真实框A,灰色为预测框B,虚线框为最小可包含A、B的框C.假设有框A和B,总可以找到一个最小的封闭矩形C,将A和B 包含在内,然后计算C 中除了A和B 外的部分的面积占C 总面积的比值,再用A 与B的IoU 减去这个比值,IoU 计算公式和GIoU 计算公式如式(1)、式(2)所示.
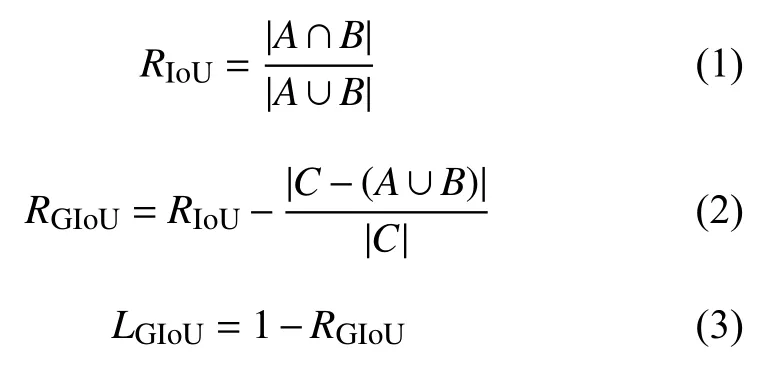
GIoU 与IoU 类似,可以作为一种距离度量,损失可以由式(3)计算.GIoU 对物体的大小并不敏感,其值总是小于等于IoU,是IoU的下界.在两个形状完全重合时,GIoU和IoU 大小均为1.GIoU 引入了包含框A和B 两个形状的C,解决了IoU 不能反映重叠方式,无法优化IoU为0的预测框的问题.al
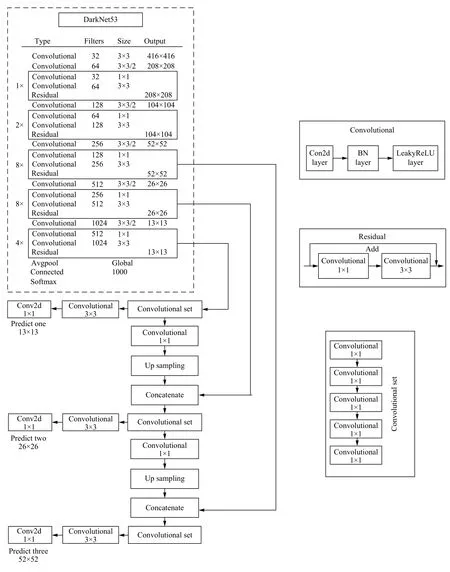
图1 YOLOv3 网络结构(含DarkNet-53)

表1 4 种网络框架性能对比
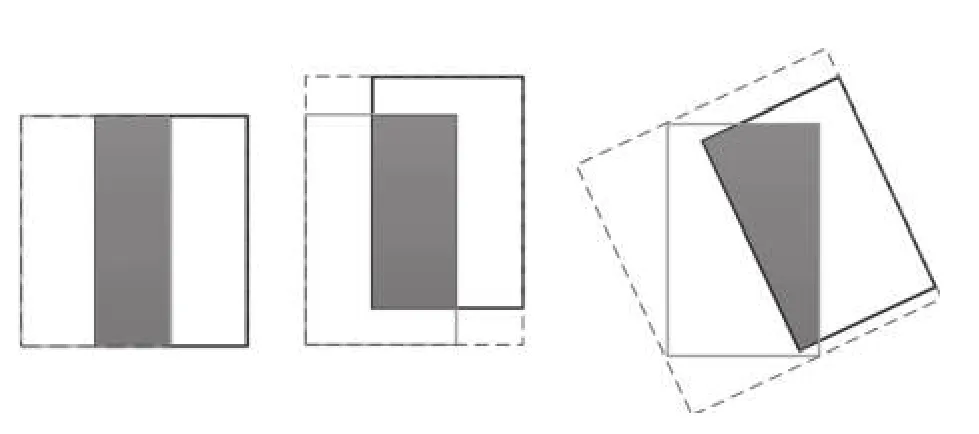
图2 IoU 均为0.33 时3 种不同的重叠情况
2.2 Loss 损失计算
本文将LGIoU损失函数应用于YOLOv3 目标检测算法中,以LGIoU直接作为边界框回归损失函数代替原来的均方差和损失函数.
损失函数的公式包含目标定位损失、目标置信度损失和目标类别损失3 个部分,分别对应式(4)中的第一项、第二、三项和第四项.
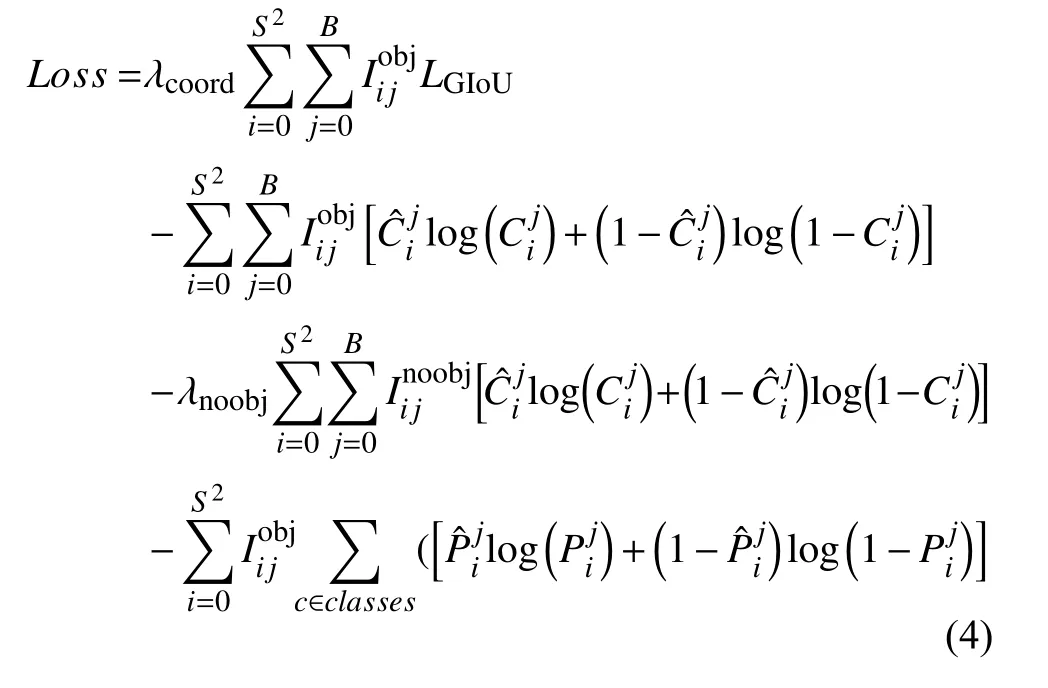
3 算法流程
该算法流程主要分为特征提取和多尺度预测两部分,图片经过DarkNet-53 网络,生成3 种尺度的特征图,每种尺度的特征图划分为大小不同的网格,每个网格预测3 个先验框,经过非极大抑制等,得到预测框,在训练过程中,还会进行损失函数计算,更新权重.
4 实验与结果分析
实验用计算机配置为Intel Corei5-5200 2.20 GHz CPU、Tesla V100-SXM2 GPU,显存16 GB.软件环境为Linux 操作系统、PyCharm2019.3.3、PyTorch 框架.
文中使用了AIZOO 团队公开的人脸口罩佩戴数据集,该数据集中的图片来源于WIDER FACE 数据集[8]和中科院信工所葛仕明老师开源的MAFA 数据集[9],图片示例如图3,对应的标注数据如表2.训练样本与测试样本按0.7:0.3 划分,训练集共5566 张图片,来自MAFA的图片2873 张(基本都是戴口罩的图片)、WIDER Face 图片2693 张(基本都是不戴口罩的图片).验证集共2385 张图片,取自MAFA 1188 张、WIDER Face 1197 张.
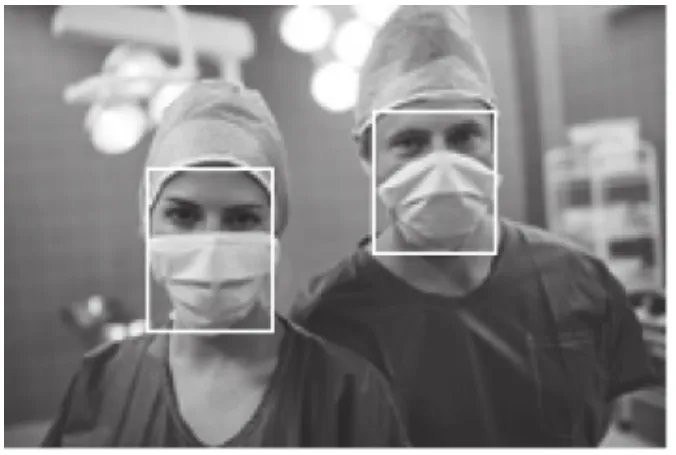
图3 数据集示例图片

表2 示例图片标注数据
采用迁移学习的方式,采用了ImageNet 预训练好的模型参数,通过初始化模型前47 层卷积层参数、微调末端参数的方式对模型进行训练,将检测类别按是否佩戴口罩调整为2 种、初始学习率设置为0.01、batchsize为16.
从图4–图6可以看出,使用GIoU 作为目标边界框损失函数总是小于IoU,该结果符合GIoU的特点,平均检测精度(mAP)上升速度更快且有小幅度的提高.在使用GIoU的条件下,训练迭代次数到达50 次后,mAP曲线渐趋平缓,最后达到88.4%左右不再增加,而GIoU一直平稳下降至0.93,目标定位损失下降至0.315,目标分类损失下降至0.0361.验证集数量少后期易出现过拟合现象,故迭代次数达到100 次时停止训练.
GIoU 作为目标边界框损失函数的训练模型,多目标检测的平均精度达到88.4%,佩戴口罩的类别达到96.5%,检测结果如表3,与IoU 相比均有提高.
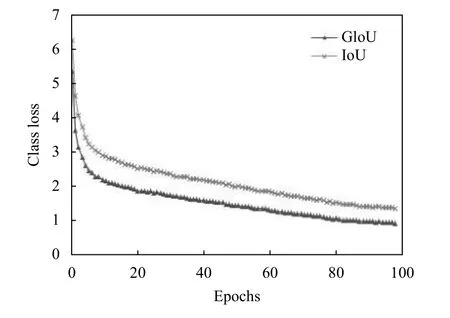
图4 GIoU 与IoU 训练过程曲线
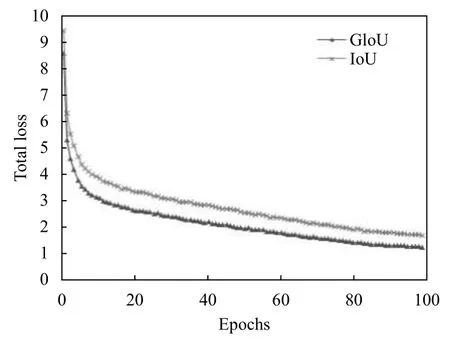
图5 使用GIoU 与IoU的YOLOv3 总损失函数训练过程曲线
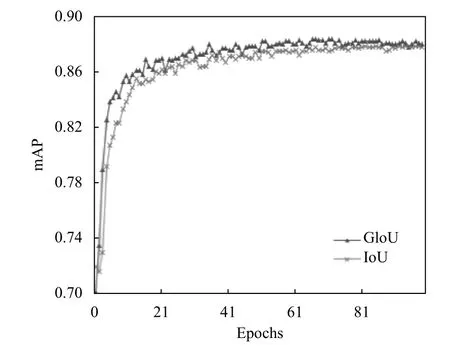
图6 GIoU-YOLOv3 与IoU-YOLOv3 mAP 训练过程曲线

表3 不同类别使用GIoU和IoU的mAP 对比
图7(a)为GIoU-YOLOv3 测试结果,图7(b)组图片为IoU-YOLOv3 测试结果.从测试结果可见GIoUYOLOv3 算法针对小目标的漏检率有明显降低.

图7 未戴口罩和佩戴口罩的检测图像
图8为从网络随机爬取的512×320 大小416 帧的视频的测试结果,共用时10.751 s,平均每帧用时0.026 s,FPS 达到38.69,满足实时检测的要求.
5 结论
论文提出改进检测目标边框损失的自然场景人员口罩佩戴检测算法,在一定程度上减小了漏检率,mAP也有一定的提高.该方法平均每秒检测约38 张图片,可以实现实时检测.同时,对佩戴口罩类别的检测准确率可达96.5%,行人是否佩戴口罩的mAP 达到了88.4%.在多目标检测上有较好的表现,检测速度更快、成本更低、准确率更高.

图8 视频测试结果部分截取
猜你喜欢
今日农业(2022年15期)2022-09-20
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小天使·二年级语数英综合(2019年10期)2019-11-08
作文大王·笑话大王(2019年3期)2019-04-22
读者·校园版(2015年19期)2015-05-14
