
基于BIG-WFCHI的微博信息关键特征选择方法①
2021-02-23 06:30殷仕刚蔡欣华屈小娥
计算机系统应用 2021年2期
殷仕刚,安 洋,蔡欣华,屈小娥
1(西安理工大学 信息化管理处,西安 710048)
2(西安理工大学 计算机科学与工程学院,西安 710048)
目前,作为现实社会网络的延伸,微博平台已经成为网民表达意见、交流信息的热门网站平台.据中国互联网络信息中心(CNNIC)第45 次《中国互联网络发展状况统计报告》显示[1],微博是我国三大社交应用之一.在抗击新冠肺炎疫情过程中,上亿用户通过微博关注最新疫情、获取防治服务、参与公益捐助.截至2020年2月4日,微博热搜榜上疫情相关话题的占比超过60%.显然,新兴媒体已经渗透到我们的生活中,给我们的信息获取和社会互动带来了巨大的变化.然而,由于缺乏对内容的即时审查,虚假信息极易产生和迅速传播,给社会带来负面影响.因此,准确、有效地预测微博的传播范围,对于防止虚假信息传播具有重要意义.
利用机器学习方法预测微博传播范围的前提是提取微博转发特征.因此,选择有效的特征是提高预测精度和效率的关键步骤,通过选择有效的特征可以在不损失处理速度和性能的前提下消除不相关和冗余的特征.
通过对文献[2,3] 实验结果的分析,发现:1)IG和CHI 方法表现良好,表明高频词有利于分类;2)相反,MI 有效性较差的原因在于其固有的低频词优势,这一缺陷导致了预测能力差和学习能力差[4].代六玲等[5]在研究中也发现将单一的方法进行组合应用可以提高特征选择的准确率,并大幅度缩短分类训练时间.李玉鑑等[6]将DF 和CHI 相结合不仅保留了CHI 方法能够考虑特征词项与类别相关的优点,而且利用文档频率DF 值来去除掉低频词,降低了CHI 对低频特征词的权重,增强了对关键特征的识别能力.Qian 等[7]将信息理论与集合论理论相结合,解决了特征选择中的不完全数据问题,但分类数据与数值数据的共存却悬而未决问题.Wang 等[8]进一步发现,为了克服CHI 的缺陷,CHI 常常与词频等其他因素相结合.Guyon 等[9]也发现IG 受到冗余相关特征的影响.
通过以上分析,发现直接简单的将DF 和CHI 进行结合很难去除冗余特征.相反,它甚至可以忽略低频词的关键特征.本文对传统IG 和CHI 特征选择方法进行了研究分析,针对IG 算法低频特征词对运算结果产生干扰的问题,引入平衡因子进行调节;针对CHI 算法存在的负相关问题,引入词频因子来提高算法准确率.在此基础上,根据微博信息传播特点,结合改进的IG和CHI 算法,提出了一种基于BIG-WFCHI (Balance Information Gain-Word Frequency CHI-square test)的特征选择方法.最后,以2017年微博数据和Reddit 社区数据,测试BIG-WFCHI 的性能.实验结果表明BIGWFCHI 特征选择方法能够提高信息分类准确率,且降低了运算时间和成本.
1 BIG-WFCHI 微博信息关键特征选择方法
1.1 信息增益
在信息论中,熵表示信息中包含的平均信息量.对于特征,熵度量它们对分类的有用程度.假设特征t有m个可能值,v={v1|v2|…|vm},pi(i=1,2,…,m)是vi的概率,那么t的信息熵可以定义为:

其中,较低的熵表示更简单的分布.注意,熵为0 意味着所有的样本都有相同的值.相比之下,熵越大表明无序分布越多.当特征分布均匀时,在log2m处达到最大熵.
信息增益是根据系统的原始熵与系统具有固定特征的条件熵之差定义的,它描述了特征的信息量.一般来说,一个特征越不确定,它包含的信息就越多.特征t的IG 定义为式(2)[3,10].
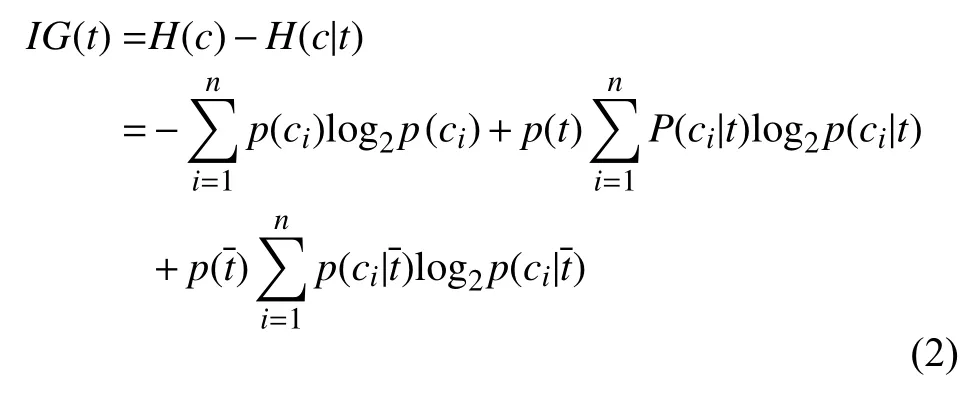
其中,p(ci)表示类别ci的出现概率,对于特征t和类别集C={ci,i=1,2,…,n},IG 利用类别ci中t出现(p(t))和不出现的概率来度量其在C上的信息增益,因此,较大的信息增益表示t对C的贡献较大,这使得IG 方法更有可能选择信息增益较大的特征到一个类别.
1.2 卡方检验
卡方检验(CHI-square test)[6]又称为χ2检验,是检验特征是否服从某一理论分布或假设分布的假设检验之一,属于自由分布的非参数检验.
其基本思想是,首先假设H0是真的,然后基于H0计算χ2来描述观测值与期望值之间的差距.利用χ2分布和自由度,可以得到当前统计量在H0下的概率p.
卡方检验可以用来衡量特征t和类别ci之间的相关性.假设t和ci服从单自由度的χ2分布.其中,N表示数据集的大小;B表示ci中具有特征t的子集的大小;D表示ci中不具有特征t的子集的大小;L表示ci中不具有特征t 的子集的大小,M表示ci中不具有特征t的子集的大小.ci中特征t的χ2值为:
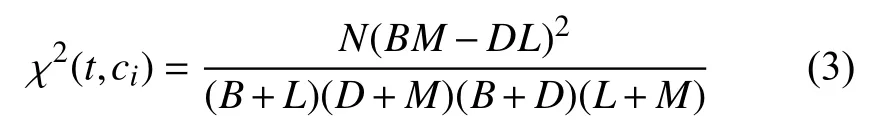
当χ2(t,ci)=0 时,特征t和ci是独立的,χ2的值越大它们的相关性越强.
对于多类问题,首先计算t和ci的χ2值,然后分别在整个数据集上测试特征t的χ2值.
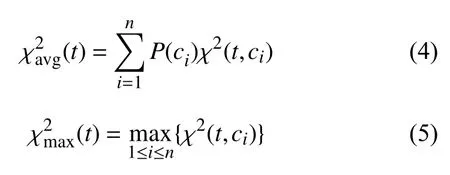
其中,n表示类别数.式(4)是分类特征的平均χ2值,式(5)是最大值.根据χ2值得到排序后的特征列表,然后根据排序后的列表选择特征.
1.3 基于BIG-WFCHI 的微博信息关键特征选择算法
信息增益和χ2方法只计算整个数据集中每个特征的频率,而不考虑特定类别的特征(转发/不转发).这两种方法只关注具有一定特征的微博数量,而不关注特定类别微博的频率.这夸大了低频特征的作用,导致分类精度下降[11].
因此,除了使用基于微博数量的统计方法外,还需要考虑所有类别特征的概率分布,本文引入词频因子E作为标准度量,它表示出现在一个类别中的特征的总频率.
设在微博数据集中,属于类别Ci的微博是d1,d2,…,dn,特征t微博dk(1≤k≤n)中出现的次数为fik(t),特征t在Ci中出现的次数为fi(t).词频因子E为特征t在某类Ci中出现的总词频,如式(6)所示.
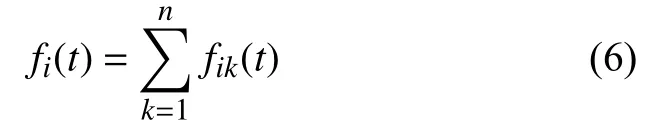
除了上述导致结果不理想的原因外,传统的信息增益方法更有可能选择在一个特定类别中出现较少而在其他类别中出现较多的特征,而不是在一个特定类别中出现较多而在其他类别中出现较少的有价值特征.为了解决这个问题,需要设置一个平衡因子,以确保当一个特定类别的无关特征(或受影响较小的特征)发生时,该参数变为负值或非常小的正值,表明该特征具有负相关性或贡献较小.平均值可以是一个简单有效的标准来衡量特征对类别的影响.因此,本文引入平衡因子F为:

平衡因子F为分类Ci中包含特征t的微博数与各分类出现特征t的微博平均数的差值,如式(7)所示.其中,d fi(t)为在分类Ci中包含特征t的微博数;为数据中各分类出现特征t的微博平均数,=n为数据集的分类个数.
通过式(2)、式(6)和式(7)得出:

因此,IG 避免忽略特定类别中的特征频率,并选择在特定类别中出现较少但在其他类别中出现较多的特征.
从式(3)可以看出,D和L变大,而B和M变小.即DL>BM,这意味着由于特定类别的频率较低,特征的统计值被夸大.因此,这些非最优特征更有可能被选择.这就是所谓的负相关[12].为了克服这个问题,如式(9)所示,对式(3)进行限定.

基于上述对IG 和CHI 特征选择方法优缺点的分析,结合两个引入的词频因子E和平衡因子F,提出一种基于BIG-WFCHI 特征选择算法.其计算方法如式(10)所示.
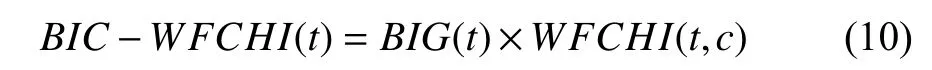
为了更加准确的描述BIG-WFCHI算法,引入以下两个定义:BIG-WFCHI离散度和BIG-WFCHI特征类间差值.
定义1.BIG-WFCHI 离散度,记为DpBIG-WFCHI,表示每个类别中特征BIG-WFCHI(以下简称IC)值的分散程度,用式(11)中的Dp表示.

其中,m表示特征总数,n表示类别数量,ICij表示第i个特征在第j个分类的BIG-WFCHI值,为第i个特征在所有类中ICij的平均值.
BIG-WFCHI离散度可以用来测量特征的冗余度.具有较大BIG-WFCHI离散度的特征具有较强的识别能力,即它们对分类更具价值.
定义2.BIG-WFCHI 特征类间差值,记为Df表示在类间最大IC值与第二IC值的差值,如式(12)所示.
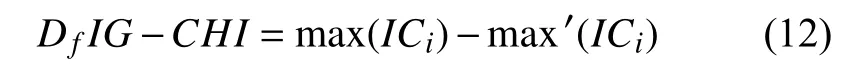
其中,max(ICi)表示第i个特征在指定类中最大的BIG-WFCHI值,m ax′(ICi)表示第i个特征在指定类中第二大值.Df值越大说明特征越特征在特定类别中的分布越密集.也就是说,这个特征对分类更为关键.
利用Dp和Df进一步分析特征的冗余度,可以减少特征的维数,去除冗余特征,缩短运行时间.
BIG-WFCHI 算法的主要步骤如算法1.
在这里,本文利用E和F来减少低频特征和负相关引起的干扰,然后根据Dp和Df选择特征.不同的数据集需要不同的阈值Ɛp和Ɛf,其中极小的数据集不利于选择,而较大的数据集去除了一些关键的分类特征.本文分别以Dp和Df的平均值作为阈值Ɛp和Ɛf.
2 实验分析
2.1 数据集与实验环境
本文采用2017年新浪微博数据为实验数据集,并以Reddit 社区的“披萨随机行为”为样本1,测试BIGWFCHI 的通用性.这两个数据集分别命名为WBdataset和PZdataset.它们的属性如表1所示.

表1 实验数据集
由于WBdataset 和PZdataset 中只有两种状态:retweeted 和not retweeted,successful 和not successful,因此本文将预测视为二值分类.通过分析WBdataset和PZdataset 的数据记录,分别提取了20 个原始特征[13].采用IG,CHI,BIG-WFCHI,TF-IDF[14,15]分别从这两个原始特征集中选择在每个方法中贡献大多数值的前10 个特征作为主要特征.
为了验证BIG-WFCHI 方法的有效性,本文选取了LIBSVM(SVM)[16]、MaxEnt(ME)[17]、Naive-Bayes分类器(NBC)、K 近邻(KNN)和多层感知器(MLP)5 种分类器.这些分类器通常用于机器学习,它们的分类结果在效果上有所不同[17–20].在此,本文简要说明了这些方法的主要参数选择.考虑到数据集是稀疏矩阵,本文选择SMO[19]作为优化算法,在LIBSVM 中选择RBF 作为核函数,使得数据集有更好的性能.在KNN中,k的值是通过交叉验证确定的,得到的最佳结果介于100 到150 之间.由于一个分类模型的精度不是本文研究的重点,所以在MLP 中只设置了一个隐藏层.
2.2 实验结果与分析
实验中采用10 倍交叉验证.对于每个特征选择方法、分类器和数据集,我们执行10 次运行,然后报告结果的平均值、标准差和弗里德曼检验.
表2显示了4 种特征选择方法的精度.最高的分类精度用粗体加下划线和突出显示.从表2可以看出,本文提出的方法在支持向量机、KNN、NBC 和MLP上达到了最佳的精度.该方法在基于ME 的PZdataset和WBdataset 上分别取得了最佳精度和次优精度.
在10 倍交叉验证中,由于每次运行时都会更改训练数据集和测试数据集,因此分类精度会有所不同.为了显示精度之间的差异,表3中执行了10 次运行的标准差.结果表明,在两个数据集上,基于BIG-WFCHI 的分类精度标准差在KNN 中是最小的.在其他分类器中,基于BIG-WFCHI 的标准差也是小的有理数.
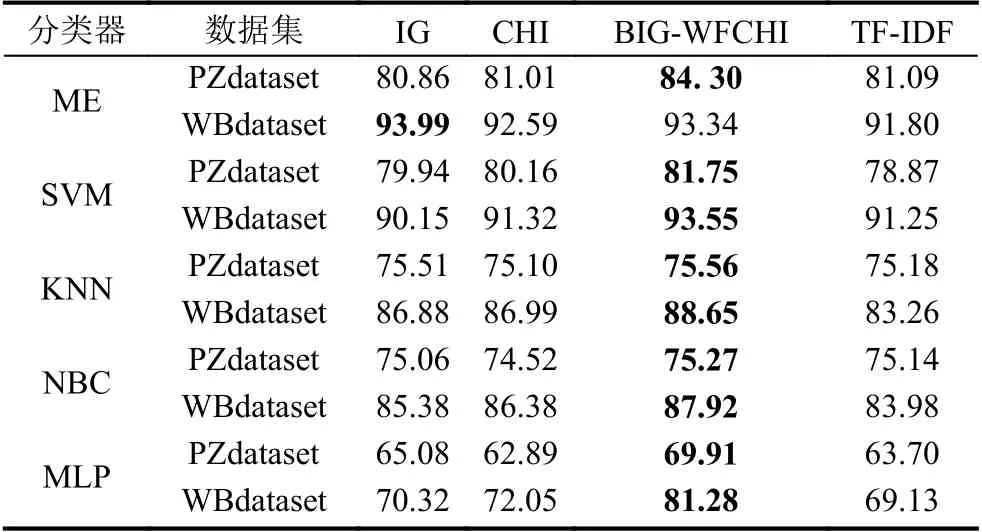
表2 IG、CHI、BIG-WFCHI 和TF-IDF 的分类精度(%)
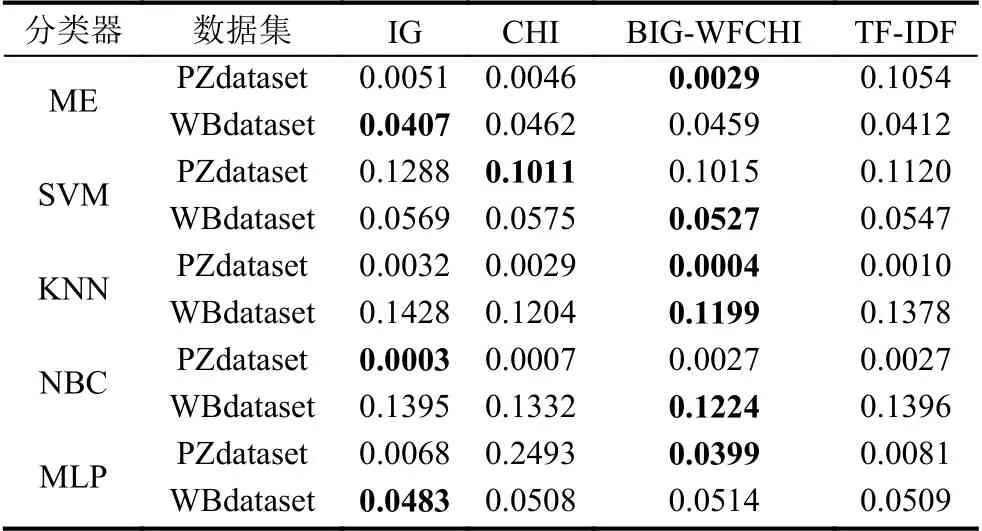
表3 IG、CHI、BIG-WFCHI 和TF-IDF 的标准偏差
进一步探讨10 次运行结果之间是否存在显著差异,本文对这些分类结果进行了Friedman 检验.在所有的测试中,选择变量无显著性差异作为零假设,0.05作为置信水平.由于篇幅的限制,本文在只表4中显示WBdataset 上的测试结果.所有的精确都大于0.05,这意味着我们接受了零假设.10 次10 倍交叉验证没有显著性差异.因此,预测结果的均值是可靠的.在PZdataset上的测试结果显示了相同的结论.
表5显示了基于IG、CHI、BIG-WFCHI 和TF-IDF选择的特征的不同分类器分类结果的AUC 值.从这些AUC 值可以很容易地看出BIG-WFCHI 优于其他3 种选择方法.
图1和图2显示基于IG、CHI、BIG-WFCHI 和TF-IDF 选择的特征的不同分类器分类结果的ROC 曲线.可以看出,在4 种分类器中,BIG-WFCHI 选择的特征具有最好的分类效果.
实验结果表明,在不同的数据集或分类器下,基于BIG-WFCHI 选择的特征子集,分类精度可以提高或至少保持在同一个数量级.通过以上讨论,BIG-WFCHI方法可以更有效地选择信息量更大的特征,实现特征选择具有实际意义.

表4 WBdataset 中IG、CHI、BIG-WFCHI 和TF-IDF 的Friedman 检验
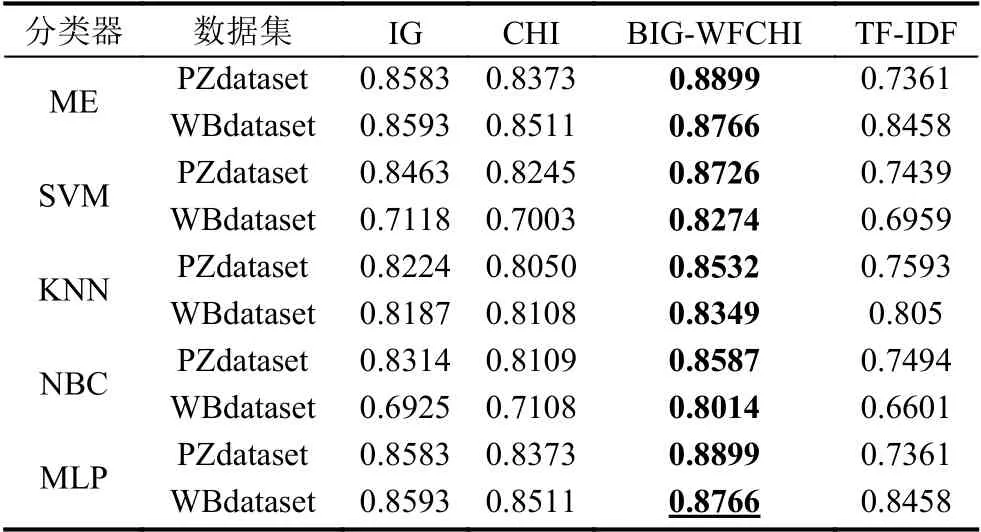
表5 IG、CHI、BIG-WFCHI 和TF-IDF 的AUC 值
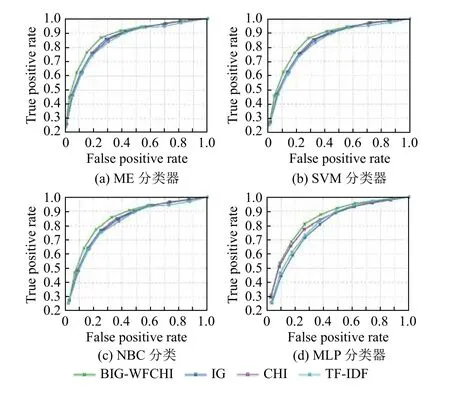
图1 基于WBdataset 相关选择特征的不同分类器的ROC 曲线
3 结论
本文以转发预测为例,讨论了信息增益、互信息和卡方检验等方法在特征选择中的应用,但这些方法存在负相关和可能对计算结果产生干扰等缺陷.本文引入平衡因子和词频因子来提高算法准确率;其次,提出了一种BIG-WFCHI 特征选择方法.实验结果表明,该方法克服了上述缺陷,消除了冗余贡献,提高了ME、支持向量机、NBC、KNN 和MLP 等分类器的效率.
随着网络数据复杂度和规模的迅速增加,特征选择变得越来越重要.BIG-WFCHI 特征选择方法能去除冗余特征,有助于减少计算时间,节省存储空间,提高机器学习效率.因此,为特征选择提供了一种有效的方法.
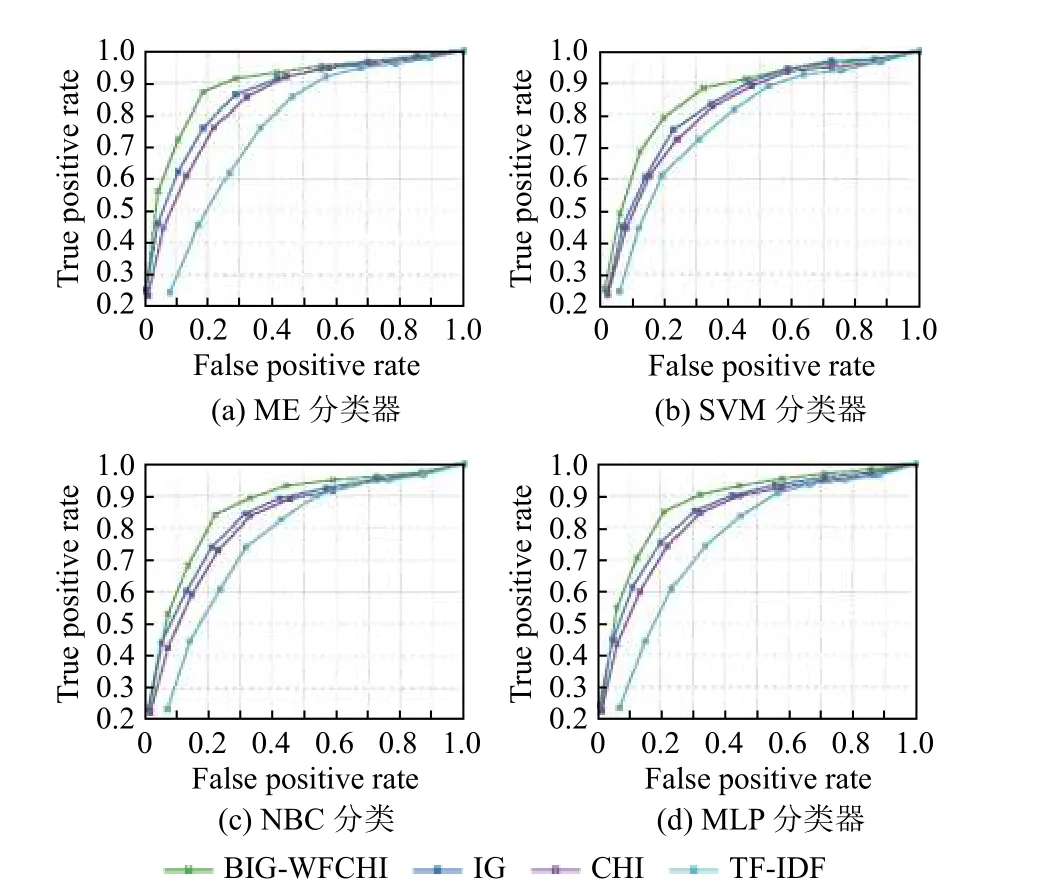
图2 基于PZdataset 相关选择特征的不同分类器的ROC 曲线
猜你喜欢
计算机仿真(2022年7期)2022-08-22
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
软件导刊(2017年4期)2017-06-20
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
读者·校园版(2015年7期)2015-05-14
心理学报(2014年4期)2014-02-02
