
全监督学习的图像语义分割方法研究进展
2021-02-22 11:59袁铭阳黄宏博周长胜
计算机工程与应用 2021年4期
袁铭阳,黄宏博 ,2,周长胜,2
1.北京信息科技大学 计算机学院,北京 100101
2.北京信息科技大学 计算智能研究所,北京 100192
图像语义分割在计算机视觉领域中是一个重要的研究方向,可以从像素级别对图像中的各个事物进行图像识别和目标检测。具体来说,图像语义分割是指从像素级别分辨出图像中的目标对象具体是什么以及目标对象在哪个位置,即先把图片中的目标检测出来,然后描绘出每个个体和场景之间的轮廓,最后将它们分类并对属于同一类的事物赋予一个颜色进行表示。而图像语义分割存在一些难点,例如不同种类的物体有着相似的外观或形状,此时很难将物体种类区分开来。而且当物体尺寸过小时,不仅易丢失物体的细节,而且难以识别出物体的具体轮廓。为了解决这些难点,最初大多图像语义分割技术都是基于传统方法,主要包括基于阈值、边缘检测以及区域的分割方法。随着深度学习的出现,基于深度学习的图像语义分割方法逐渐取代了传统方法,其准确率和速度等各种性能指标都有着很大程度的提高。现如今,基于深度学习的图像语义分割在自动驾驶、面部分割、服装解析、遥感图像以及医学图像等领域都有着广泛的应用前景,具有很好的研究价值。
目前,已经存在不少综述性文章对各种图像语义分割方法进行分析和点评。文献[1-2]主要是对常见的语义分割方法进行全面解析;文献[3-4]对多种语义分割方法进行了合理的分类,并对数据集进行了详细的说明;文献[5-7]详细描述了多种语义分割方法并对各方法的优势之处进行合理的分析对比,同时对各种方法进行明确的分类。本文在已有综述的基础上,补充了许多最新的图像语义分割方法,并对目前主流方法的描述说明进行了进一步完善。
近年来,随着深度学习的不断发展,图像语义分割技术也取得了重大进步,越来越多的基于深度学习的前沿图像语义分割方法相继出现,均不同程度对网络模型进行了改进。由于在前沿的深度学习语义分割方法中,全监督学习的图像语义分割方法的效果要明显优于弱监督以及半监督学习的图像语义分割方法,本文旨在对全监督学习的图像语义分割方法的研究进展进行全面分析。全卷积网络(Fully Convolutional Network,FCN)[8]的出现,标志着深度学习正式进入视频图像语义分割领域。本文将从FCN 开始,按照分类依次介绍各种语义分割方法。接着对各种图像语义分割方法进行性能对比,介绍图像语义分割的评估指标和数据集。最后对所有图像语义分割方法从多个方面进行总结,并对语义分割的未来进行展望。
1 全监督学习的图像语义分割方法
由于经过像素级标注的图像可以包含较多的细节信息,有利于通过网络训练提取到更加丰富的语义信息,因此目前取得较好分割效果的方法大多属于全监督学习类型。由于早期计算效率低下,早期语义分割方法大多采用全卷积的方式来直观地获得分割结果,为了使网络模型形成一种对称的美感,编码器解码器结构也逐渐变得流行起来。随着计算力的增加,新方法开始将注意力机制引入到语义分割模型中来提升性能,也有些方法尝试着设计出特殊模块添加进已知模型中来提升分割精度。后来,由于单一网络难以满足对所有数据集中图像都有较好的分割效果,进而开始出现非静态网络用于图像语义分割。根据这些方法的不同特点,将全监督学习的图像语义分割方法共分为5大类:基于全卷积的图像语义分割方法、基于编码器解码器结构的图像语义分割方法、基于注意力机制的图像语义分割方法、基于添加特殊模块的图像语义分割方法以及基于非静态网络的图像语义分割方法。
1.1 基于全卷积的图像语义分割方法
全卷积网络(FCN)是将深度学习运用到图像语义分割领域的开山之作。FCN的主要思想是把AlexNet[9]、VGG16[10]以及GoogleNet[11]等常见的网络结构中的全连接层转化为卷积层,并在最后使用反卷积,用来将经过下采样压缩后的特征图通过上采样恢复到原来的尺寸,具体的网络结构如图1 所示。FCN 可以把图像中的每一个像素作为训练样本,保留每个像素在原图片中的位置信息,在网络训练时对各个像素进行预测并输出一个相对应的判断标注,最终计算出各个像素最大可能属于哪一类别。

图1 FCN网络结构图
FCN最先在图像语义分割领域引入了一种端到端、像素到像素的全卷积网络。文献[12]是对FCN 的一种改进,引入了表观适配网络学习视觉的相似性,获取特征图的低级像素信息,并通过表征适配网络获取表征信息,能一定程度提升分割效果。文献[13]以DenseNet[14]网络结构作为骨干,并对Dense块后的特征图使用上采样恢复图像分辨率,使得网络模型的精度更加准确且更加易于训练。
DeepLab系列网络专门用于图像语义分割,该系列通过不断改进网络模型来优化图像语义分割效果,最先问世的是 DeepLabV1[15]。DeepLabV1 首先将 VGG16 中的全连接层转化为卷积层,接着将网络中最后两个池化层之后的卷积层替换为空洞卷积(Dilation Convolution)[16]。空洞卷积优势之处在于可以增加感受野,不仅可以很好地解决由于池化计算导致的图像分辨率降低的问题,还能大幅提升网络对图像中大物体的分割效果。DeepLabV1在网络的最后一层添加了全连接条件随机场(Conditional Random Field,CRF)[17],可以小幅提升图像语义分割的精确率。由于空洞卷积会增加计算复杂度,文献[18]使用联合金字塔上采样来代替空洞卷积,通过将多个并行的不同扩张率的空洞卷积恢复到相同分辨率,在提高模型精度的同时还能加快计算速度。
DeepLabV2[19]在DeepLabV1 的基础上做出了改进,以残差网络ResNet[20]代替VGG16作为网络模型,ResNet直接将输入信息绕道传到输出端,一定程度上解决了传统神经网络在训练过程中或多或少丢失部分信息的问题。为了解决空洞卷积难以识别小物体的问题,DeepLabV2使用了空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)对原图提取多尺度特征。ASPP的思想与空间金字塔池化[21]类似,可以更有利于获取同一事物在不同尺度下的特征。由于ASPP的加入,虽然使得DeepLabV2相较于DeepLabV1有了更多的参数量,但是却带来了很大程度上的精度提升。文献[22]对DeepLabV2 的分割速度做出了优化,采用Xception 网络作为编码器,增加FPN解码特征的过程,并减少了ASSP的参数数量,使分割速度提高了近一倍。
DeepLabV3[23]在DeepLabV2 的基础上做出了改进,依旧以残差网络ResNet 作为网络模型。DeepLabV3 提供了两种思路,第一种是在结构上利用空洞卷积能够增加感受野的优势,采用空洞卷积来加深网络的层数,这样做的优势在于不用担心因为网络层数的增加而降低图像分辨率,之后将这些串行连接的空洞卷积与ASSP相结合。DeepLabV3 的第二种思路是在ASSP 模块中做出了改进,在模块中添加了一个1×1 的卷积层和BN(Batch Normalization),并在模型最后添加了全局平均池化[24],可以获得更加全面的图片语义信息。最后,由于CRF 学习速度过慢,且在DeepLabV1 和DeepLabV2中提升的精度较少,因此在DeepLabV3中被舍弃。最终实验结果证明,DeepLabV3即使是在去除了CRF的条件下也能获得比DeepLabV2 更高的精确度。文献[25]在DeepLabV3 的基础上,使用轻量化MobileNet 作为特征提取器,并采用Swish 激活函数进行精度补偿,使得在相同精度的条件下,模型大小和运行时间大幅降低。
RefineNet[26]是一种用于高分辨率语义分割的多路径优化网络,该网络可以完美利用降采样过程中的所有可用信息,以实现使用远程残差连接的高分辨率预测。RefineNet 网络一共包含三部分:第一部分是残差卷积单元,用来接收多个任意分辨率的特征图并获得这些特征图的底层信息;第二部分是多分辨率融合,将多个分辨率的图像通过上采样恢复到相同的分辨率并进行融合;第三部分是链式残差池化,构建由多个块组成的链,每个块由一个最大池化层和一个卷积层组成,可以从较大的图像区域捕获背景上下文信息并提取高级语义特征。RefineNet的主要贡献在于提供了一个结合高级语义特征和低级特征生成高分辨率分割图的网络结构,该网络适用于多类语义分割任务,在语义分割主流的7个数据集中超过了所有同期的其他网络。
1.2 基于编码器解码器结构的图像语义分割方法
编码器解码器结构是语义分割领域中一种流行的网络结构。其中编码器通过卷积池化操作获得像素的位置信息,而解码器通过反卷积操作还原像素的位置信息,进而形成一种对称的网络结构。
SegNet[27]是最经典的编码器解码器结构的图像语义分割网络,具体网络结构图如图2所示。SegNet中编码器以VGG16网络结构为原型,保留了VGG16中的前13个网络层,完全删除了全连接层,用来提取输入图的特征。而解码器与编码器相对应,对编码器生成的特征图进行上采样,保证最后的分割图与原图分辨率一样。值得注意的是,SegNet中的每一个池化都添加了一个索引功能,作用是保留经过最大池化后剩余元素的初始位置。添加索引使编码器在网络训练过程中不再需要把完整的生成图传递给解码器,可以大幅减少网络训练时的内存占用。文献[28]也使用了编码器解码器结构,并提出了双通道,用来分别处理像素标注目标图像和所有源图像,不仅一定程度上解决了图像标注问题,还提升了精度。
U-Net[29]是对生物医学图像和遥感图像[30]进行语义分割的编码器解码器结构的网络。编码器通过卷积和池化提取输入图特征,之后将这些特征图传递给解码器进行上采样。U-Net用到了网络层之间通道的拼接,这种网络层之间的拼接方法可以实现多层次融合,也就是说把网络中的每一层信息融合在了一起。拼接的优势在于通过实现多层次融合,使得网络在训练过程中可以很大程度减少因为池化层的计算而丢失的信息。而由于U-Net多次使用复制和裁剪,最终虽然会导致语义分割图即使通过解码器进行上采样也不能够恢复到与输入图相同的尺寸,但是在同期却因为在网络结构中保留了更多的原图信息而取得了较高的精度。文献[31]对U-Net进行了改进,采用了DenseNet的思想,将U-Net中的前四层全部连接起来,可以更好地获取多个层次的特征,专门用来处理生物医学图像。
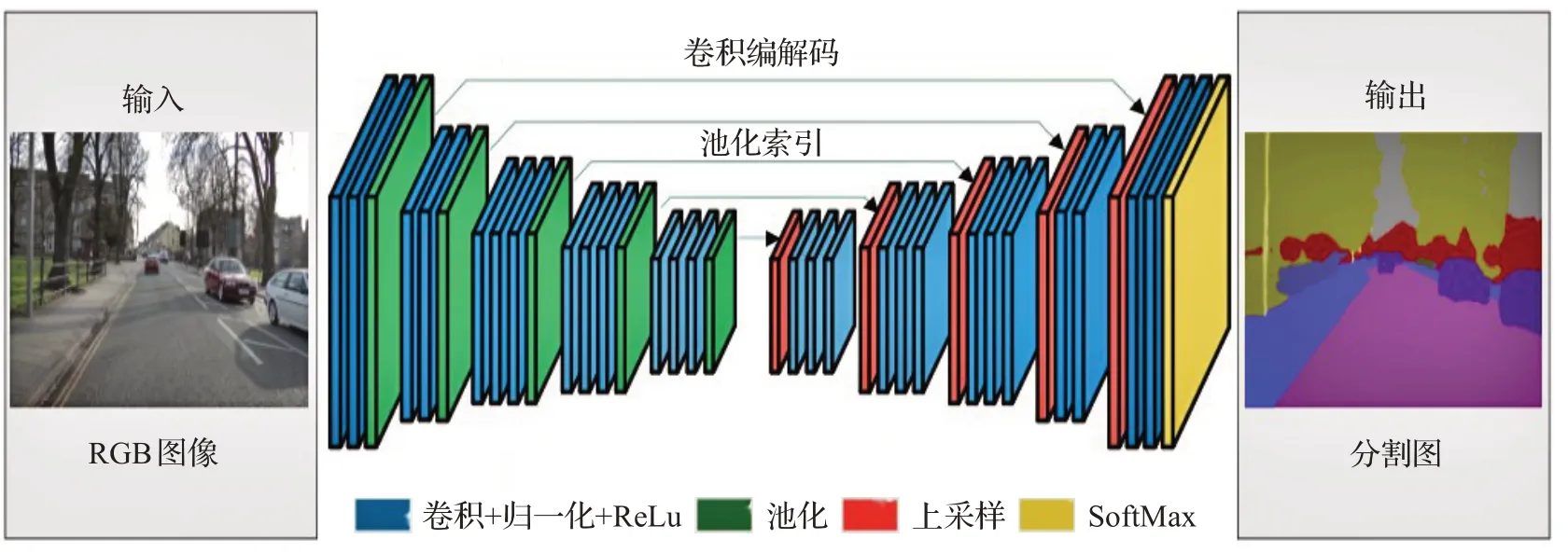
图2 SegNet网络结构图
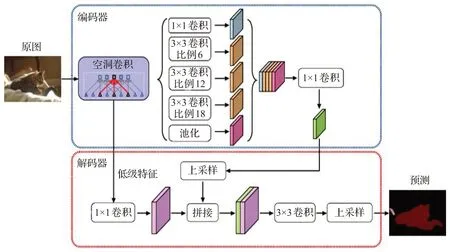
图3 DeepLabV3+网络结构图
DeepLabV3+[32]在DeepLabV3的基础上做出了改进,采用了编码器解码器结构进行图像语义分割。DeepLabV3+将DeepLabV3网络结构作为编码器,并添加一个简单高效的解码器用于获取空间信息,具体的网络结构如图3所示。DeepLabV3+使用了Xception[33]结构进行图像语义分割,可以大幅提升网络的运行速度。在编码器中,利用空洞卷积获取并调整编码器特征的分辨率,来平衡运行时间和精确度之间的关系。在编码器中的ASPP以及解码器中,添加了深度分离卷积,可以大幅降低网络的参数量,使得整个网络模型可以快速计算并保持较好的学习能力。最后,将由空洞卷积获得的低级纹理特征和由ASSP 获得的高级语义特征拼接起来,经过3×3 卷积层再上采样获得预测结果。DeepLabV3+取得了较DeepLabV3更高的精度,达到了当时的最高水准。
1.3 基于注意力机制的图像语义分割方法
近年来,随着注意力(Attention)机制在自然语言处理(Natural Language Processing,NLP)领域取得主导地位,人们把Attention机制也同样用在了图像语义分割上。将注意力机制引入语义分割网络,可以更好地从大量语义信息中提取出最关键的部分,使得网络的训练过程更加高效,分割效果也会显著提升。但基于通道注意力机制的模型SENet[34]很难达到像素级别的分割效果,因此大多基于注意力机制的图像语义分割方法使用自注意力机制模型来提高图像语义分割精度。
DANet[35]就是基于自注意力机制的图像语义分割网络,采用带有空洞卷积的ResNet 作为主干网络。将经过主干网络后的生成图通过两个并行的自注意力机制模块,即位置注意力模块和通道注意力模块。位置注意力模块通过加权求和的方式来更新位置特征,用来获得生成图的任意两个位置之间的空间依赖关系。通道注意力模块同样通过加权求和的方式来更新每个通道,用来获得生成图任意两个通道之间的通道依赖关系。最后对经过两个自注意力机制模块的输出图进行元素求和实现融合,最终通过一次卷积获得语义分割图。
大多数的语义分割任务都通过多个卷积层来增大感受野,但随着卷积层的不断堆叠,不仅造成计算量的增加,而且使得能保留的原图信息越来越少。为了解决这些问题,设计出non-local[36],一种可以用于图像语义分割的自注意力机制模块,该模块的示意图如图4 所示。non-local 模块可以通过直接计算出任意两点的关系来高效获得长范围依赖,且能保证输入图和输出图尺度不变,便于应用到各种网络模型中。文献[37]以ResNet为网络结构并利用non-local模块,在该模块中加入金字塔池化进行下采样,使得non-local模块从计算任意两点的关系转变为计算任意一点和图像块之间的关系,大幅提升了计算效率。文献[38]使用了两个注意力机制模块,第一个模块通过双线性池化[39]获得图像的全部特征,并将其放在一个集合中,第二个模块将这些特征自适应地分配到每个位置,与non-local 有类似之处。CCNet[40]是一种基于十字交叉模块的网络,十字交叉模块是对nonlocal 模块的一种改进。使用了串行连接的两个十字交叉模块,使得每个像素点在第一个模块中先计算出该点与其十字型结构的其他像素点的关系,接着在第二个模块遍历所有的像素点,这样可以在提升精度的同时降低内存。
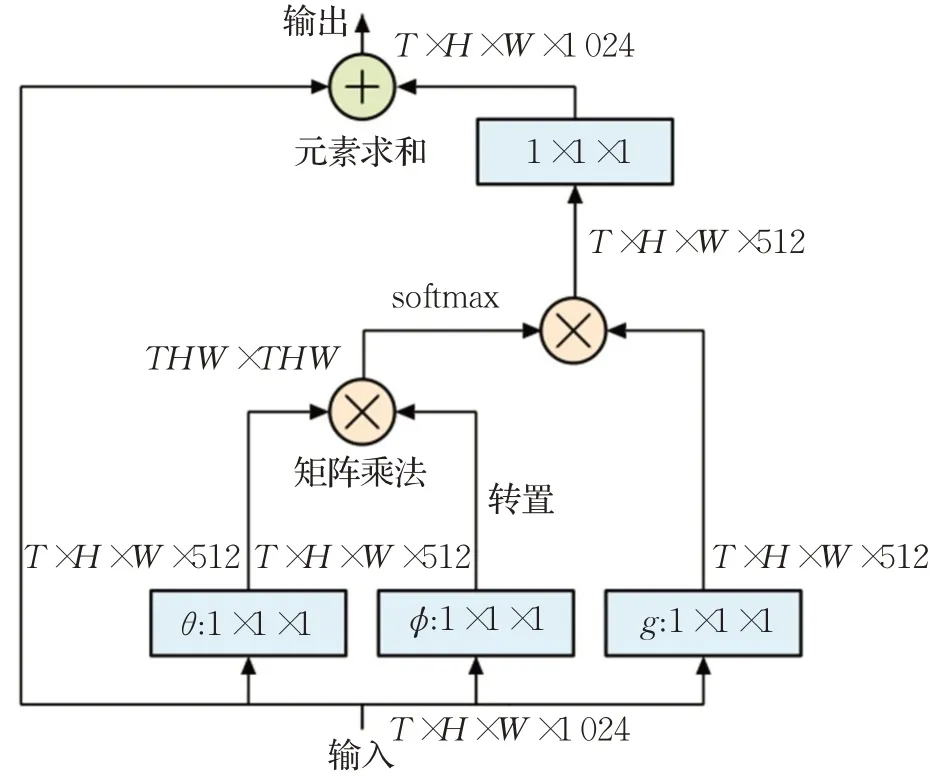
图4 non-local示意图
虽然non-local 在图像语义分割任务中表现十分突出,但由于每个像素点都要和全图所有其他的像素点进行计算,时间复杂度和空间复杂度过大。EMANet[41]是一种期望最大化注意力机制网络。EMANet 的核心之处在于EMA单元,该单元通过EM算法中的E步更新注意力图,M步更新一组基,之后E步M步交替执行,最后迭代出一组紧凑的基。由于仅在这组紧凑的基上运行注意力机制,相较于non-local大幅降低了复杂度。EMANet随着EM算法迭代次数的增加,其性能相较non-local有了明显的提升。
HANet[42]是一个添加了通用附加注意力机制模块的网络,名为高度驱动注意力网络,专门用来对城市场景图像进行语义分割。通过对城市场景图像的观察,发现图像水平分割部分的像素存在着明显的差异,因而可以根据像素的垂直位置有选择地调整信息特征并对像素进行分类。就类别分布而言,城市场景图像中每行像素都包含不同的上下文信息,HANet模块的主要目的就是提取这些信息并计算每行像素的注意权重,用来表示每行的重要性。HANet 模块将原图通过宽度池化压缩空间维度,再经过三层卷积获得注意力图,并将正旋位置编码添加到HANet模块中,用于提取高度方向的上下文信息,最后将注意力图与特征图进行元素乘积获得分割图。HANet模块可以添加进如DeeplabV3+的现有模型中,可在城市场景数据集中取得最高性能。
1.4 基于添加特殊模块的图像语义分割方法
目前,许多图像语义分割方法通过构建特殊模块,并将特殊模块添加到常见网络结构中达到提升图像语义分割性能的目的。E-Net[43]属于实时图像语义分割的网络,和大多数的语义分割网络不一样,该网络的侧重点主要放在确保一定精度时网络的速度上。E-Net设计出一种初始模块来达到目的,初始模块将池化层和卷积层采用并行的方式计算,代替传统CNN 中池化层在卷积层之后的设定。之后再对并行运行的结果进行拼接作为输出,可以减少网络的深度并降低计算量。另外将下采样放置在网络结构的前端,可以有效地对特征图的尺寸进行压缩并减少网络参数,从而进一步提升速度。单从速度指标来看,E-Net的速度是SegNet的20多倍。
PSPNet[44]是一种用于复杂场景的金字塔场景解析网络,用来将复杂场景上下文特征嵌入基于FCN 的像素预测框架中,通过金字塔池化模块聚合了基于不同区域的上下文信息,具体的网络结构如图5所示。PSPNet的核心之处在于金字塔池化模块,首先让经过卷积层的特征图进入金字塔池化模块。该模块通过四种不同尺度的池化得到不同大小的输出特征图,之后将多个输出特征图通过卷积层再进行上采样,可以将多个不同大小输出特征图恢复到和原特征图相同的尺寸,最后对所有的输出特征图和原特征图进行拼接卷积得到最终图像语义分割图。PSPNet通过金字塔池化模块可以很好地解决由于大多数基于FCN网络没有捕获到足够的上下文信息而导致错误分割的问题,因此可以提升对具有相似外观的不同物体的语义分割精度。
PointRend[45]是基于点的渲染的神经网络模块,该模块的设计理念是将对图像分割问题视为图像渲染问题进行处理。所谓渲染,即把3D实体在2D平面上绘制出来,难点在于对实体的边缘进行分割。PointRend 模块共由三部分组成:第一部分是点的选择策略,仅选择处于物体边缘位置的点;第二部分是点的特征表示,通过双线性插值计算出被选择的点的特征;第三部分则是对这些点的特征进行预测。其中重点在于点的选择策略,通过计算该点与其近邻点是否显著不同的方式可以自适应地正确选择出少量物体边缘位置的点,不仅能避免对所有像素进行过多无用的计算,还能直接影响最终的分割效果。PointRend 模块可以理解成上采样功能模块,用双线性插值法进行上采样,并对模糊的点进行预测,直到达到所需的分辨率。该模块可以添加到实例分割网络Mask R-CNN[46]和语义分割网络DeepLab 中,进一步提升分割精度。

图5 PSPNet网络结构图
SPNet[47]是由条纹池化模块(Strip Pooling Module,SPM)和混合池化[48]模块(Mixed Pooling Module,MPM)构建而成的图像语义分割网络,该网络的核心在于条纹池化(Strip Pooling)。条纹池化是一种新的池化方法,其计算方式和平均池化一样,但池化核变为1×n或n×1(n为特征图的长或宽)。这种长方形池化核相较于大多数正方形池化核可以更好地捕获图像中长条型结构的目标对象。SPM 将输入图通过并行的水平条纹池化和竖直条纹池化得到两张特征图,再将两张特征图进行扩张求和后得到融合特征图,最后将融合特征图进行卷积处理后与原输入图进行像素相乘获得输出图。MPM 是对SPM 的改进,区别在于添加了金字塔池化,与条形池化构成混合池化,用来解决SPM 不能较好地捕获图像中的非长方形目标的问题。SPNet 通过SPM和MPM 对各类形状的物体都有较好的分割效果,其精度达到了SOTA。
SFNet[49]是用于场景解析的特征金字塔对齐网络,通过将光流对齐模块(Flow Alignment Module,FAM)插入特征金字塔网络(Feature Pyramid Network,FPN)[50]框架构建而成。SFNet的核心部分在于FAM,FAM将变换后的高分辨率特征映射与低分辨率特征映射相结合,生成语义流场,用于将低分辨率的粗略特征转化为高分辨率的精细特征。FAM在形式上类似于通过光流对齐两个视频帧,用于学习相邻层特征映射之间的语义流,并将高级语义特征有效地传播到高分辨率特征并进行对齐,进而获得具有高分辨率的高级语义特征。由于FAM 可以高效地将语义信息从深层传递到浅层,可以更加丰富地表示低级特征的语义。SFNet 通过丢弃部分相对无关的卷积来减少计算开销,再配合使用FAM提升精度,使得网络在分割精度和速度之间实现最佳的平衡。最终不仅在速度上达到了实时的效果,还显著提高了准确性,在多个数据集中均表现出了极佳的性能。
1.5 基于非静态网络的图像语义分割方法
直到现在,大多图像语义分割网络都属于单一静态网络,虽然静态网络也能对各种不同类型的图像有着较高精度,但是静态网络却不能保证最适用于所有类型的图像。因此设计出一种可以对不同类型的图像进行合理网络构建的非静态网络,不仅会适用于所有图像,还能较静态网络取得更高精度。
Auto-DeepLab[51]是一种自动搜索图像语义分割架构的方法,该方法首次将神经架构搜索(Neural Architecture Search,NAS)[52]用在图像语义分割中。Auto-DeepLab提出了一种网络级架构搜索空间,这种搜索空间可以增强单元级搜索空间,从而形成分层架构搜索空间,通过这种分层架构搜索空间可以搜索到最优的单元架构和网络架构。为了保证搜索最优架构的高效性,Auto-DeepLab 设计出了一种与分层架构搜索空间相匹配的连续松弛的离散架构,可以通过梯度下降的方法进行优化,进而明显提升搜索效率。由于搜索的高效性,Auto-DeepLab 在未预训练的条件下性能超过了当时大多数预训练模型。
Dynamic Routing[53]是最新的语义分割表示方法,提出了一个动态路由的新概念。动态路由会根据输入图像中不同尺度目标的分布情况进行推理,并在推理过程中自适应地生成不同的网络结构。利用动态路由,可以将图像中各类物体根据尺寸的大小自适应地分配到相对应分辨率的网络层上,从而针对性地实现特征变换。在路由空间方面,可以包含多个独立的节点,每个节点都包含上采样、尺度不变和下采样三种尺度变换通路。与Auto-DeepLab 中的节点只能选择一条路径不同,动态路由中的每个节点都支持多通路选择和跳跃连接,因而可以模拟出很多经典的语义分割网络架构。在路由选择方面,由于对每个节点都设置了一个计算单元并设置了一种软条件门控,使得该节点选择的每一条路径的概率都由门控函数计算,因而可以动态地选择路径。此外,通过给门控函数设计预算约束,可以尽可能舍弃无意义的计算,进而降低计算成本。实验结果显示,Dynamic Routing 网络较大多数静态网络有着更优越的性能。
2 语义分割的性能对比
2.1 图像语义分割性能评估指标
为了对各种图像语义分割方法的性能进行公平的对比,需要使用一种统一的、在语义分割领域公认的评估指标。目前,语义分割领域中常用的三种评价指标包括精度、执行时间以及内存占用。就精度这一评价指标而言,最常见的性能评估指标包括像素精度(PA)、平均像素精度(MPA)、平均精度(AP)、平均召回率(AR)、平均精度均值(mAP)、交并比(IoU)以及平均交并比(MIoU)。在评估结果时,一般会选择PA、MPA 以及MIoU这三项指标进行综合对比分析。
(1)精度
精度是当前语义分割任务中最重要的一项指标。PA表示语义分割图像中分割正确的像素数量与总像素数量的比值,具体的计算方法如式(1)所示:

MPA表示每个类别中正确的像素数量与该类别所有像素数量的比值的均值,具体的计算方法如式(2)所示:

MIoU 从字面上理解,表示各类像素的观测区域和真实区域的交集与并集之间的比值的平均值,从而可以反映出分割结果和真实图像的重合程度。MIoU是图像语义分割中使用频率最高的一项指标,具体的计算方法如式(3)所示:

式中,n表示像素的类别;pij表示实际类型为i,预测类型为j的像素的数量;pii表示实际类型为i,预测类型也为i的像素的数量,即正确的像素数量。
(2)执行时间
对于实时语义分割任务,执行时间是比精度还重要的一个指标。这项指标可以反映运行速度的快慢,进而决定是否能投入到实际应用中。
(3)内存占用
当满足精度和执行时间指标时,由于可能在某些应用场景中存在内存配置固定的情况,此时需要考虑内存占用问题。
2.2 图像语义分割数据集
不同的图像语义分割方法在处理相同类型的图像时的效果参差不齐,而且不同的图像语义分割方法擅长处理的图像类型也各不一样。为了对各种图像语义分割方法的优劣性进行公平的比较,需要一个包含各种图像类型且极具代表性的图像语义分割数据集来测试并得到性能评估指标。下面将依次介绍图像语义分割领域中常用的数据集,所有常用数据集的数据对比如表1所示。
PASCOL VOC 系列数据集在 2005 年至 2012 年每年都会用于图像识别挑战,为图像语义分割提供的一套优秀的数据集。其中最常用的PASCOL VOC 2012[54]数据集包括场景在内共有21种类别,主要包含人类、动物、交通工具和室内家具等。该数据集共包含10 000多张图像,而适用于语义分割的图像有2 913张,其中1 464张作为训练图像,另外1 449 张作为验证图像。之后该数据集的增强版PASCOL VOC 2012+又标注了8 000多张图像用于语义分割,这些适用于语义分割的图片尺寸不同,且不同物体之间存在遮挡现象。
PASCOL Context[55]数据集是由PASCOL VOC 2010数据集改进而来,添加了大量的物体标注和场景信息,一共有540个标注类别。但在算法评估时,一般选择出现频率最高的59 个类别作为语义标签,剩余类别充当背景。
PASCOL Part[56]数据集也是由PASCOL VOC 2010数据集改进而来,图像数量保持不变,但对数据集中的训练集、验证集和测试集三部分中的图像添加了像素级别的标注。对于原数据集中的部分类别也进行了切分,使得物体的各个部位都有像素标注,可以提供丰富的细节信息。
MS COCO[57]数据集是一种由微软团队提供的可用于语义分割的大型数据集。MS COCO 数据集提供了包括背景共 81 种类别、328 000 张图像、2 500 000 个物体实例以及100 000个人体关键部位标注。数据集中的图片来源于室内室外的日常场景,图片中每个物体都有精确的位置标注,适用于对网络进行预训练。
Cityscapes[58]数据集是一种无人驾驶视角下的城市景观数据集。Cityscapes 数据集记录了50 个不同城市的街道场景,包含了5 000 张精细标注还有20 000 张粗略标注的城市环境中无人驾驶的场景图像。这5 000张精细标注图像共分为2 975张训练图像,1 525张测试图像以及500 张验证图像,总共提供了包括行人、车辆和道路等30种类别标注。
KITTI[59]数据集是一种用于自动驾驶场景的算法评估数据集。KITTI数据集中包含了城市、乡村以及高速公路等多种真实场景图像,最初用于评估目标检测等技术,是自动驾驶领域最受欢迎的数据集之一。但是该数据集创立时却缺乏语义标注,后来通过三人添加手工标注的方式使得该数据集可用于语义分割。
ADE20K[60-61]数据集是一种由MIT发布并维护的用于场景解析的大型数据集。ADE20K 数据集拥有超过25 000 张场景图像,其中训练集有20 210 张图像,验证集有3 000张图像,测试集有3 352张图像。数据集中的图像包含了150种类别,图像中的物体大多为室内和室外的常见物体。

表1 语义分割常见数据集对比
SUN-RGBD[62]数据集是通过4 个RGBD 传感器捕获的图像集合而成的数据集。SUN-RGBD数据集均为密集标注,图像尺寸与PASCOL VOC一致,包含10 000多张RGBD图像和37种类别,另外还包含了146 617个多边形标注和58 657个边界框标注。
NYUDv2[63]数据集是由微软Kinect设备获得的室内场景组成的数据集。NYUDv2 数据集由一系列的视频序列组成,包含1 449 张具有40 个类别的RGBD 图像。数据集中共包含464 种室内场景,26 种场景类型,适用于家庭机器人的图像分割任务。
Sift Flow[64]数据集是以室外场景为主的数据集。Sift Flow 数据集共有2 688 张连同场景在内的34 种类别的训练集图像,包含例如沙漠、河流以及山川等8 种户外类型场景,每张图像都带有像素级标签,专门用于基于室外场景的任务。
SBD[65]数据集是对PASCOL VOC数据集的一个扩展,为PASCOL VOC数据集中图像提供了正确的标签,这些标签提供了各个物体的边界信息。SBD 数据集包含11 335张具有21个类别的图像,其中8 498张图像作为训练集,2 857张图像作为验证集。
CamVid[66]数据集是最早用于自动驾驶的数据集。CamVid数据集是由车载摄像头从驾驶员的角度拍摄的5 个视频序列组建而成的,包含了在不同时段的701 张图像和具有32个类别的语义标签。
2.3 实验结果分析与对比
各种图像语义分割方法的网络结构和所使用的数据集各不相同,无法对所有指标进行比较。为了对各种方法进行公平且直观的对比,表2 选择MIoU 作为对比上述图像语义分割方法的指标,并列举各种图像语义分割方法的关键技术。
3 总结与展望
目前,自从深度学习进入图像语义分割领域,越来越多的全监督学习语义分割方法相继提出,伴随着计算机性能的提升和网络模型的优化,其分割精度不断提升。本文主要对当前主流的全监督图像语义分割方法进行了分类,依次对每种类别中极具代表性的方法进行了综合性的评估,详细介绍了各方法的网络模型和具体流程,并对各方法的实验效果进行了对比。在语义分割领域现有研究的基础上,对该领域的未来研究重点进行展望。

表2 图像语义分割方法对比

表2 (续)
(1)注意力机制
自从注意力机制引入到图像语义分割领域,出现了多种基于注意力机制的语义分割方法。由于注意力机制可以简化特征提取方式,使得引入注意力机制的方法性能超过了大多全卷积语义分割方法。语义分割领域仅仅在引入注意力机制的三年内,已经出现少量通过引用注意力机制使其性能达到了SOTA 的语义分割网络模型,证明了引入注意力机制的有效性。到目前为止,许多注意力机制模块都是以non-local 为基准进行结构或者算法上的改进,嵌入到网络模型中能提升分割精度。也有少量注意力机制模块专门针对某一数据集图片的共同特点来设计,仅在该数据集中能取得最好效果。从当前发展趋势来看,语义分割网络模型中如何引入更合适的注意力机制模块来提高性能将会是未来研究的重点。
(2)实时图像语义分割技术
目前,主流图像语义分割方法把重点都放在分割精度方面,缺乏对实时性的关注。任何网络模型在追求精度的同时,势必会增加网络层数和网络参数量,这都对网络的实时性产生影响。而在实际应用场景中,无论是无人驾驶还是智能机器人,为了保障人身安全,需要对网络的实时性进行严格的把控。现在,部分网络通过采用轻量化的主干网络、改变网络模型通道数或对图像进行压缩的方法来确保实时性,但都会不同程度地导致分割精度的下降。值得一提的是,为了速度指标而大幅降低分割精度同样不能满足应用需求。因此如何在保证分割精度的前提下提升语义分割网络模型的速度,也会成为语义分割领域中一个研究热点。
(3)数据集的自动标注
目前大多数主流的图像语义分割领域所使用的数据集都是依赖人工标注的方式构建的,这并不能满足图像语义分割的需求。人工进行图像像素级标注所需的时间成本和人力成本过大,且产生的精细标注的图片数量也较少。而自动标注的难点在于其容易忽略图像的深层语义,且没有一个固定的质量评价标准,导致最终结果和人工标注图像差距较大。随着深度学习技术的深入,许多基于深度学习的数据集自动标注方法相继出现。最初主要是基于多模态空间的方法以及基于多区域的方法。之后出现利用基于GAN 的方法,使自动标注图像可以通过网络训练尽可能缩小与人工标注图像的差距,取得了更好的效果。为了能在实际应用中有效地解决标注成本问题,设计出更好的GAN 模型对图像数据集自动标注或将成为另一个研究热点。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
