
基于Kudu 的电力辅助设备实时监控业务解决方案
2021-02-22 02:38:32陶继群
科技创新与应用 2021年8期
曹 成,陶继群,郑 湃
(江苏中科院智能科学技术应用研究院,江苏 常州213164)
1 概述
江苏中科院智能科学技术应用研究院基于Hadoop架构的分布式大数据平台已经搭建完成,以T+1 形式处理数据,目前已成功运行各类数据应用和业务需求。但这种离线处理数据的方式已无法满足目前的电力辅助设备的实时数据监控需要,基于分布式文件存储系统(HDFS)、分布式的高性能并行计算平台(MapReduce)和Hive 的Hadoop 架构无法实时加载数据和提供数据查询分析;虽然可以在该架构中添加HBase 存储系统,HBase存储系统虽然可以实现数据的快速插入和实时更新,但其并不适用于大批量的数据扫描工作[1]。目前,我院大数据平台急需能够实现大批量数据实时读写和实时分析的解决方案。
Kudu 存储系统是Cloudera 公司开发的可以实现多种一致性协议的列式存储引擎,兼顾了数据更新实时性和分析速度,能够与Hadoop 大数据平台中的Hive、HDFS等组件形成互补。Kudu 存储系统在满足电力辅助设备实时监控业务实时查询需求的同时,还能够满足监控业务的实时分析,同时还提供了Kudu-API、Impala-JDBC 等连接方法[2],向电力辅助设备的分析系统和展示系统提供快速的查询和分析类的数据共享能力,满足大数据平台的实时类业务处理能力需求。
2 电力辅助设备实时监控业务应用难点分析和相关解决方案
2.1 电力辅助设备实时监控业务应用难点分析
电力辅助设备的实时监控业务主要包括输变电系统中的红外热成像、避雷器、驱鸟器、通风装置、端子箱等6大类辅助设备的数据实时采集入库和实时查询、实时分析和远程控制等。目前大数据平台已对接电力辅助设备500 余台,各类终端20000 余个,通过该监控业务可以有效监控变电站各类设备工作情况和实时报警等。
目前,江苏中科院智能科学技术应用研究院基于Hadoop 架构的分布式大数据平台主要完成各类工业离线数据的计算和分析工作,每日凌晨定时汇总前一天数据至历史数据表单中,按业务要求完成离线计算任务,再将结果同步到结果表单中,供前台系统调用。然而这种处理方式并不适用于电力辅助设备的实时监控业务。主要有以下原因: 该监控业务对底层数据库的响应时间要求极高,涉及的电流值、电压值波动记录存储通常为秒级或者毫秒级,轻微的电流值和电压值波动很可能造成电力设备供电异常或故障。然而HDFS 存储数据效率无法满足这一需求,也无法支撑数据的动态更新和插入等数据库DLL 操作[3];在分析计算实时数据时,Hive 的大批量数据关联查询和计算效率偏低,计算时间偏长,达不到实时数据的计算需要;外网部署的客户分析系统和展示系统获取数据需要大数据平台通过数据API 接口提供,但Hadoop 平台提供的HadoopAPI 接口和Hive API 接口快速响应的能力差,无法满足实时性需求[4]。基于以上分析,大数据平台实时数据处理和读取的能力缺陷导致其成为电力辅助设备实时监控业务的制约。为了满足实时应用的需要,平台急需可以实现大批量实时读写、实时分析解决方案。
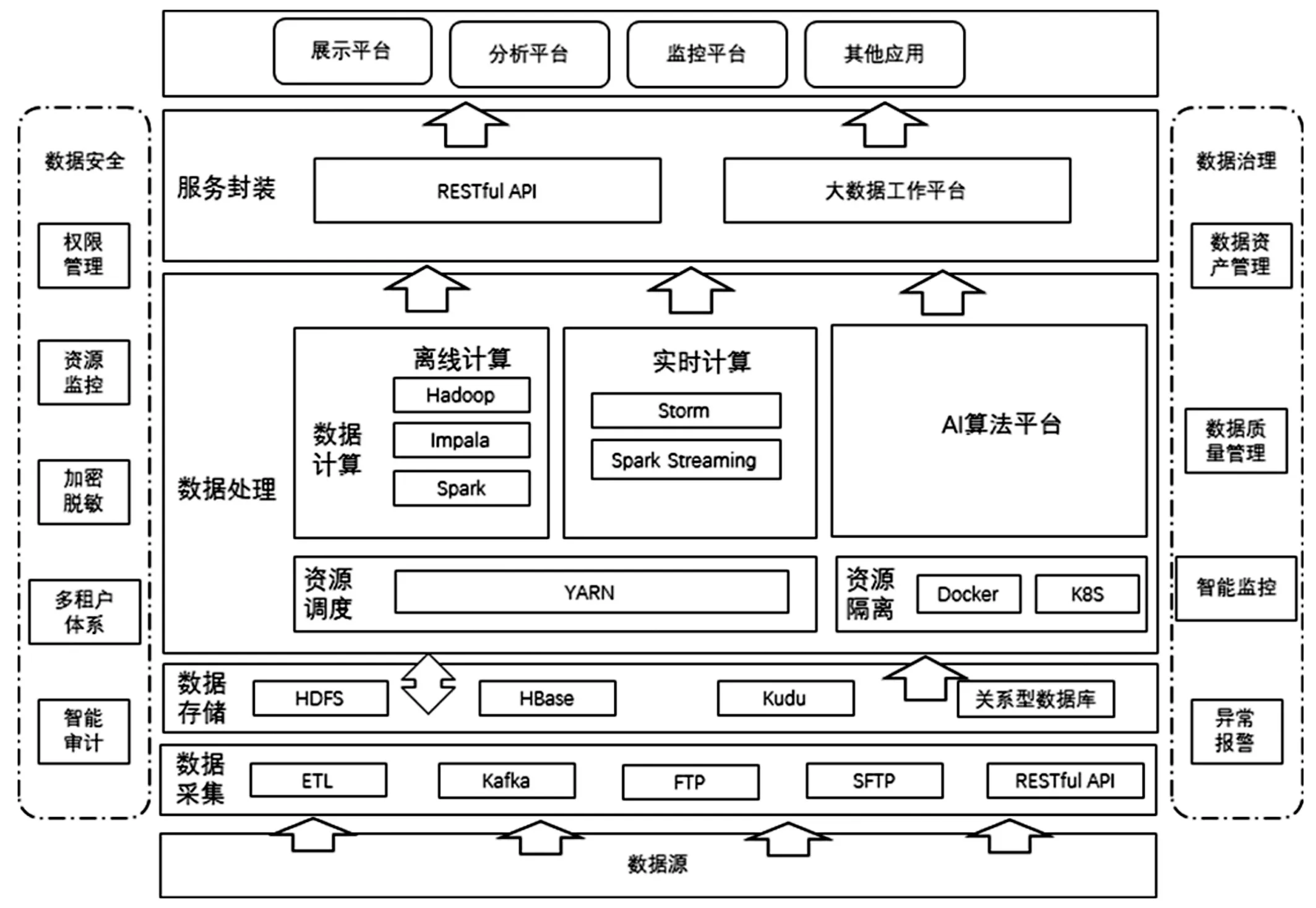
图1 大数据平台总体架构图
2.2 相关解决方案
为处理电力辅助设备的实时监控业务,前期尝试采用的解决方式有Strom 和Spark Streaming 两种,但两种方案最终均被证明无法满足业务需求。
方案1:Strom
Storm 是毫秒级的流处理实时计算体系,Storm 的流处理过程是将实时应用的计算任务写好topology(拓扑)结构然后等待数据进来分析,相似于Hadoop 的MapReduce 任务。其优点是全内存计算[5],所以Storm 的速度相比Hadoop 非常快(瓶颈是计算机内存和CPU),缺点就是不够灵活,数据吞吐量低,不能在中间执行SQL 交互式查询、复杂的转换等[6]。对于电力辅助设备的实时监控业务中的OLTP 场景并不适用。
方案2:Spark Streaming
Spark Streaming 是可以实现高吞吐量的、具备容错机制的实时流数据的处理,Spark Streaming 的处理机制是接收实时的输入数据流,并根据一定的时间间隔(秒级)拆分成一批批的数据,然后通过SparkEngine 处理批数据,最终得到处理后的结果[7]。但Spark Streaming 只是准实时的,事务机制不够完善,也不支持动态调整[8]。对于电力辅助设备的实时监控业务来说,准实时的存储和分析数据并不能满足实时需求。
3 Kudu 解决方案
3.1 Kudu 存储系统
Kudu 的定位是在更新更加及时的基础上实现更快的数据分析,HBASE 不适用于基于SQL 的数据分析方向,大批量数据获取时的性能较差;HDFS 适合离线分析,不支持单条纪录级别的update 操作,随机读写性能差[9],正因为HDFS 与HBASE 有以上缺点,Kudu 较好的解决了HDFS 与HBASE 的这些缺点,它不及HDFS 批处理快,也不及HBase 随机读写能力强,但是反过来它比HBase 批处理快(适用于OLAP 的分析场景),而且比HDFS 随机读写能力强(适用于实时写入或者更新的场景),在更新更加及时的基础上实现更快的数据分析。通过在Hadoop 大数据平台中加入Kudu 存储系统,江苏中科院智能科学技术应用研究院大数据平台实现了对实时业务处理的能力。且Kudu 存储系统可以和已有的Hive、Kafka、Impala 等组件无缝对接,从而服务上层中的数据应用和ETL 流程[10]。引入Kudu 后的大数据平台总体架构如图1 所示。
通过引入Kudu 存储系统,江苏中科院智能科学技术应用研究院大数据平台在保留现有离线业务的前提下,可以实现平台对实时业务的处理能力。同时支持Python、JAVA 等语言开发人员直接调用Kudu API 数据接口,极大的拓展了大数据平台的使用范围[11];同时Kudu 存储系统还具备众多优点,如下:
我院使用的Kudu 存储系统为开源版本,无版权费用支出,降低了项目开发成本。
数据开发工程师只需要向大数据平台提交一份SQL脚本就可以同时处理和HDFS 和Kudu 存储系统中的数据,不需要同时在两个系统中都存储数据,节省硬盘空间,方便快捷[12]。
Kudu 存储系统可以和现有平台中的租户共用,不需要重新申请创建新的租户,其主持多用租户操作环境,有效避免了不同账号的多源管理问题[13]。
Kudu 存储系统开发门槛低,数据开发工程师无需掌握Kudu 底层原理,只需掌握SQL 语言和大数据平台运维原理就可以快速上手,大大节约了学习成本。
3.2 Kudu 实时数据查询
电力辅助设备的实时监控业务对数据的实时性要求极高,从数据采集到数据入库分析再到数据读取整个数据流程不能超过2 秒,终端设备的电流值和电压值入库后需要再次和其他业务表单进行多表联合查询,并将结果及时反馈到分析系统和展示系统中。少量数据可以通过传统型数据库或HBase 进行处理。该方案无法满足电力辅助设备监控业务的大批量数据查询的实时响应要求。
使用Kudu 存储系统+Impala 交互式SQL 解析引擎可以有效满足电力辅助设备的实时监控业务实时查询的业务需求。Impala 是Cloudera 公司开发的一种高效率的SQL 查询工具,采用内存计算模型,对于分布式Shuffle,最大限度的利用服务器的内存和CPU 资源。同时,Impala也有预处理和分析技术,表数据插入之后可以用COMPUTESTATS 指令来让Impala 对行列数据深度分析,具有实时,批处理,多并发等优点,其也允许开发人员使用Impala 的SQL 语法对Kudu 存储系统中的tablets 插入、查询、更新和删除数据[14]。
对于电力辅助设备的实时监控业务中的电流值和电压值查询业务,涉及跨数据库多表关联查询、消除取值重复行查询、大小比较查询和分组聚集函数查询、嵌套查询等;其中分组聚集函数查询和跨数据库多表关联查询两种业务最为典型,测试结果见表1,表2。
从表1、表2 测试结果可以看出,基于Kudu 和Impala 结合使用的解决方案完全能够支撑电力辅助设备的实时监控业务需要,跨数据库大批量的数据查询和分组聚集函数查询响应时间都达秒级,分析系统和展示系统展示的数据查询结果和实时数据相差也为秒级,满足精度要求极高的电流监控和电压监控等需求。
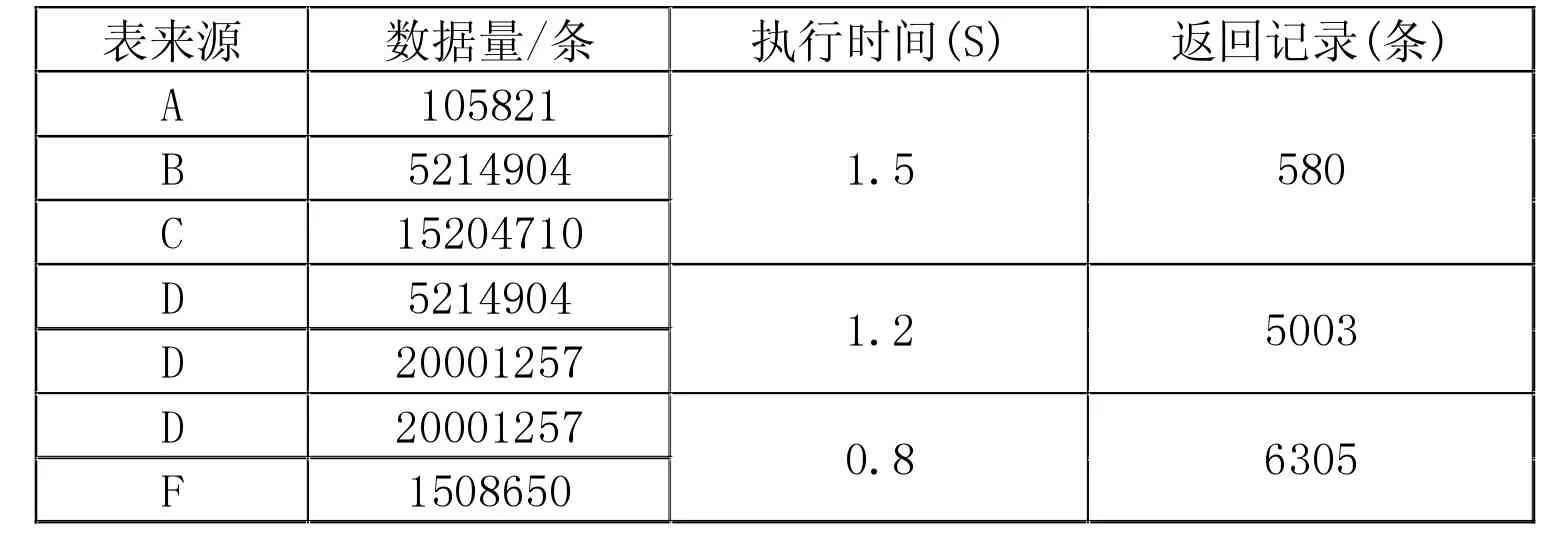
表1 Kudu 存储系统跨数据库多表关联查询
3.3 Kudu 实时数据入库和增量更新
电力辅助设备的实时监控业务数据采集周期设置为实时采集,每秒采集各类终端设备20000 余个,电流值、电压值、温湿度、风速、声波值等各类数值500 多项,约1.5 万余条数据。Hadoop 大数据平台通过结合Kafka 流式处理平台与分布式文件存储系统对接采集实时数据。Kafka 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB 的消息存储能够保持长时间的稳定性能[15]。
Kudu 数据存储系统可以和Kafka 实时消息系统进行对接,从而实现电力辅助设备实时监控业务数据的加装。Kudu 作为列式存储引擎,满足数据逐条采集,因此Kudu 适用于Kafka 的实时写入要求,数据入库效率极高,大数据平台每秒可入库约10 万余条。基于Kudu 的流式数据实时入库测试结果见表3。由此可见,使用Kudu 结合Kafka,电力辅助设备的实时监控业务数据每秒2 万余条数据采集至Kudu 存储系统中的时间完全可以达到秒级,满足监控业务的实时性要求。

表2 Kudu 存储系统分组聚集函数查询

表3 基于Kudu 的流式数据入库测试结果
Hadoop 大数据平台的离线数据仓库Hive,在数据的提取、装载和转化等方面具有优势,但Hive 的执行效率偏低、调优困难、粒度较粗、每次执行Hive 都会自动生成Mapreduce 作业,通常情况下不够智能化,每次都会产生大量的I/O 开销、平台内存被长期占用,因此Hive 无法支持批量数据的增量更新和修改。Kudu 存储系统可以用以下方式实现数据增量更新:每张Kudu 表都会被分成若干个tablet,每个tablet 包括MetaData 元信息及若干个RowSet。执行数据写入操作时,系统都会在Tablet 中的所有RowSet 中进行查找,验证等待写入数据相同主键的记录是否冲突。如果master 校验通过,则返回表的分区、tablet 与其对应的tserver 给client;如果校验失败则报错给client,再次经过一致性算法校验通过后,tserver 会将写入请求预写到WAL 日志,用来server 服务器宕机后的恢复操作。插入的数据寄存在Tablet 的MemRowSet 中,一旦MemRowSet 的大小达到1G 或120s 后,MemRowSet会flush 成一个或DiskRowSet,用来将数据持久化存储,同时再次生成MemRowSet 继续接收新的数据请求,如此循环[16]。Kudu 写入数据的工作机制如图2 所示。
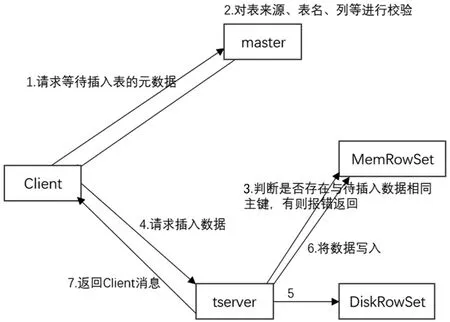
图2 Kudu 写入数据的工作机制
3.4 Kudu API 接口服务
电力辅助设备的实时监控业务不仅需要在分析系统和展示系统中实时展示和应用,同时需要为企业提供数据API 服务,尽管Hadoop 大数据平台通过提供抽象操作和并行编程接口,以Java API 的方式实现了接口的封装,但由于MapReduce 机制原因,企业在调取该类数据API 接口时需要等待很长一段时间才能返回结果[17],企业用户对于这种问题的敏感度极高,无法容忍该响应时间过长的问题。
企业用户通过调用平台的API 数据接口和自身系统接口数据或数据库数据进行对接,通过一定的分析运算后加载在企业自用系统中,该类需求就需要尽量缩减企业调用大数据平台API 接口并返回有效值的响应时间。Kudu 存储系统提供的Kudu API 接口服务正好可以满足这类要求响应时间短,操作简洁、修改方便的需求,Kudu官方推荐使用Java API 或Python API 来完成Kudu 存储系统中的数据读写操作,且Kudu 每张表单均有主键可作为索引进一步缩短了响应时间,Kudu API 在进行调用时运算均在数据磁盘上进行,此种方式处理简单的联机事务(OLTP)时是可行的;单在联机分析处理(OLAP)方面,采用Impala-JDBC 的连接方式处理Kudu 存储系统数据更为高效,Impala 自身并没有存储系统,在进行数据运算时,Impala 会将Kudu 存储系统和HDFS 存储系统中的数据放入内存中进行计算;基于大数据平台512G的运算内存,将数据放入内存中计算的效率远高于在数据磁盘上运算效率[18]。
为提升企业用户调用大数据平台数据的效率和充分利用大数据平台内存资源,针对OLAP(联机分析处理)和OLTP(联机事务处理)两种不同的业务场景均选择使用Impala-JDBC 的连接方式与企业系统进行数据交互,其性能测试结果见表4。
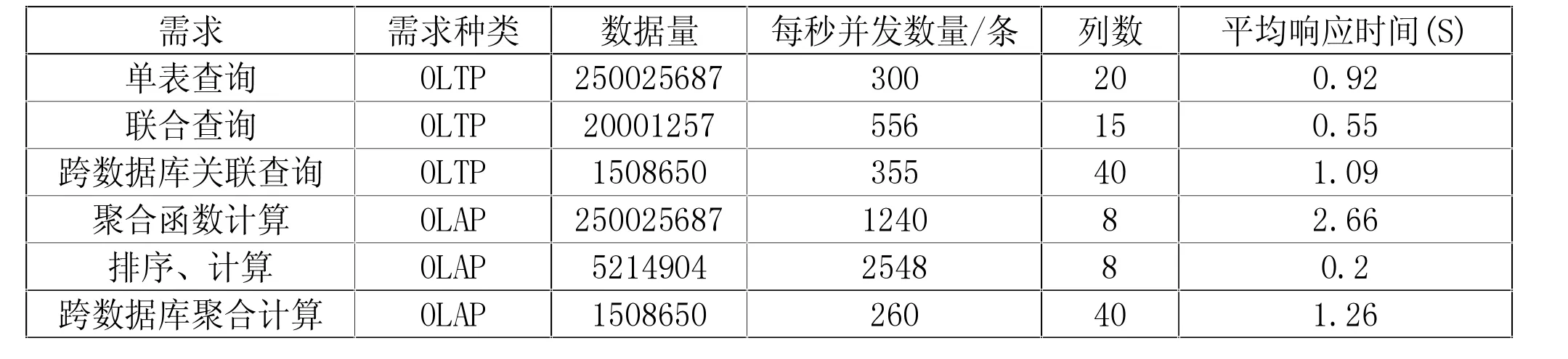
表4 基于Impala-JDBC 的OLAP 和OLTP 接口性能测试结果
从测试结果可以看出,基于Impala-JDBC 的OLAP和OLTP 接口性能可以满足大数据平台对企业提供电力辅助设备的实时监控业务的OLAP(联机分析处理)和OLTP(联机事务处理)两种不同的业务场景的需求,达到了快速响应、提升企业用户使用体验的要求。
4 结束语
综上所述,Kudu 存储系统解决了Hadoop 大数据平台对实时数据的处理短板,Kudu 存储系统部署以来,高效、稳定的完成了实时数据入库、数据的增量更新、实时查询、对外提供高效的API 数据接口服务等工作,在电力辅助设备实时监控业务中发挥了极为重要的作用。后续在保障数据安全的前提下将不断调优Kudu 存储系统性能,进一步提升Kudu 存储系统在电力辅助设备实时监控业务中的能力,为后期进行的深度数据挖掘做足准备。
猜你喜欢
河北理科教学研究(2021年3期)2022-01-18 05:34:24
疯狂英语·新读写(2021年10期)2021-12-07 02:41:30
发明与创新(2021年39期)2021-11-05 07:15:28
哈尔滨轴承(2020年2期)2020-11-06 09:22:36
新世纪智能(英语备考)(2019年4期)2019-06-26 00:49:04
铁道通信信号(2019年11期)2019-05-21 03:06:06
发明与创新·大科技(2019年12期)2019-03-17 09:23:31
中国公共安全(2017年8期)2017-10-13 08:12:17
材料科学与工程学报(2016年1期)2017-01-15 13:33:48
汽车文摘(2015年11期)2015-12-02 03:02:53
