
机器学习在卫星遥测分析建模中的应用
2021-02-22 10:47都晓辉陈昌麟
计算机测量与控制 2021年1期
王 旭,都晓辉,陈昌麟 ,付 宇,杨 涛
(1.航天东方红卫星有限公司,北京 100094; 2.山东航天电子技术研究所,山东 烟台 264670; 3.空间电子信息研究院,西安 710100)
0 引言
机器学习作为人工智能技术的重要分支,在数据挖掘、生物特征识别、机器人等领域有着十分广泛的应用,提高了诸多行业的生产力水平。但在我国卫星制造和卫星在轨管理领域,使用机器学习技术对卫星遥测进行分析和建模的应用尚不普及,仍然较多地依赖人工分析+专家系统解决特定的问题,在面对数量庞大、多类型且相关性复杂的数据时,无法提供有效的综合处理能力[1]。相比专家系统,机器学习在这些方面有天然的优势:它能够处理更加庞大的数据,能够梳理和关联数据的维度信息,并且具有数据处理的实时性。使用机器学习技术后,卫星可以产生更多的数据,为建立各种功能模型提供参数和特征,而不必作为遥测下传。应用这些功能模型就能更加敏感地感知和预测卫星的状态,进而提高卫星研制效率和卫星在轨自主管理水平。
本文以对星载铷钟的遥测数据建模为例,介绍了利用Python的生态环境对卫星数据进行分析,并使用机器学习的算法来建立预测模型的通用方法,为探索人工智能技术在卫星制造领域的应用提供支撑。
1 算法研究与建模的方法
1.1 Python库生态圈
Python是一门动态语言,Python由于拥有强大而成熟的开发生态,逐步成为了机器学习领域最受欢迎的开发语言[2]。IEEE Spectrum第六届编程语言排名评出了2019年度十大流行语言,Python连续数年稳居榜首[3],如图1所示。这在GitHub上也得到了证实,现在Python存储库总数排名仅次于Java和C语言。Python在数据分析和机器学习建模方面的库生态圈主要包括SciPy和scikit-learn。
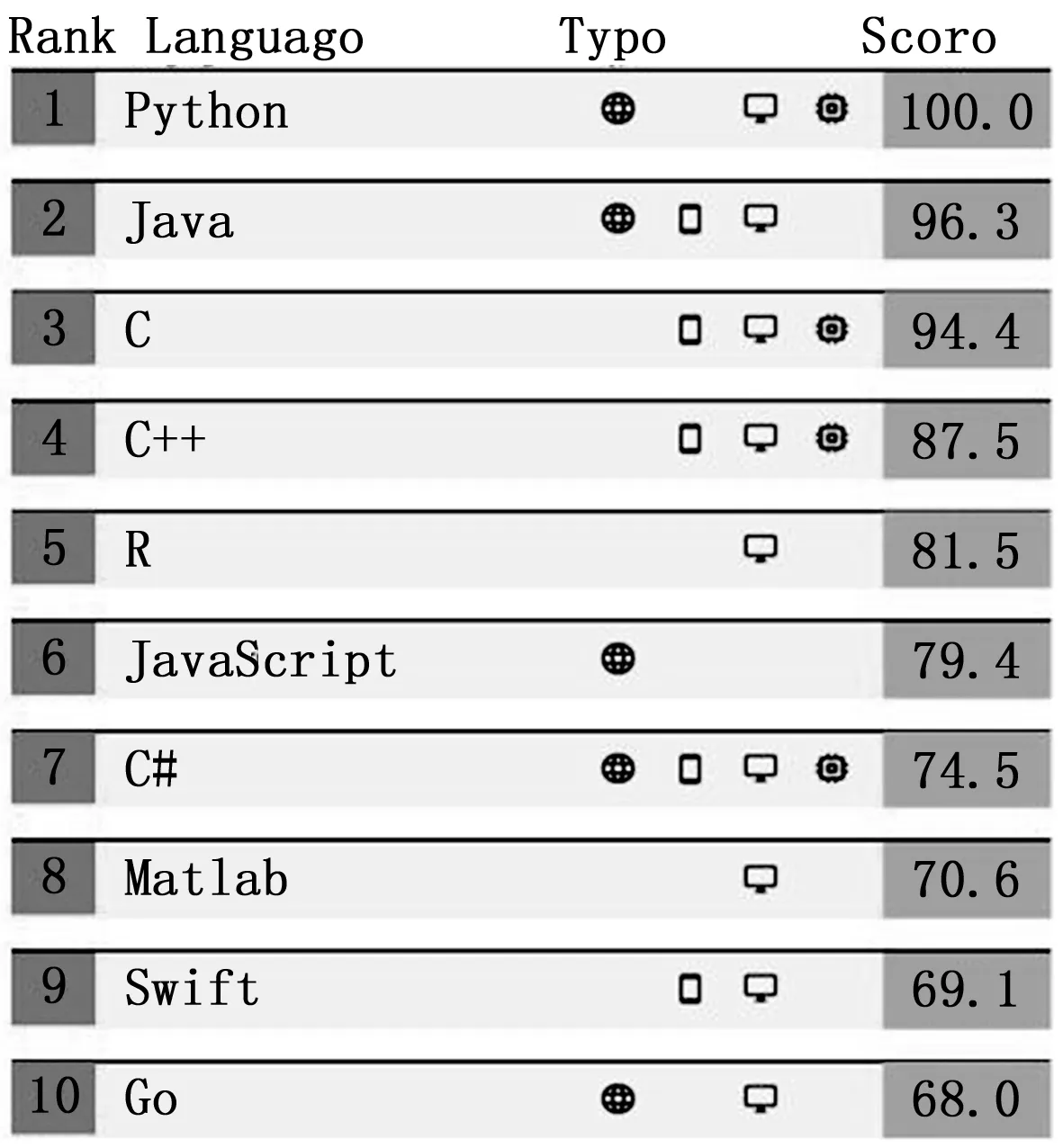
图1 2019年度编程语言排名
SciPy是在数学运算、科学和工程学方面被广泛应用的Python类库。在机器学习领域主要使用NumPy、Matplotlib和Pandas这三个类库来完成数据清洗、显示和数据分析工作[4]。
scikit-learn依赖SciPy及其相关类库来运行,其基本功能主要包括分类、回归、聚类、数据降维、模型选择和数据预处理六部分[5]。
1.2 确定算法并建模的步骤
利用Python进行分析数据、研究算法并预测模型共有七个基本步骤。
1)定义问题:这个过程主要研究和提炼问题的特征,以帮助开发者更好地理解工程目标。
2)导入数据:在训练机器学习模型时需要用到大量数据,最常用的做法是导入并利用目标工程的历史数据来训练。这些数据一般以.csv的格式存储,通常有三种方法实现数据导入:标准Python库导入、NumPy导入、Pandas导入。
3)数据理解:通过描述性统计和可视化数据来分析现有的数据。这个过程需要导入原始数据,查看数据的维度、属性、类型,并利用Pandas进行数据描述性统计、分析数据属性的相关性和分布情况。这个步骤一般会用到DataFrame的shape属性、Type属性、describe()方法、corr()方法、skew()方法等。其中,shape属性可以方便获得数据集的行列维度信息;Type属性用于获取每个字段的数据类型;describe()方法用于审查数据的描述性统计内容;corr()方法用于计算数据集中数据属性之间的关系矩阵;skew()方法用于计算所有数据属性的高斯分布偏离情况。
4)数据准备:开始机器学习的模型训练前,必须对数据进行格式化处理,以便构建一个预测模型。这是因为不同算法对数据有不同的假定,需要按照不同方式转换数据,这样能够得到一个准确度比较高的模型。这个过程中一般会进行调整数据尺度、正态化数据、标准化数据或二值数据等操作。
5)评估算法:通过一定方法分离一部分数据,用来评估算法模型,并选取一部分代表数据进行分析,以改善模型。这个过程包括主要通过使用scikit-learn进行数据预处理和数据特征选定,以实现数据尺度的统一或正态化,并降低数据的拟合度[6]。
6)优化模型:通过集成算法和算法调参提升预测结果的准确度。一般有三种集成算法用于优化模型:装袋(Bagging)算法、提升(Boosting)算法和投票(Voting)算法。其中,袋装算法先将训练集分离成多个子集,然后通过各个子集训练多个模型;提升算法是训练多个模型并组成一个序列,序列中的每一个模型都修正前一个模型的错误;投票算法是训练多个模型,并采用样本统计来提高模型的准确度。算法调参是对参数化的机器学习模型进行处理,用来提高模型的准确度。一般用网格搜索优化参数和随机搜索优化参数两种方法。
7)模型部署:完成模型,将其部署到项目中,并执行模型来预测结果和展示。
2 问题定义及数据准备
2.1 定义问题
这个项目将通过使用星载铷钟在真空环境下的遥测数据建立预测模型,数据集的每一行都是铷钟状态的描述。数据中包含以下4个特征和1 609条数据。选定的数据特征如下:
LV:铷钟灯电压;
LOCK:锁定信号;
LS:光强信号;
RU:铷信号。
2.2 导入数据
星载铷钟遥测数据集以.CSV的格式来存储,因此可以通过标准的Python库、NumPy、或者Pandas进行导入。由于在机器学习的项目中经常使用Pandas做数据清洗与数据准备工作,因此本项目使用Pandas导入数据集。通过Pandas导入数据需要使用pandas.read_csv()函数,该函数的返回值为DataFram,可以方便后续处理。
首先导入在项目中需要的类库,并导入数据集到Python中,本项目所导入的类库如图2所示,有numpy、matplotlib、pandas和sklearn,其中numpy是一种开源的数值计算扩展库,matplotlib是跨平台交互式环境的绘图库,pandas是基于numpy的为解决数据分析任务而创建的工具库,sklearn(全称scikit-learn)是开源的机器学习工具包。
导入项目类库后,为数据集中的相应数据特征定义名称,并将返回的DataFram命名为dataset,之后就可以开展数据分析理解工作了。

图2 模型预测需要导入的类库
2.3 理解数据
导入数据后需要进行分析,便于构建合适的模型。本项目使用dataset.shape方法观察数据维度,使用dataset.types观察数据特征。
本项目有1 609条记录和4个特征属性,如图3所示。
本项目所有的特征属性都是数字,并且都是浮点数,如图4所示。

图3 数据维度信息 图4 数据特征属性
使用set_option库对数据进行一次简单查看,该数据集的前21行数据如图5所示。

图5 数据特征
接下来分析数据的描述性统计信息。该信息中包含数据的最大值、最小值、中位值、四分位值等,分析这些数据能够加深对数据分布、数据结构等的理解,如图6所示。

图6 数据描述性统计信息
然后可以通过图7查看皮尔逊相关系数,或通过图8相关性矩阵图,找到数据特征之间的关系。

图7 皮尔逊相关系数
由皮尔逊相关系数和相关矩阵图可以看到,部分数据特征具有强关联关系。在机器学习建模中,当数据的关联性比较高时,有些算法(如linear、逻辑回归等)的性能会降低。所以在开始训练算法前,应对数据特征进行降维处理[7]。
3 算法评估及模型优化
3.1 数据分析
在评估机器学习建模的算法时,由于存在过度拟合的原因,不能将训练集直接作为评估数据集,一般将评估数据集和训练数据集完全分开,采用评估数据集来评估算法模型,这样做的目的是用来评判生成模型的准确度[8]。一般工程上会将数据总量的70%到90%分离出来用于模型训练生成,10%到30%用于评估算法模型。本项目分离80%的数据用于模型训练,20%的数据用于算法评估。
通过对本项目数据集的初步分析不难发现部分数据表现出线性分布的特征,因此选择弹性网络回归和线性回归等算法处理数据的效果可能较好。同时,考虑到数据集中不同时刻采样到的数据表现出了离散化的特点,因此在算法选择上也可以同时考虑引入决策树或支持向量机等算法。如何评估选择合适的算法,需要进一步评估。
本项目使用十折交叉验证法将数据集中的数据进行分离,再带入各个算法中产生模型预测结果。由于带入算法过程前分离了20%的数据用于算法评估,因此将预测结果与评估数据进行均方差计算,均方差值小的算法准确度高。
本项目选择三个线性算法和三个非线性算法进行比较。
线性算法:线性回归(LR)、套索回归(LASS0)、弹性网络回归(EN)。
非线性算法:分类与回归树(CART)、支持向量机(SVM)、K近邻算法(KNN)。
执行结果如图9所示。从结果看,CART具有最优的MSE,其次是LR和KNN[9-11]。

图9 原始数据集建模结果
3.2 评估算法
本项目数据集中的四个参数采用了不同的度量单位,这会影响机器学习的结果。因此需要先对数据集中的参数进行正态化处理,然后再次评估这些算法[12]。为了避免在数据正态化时出现数据采样偏差,使用Pipeline对模型进行评估。为了与前面的处理结果比较,采用与上面相同的均方差计算来评估算法模型。
从结果看,仍然是CART具有最优的MSE,其次是LR、KNN和SVM,其中SVM在数据处理后精度得到明显提高。执行后结果如图10所示。

图10 正态化后结果
3.3 优化模型
通过评估算法,发现几个优秀算法的准确度比较接近,这时可以使用集成算法进一步提高算法准确度。本项目使用以下两种流行的集成算法对表现较好的线性回归、K近邻、分类回归树算法进行集成。袋装算法(Bagging)是将训练集分离成多个子集,然后通过各个子集训练多个模型。提升算法(Boosting)是训练多个模型并组成一个序列,序列中的每一个模型都会修正前一个模型的错误。本项目采用以下四种模型:
袋装算法:随机森林(RF)、极端随机树(ET);
提升算法:AdaBoost(AB)、随机梯度上升(GBM)。
在分析算法时依然采用和前面相同的评估框架和正态化后的数据进行。执行后结果如图11所示。从结果看,线性算法和非线性算法的准确度都有提高,其中随机梯度上升算法的准确度最好。

图11 集成算法后结果
集成算法都有一个参数n_estimators,可以通过调整这个参数进一步优化算法的准确度。调参后程序给出最优的n_estimators结果为100,如图12所示。

图12 算法调参后结果
由此得到本项目最终的算法是随机梯度上升,参数n_estimators=100,然后通过该算法对象的.fit方法进行训练并生成最终的模型。使用模型对象的.predict方法就可以进行数据预测了。最后通过评估数据集来评估该模型的准确度。本项目使用了sklearn库的mean_squared_error模块来评估模型的准确度,以均方差来表示,最终结果为:5.077。
3.4 模型部署
模型部署是机器学习项目的最后一步,也是最重要的步骤之一。选定算法后,对算法训练生成模型,通过pickle或joblib将其序列化,并发布到硬件环境上。之后就可以利用机器学习解决实际问题,如对新产生的遥测与模型进行比较,并预测其变化趋势等[13]。
对于使用卫星遥测数据进行机器学习的结果既可以应用于卫星地面测试系统,提高测试系统的数据分析能力和趋势预报能力,也可以加载到星上嵌入式设备中,使卫星具备数据现场分析和预测的能力,这是卫星智能化的必要前提。
模型生成之后,也需要定期对模型进行更新,使模型处于最新、最有效的状态。
3.5 结果分析
对部署后的模型进行了预报能力评估测试,测试的工况选择卫星在轨运行期间需要经历的6种典型环境,因此将测试工况抽象为评估测试项A~测试项F。由于LOCK参数的数据聚合度较高,因此选择以参数LOCK为测试对象进行预报准确度评估。模型预测结果见下表所示。从测试结果看,模型预报的准确度优于6E-3,说明模型训练和优化的效果较好,能够起到数据分析和准确预测的作用。

表1 模型预测结果评估表
4 结束语
当前,我国卫星设计和在轨自主管理的智能化主要通过专家策略来实现,故障的类别与处理的过程是事先设计出来的,这对于典型故障的识别与处理有很好的效果,但由于无法充分挖掘星上遥测数据的价值,无法进一步预测故障类型,导致对于意料之外的故障往往束手无策。随着科技发展,卫星智能化是必然的趋势。卫星产生的绝大部分数据都将直接用于实时分析与处理,而不再需要生成遥测信息。作为卫星设计人员,找到人工智能技术在卫星设计和应用中的着力点,并利用机器学习的算法对大数据进行挖掘处理,是需要认真思考和实践的。
本文利用Python强大的生态环境和开源的算法,使用星载铷钟遥测数据,按定义问题、导入数据、理解数据、数据分析、评估算法、优化模型到结果部署七个步骤,详细介绍了模型建立的过程,该模型可用于星上数据的实时处理和预报,并使卫星具备实时自主控制的能力。本文是机器学习在卫星设计和应用上的探索,所使用的数据集为星载铷钟真空高、低温环境下开机过程的数据,因此训练出的模型是否适用于铷钟长期稳定后的状态还需要进一步测试验证[14-15]。
猜你喜欢
环球时报(2022-07-13)2022-07-13
科海故事博览·下旬刊(2022年4期)2022-05-07
探测与控制学报(2022年1期)2022-03-21
环球时报(2022-03-14)2022-03-14
计算机测量与控制(2021年9期)2021-10-08
电影(2018年8期)2018-09-21
价值工程(2016年32期)2016-12-20
考试周刊(2016年34期)2016-05-28
企业文化·中旬刊(2015年10期)2016-03-09
中小企业管理与科技·中旬刊(2014年10期)2015-02-03
