
基于句子级上下文内容的神经机器翻译方法
2021-02-22 10:47杨娇
计算机测量与控制 2021年1期
杨 娇
(商洛学院 人文学院,陕西 商洛 726000)
0 引言
基于短语的统计机器翻译(phrase-basedstatistical machine translation,PBSMT)[1-2]和神经机器翻译(neural machine translation,NMT)[3-4]在翻译语境中学习主题信息引起了广泛的关注。尽管取得了这样的成功,现有的方法大多数还是围绕着提前学习每个单词的固定主题分布,以在看不见的源语句中模拟单词主题。在实践中,词的主题往往根据句子的上下文动态变化,而不是静态的预先训练的分布。换言之,单词主题在很大程度上依赖于它们的句子级上下文,甚至一个单词在一个句子中可以有多个主题。然而,现有的NMT结构只关注与下一个目标词相关的源词级上下文信息,而忽略了基于句子级上下文的主题信息。
因此本研究以句子级上下文为研究对象,对源话题信息进行建模,并设计了一个话题关注度模型,将学习到的潜在话题表示融入到已有的NMT结构中,以提高目标词的预测能力。为此,首先通过卷积神经网络(convolutional neural networks,CNNs)的一个变体,将源语句上的源主题信息表示为潜在主题表示(latent topic representations,LTRs)[5]。然后根据单词上下文和主题上下文学习,用于计算用于预测目标单词的额外主题上下文向量。本文的创新点在于本研究的方法是动态而不是静态地学习每一个源语句的LTR,并通过主题注意而不是简单的向量连接将LTR集成到解码器中,同时对源词和译文进行联合而不是单独的修改。
1 CNN模型变体
在本研究中,主要采用了一种CNN变体,它基于句子级上下文捕获源主题信息,本节将具体介绍该CNN的网络结构,如图1所示。
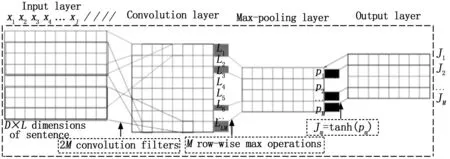
图1 所提出的CNN模型结构
考虑到CNN将话题信息隐式地映射到话题向量中,将这些向量称为LTR。与传统CNN的句子分类任务不同,在这里使用卷积层来学习2 MD维特征向量,因此,通过最大值合并行向量来提取MD维向量。提出的CNN网络结构如下。
1.1 网络结构中的输入层
vj∈D是与句子中第j-th个词相对应的D维词向量。因此,长度为J的句子被表示为D×J向量矩阵M。这里,将最大句子长度L设置为50。较短的句子用尾随的零填充。
1.2 网络结构中的卷积层
由2M个滤波器组成,每个滤波器Wm∈tD(1≤m≤2M)应用于M的t个连续行的窗口,产生特征,如式(1)所示:
(1)
其中:bm∈是一个偏倚项,Md:d+t-1是所有单词的d-th维到{d+t-1}-th维的连接。每个滤波器应用于输入矩阵M的每个可能窗口,生成特征向量D,类似于句子分类任务中编码源主题信息的特征向量Lm。依次使用2M滤波器遍历M生成特征映射L,其中L={L1,L2,…,L2M}。
注意,在建议的CNN的句子分类任务中,每个过滤器对所有词向量的组成行执行,而不是对局部词向量执行。在此期望学习每个特征值时考虑所有词的部分信息,期望最终的潜在主题表示依赖于句子级上下文而不是局部词级上下文。换句话说,一个特征值是从所有单词的特定向量空间而不是从局部单词向量中学习的。此外,本研究还设计了一个类似于句子分类任务的CNN结构。

图2 不同输入矩阵的对比
与图2(a)中的输入矩阵相比,长度J的句子被表示为J×D向量矩阵,而不是原来的D×J向量矩阵,如图2(b)所示。因此,每个过滤器都从本地单词嵌入中提取。
1.3 使用的最大池层
在L的连续行对上取行最大值, 如式(2)所示:
Pm=max(L2m-1,L2m),1≤m≤M
(2)
结果输出特征映射为P,P={P1,P2,…,PM}。注意,对最大池化操作应用于L2m-1和L2m-1以获得D维主题特征向量Pm。与句子分类任务的最大池相比,在这里使用D维主题特征向量Pm来表示输入句子中的主题,而不是主题特征值。众所周知,矢量表示具有更好的编码单词或主题信息的能力。同时,主题的矢量表示也更容易集成到现有的NMT架构中。
1.4 网络结构中的输出层
这将tanh函数应用于Pm以获得LTRTm,具体如式(3)所示:
Tm=tanh(Pm),T={T1,T2,…,TM}
(3)
T是提出的LTRs,稍后将用于学习NMT的主题上下文向量。学习T的模型参数如式(4)所示:
η={W1,W2,…,W2M;b1,b2,…,b2M}
(4)
2 句子级主题语境下的NMT
2.1 基于Attention机器翻译

(5)
其中:Si-1是根据原始单词上下文和建议的主题上下文计算的。
(6)
直观地说,NMT的目的是产生一个与源句意义相同的目标词序列,而不是产生相同的目标话题序列。换言之,在翻译预测过程中,主题信息可以起到辅助作用。因此,计算λi∈[0,1],这是一个门控标量[8],用于在时间步骤i为下一个目标词加权源主题上下文的预期重要性:
(7)

(8)
(9)

2.2 基于Transformer的NMT中的主题
在本节中,将介绍如何将提出的CNN集成到现有的NMT中,以共同学习LTR和翻译。本研究使用的NMT为基于Transformer的NMT[9]。
首先,提出的CNN作为编码器的附加模块,从输入源语句中学习LTR序列。其次,使用额外的多头注意力(multi-head attention)模块,学习基于前一解码器层的目标查询的新主题上下文表示。与原有的词级上下文表示方法相比,新的主题上下文表示方法侧重于获取句子级的主题信息,用于翻译预测。最后,主题上下文向量和原始单词上下文表示一起用于预测目标转换,如图3所示。

图3 基于Transformer的NMT网络结构
形式上,编码器的CNN模块首先从输入源T语句学习LTR序列。然后T被映射到一组键值对{K,V}={(K1,V1),(K2,V2),…,(KM,VM)}。在解码器中,多头自关注将先前解码器层Qi,K和V的目标查询转换为H次:
(10)

(11)
最后,将H子空间中的主题上下文向量连接为当前时间步主题向量Qi。根据文献可知,新主题上下文向量Qi和原始单词上下文向量Qi都用于通过线性,潜在的多层函数计算下一个目标单词的翻译概率,如式(12):
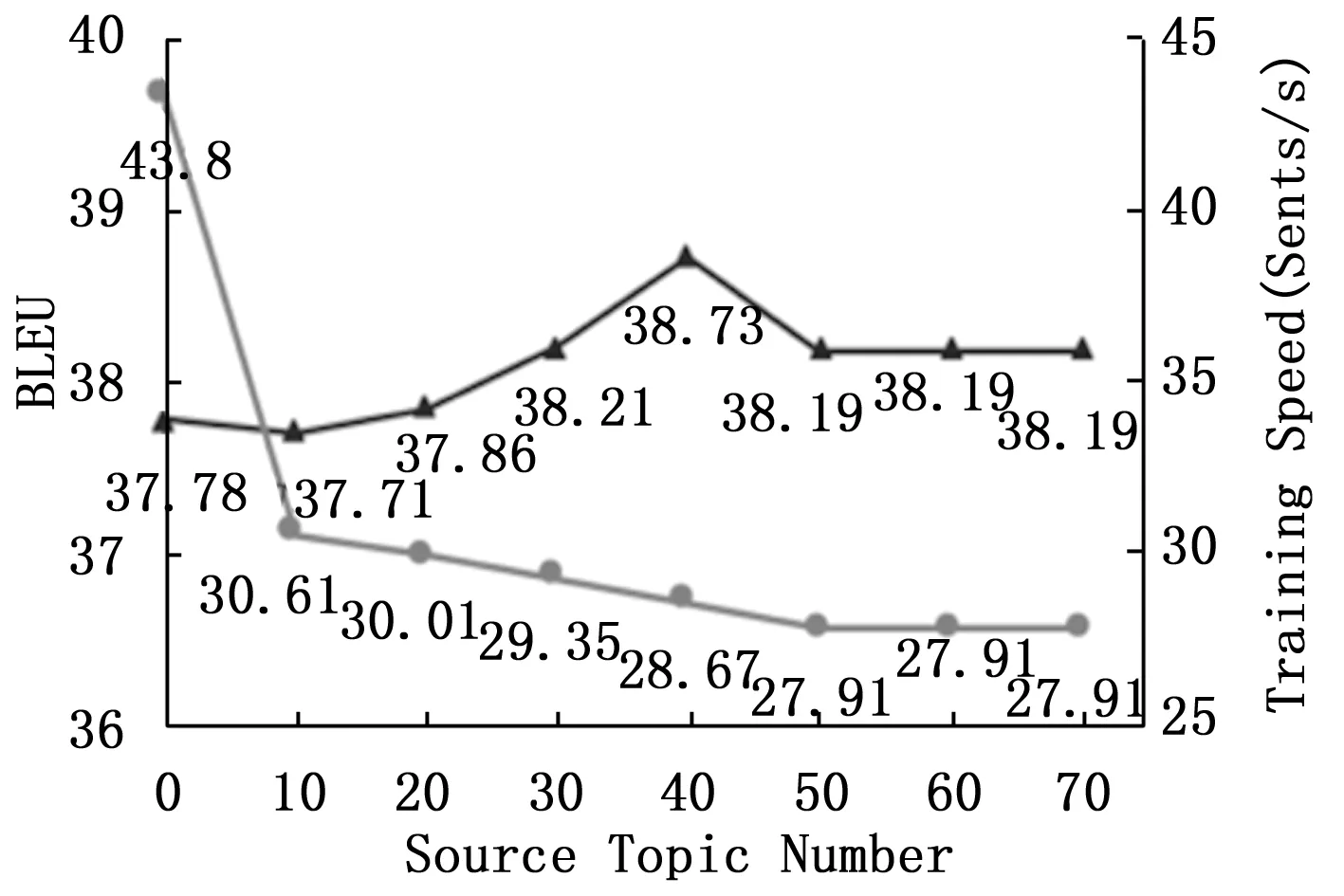
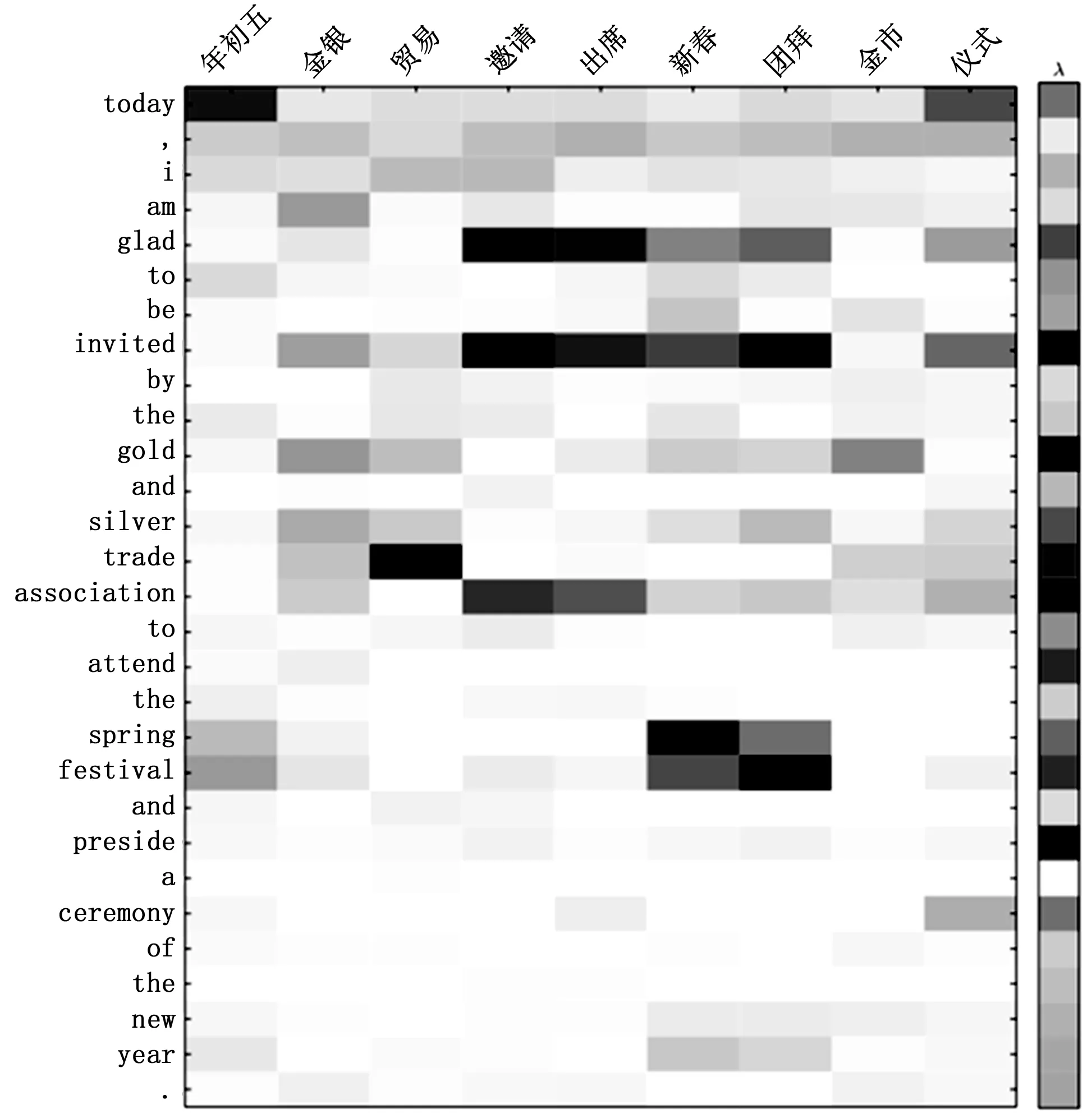
P(yi|y (12) 在这里Lo,Lw和LT代表投影矩阵。 与传统的主题方法相比,本文提出的LTRs通过神经网络对源主题进行隐式编码,这可能很难显示这些学习到的LTRs编码的主题信息。为了进一步了解源主题的有效性,设计了一种通过术语频率逆文档频率(TF-IDF)的显式主题表示方法[10]。具体地说,长度为Jg的输入句子被视为文档Xg,并为Xg中的每个单词xj计算TF-IDFTIj如式(13)所示: (13) 在这里中,nj,g表示输入句子dg中的第j-th个单词的出现次数;|G|是训练数据中源语言句子的总数;|g:xi∈Xg|是训练数据中包含单词xi的源句子的数目。然后选取固定百分比(实验中为40%)的高TD-IDT词,将其转换成词向量,形成一个主题T序列。 与以往的LTR相比,T是基于TF-IDF方法显式提取的,因此称为显式主题表示(explicit topic representations,ETRs)。最后,利用ETRs序列代替以往的LTRs序列,并将其集成到现有的NMT体系结构中,以增强翻译预测的注意对齐。 (14) T(θ*,η*)=argmaxθ*,η*T(θ,η) (15) 在这里使用两个翻译数据集对所提出的方法进行评估:一个用于LDC中英翻译(ZH-EN),另一个用于WMT’14英德翻译(EN-DE)。ZH-EN训练集包括118万个来自LDC语料库的双语句子对,而MT06和MT02/MT03/MT04/MT05数据集分别用作开发集和测试集。EN-DE训练集包括409万个WMT’14个语料库的双语句子对,而newstest2012和newstest2013/newstest2014/newstest2015分别用作开发集和测试集。 3.2.1 基于RNN的NMT的主题数和训练效率 图4显示了出了针对不同源话题的MT02上所提出的NMT模型的翻译性能和训练速度。随着话题数的增加,训练速度在开始时(从0到10)显著下降,然后(10之后)略有下降。对于NMT性能,当主题数从0增加到40时,BLEU从37.78增加到38.73;40后,BLEU开始随着主题数的增加而减少。很明显,当源主题数为40时,所提出的NMT在速度下降可接受的情况下表现最好。 图4 源话题数与BLEU和训练时间之间的关系 在这一节中,评估了基于Attention的NMT(ANMT)翻译性能结果,并与PBSMT[11],TiNMT[12],SFLTR[13],DWCont[14],LTR进行了比较。 表1显示了不同方法在测试集上的翻译性能。ANMT的平均成绩比PBSMT高出3.87个BLEU点,表明ANMT是一个很强的baseline。 表1 基于ZH-EN翻译结果 此外,表2列出了EN-DE任务的翻译结果以及40个源话题(与ZH-EN任务相同)。 表2 EN-DE翻译结果 从表2中可知,+LTR对ANMT和TiNMT进行了类似的改进,因此表明本研究的工作是改进其他语言对翻译的可靠方法。 3.2.3 基于不同构型的NMT网络的结果比较 在这一节中,在一个强大的baseline下,进一步评估了提出的方法。这个baseline是由一个标准的训练配置训练的。例如,采用字节对编码(BPE)算法[16],字节大小设置为32 k,所有输入输出层的维度设置为512,内部FFN(feedforward neural network)层的维度设置为2 048。一方面,对于基于RNN的NMT模型,另一方面,与3.2.2节的设置相同;另一方面,对于基于Transformer的NMT模型,在8 000个预热步骤下,学习率有所变化,模型(基础)被训练了大约20万个批次。所有模型都在一个P100 GPU上进行训练和评估。SacreBELU[17]被用作EN-DE任务的评估指标,并且-bleu.perl语言作为ZH-EN任务的评价指标。 这些转换结果如表3和表4所示。新的baseline,包括ANMT和Transformer,优于表1和表2;特别是新的Transformer(base)的BLEU得分与文献[9]中展示的结果相同。这表明本研究的baseline是强大的比较系统。在表3和表4中,+LTR和+ETR都优于Transformer(base),这表明所提出的句子级主题信息有利于NMT。+LTR取得了与表3和表4中的+ETR相当的性能,这意味着这些学习到的LTR能够捕获源主题信息。+LTR优于+SFLTR,说明动态注意主题语境比单一固定主题更能有效地预测目标词。+LTR的性能优于+DWCont,并且它们都有相似的模型参数。这表明改进来自句子级的主题信息,而不是更大的模型参数。+ETR和+LTR的BLEU评分均优于文献[9]在Transformer(big)模型中。这表明提出的方法提高了翻译性能。 3.2.4 输出样本研究 如图5中示例1,在此将所提出的方法与ANMT对淡色源汉语单词“xinchun”的翻译进行了比较。直观地说,本研究提出的LTR和ETR利用句子层面的语境来编码源话题,如经济、仪式、中国和其他潜在话题。通过注意机制,本研究的方法学习了一个额外的话题语境向量,该向量聚焦于源话题,仪式和中国,以正确地将“xinchun”翻译为“springfestival”,而不是“newyear”。此外,通过图6中的显式主题对齐可视化验证了这些观察结果。例如,译文“spring”和“festival”有着相似的主题词,如“nianchuwu”,“xinchun”,“tuanbai”。 表3 基于Transformer的NMT翻译结果 表4 基于RNN的NMT翻译结果 图5 具体翻译示例 图6 结果对齐可视化 图5的示例2显示了所提出的方法与ANMT之间的其他源汉语单词“neidi”的翻译。同样,可能有多种来源的话题,如经济、中国、政治和其他潜在话题。直观地说,当不考虑源语话题(或句子层面的语境)时,源语“neidi”可以译为“大陆(mainland)”或“内地(inland)”。总的来说,翻译“内地”与话题地理密切相关,而翻译“大陆”则与话题政治密切相关。在提议的LTR和ETR中,主题关注的焦点是中国和政治,选择翻译“大陆”而不是“内地”。 本研究探讨了源话题信息对句子层面语境的依赖性,并提出了一种话题注意方法,将潜在话题表征整合到现有的NMT结构中,以提高翻译预测能力。在未来的工作中,将利用显式的源主题信息来增强NMT中的目标词预测。2.3 显式主题表示
2.4 训练模型

3 实验与评估
3.1 数据集与设置
3.2 结果与评估





4 结束语
猜你喜欢
艺术生活-福州大学厦门工艺美术学院学报(2022年1期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
阅读(快乐英语高年级)(2020年8期)2020-01-08
疯狂英语·爱英语(2020年9期)2020-01-07
疯狂英语·爱英语(2020年9期)2020-01-07
智慧少年·故事叮当(2018年11期)2018-05-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
时代英语·高二(2015年1期)2015-03-16
