
基于数据驱动与数据包络分析的运动队成绩预测
2021-02-21 13:45:02符巍
山东体育学院学报 2021年4期
符巍








摘要:提出一种基于数据包络分析方法和数据驱动多元逻辑回归的运动队成绩预测方法。首先进行多元逻辑回归分析,以检查运动队获胜概率与比赛结果之间的关系。其次利用基于数据包络分析的球员组合效率分析,从而最优的选择球员并安排场上球员的比赛时间。然后利用球员和球队的历史数据来进行训练,从而获得预测结果。最后,将提出的成绩预测方法应用于美国国家篮球协会,并以金州勇士队为例来说明其有效性。结果表明基于数据包络分析的多元逻辑回归方法可以很好地预测运动队的成绩,并且还可以提供与成绩相关的决策策略。
关键词:数据包络分析;多元逻辑回归;成绩预测;数据驱动;运动队
中图分类号:G80-059文献标识码:A文章编号:1006-2076(2021)04-0102-10
Performance prediction of sports teams based on data driven and data envelopment analysis
FU Wei
Dept. of P.E., South China Agricultural University, Guangzhou 510642, Guangdong, China
Abstract:A method of performance prediction based on data envelopment analysis (DEA) and data-driven multiple logistic regression was proposed. Firstly, the multiple logistic regression analysis was carried out to check the relationship between the winning probability of the sports team and the result of the competition. Secondly, the efficiency analysis of player combination based on DEA was used to optimize the selection of players and arrange the game time of players. Finally, the performance prediction method was applied to the National Basketball Association of the United States, and the Golden State Warriors was taken as an example to illustrate its effectiveness. Results show that the multiple logistic regression method based on DEA can predict the performance of sports teams well, and can also provide decision-making strategies related to performance.
Key words:data envelopment analysis; multiple logistic regression; performance prediction; data driven; sports team
现如今,对未来的绩效准确预测可以使各种行动和目标受益,例如资源分配、生产调整、收入管理等。此外,绩效预测对于为这些生产部门设定发展目标也至关重要。例如,制造商将基于各个方面的生产效率预测来制定生产计划;一个国家可以通过进行良好的生产分析和预测,很好地起草和管理国家经济计划。而集体运动的成绩预测近年来引起了越来越多的关注,可用于设计训练和比赛计划。在真正的管理应用程序中所有这些成绩预测应用程序中,最重要的领域之一是体育行业。成绩预测和分析与相关教练、球员、体育科学家、投资者和成绩分析师利益攸关。
在过去的几十年中,全世界的体育运动越来越引起人们的关注。体育产业在全球范围内赢得了巨大的价值和收入,其中美国国家篮球协会(NBA)是最有价值的联赛之一,在该联盟中,2019年NBA球队的平均特许经营价值仅为19.23亿美元。NBA凭借其转播权、广告和商品销售已成为最大的体育业务之一。为此,经理或教练将专注于对未来可能表现的分析,并相应地调整团队设置。
运动队成绩研究中通常使用回归方法和贝叶斯推理以及神经网络等方法,例如,杨若愚集成了贝叶斯推理,基于规则推理和比赛时间序列方法来预测足球比赛的结果。AMATRIA M等分析了评估运动参与者能力和获胜概率的几种不同方法,并将这些方法进一步整合到一个通用框架中,以预测2008年欧洲足球锦标赛的结果。ARABI B等基于1908年至2012年的21 639名运动员的样本,应用了逻辑回归模型来检验相对年龄对运动表现的影响。刘天彪等使用多项式逻辑回归来确定与中超联赛球队质量相关的技术成绩变量。所有这些方法都解决了性能预测问题,但是运动成绩可能会受到鲜为人知的事件或极端事件的影响。
数据包络分析,这是一种用于性能评估的非参数生产前沿方法,该方法考虑了可变规模收益假设,因此获得了不受规模效应影响的纯技术效率,由于其有效性,在医学、体育、教育、金融等领域得到了广泛的应用。数据包络分析方法学擅长处理多个输入和多个输出;其次,它考虑了各种投入和产出之间的权衡;另外,这种非参数方法不使用任何主观权重,这在开发成绩预测方法时显示出极大的灵活性。许多学者开发了基于数据包络分析的方法来评估NBA球队和球员的表现,因为球员交易在NBA中非常普遍,而數据包络分析方法提供了考虑不同球员组合的预测比赛结果的机会,这非常适合教练处理此类工作的NBA运作。此外,可以进行基于数据包络分析的实验和模拟来找到可以确定最大获胜概率的最佳球员组合,这个因素无法被忽略,因此可以很好地预测NBA球队的表现。例如,GOMEZ M等使用网络数据包络分析方法评估了NBA球队的效率,并且作者还计算了可能减少的球队预算和球队赢得的比赛。KOSTER J等还评估了网络环境下NBA的球队效率,并且作者使用了附加的两阶段分解框架来估计工资效率和场上效率。LEE BL等使用动态网络数据包络分析模型来解决篮球比赛的效率,并且作者考虑了主场球队和客队之间的差异。几乎所有数据包络分析模型都是为基于预先指定的输入和输出数据进行事后效率分析而设计的,很少有研究着眼于未来的性能预测。数据驱动的提出,从正在考虑的大量数据到数据背后的知识和信息,高度评价了数据的价值,如何充分挖掘大数据下隐藏的可用信息也逐渐成为研究热点。
在本文中,基于数据包络分析与方法开发一种数据驱动多元逻辑回归的运动队成绩预测方法,提出的方法將应用于美国国家篮球协会,以验证其有用性和有效性。
1问题与方法
1.1问题设定
对于任何一支NBA球队,假设下赛季将列出n名球员。为了简化研究,假设不存在参与者交易。此外,假设没有球员受伤,可以分配所有球员的上场时间和下赛季的比赛。对于预先指定的数据样本,此NBA球队记录了q场比赛,且第pp=1,…,q场比赛的比赛时间tp>1,比赛结果xpr≥0r=1,…,s。此外,对于每一位球员j=1,…,n,他在第p场比赛的总时间tpj≥0内,所获得的输出数据xprj≥0。
在一个赛季中,教练将在所有球员之间分配比赛时间,并预测每位球员获得相应的胜利贡献值。然后,将其参与者汇总的总结果转换为可能的获胜概率。因此如何在球员之间分配上场时间,从而在下一个常规赛中使得所有82场比赛的获胜概率和预期获胜次数最大化。
对于常规的篮球比赛,将有四节比赛,每节持续12 min,因此t0=12*4。同时,场上允许同时有5名球员,即n0=5。因此,总共的比赛时间n0*t0=240将分配给这n名球员,每名球员将通过在场上比赛获得一些结果。最后可以通过将单个球员的结果相加,可以预测整个团队的量化总结果。此外,总收益将根据比赛结果与获胜概率之间的数量关系转换为可能的获胜概率,并且这种获胜概率可以作为考虑的NBA球队的未来表现预测结果。可以通过一种有效的方式分配上场时间最大化某个目标函数f,这个基本的预测模型可以表述为模型(1):
maxf=f(t1,L,tn)
s.t.∑nj=1tj=n0×t0(1)
0≤tj≤t0,j=1,L,n.
目标函数f是球员比赛时间的函数,通过适当分配总比赛时间no·t0,目标函数f可以最大化。如果f是单个目标函数,则最佳预测结果将仅与一个球员的比赛时间有关。但是,像NBA这样运动中,影响结果的因素很多,因此需要使用回归方法来获得多目标函数的公式,该公式可以显示获胜概率与分配给个人球员的上场时间之间的数量关系。进一步通过数据包络分析的生产前沿方法将上场时间tj(j=1,…,n)转换为各种输出xrjr=1,…,s;j=1,…,n,因此只需要估计获胜概率和各种结果之间的数量关系即可。
1.2DEA数学建模
为了解决性能预测问题,需要指定在预定的时间段内可能的效率或低效率状态。为此,应该首先对球员和整个球队进行效率评估。效率分析的方法有很多种,本文基于一种称为数据包络分析的生产层方法提出了效率分析的方法。该方法利用历史数据构建一个效率边界,在此边界上对所有决策单元进行预测,并将实际单元与这些预测进行比较,以评估它们的相对效率。该模型具有内生方向矢量的基于松弛的方向距离函数(DDF)模型,以最大化期望的输出并且同时最小化不期望的输出。此时只考虑基于输出的基于松弛的方向,因为:(1)只有一个输入(即比赛时间);(2)可以很容易地证明,如果只考虑一个输入,则基于最优输出余量的低效率DMU的投影将非常有效;(3)最优方向向量是非径向的,因此模型在存在非零松弛的情况下不会高估效率。对于最佳方向矢量,可以参考文献\。因此可以根据不期望的输出的可行的减少和期望的输出的可行的增长来估计最大的效率低下。根据文献\计算球员jj=1,…,n的每个度量的无效率比ρ+orj,ρ-orj。
尽管在预测期间球队和球员的可能效率未知,并且充满不确定性,但效率的可能近似值是过去几个赛季中的平均效率得分,因此可以得到每种度量的加权平均无效率,其中以第oo∈Pj场比赛的比赛时间作为每个独立无效率比的权重ρ+rj,ρ-rj。
为了进行基于数据包络分析的性能预测,认为平均无效率比ρ+rj,ρ-rj和ρ+r,ρ-r是球员和团队分别在预测期内的无效率状态的良好代表。这个假设可以与以下观察结果相联系:基于对手的表现,表现良好的球员和球队在比赛中的表现可能要好于对手。
在预测模型中,决策变量tj是球员j的比赛时间,xrj是其相应的最优结果,λkj是用于构建每个球员j(j=1,…,n)的效率边界的强度变量。第一个约束意味着所有球员分配的上场时间与单个比赛的总比赛时间精确相加,而随后的4个约束则确保预测期内每个球员的计划投入产出在生产可能集(PPS)内,它是在变量回归比例(VRS)假设下,利用历史数据构建的。这里,计划投入产出和加权无效率比的乘积给出了一个无效率松弛,这可以被描述为在预测期内采用的无效率状态。约束条件x^r=∑nj=1xrj表示团队的输出仅来自所有球员的输出。另外,剩下的3个约束被用来确保预期的输出在团队的生产可能性集合内。同样,团队的平均低效率比率也被强加给了团队。为方便研究,消除对团队比赛时间的限制,因为考虑的是一个正常的比赛环境,并且团队比赛时间对于所有比赛都是相同的。
预测模型开发了一个基本框架来处理预测,但是仍然可以添加额外的约束。通过保持每个度量的加权平均无效率,可以计算最大可能的获胜概率P。假设每个常规赛季每队有N场比赛,则预期的获胜次数将被统计为N·P。 特别是,在NBA常规赛中,预期的比赛获胜次数将表示为82P。
数据包络分析方法是运筹学、管理科学与数理经济学交叉研究的一个新领域。DEA评价结构框图如图1所示。
2应用实例
2.1数据描述
在本节中,使用金州勇士队从2011—2012赛季到2014—2015赛季的数据来预测下一个2015—2016常规赛季的理想表现。此外,出于以下两个原因,将删除那些超时的比赛:一方面,将为虚拟比赛分配240 min的总比赛时间,而这些超时的比赛的总比赛时间将超过该值。另一方面,在标准比赛时间(即240 min)内,由于这些比赛以平局结束,因此很难将这些加时赛的输赢结果量化为一或零。另外,本文忽略了进行了48 min以上的比赛。从篮球参考(http://www.basketball-reference.com/)获得了金州勇士队及其14名球员的经验数据,如表1和表2所示。
2.2初步预测结果
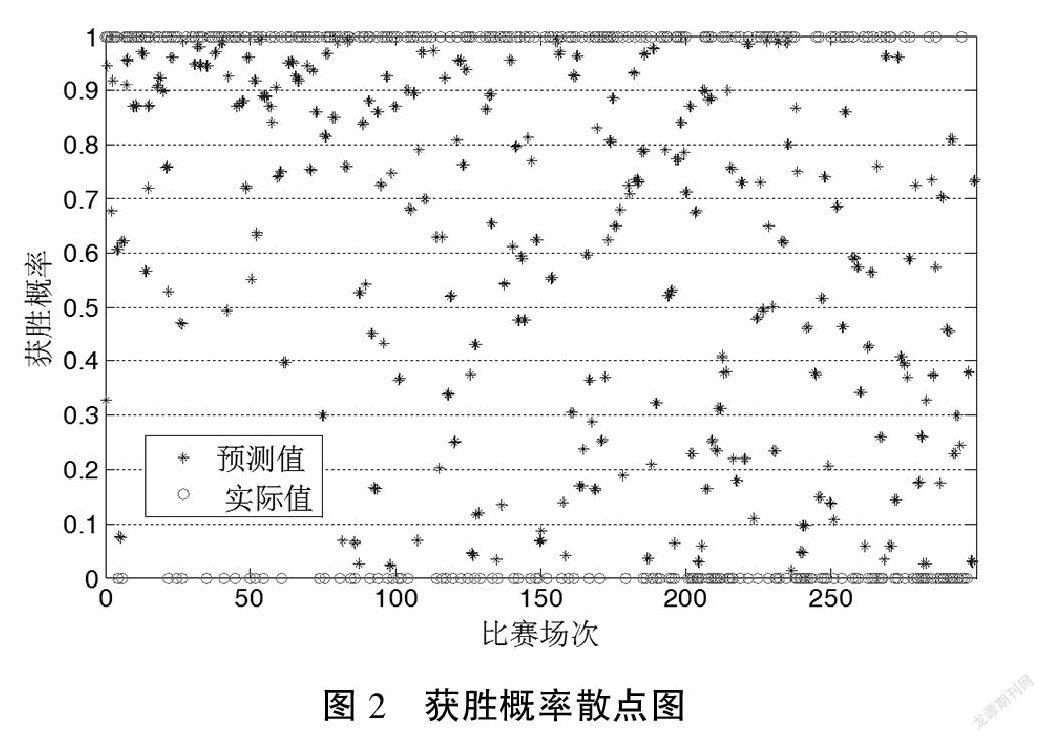
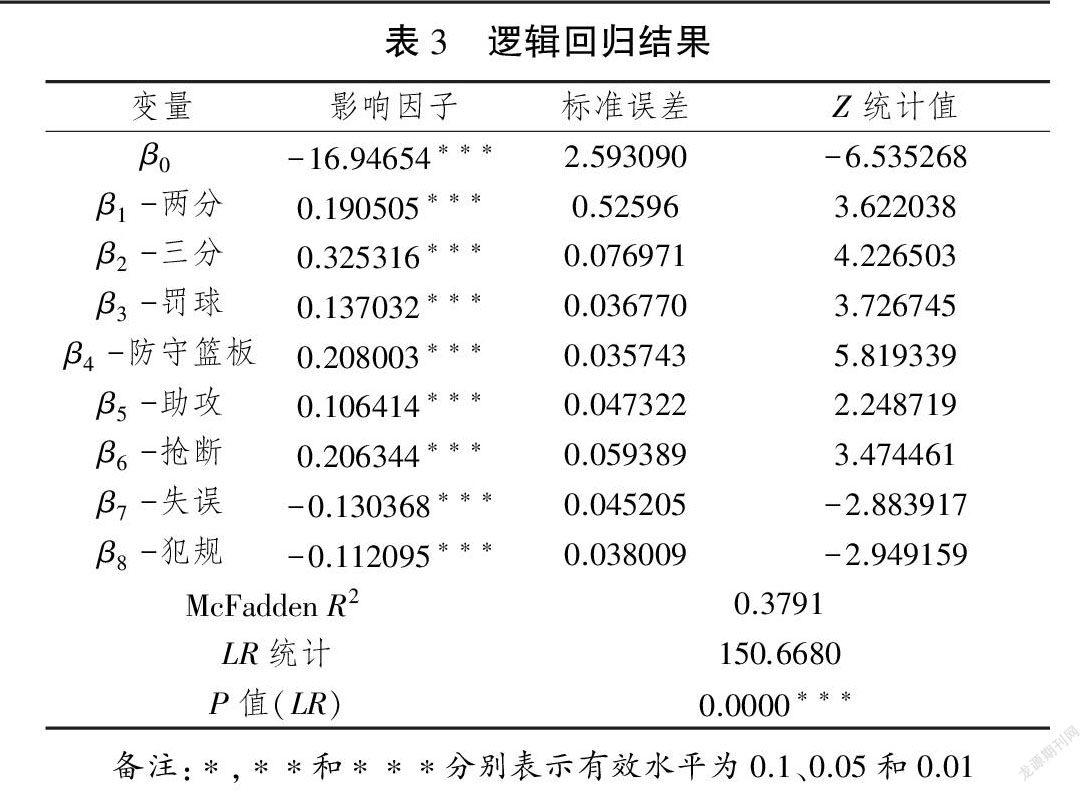
首先,使用团队结果数据进行逻辑回归分析,结果在表3和图2中给出,結果发现逻辑回归方程可以很好地拟合获胜概率。实际上,如果将阈值设置为50,那么在297场比赛中只有53场与实际结果不一致。因此,准确性可以接近82.15。 McFadden和LR统计也证明了该方法具有良好的适用性。以上所有发现表明,可以使用估计的回归方程来说明各种比赛结果与获胜概率之间的数量关系。因此,将在性能预测模型中使用的目标函数给出如下:
F=-16.94654+0.190505*两分+0.325316*三分+0.137032*罚球+0.208003*防守篮板+0.106414*助攻+0.206344*抢断-0.130368*失误-0.112095*犯规(2)
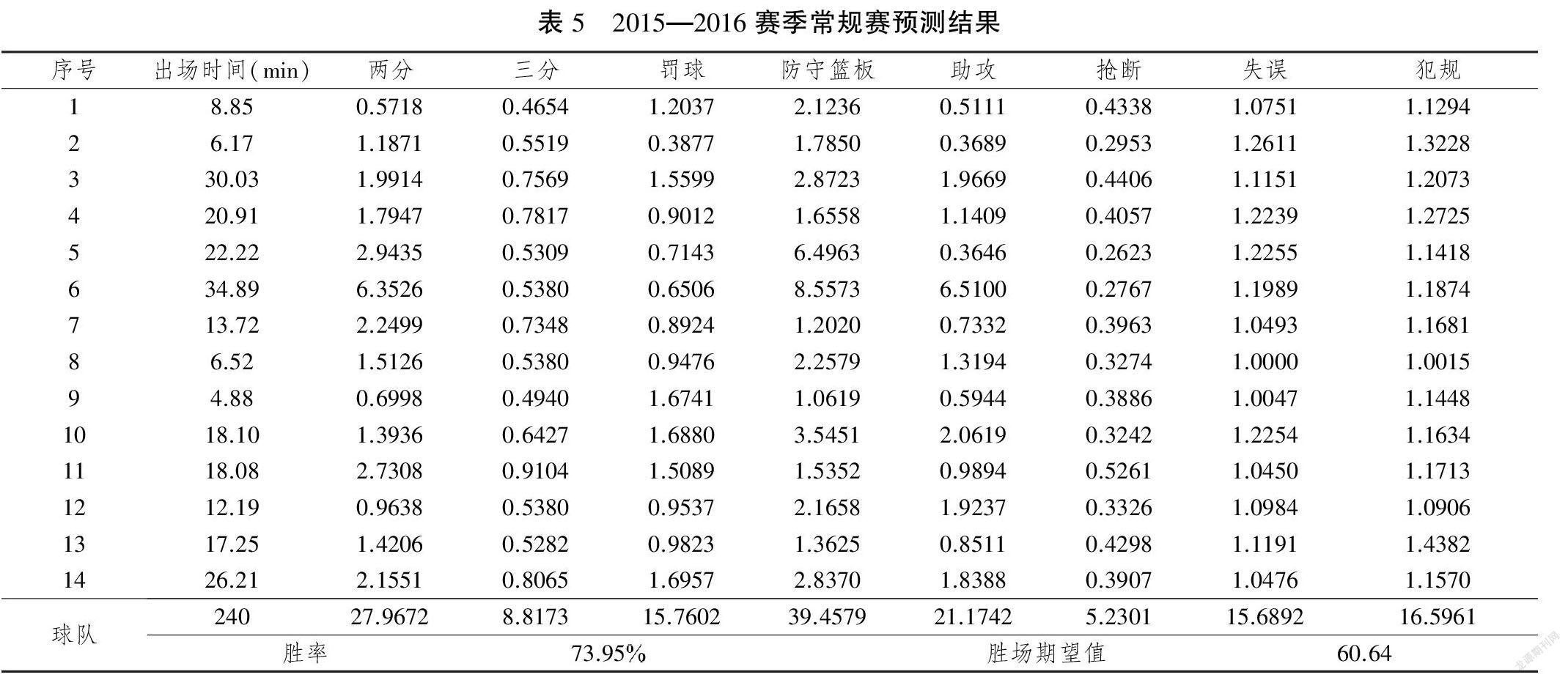
进攻篮板和盖帽不考虑在回归方程式中,因为它们的两个估计参数都不具有统计意义。此外,可以通过对比赛时间进行加权来获得平均无效率比率,如表4所示。进一步将这些结果纳入DAE模型中,以最佳分配比赛时间,并获得下一个2015—2016赛季常规赛预测的期望结果,如表5所示。
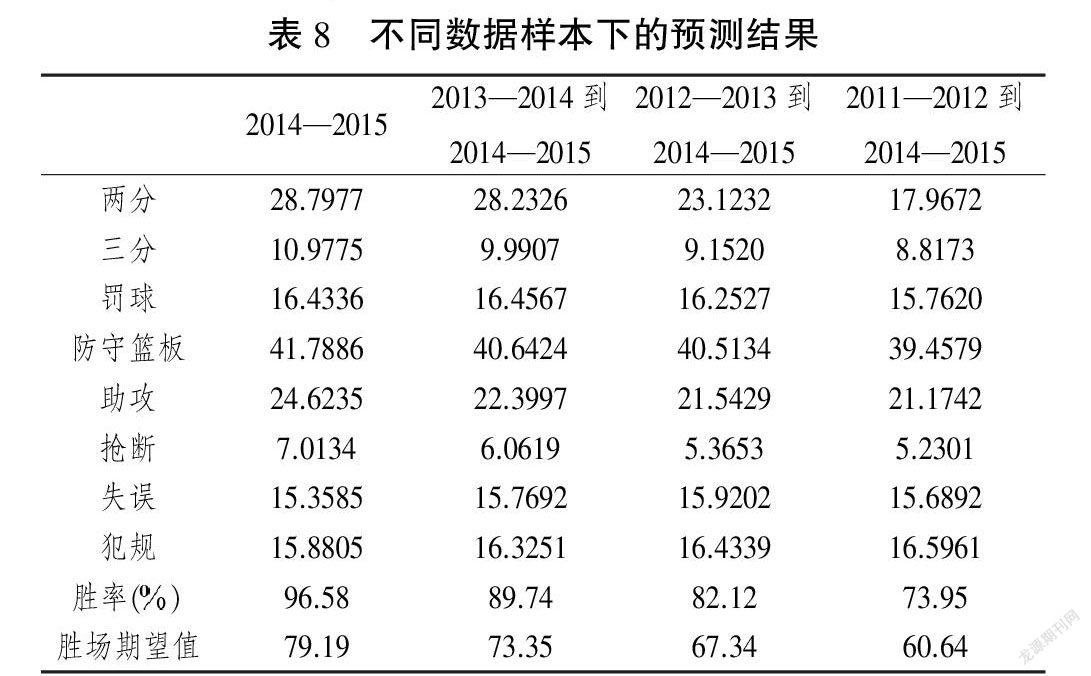
根据表5,可以得出结论,通过最佳选择球员并分配上场时间,金州勇士队的最佳获胜机率是73.95,2015—2016赛季常规赛的预期胜利将是60.64。获得该结果的一个基本假设是在预测方法中采用平均无效率比率来表征球员和球队的无效率状态,因此从统计上看,平均无效率比率是暂时的冲击,不应影响整体预测结果。金州勇士队在2015—2016赛季打破了NBA的纪录,获得了73场胜利,因此可以得出结论,提出的预测方法可以提供良好的预测结果。同样,可以验证金州勇士队在整个赛季中的表现都非常出色,因为实际获胜的概率甚至比预期的更高。该结果还可能存在如下原因:从2011—2012赛季到2014—2015赛季,金州勇士队的获胜概率呈上升趋势,因此,基于四季数据集的平均无效率比率可能会低估金州勇士队的潜力。此外,根据表5中的结果,可以说安德森·瓦雷乔、斯蒂芬·库里、哈里森·巴恩斯,安德鲁·博古特和安德烈·伊瓜达拉是金州勇士队中最有价值的前5名球员,因为他们应该获得大多数得分,此外,这些球员还获得了许多其他成果。
DAE预测方法可以获得唯一的最佳目标函数,因此预测的获胜概率是唯一的,但是解决方案可以是多个。一旦添加一些其他约束,解决方案可能会更改。例如,在许多实际应用中,教练倾向于将一些球员安排给其他人,特别是那些顶级球员在世界各地都有很多球迷,他们的出场时间将有利于门票收入,因此,教练将为那些顶级球员分配比其他人更多的比赛时间。考虑前面讨论的情况,这5个首发球员的预期比那些替代者的比赛时间更长。正如金州勇士队宣布的那样,克莱·汤普森、安德鲁·博古特、德雷蒙德·格林、斯蒂芬·库里和哈里森·巴恩斯是2015—2016赛季常规赛的首发球员。通过再次求解DAE模型,在表6中获得了新的预测结果。如表6所示,预测获胜概率将保持不变,但是不同球员所上场时间的分配和相应的比赛结果将有很大差异。同样,将重点放在得分最高的有价值球员上,他们将排在斯蒂芬·库里、安德森·瓦雷乔、德雷蒙德·格林,哈里森·巴恩斯和安德鲁·博古特的行列,该结果与先前获得的结果非常相似。
另外,将比较本文方法与其他一些预测方法的预测结果。尽管许多学者在NBA中建立了运动成绩预测方法,但普遍的缺点是预测准确性低,并且这些方法都没有被广泛接受。考虑体育行业从业者和体育迷广泛使用的两个预测结果:一个由娱乐体育节目网络(EPSN,www.espn.com)提供,另一个由FiveThirtyEight(fivethirtyeight.com/sports)提供。ESPN使用一种称为“篮球实力指数(BPI)”的前瞻性方法来衡量球队的素质,它使用高级统计分析来衡量每支球队相对于平均球队的攻防水平。BPI可以用来预测给定球队的平均得分和获胜概率。ESPN的BPI被宣称是最成功的预测方法之一,它已经赢得了NBA比赛的72以上。相反,FiveThirtyEight将基于Elo的模型与所谓的CARM-ELO球员预测:一种将当前NBA球员与整个联盟历史上类似球员进行比较的系统,以预测NBA球队的“CARM-Elo”评级,预期数量输赢和进入季后赛的可能性。可以在网上找到这两种方法的结果,但是有关其预测模型和技术参数的信息有限,因此仅将预测结果与数学值进行比较。
ESPN得到了60胜22负的预测结果,而FiveThirtyEight预测了金州勇士队的季前赛结果也相同,比较结果示于表7。首先,当金州勇士队打破NBA纪录并获得73胜时,包括本文在内的所有3个预测都低估了获胜的可能性和预期的获胜次数。此外,可以看出,本文提出的预测方法与ESPN和FiveThirtyEight提供的预测结果极为接近,而本文提出的方法预测精度较高。这一发现表明,本文预测方法具有与ESPN和FiveThirtyEight相似的预测结果,考虑到金州勇士队创造了新记录,在2015—2016年的理由甚至更好。由于ESPN和FiveThirtyEight都是成功的预测方法的典范,通过比较分析,可以得出结论,基于数据包络分析的数据驱动方法在运动队成绩预测中具有相对较好的预测效果。
2.3讨论与分析
在上一节中,以“金州勇士”为例来说明提出的数据驱动预测方法的有用性和有效性。在下面的部分中,将对所提出的预测方法及其应用结果进行进一步的讨论,以展示如何将其用于对问题进行深入了解。
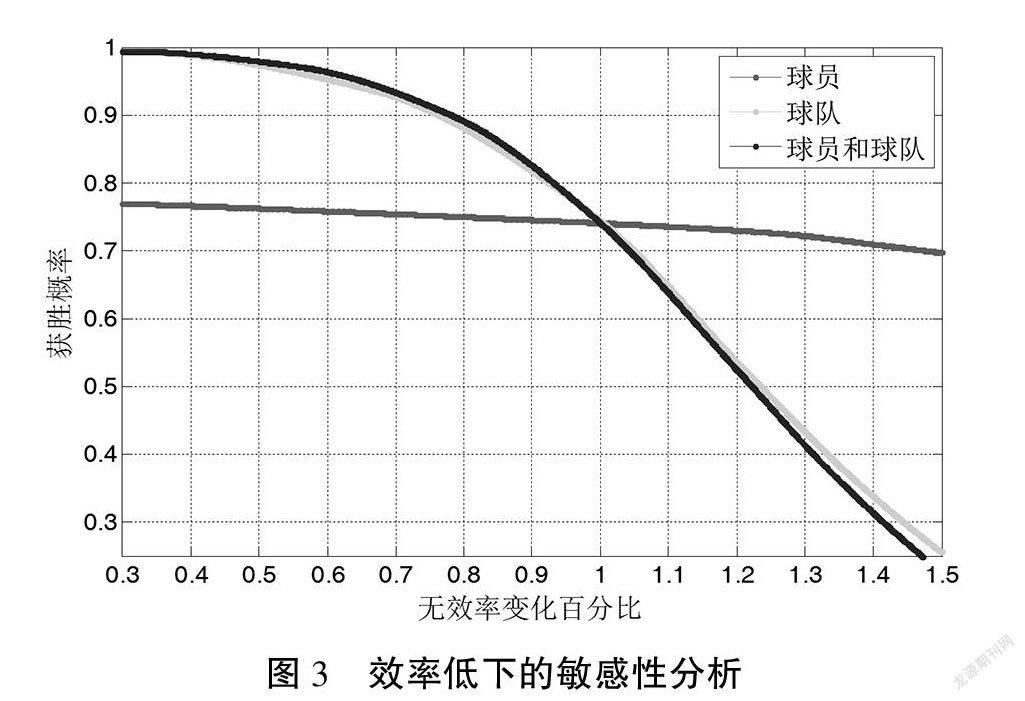
在DEA模型中,通过假设所有结果的无效率均恒定来进行确定性的最佳性能预测。但是,会有一些不确定性。考虑了球员、整个球队以及球队和球员同时处于低效率状态的不确定性,关于无效率变化率的灵敏度分析结果如图3所示。结果发现,与球员相比,最佳获胜概率对团队效率低下概率的变化更加敏感。这是因为对于像NBA这样的集体运动,并不是每个球员在同一场比赛中都会表现好或者坏。实际上,在几乎所有比赛中,有些球员会表现得很好,而其他球员则会表现得不好。结果,整个团队将同时获得来自表现出色的球员和表现不好的球员的比赛结果。因此,当强加团队的生产可能集和生产前沿约束时,团队的无效率比率是一个敏感因素,而球员的无效率比率则较不敏感。从这个角度出发,建议金州勇士队的经理和教练更加注意团队合作与沟通,并努力消除更多的团队效率低下的情况。
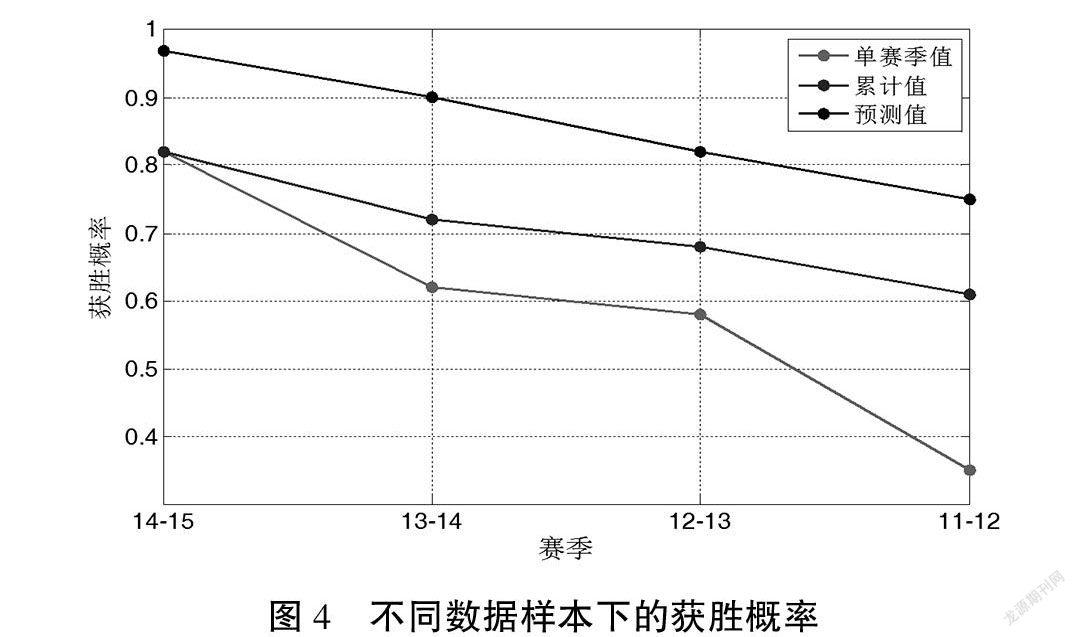
显然,所提出的预测方法是数据驱动的,结果将基于数据,因此不同的数据样本可能会导致不同的结果。先前获得的结果基于从2011—2012赛季到2014—2015赛季的4个季节的数据样本,通过使用最新的2014—2015赛季,在这里将考虑另外3个样本,分别只有1个赛季、2个赛季和3个赛季。以相同的方式解决了所提出的预测方法,预测结果如表8所示。结果表明预测的获胜概率将减少样本量,这是因为金州勇士队在2011年至2015年的常规赛中赢得了越来越多的冠军,其平均无效率比越来越小。图4显示了不同数据样本下的获胜概率,其中涉及每个赛季的实际获胜概率、基于不同样本的累积获胜概率和预测获胜概率。因此,预测结果也将越来越好。尤其是,基于2013—2014和2014—2015两个赛季的结果非常接近2015—2016常规赛季的真实结果,当时金州勇士队打破了NBA纪录,获得了73场胜利。
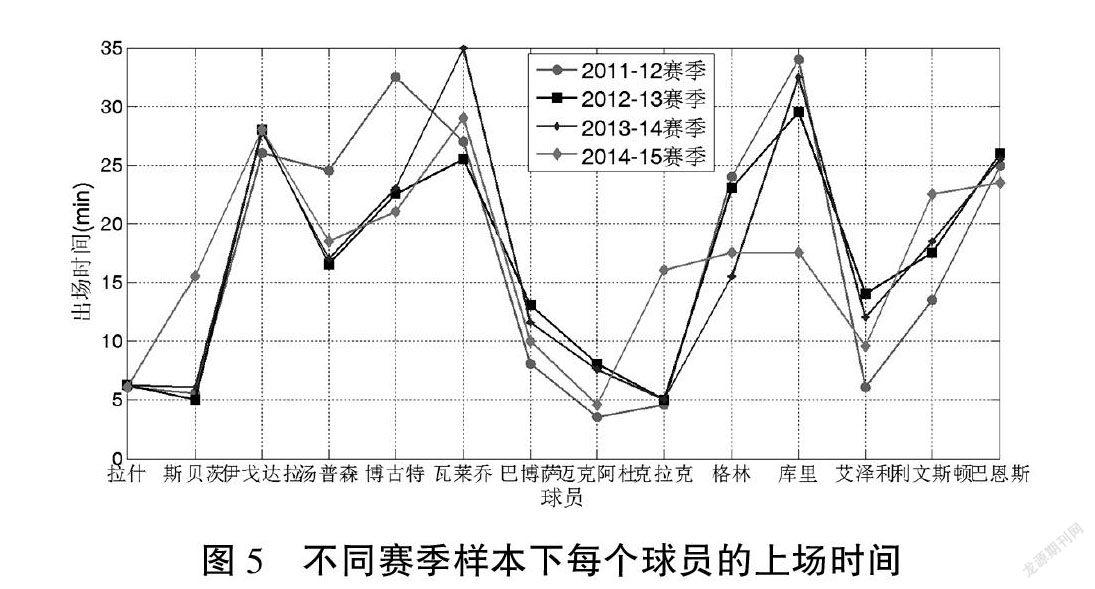
图5显示了在不同数据样本下每个球员的比赛时间,可以看出,尽管存在一些变化,但是球员表现出主要趋势,这意味着具有最佳球队获胜概率的比赛时间是相对稳定的。
在此,还将给出最小的成绩,同时还要给出由DEA模型计算的平均无效率比率,如表4所示。为解决最小获胜概率预测问题,提出如下目标函数:
Minf^=β0+β1x^1+…+βsx^s
s.t.∑nj=1tj=n0·t0
∑k∈Ejλkjtkj=tj,j=1,…,n
∑k∈Ejλkjxkrj=xrj+ρ+rjxrj,r=1,…,m;j=1,…,n
∑k∈Ejλkjxkrj=xrj-ρ-rjxrj,r=m+1,…,s;j=1,…,n
∑k∈Ejλkj=1,j=1,…,n
∑nj=1xrj=x^r,r=1,…,s(3)
∑l∈Eλlxlr=x^r+ρ+rx^r,r=1,…,m
∑l∈Eλlxlr=x^r-ρ-rx^r,r=m+1,…,s
∑l∈Eλl=1
0≤tj≤t0,j=1,…,n
λkj,λl≥0,j=1,…,n;k∈Pj;l=1,…,q.
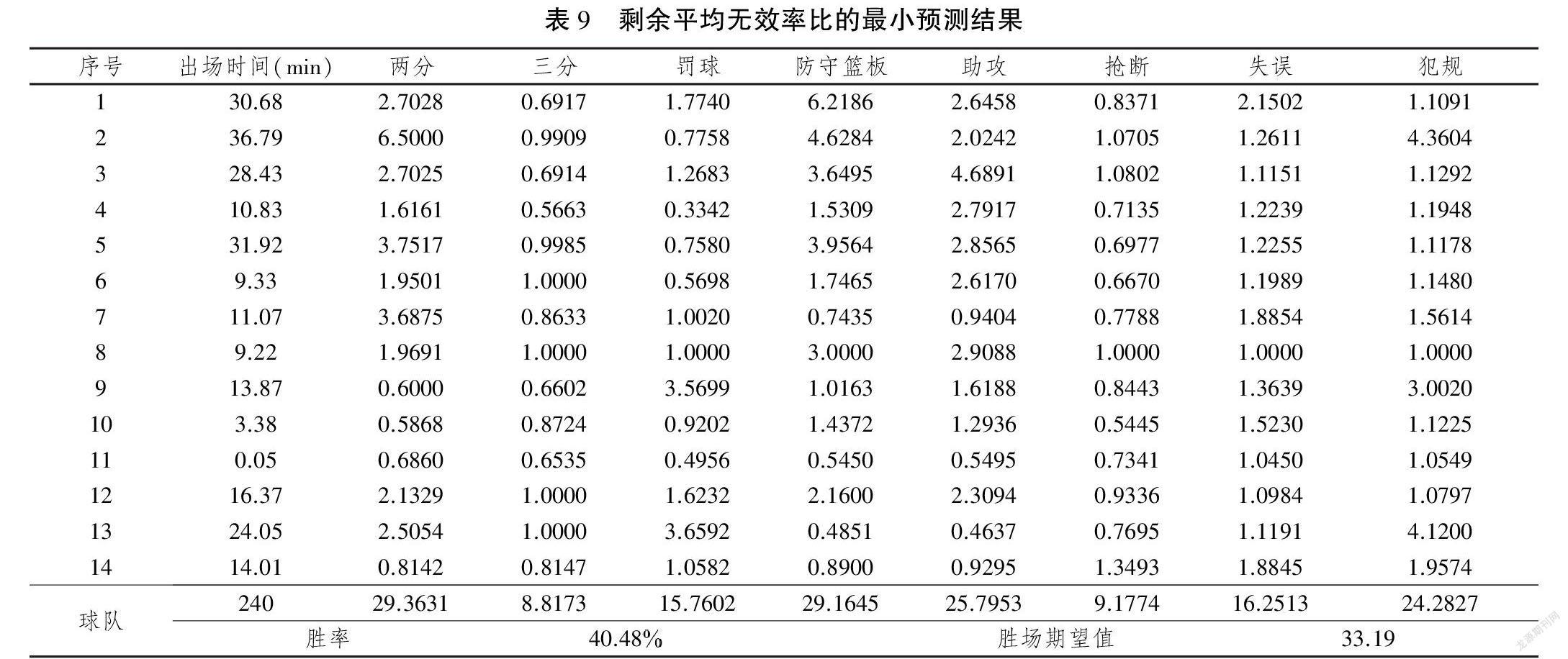
表9列出了基于模型(3)的最小预测结果,结果发现预测的最低性能与表5中给出的期望结果有很大不同。尽管所有参与者的平均无效率比率都很高,但是不同的计划会导致不同的结果,甚至会有很大的不同。结果证明适当选择球员和在场上分配上场时间对NBA球队而言最为重要,而且,获得这些期望的和不期望的结果的不同组合的战略安排与获胜概率密切相关。
在许多体育赛事中,都存在“热球员”现象,这表明某些球员的表现将优于其他球员。另外,几乎所有运动中的每个团队中都会有一个、两个或更多的关键球员贡献最大。从这个角度来看,可以进一步讨论一些球员缺席的影响,毕竟伤病问题对于几乎所有球员都是不可避免的。在不失一般性的前提下,认为存在一些关键角色,如果其他角色发挥较差,他们将做出更多贡献。另外,如果一名球员受伤并且在预测期内不打任何比赛,那么将来的表现会发生多少变化,以及如何重新分配比赛时间。为此,考虑下一个赛季整个赛季某个球员不在这里的情况,其结果列在表10中。根据结果发现,通过保持团队和球员的平均无效率比率,无论缺席哪个人,最优预测获胜概率都将保持不变。此结果的一个可能原因是,在基于数据包络分析的方法中,不同的DMU是同质的,并且可以用对等DMU的凸组合代替。结果,任何人的缺席都可以被其他人抵消,获胜的概率保持不变。另一个原因是,除了每个球员的PPS之外,还使用了团队的PPS来限制预测的可能的输入输出。由于NBA是一项团队运动,而且金州勇士队的球员每年都会发生很大变化,因此,球队的PPS与球员的PPS总和之間的差距会很大。当使用DEA模型来解决获胜概率预测时,可能存在一些更多的输出,这些输出可以通过球员总数来实现,而不能通过团队来实现。因此如果存在这种冗余输出,则无论哪个球员不能参加比赛,获胜概率都将保持不变。
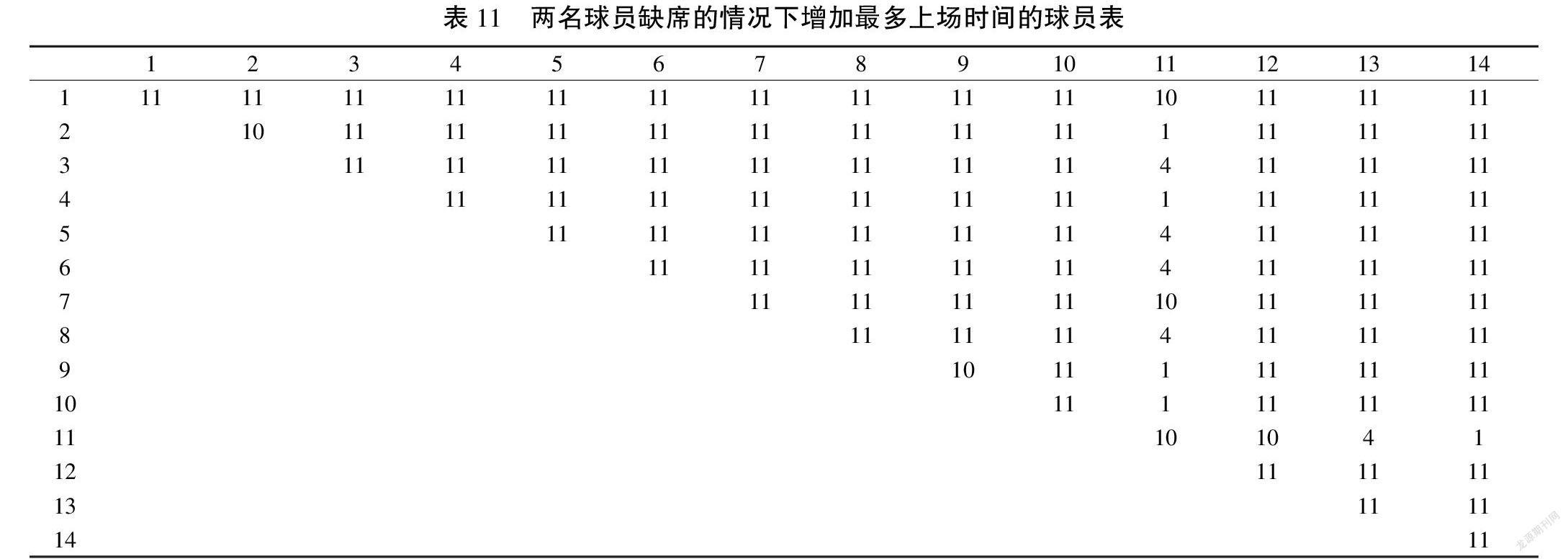
但是,如果调查比赛时间的变化,就会发现史蒂芬·库里的比赛时间增加最多。表11显示了如果同时删除两个球员,则11号球员史蒂芬·库里将成为增加最多比赛时间的球员,结果表明,在几乎所有情况下,史蒂芬·库里都是最大目标。增幅最大的人可以被认为是关键球员,因为随着比赛时间的延长,他会尽力抵消缺席带来的负面影响,并为球队带来最佳的比赛结果。另外,根据可能的得分和比赛结果,以前发现史蒂芬·库里是前5名有价值的球员之一,因此,可以得出结论,根据数据驱动预测方法和本文中使用的数据样本,史蒂芬·库里是金州勇士队最有价值的球员。实际上,史蒂芬·库里在2015—2016赛季NBA常规赛中获得了最有价值球员(MVP)的荣誉。
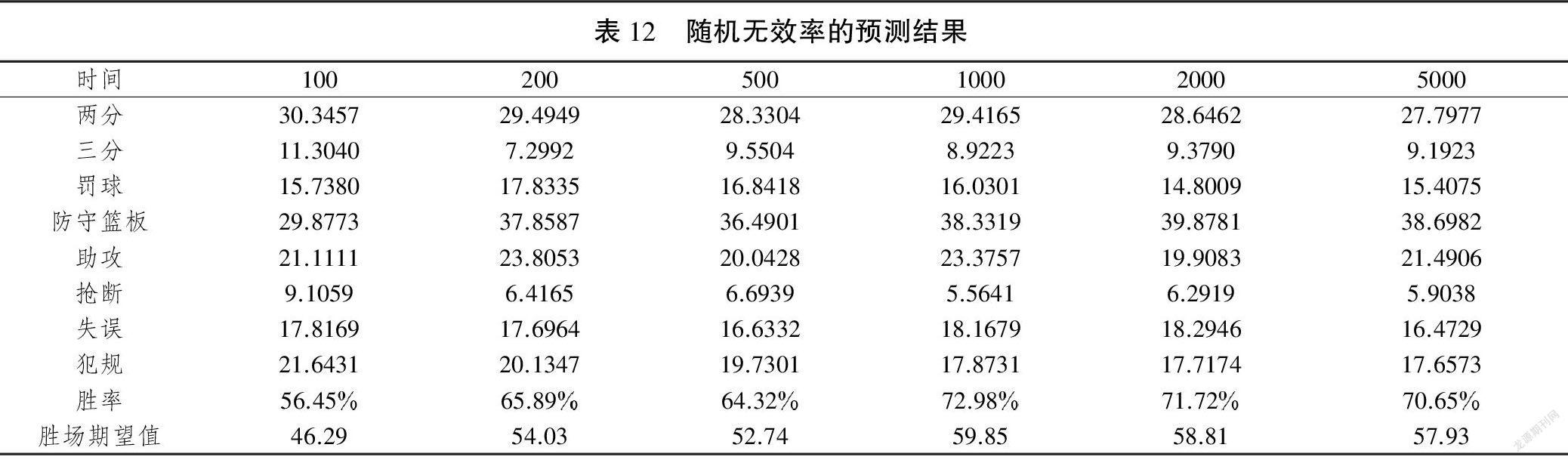
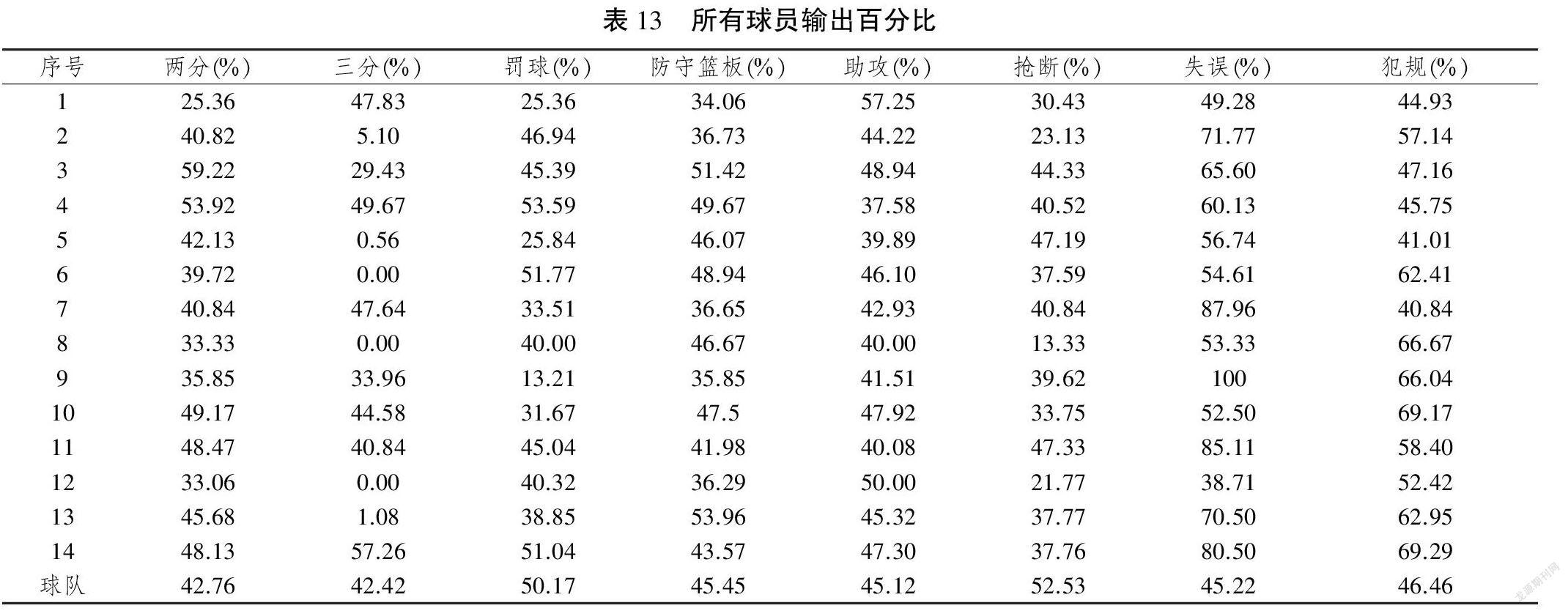
此外,考虑这样一种情况,即所有参与者在每个结果上的个人效率低下率和整个团队的效率低下率都是随机确定的。表4中的结果是基于DEA模型的平均值,这里假设效率低下的比率是从样本中以前的比赛中随机选择的,结果如表12所示,预测结果也将随机改变。因此可以发现随机预测结果更有可能比确定性情况低。这可能存在如下原因:对于这些理想或不理想的输出,这些球员在所有比赛中很少是百分比高于或低于其平均值。详细信息可以参考表13中给出的统计信息,该统计表明,对于期望的输出,几乎所有百分比值都小于0.5,对于不期望的输出,则几乎大于0.5。
3结论与展望
本文中提出了一种基于数据包络分析的两步数据驱动方法,以预测NBA球队的获胜概率。它首先使用多元统计回归分析来估计团队一级获胜概率与各种比赛结果之间的数量关系,然后应用基于数据包络分析的生产前沿模型来获得最佳比赛结果。得出如下结论:
(1)提出了具有可变规模收益假设的数据包络分析方法,为捕获比赛时间和球员输出之间的非线性关系提供了十分有效的途径。一般来说建议将数据包络分析用于事后评估,本文首次将数据包络分析方法用于事先预测团队运动水平,结果表明数据包络分析提供了考虑不同球员组合的预测比赛结果的机会,能够有效预测球队与球员的关系。提出的基于前沿生产方法的数据驱动多元逻辑分析方法,在大数据环境中,充分发挥了数据的潜力,提升了训练数据的利用效率,增大了预测精度。
(2)球队的无效率比率是一个敏感因素,而球员的无效率比率则较不敏感。从这个角度出发,建议球队的经理和教练更加注意球队合作与沟通,保持良好的球队相处氛围与竞技状态,并努力消除更多的团队效率低下因素,保持团队效率将极大提升球队的成绩。
(3)尽管所有参与者的平均无效率比率都很高,但是不同的计划会导致不同的结果,甚至会有很大的不同。这样的发现证明了选择适当的球员与合理分配上场时间对球队而言最为重要。而且,获得这些期望的和不期望的结果的不同组合的战略安排与获胜概率密切相关。
(4)为消除球队伤病带来的影响,可分析得到全队比赛时间增加较多的球员,该类球员为全队的关键球员,因此要更加注重合理分配关键球员的出场时间。
(5)使用来自NBA金州勇士队的真实数据集来证明所提出方法的有用性和有效性。通过经验应用,不仅建立了适用的成绩预测方法,而且还提供了有关NBA球队提升成绩的宝贵建议。另外,此方法还可推广至其他团队运动项目中,方法具备普遍性。
本文提出的方法可被视为同一目标未来研究的参考和基准,是基于数据包络分析的方法的运动成绩预测。同时,它可以从某些方向扩展。首先,提出的方法仅应用于一个NBA球队,可以尝试使用更全面的数据和情况进行说明,这一点在大数据环境中将特别具有吸引力。此外,没有考虑对手的逐项比赛日程和竞争策略,将更多的行为理论整合到数据驱动的预测方法中具有重要意义。同样,预测单个比赛是一个亟待解决的问题,对此应该考虑更多因素,例如球员限制、球员组合和比赛时间计划。未来的研究可以开发出运动水平上运动队成绩预测的方法。此外,所提出的预测方法采用平均无效率比率来量化预测期间的效率状态。这是一种自然可行的方法,但是其他方法也可以解决数据驱动的预测问题。并且,准确预测在预测期内可能的效率状态对于预测方法和结果非常重要。此外,由于数据包络分析方法非常理想,因此预测结果可能会被夸大。可能的原因取决于生产前沿,这可能与对手弱的比赛密切相关,需要设计一项可能的研究来克服此缺点并获得更好的结果。
参考文献:
[1]赵月民,陈培友.基于加速度传感器的大学生自行车运动能耗预测模型研究\.山东体育学院学报,2019,35(1):80-85.
[2]郭正茂,谭宏,杨剑.竞争战略对中国体育用品制造业上市公司短期绩效影响的实证研究——基于PORTER基本竞争战略分类范式\.山东体育学院学报,2018,34(6):1-7.
[3]袁军. 陕西省竞技武术套路男子长拳后备人才专项身体素质因子分析及预测模型构建\.西安:西安体育学院,2019.
[4]谢晖.利用多变量GM(1,N)灰色模型预测运动成绩的研究\.当代体育科技,2018,8(13):221-224.
[5]曲淑华,张晓东,尹贻杰.世界田径锦标赛标枪成绩发展态势分析及灰色预测\.北京体育大学学报,2017,40(11):93-97.
[6]刘山玉,韩盼星.第20届CUBA男篮四强攻防能力分析\.广州体育学院学报,2019,39(6):91-93.
[7]杨若愚. 中国优秀运动员爆发力素质相关基因多态性及其预测模型的研究\.上海:上海体育学院,2017.
[8]AMATRIA M, LAPRESA D, ARANA J, et al. Optimization of game formats in U-10 soccer using logistic regression analysis. J Hum Kinet,2016,54(1):163-171.
[9]ARABI B, MUNISAMY S, EMROUZNEJAD A. A new slacks-based measure of Malmquist-Luenberger index in the presence of undesirable outputs. Omega,2015(51):29-37.
[10]刘天彪,马成全,张丹,等.中超联赛职业足球俱乐部赛季初的资金投入和比赛表现与赛季末成绩排名的相关性研究\.首都体育学院学报,2019,31(6):511-516.
[11]杨润田,徐腾达.冬奥会背景下崇礼滑雪旅游产业的发展规模——基于经济预测的视角\.沈阳体育学院學报,2019,38(6):1-7.
[12]李欣.基于DEA模型的我国少数民族自治州公共体育服务效率研究\.广州体育学院学报,2018,38(4):78-82.
[13]GOMEZ M, IBANEZ S, PAREJO I. The use of classification and regression tree when classifying winning and losing basketball teams. Kinesiol: Int J Fundam Appl Kinesiology,2017,49(1):47-56.
[14]KOSTER J, AVEN B. The effects of individual status and group performance on network ties among teammates in the National Basketball Association. Plol One,2018,13(4):e0196013.
[15]LEE BL, WORTHINGTON AC. A network DEA quantity and quality-orientated production model: an application to Australian university research services.Omega,2016(60):26-33.
[16]游艳雯.基于数据包络分析的路网性编组站运营效率评价研究\.铁道运输与经济,2019,41(11):99-104.
[17]涂春景,江崇民,张彦峰,等.基于灰色模型的我国城镇老年人体质定量预测研究\.体育科学,2016,36(6):92-97.
[18]蒋佳峰.杭州富阳运动休闲产业竞争力分析——基于数据包络分析法(DEA)\.浙江体育科学,2017,39(6):1-6.
[19]VILLA G, LOZANO S. Dynamic network DEA approach to basketball games efficiency. J Oper Res Soc,2018,69(11):1738-1750.
[20]钟松伟,唐行军,陈晓娟.2016-2017赛季NBA总决赛冠军勇士队致胜因素分析\.体育科技文献通报,2019,27(11):77-79.
猜你喜欢
中国体育教练员(2017年2期)2017-07-31 19:09:34
职教论坛(2016年26期)2017-01-06 19:29:53
科技创新与应用(2016年34期)2016-12-23 16:02:22
青春岁月(2016年20期)2016-12-21 18:48:37
科技视界(2016年26期)2016-12-17 15:59:49
湖北农业科学(2016年18期)2016-12-08 19:10:40
合作经济与科技(2016年24期)2016-12-07 01:55:17
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:54
商(2016年33期)2016-11-24 21:57:42
科技视界(2016年1期)2016-03-30 12:52:04
