
基于神经网络模型的影评情感分析研究
2021-02-12 10:06:14杨晓晨莫秀良王春东
天津理工大学学报 2021年5期
杨晓晨,莫秀良*,王春东
(天津理工大学a.天津市智能计算及软件新技术重点实验室,b.计算机科学与工程学院,天津300384)
随着互联网技术的不断发展,人们已经从信息缺乏时代过渡到信息十分丰富的数字化时代,越来越多的人愿意将自己的意见、评论在网络中与人交流,网络中的评论能够表达出人们情感,如何准确地从这些情感性评论中挖掘出有效信息至关重要。文本情感分析也被称为意见挖掘[1],主要用来将文本进行分类,分为正面情感、负面情感以及中性情感[2]。最初的情感研究方法是基于情感词典进行研究[3],RAO等[4]提出了基于主题建模的方法来构建主题级词典。随着机器学习的发展,传统的支持向量机、朴素贝叶斯、K-近邻算法等逐渐应用到文本分类任务中。由于传统方法的完成效率和质量不是很高,人们开始利用深度学习构建网络模型进行文本分类任务,MINAEE等[5]在其综述中,详细回顾了近几年发展起来的150多种基于深度学习的文本分类模型,并讨论了它们的技术贡献、相似性和优势。神经网络模型的使用带动了词向量嵌入技术的发展,例如词向量(word to vector,Word2vec)就是MINAEE等[5]提出来的一种文本分布式表示的方法。ABID等[6]将词嵌入与神经网络结合进行情绪分析;速递神经网络无法解决长依赖问题,而长短记忆循环神经网络(long short-term memory,LSTM)能很好地解决依赖问题,并且能很好地存储信息。MA等[7]提出了在LSTM中添加一个叠加的注意力机制,可有效地提升分类性能。LIU等[8]进一步提出了学习注意力机制的相关理论,指出将注意力机制和循环神经网络组成的融合模型进行文本分类。MENG等[9]进一步强调增强注意力机制应用在混合模型中将取得更好的效果,为不同模型的优势进行融合提供了研究思路。
综合以上研究,本文提出了神经网络(CNN+LSTMAttention)模型进行影评文本情感分析研究,在公开数据集互联网电影资料库(internet movie database,IMDB)的影评数据集上进行多组实验[10],并设置不同模型的对比实验,结果表明新模型具有更好的分类准确率。
1 相关模型
1.1 卷积神经网络
卷积神经网络(convolutional neural network,CNN)是多层神经网络,基本结构为输入层、卷积层、池化层、全连接层和输出层,CNN在图像视觉领域取得了很大的成就。随着学习的深度发展,KIM[11]在论文中提出了CNN模型,CNN模型的整体网络架构如图1所示。

图1 CNN模型的整体网络架构Fig.1 The overall network architecture of CNN model
输入层,在图像处理领域,一般为图片像素,类比图像中的原始像素点。文中将句子或者文档表示成向量矩阵。假设某一句子的向量矩阵为n*k,n表示句子中词的个数,k表示词向量的维度。
卷积层,是CNN的核心,主要思想是局部连接和参数共享。卷积层用若干个可学习的卷积核与词向量矩阵进行卷积运算,通过卷积运算可以得到更高级的特征表示,一般可以取宽度、词向量维度相同和高度有所变化的卷积核,每个卷积核与输入特征的不同局部窗口进行卷积操作,将运算得到的特征向量经过激活函数的处理可以输出本层的特征,得出计算公式(1)为:

式中,hj表示经过卷积层得到的第j个特征数据,g为激活函数,xi表示输入数据的集合中第i个输入数据,wij表示在卷积层中第i个输入特征数据对应第j个输出特征数据的卷积核权值,bj为偏置。
池化层,是对卷积层的输出特征结果采用最大值采样,将卷积层的最大元素连接起来而创建向量。
全连接层,将所有的特征根据概率值的大小进行分类,输出最后的分类结果。
1.2 循环神经网络
循环神经网络(Recurrent neural network,RNN)用于处理可变长序列,通过维护一个状态变量用于捕获序列数据中存在的各种模式,典型的RNN相当于多层前馈神经网络,长序列带来的大量历史信息会导致传输中的梯度消失和梯度爆炸问题。
LSTM模型,专门设计来解决RNN的长期依赖问题,LSTM视为一个更高级的RNN家族。LSTM比普通的具有更长的存储记忆,它具有更多的参数,能够决定存储哪些记忆,丢弃哪些记忆。完整的LSTM架构图如图2所示,它主要由5个不同的部分组成:
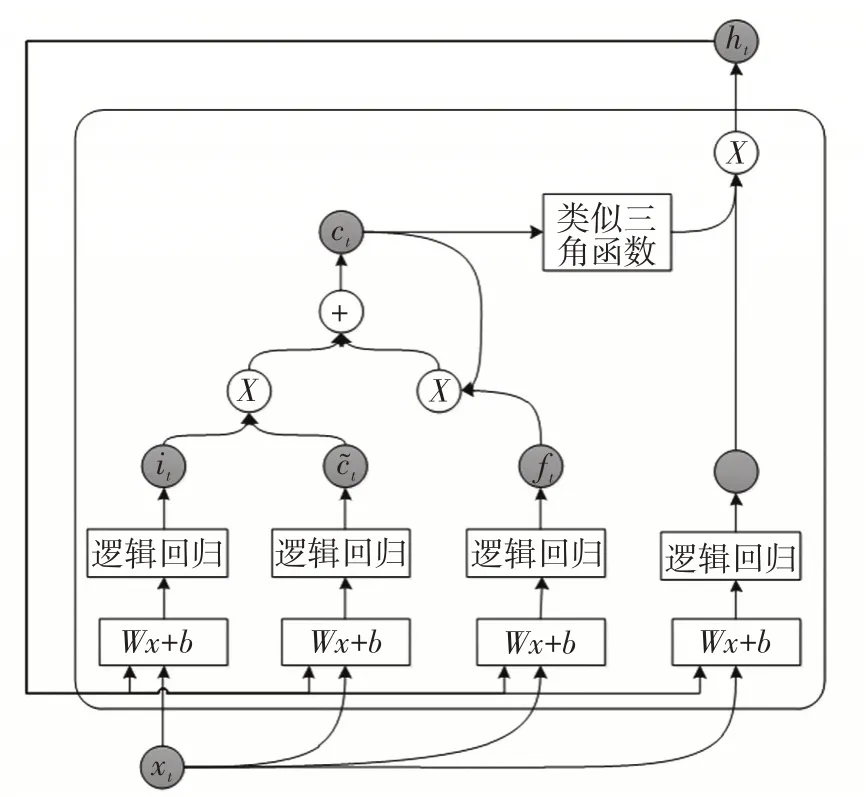
图2 完整的LSTM架构图Fig.2 Complete LSTM architecturediagram
1)单元状态,LSTM的内部单元状态即记忆。
2)隐藏状态,用于计算预测结果的外部隐藏状态。
3)输入门,决定多少当前输入会被送进单元状态。
4)遗忘门,决定多少先前的单元状态会被送到当前单元状态。
5)输出门,决定多少单元状态被输出到隐藏状态。
在LSTM中,输入门it会将当前输入xt和前一个最终隐藏状态ht-1作为输入,对比于标准的RNN,其中激活函数发生了变化,同时增加了偏置。按照公式(2)进行计算得出it为:

式中,W为权重;i为对应输入门;h为隐藏处理状态。
计算后,it=1时,来自当前输入的所有值都将进入到单元状态;it=0时,来自当前输入的所有值都不会进入到单元状态。c~t为候选值,通过公式(3)进行计算得出c~t为:

式中,ft为遗忘门,遗忘门的值为1时,x为输入。ct-1的所有信息都会传送到ct中;遗忘门的值为0时,ct-1所有信息都不会传送到ct中。
通过公式(4)计算得出ft。
LSTM有一个很好的特性,能够从先前的单元状态中选择记住或者忘记哪些信息,也可以添加或者放弃当前输入的一些信息。

最后状态ht是根据公式(6)和公式(7)更新。
以上内容介绍了LSTM的结构和形式。但在本文中,实际上在LSTM的顶部加入了具有权重和偏置的分类器用于输出最后的分类结果。
1.3 注意力机制模型
注意力机制能够赋予模型区分辨别的能力,被广泛地用于机器翻译、语音识别领域,为句子中的每个词赋予不同的权重,使神经网络模型的学习变得更加灵活,同时注意力机制可以用于解释输入和输出句子之间的对齐关系,以及解释模型到底学到了什么知识。
在该模型中需要根据公式计算编码层中各时刻隐藏层的输出加权平均值ci,计算如公式(8~9)为:
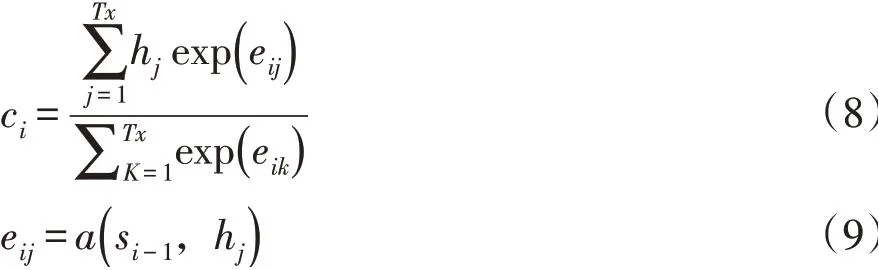
式中,si-1表示解码层中第i-1时刻隐藏层的输出,eij就是对齐模型,可以衡量编码层中j位置的词对解码层中i位置的词的影响程度。
2 新模型的构建
本文使用的是加入注意力机制的CNN+LSTM模型,首先将文本进行向量表示,形成词嵌入进行输入,本方法采用的是单层卷积层和最大池化方法,在进入到LSTM之前进行丢弃法操作,在进行训练时,会根据概率随机生成0、1向量,将部分输入的元素随机设置为0,能够将输入平均化,减少神经元之间复杂的共适应关系。
在进入到LSTM层之后,再次进行丢弃法操作,能够很好地解决拟合现象。接下来引入注意力机制,分配不同的权重以区分信息的重要程度。最后经过全连接层和分类器层得到输出最终的结果,CNN+LSTM-Attention模型结构图如图3所示。
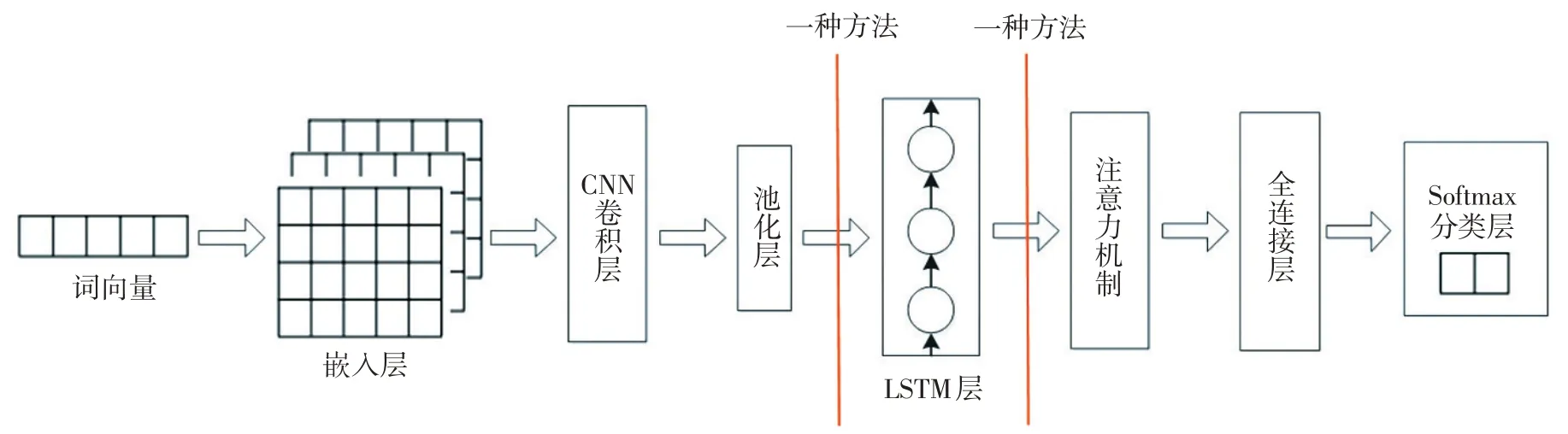
图3 CNN+LSTM-Attention模型结构图Fig.3 CNN+LSTM-Attention model structure diagram
3 实验部分
3.1 数据集
本实验用的是公开的IMDB电影评论数据集,IMDB数据集共包括50 000条电影评论数据,其中训练集和测试集各25 000条,根据实际评论内容,每条数据都被标记为正面评价或者负面评价。情感标签直接分为两类,分类标签设置如表1所示。

表1 分类标签设置Tab.1 Classification label settings
3.2 评价指标
实验采用准确率(Accuracy)作为评价分类结果好坏的指标,正面评价记为Positive,负面评价记为Negative,分类正确结果标记为True,分类错误结果标记为False。计算公式(10~12)为:
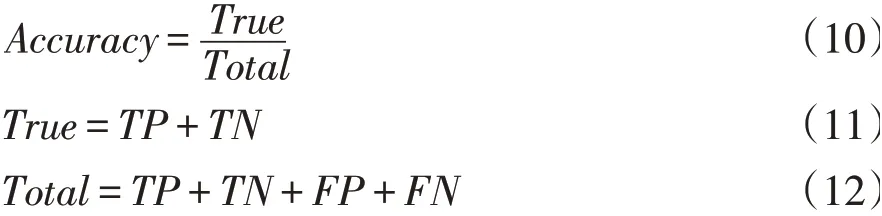
TP、TN、FP和FN的混淆矩阵如表2所示。

表2 混淆矩阵Tab.2 Confusion matrix
3.3 实验设置
本实验在Windows10企业版台式机进行,使用深度学习库(TensorFlow)和深度学习框架(karas),采用Python编程语言进行实验。在实验中用训练好的Word2vec将词转化为词向量,具体的实验参数设置如下,词向量维度200;嵌入层中特征单词的个数5 000,embedding_size参数值128;卷积层中卷积核个数32个,卷积核大小5;池化层中池化核大小4;LSTM中隐藏层维度300;可调超参数batch_size参数值32,epochs参数值10,丢弃法参数值为0.30,学习率为0.01。在实验中,优化器能将损失函数的误差最小化,并能够找到误差最小的“权重与偏差的组合”,采用的优化器是自适应学习率优化算法。
3.4 实验结果及分析
本文所提出的新模型是联合模型,为证明联合模型的有效性,针对实验的影评数据集,设置两组对比试验。第一组实验将联合模型CNN+LSTM与其他单一模型做对比,这些模型包括LSTM、双向长短时记忆循环神经网络(bidirectional long shortterm memory,BiLSTM)和CNN,第一组实验结果如表3所示。第二组实验将第一组实验中用到的模型分别加入注意力机制,与第一组实验结果做对比,这些加入注意力机制的模型包括:LSTMAttention、BiLSTM-Attention和CNN-Attention。

表3 第一组实验结果Tab.3 Thefirst set of experimental results
第一组实验中LSTM模型只能学习前项特征,无法很好地利用到后向特征,而BiLSTM能够记住前向和后向特征,能更好地利用了上下文的语义特征进行分类。从分类结果看,分类准确率提升了2.47%;利用CNN进行分类,堆叠多个卷积核提取文本的抽象特征,通过卷积计算能够获取到相邻词的特征,但不能很好地提取长距离的文本特征,尽管如此,CNN得到的分类结果仍然优于BiLSTM。本文中,将单一模型进行联合,利用CNN提取局部特征并与LSTM进行结合,得到联合模型CNN+LSTM,联合模型不仅能考虑到相邻词的特征,还能更好地考虑到远距离词的信息,即上下文信息,联合模型的分类准确率与单一模型相比有了明显提高。
在第二组实验中,注意力模型通过分配不同的权重来区分文本中信息的重要性,获取重要的局部特征,对有关情感的语义特征进行加强权重,对无关情感的语义特征进行弱化权重。将注意力机制加入到模型中,能够更好地利用文本信息,进一步提高了分类准确率,第二组实验结果如表4所示,对比于表3的结果,看到模型加入Attention机制后,准确率都有进一步的提高,证明了Attention机制提高分类准确率的有效性,提高了1.74%。

表4 第二组实验结果Tab.4 The second set of experimental results
通过实验1的结果可以看到,联合模型能够结合单一模型的优点,实现充分利用文本信息,提取文本中的有效特征。通过实验2的结果可以看出,将注意力机制加入模型,加强或者弱化局部特征的权重,是为了更加合理地利用局部特征进行文本情感分类,通过将加入注意力机制的模型和未加入注意力机制的模型分类结果进行对比,可以得出提出的新模型具有较好的分类准确率,具有一定的可行性。
4 结论
本文提出的新模型使用LSTM学习和CNN池化后得到的结果连接而成新特征,能够解决单一CNN无法充分利用文章上下文信息的问题,最后引入注意力机制进行特征权重分配,能够降低噪声干扰,从而提高了分类准确率。实验结果表明,在影评情感分析任务中新模型性能上优于其他对比模型,使用该模型进行文本情感分析是可行的。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
