
精细化中子输运计算程序HNET动力学计算初步验证
2021-02-10 08:59:40康乐郝琛
哈尔滨工程大学学报 2021年12期
康乐, 郝琛
(哈尔滨工程大学 核安全与仿真技术国防重点学科实验室,黑龙江 哈尔滨 150001)
随着高性能计算能力的快速提升,反应堆数值模拟技术在精细化方面的需求逐渐提高。然而,直接采用标准三维中子输运方法开展全堆芯计算仍不现实,主要是因为典型反应堆堆芯的实际未知数总数过大,对于稳态计算接近1015数量级,而对于瞬态计算来说则要更大。目前,一种实用且切实可行的方案是采用二维/一维方法[1-4],即通过定义轴向泄漏项和径向泄漏项,将全三维输运计算转为径向二维输运计算耦合轴向一维低阶输运计算。同时,精细化全三维瞬态输运计算依赖于有效的全局加速方法的应用。其中,粗网有限差分方法(coarse mesh finite difference, CMFD)是一种流行的全局加速方法,特别针对二维/一维聚合算法,CMFD还为径向二维输运计算和轴向一维低阶输运计算提供了一种天然聚合计算框架。但是,传统CMFD有收敛慢的缺陷,同时还存在收敛发散及耦合系数为负的潜在缺陷[5]。为了有效降低多群CMFD带来的计算负担,在研发HNET程序(high-fidelity neutron trasport program for 3D nuclear reactor core,HNET)过程中,提出了基于广义等价理论的两级瞬态CMFD加速方案,通过建立等价的单群CMFD来加速多群CMFD 瞬态固定源问题的收敛,并进一步加速精细化全三维瞬态输运计算。基于CMFD并行计算框架,径向二维输运计算采用流行的特征线方法(method of characteristics, MOC),轴向一维低阶输运计算采用节块展开法(nodal expansion method, NEM)。
为了验证HNET的时空中子动力学计算功能,本文采用C5G7-TD非均匀瞬态基准题对HNET的计算精度进行验证,计算结果与高保真中子学程序MPACT进行对比。C5G7-TD系列基准题[6-7]包括一系列非均匀几何时空动力学基准题,用于校验动力学程序对非均匀几何问题的计算能力和计算精度。目前该基准问题已经发布第一阶段的系列问题,用于验证时空中子学输运算法与程序。
1 HNET瞬态计算方法
HNET采用二维MOC/一维NEM的聚合算法,并通过基于广义等价理论的两级瞬态CMFD加速全局三维瞬态输运计算,同时还采用基于MPI的区域分解并行技术,进一步缩减运行时间,更多细节见文献[5,8-11]。
1.1 三维瞬态输运固定源方程
为了简要说明三维瞬态固定源方程的推导过程,本文从瞬态多群中子输运方程出发,在各向同性散射近似的条件下,输运方程为:
Σt,g(r,t)φg(r,Ω,t)+Ss,g(r,Ω,t)+

(1)
缓发中子先驱核方程为:
(2)
式中:v为中子飞行速度;φ为角通量密度;Ck为第k缓发群的先驱核浓度;SF为经过稳态修正后的裂变源项;Ss,g为散射源项;χp和χd分别为瞬发和缓发中子能谱;βk为缓发中子份额;λk为缓发中子先驱核衰变常数;r为空间向量;Ω为角度向量;g为能群;Σt,g为总截面。
对瞬态角通量做指数变换:
(3)
其中,系数αn为:
(4)
将式(4)代入式(1)~(3)中,并且对时间导数项采用全隐式方法,则瞬态输运方程可转化为瞬态固定源方程为:

(5)
其中:
(6)
(7)
(8)
(9)
至此,式(6)可以使用任何标准的中子固定源问题求解器来解决。在HNET程序中,径向二维输运计算采用流行的MOC方法,轴向一维低阶输运计算采用节块展开NEM方法,并通过基于广义等价理论的两级瞬态CMFD加速全局三维瞬态输运计算。
1.2 基于广义等价理论的两级瞬态粗网有限差分加速方法
CMFD不仅为二维径向MOC输运计算和一维轴向NEM计算提供了天然的计算框架,同时还对全堆芯输运计算起到加速作用,三维多群瞬态扩散方程为:
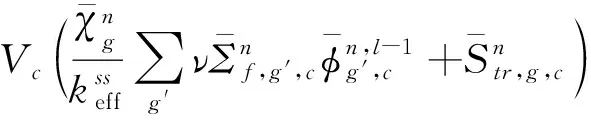
(10)

根据基于广义等价理论的粗网有限差分方法,中心节块c到相邻节块q的界面流为:
(11)

(12)
(13)
(14)
(15)
式中:W、E、N、S、T、B代表节块在西、东、北、南、顶、底方向上的6个表面。
式(15)可以由任意固定源问题求解器来求解,且所用的特征值来自于稳态输运计算,其在整个瞬态过程中应保持不变。
由于多群CMFD线性系统的条件数很大,如若采用Wielandt shift方法加速逆幂迭代,其条件数会变得更大,因此,一级多群CMFD线性系统存在收敛慢的缺陷。一群CMFD线性系统条件数较低使得其容易求解,可利用一群CMFD获得中子通量及裂变源加速多群CMFD。基于多群CMFD获得的中子通量、中子流及多群截面信息,可获得一群CMFD线性系统为:
(16)
一群CMFD用以加速多群CMFD的特征值和裂变源项,求解多群CMFD线性系统,以计算得到新的多群中子通量分布和特征值,进而用于更新一群宏观截面、中子通量和中子流。同时,计算得到的多群中子通量将进一步更新每一个节块的界面流,而界面流则会被用于更新一群CMFD的节块不连续因子和扩散系数修正因子,直到整个线性系统收敛。其中,当残差范数下降到指定标准或最大迭代次数达到时,一群CMFD迭代或多群CMFD迭代相应退出,整体收敛通过检查不连续因子的相对误差是否达到收敛标准,具体细节可参考文献[7]。
2 C5G7-TD基准题模型
C5G7-TD系列基准题二维算例包含TD0、TD1、TD2和TD3系列;三维算例包含TD4和TD5系列。每个系列都包含数个算例,这些算例包含控制棒移动和慢化剂密度变化等瞬态事件。控制棒移动是以组件为单位同时移动,即在同一组件内所有控制棒均保持相同的高度。二维与三维的瞬态问题,更多细节见文献[5]。
2.1 二维算例模型
1)TD0系列。
TD0系列算例描述了二维情况下控制棒瞬间插入与提出反应堆的过程。在初始时刻,控制棒突然插入到堆芯10%的位置,并停留1 s。随后,控制棒提出到堆芯5%的位置,并再次停留1 s。最后,在2 s结束时,控制棒从堆芯中完全撤出。在二维模型中,这一过程被模拟为控制棒区1区截面的变化。
2)TD1与TD2系列。
TD1与TD2系列描述了二维情况下控制棒线性插入与提出反应堆的过程,通过线性地将导向管截面变化成控制棒截面来模拟控制棒移动过程。在初始时刻,所有的控制棒均在堆芯外部,在0~1 s过程中,控制棒从堆芯顶部匀速插入到堆芯的特定位置。其中,TD1为堆芯5%的位置,TD2为堆芯10%的位置。然后以相同的速度提出控制棒,并在2 s结束时完全提出堆芯区域。TD1和TD2基准题各有5道算例。
3)TD3系列。
TD3系列描述了二维情况下反应堆内慢化剂密度变化过程。在起始时刻,燃料组件内的慢化剂密度(不包括轴向反射层)为正常密度,在0~1 s过程中,慢化剂密度以一定速度降低。在1 s结束时,密度达到最小值,即初始密度的w值。然后慢化剂密度以同样的速度增加,并在2 s结束时回到初始值。对于TD3中的不同算例,w的值有所区别,其中“TD3-1”的w为0.95;“TD3-2”的w为0.90;“TD3-3”的w为0.85;“TD3-4”的w为0.80。
2.2 三维算例模型
1)TD4系列。
TD4系列描述了三维情况下控制棒线性插入与提出反应堆的过程。在初始时刻,所有控制棒均处于顶部反射层内。随后在0~8 s过程中,不同组件内的控制棒以不同的速度匀速地插入与提出反应堆。TD4系列共包含5个算例,分别模拟不同组件内控制棒不同的移动情况。
2)TD5系列。
TD5系列描述了三维情况下反应堆内慢化剂密度变化过程。在整个瞬态过程中,所有控制棒均保持在燃料组件顶部的反射层中。随后在0~8 s过程中,不同组件内的慢化剂密度以组件为单位同步地进行变化。TD5系列共包含4个算例,分别模拟不同组件内慢化剂变化情况。
3 HNET数值结果与分析
对于二维算例,本文展示TD1、TD2与TD3的计算结果;对于三维算例,本文展示TD4与TD5的计算结果。对于二维算例,瞬态输运计算的步长为10 ms,对于三维算例,时间步长为25 ms。对于所有算例,径向网格的划分方式是一致的。对于燃料组件内的非均匀栅元,在燃料区域径向划分3圈且周向划分8区,在慢化剂区域径向划分1圈且周向划分8区;对于反射层内的慢化剂栅元,靠近燃料组件的部分栅元划分为6×6的平源区网格,远离燃料组件的部分栅元划分为1×1的平源区网格。对于所有三维算例,轴向网格尺寸为 5.355 cm,特征线间距为0.03 cm,轴向求积组采用Yamamoto求积组[12],半空间内采用64个方位角与3个极角的组合。特征值的收敛准则为1.0×10-6,中子标通量采用无穷范数误差,其收敛准则为1.0×10-4。算例所使用的CPU型号均为2.60 GHz Intel Xeon E5-2690 v4,二维算例均采用径向9核的区域分解并行计算方案,三维维算例均采用轴向32核的区域分解并行计算方案。为了保证数值结果对比的有效性,上述参数除求积组和CPU型号外均与MPACT的参考解保持一致。
3.1 二维算例计算结果
对于C5G7-TD基准题的稳态特征,MPACT程序的参考解为1.186 673,HNET程序的计算结果为1.186 867,HNET结果与参考解的相对误差约为0.016%,表明HNET计算得到的初始时刻的堆芯状态是正确的。二维算例的堆芯相对功率历史、与MPACT参考解的堆芯功率误差和反应性历史如图1~9所示。
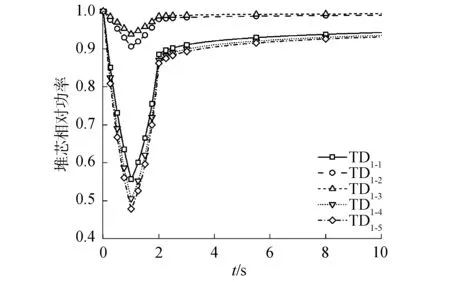
图1 TD1系列堆芯相对功率历史Fig.1 TD1 fractional core power history
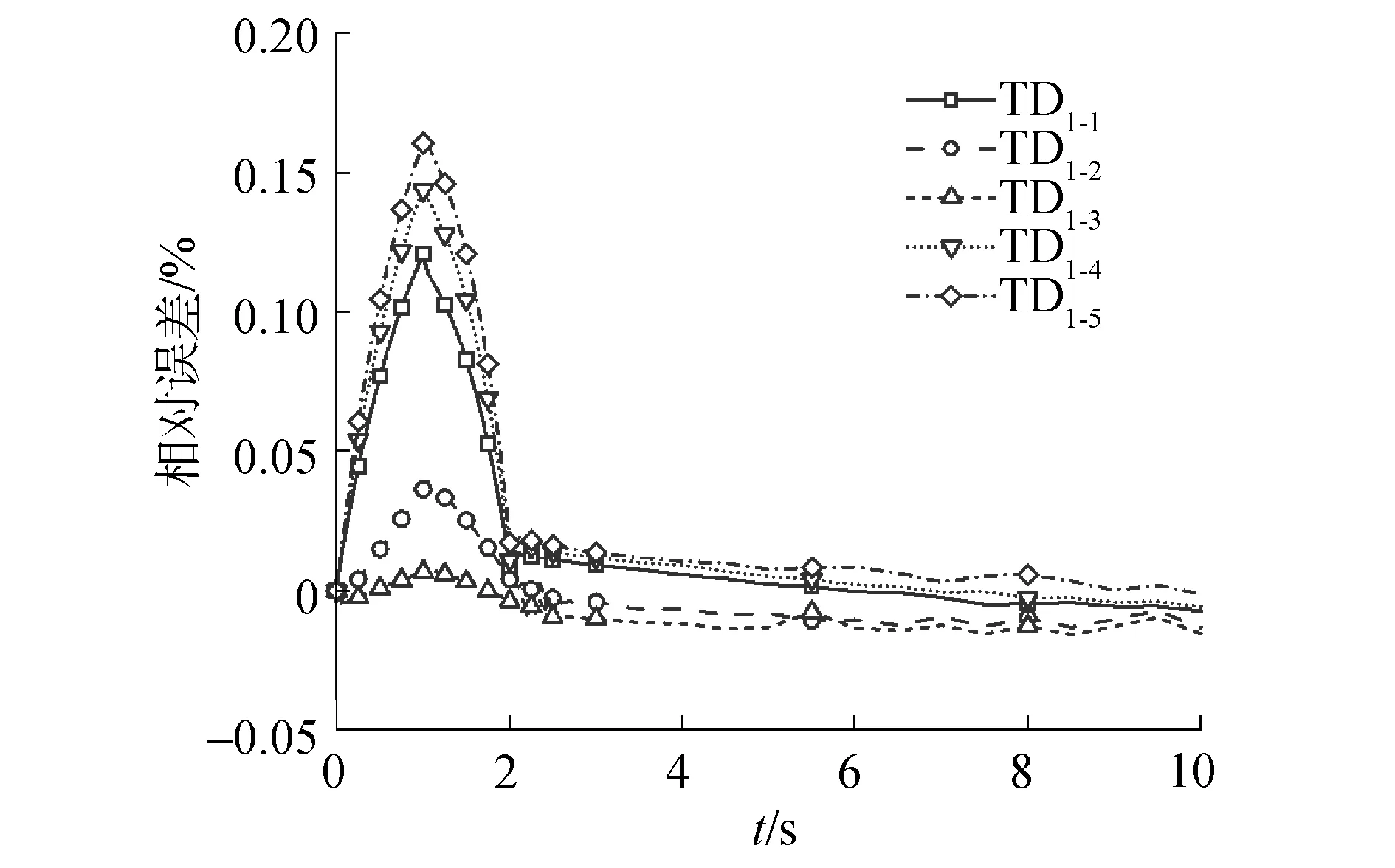
图2 对比MPACT程序的TD1系列堆芯功率相对误差Fig.2 Relative errors of TD1 fractional core power compared to MPACT results
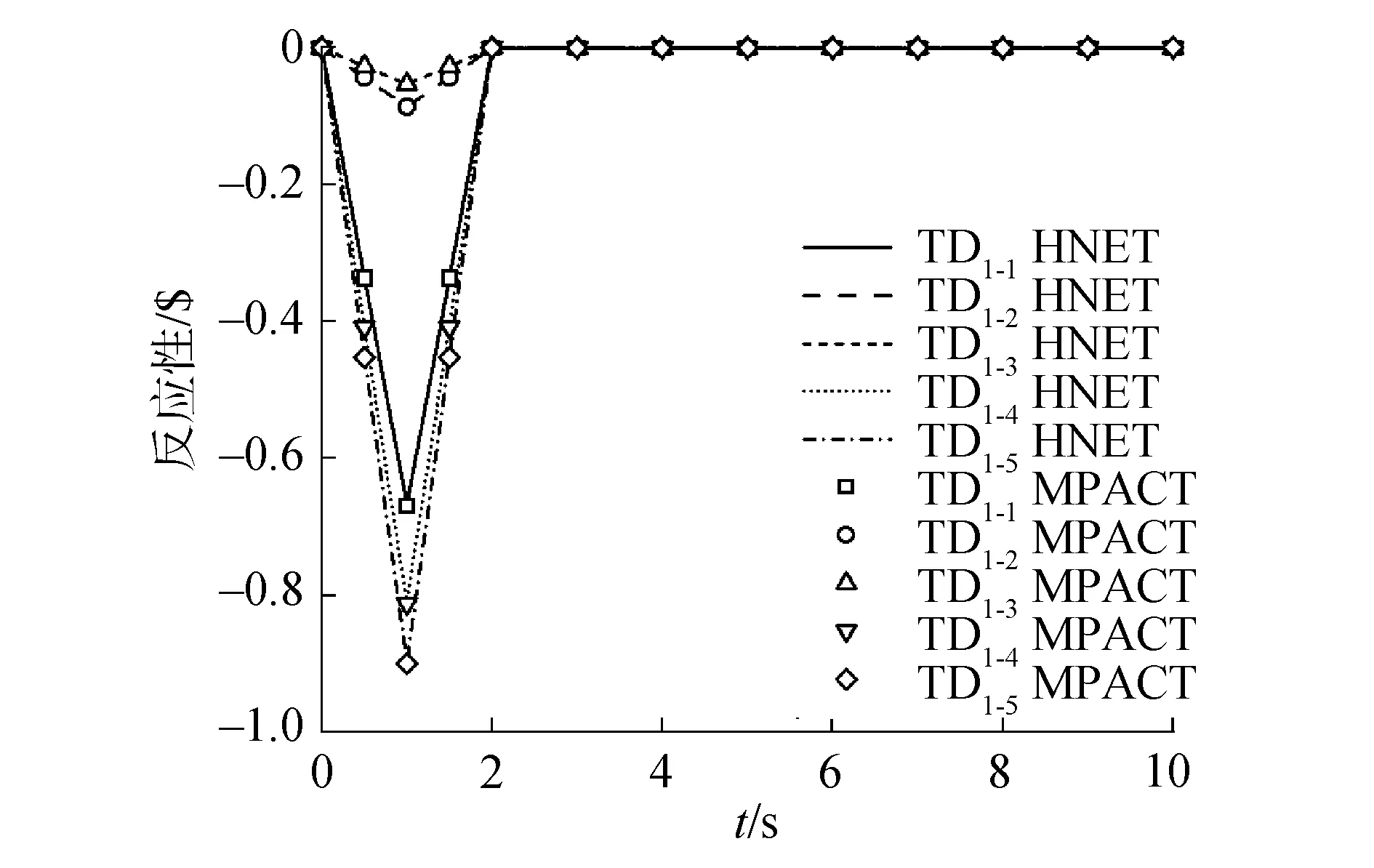
图3 TD1系列反应性历史Fig.3 TD1 reactivity history

图4 TD2系列堆芯相对功率历史Fig.4 TD2 fractional core power history
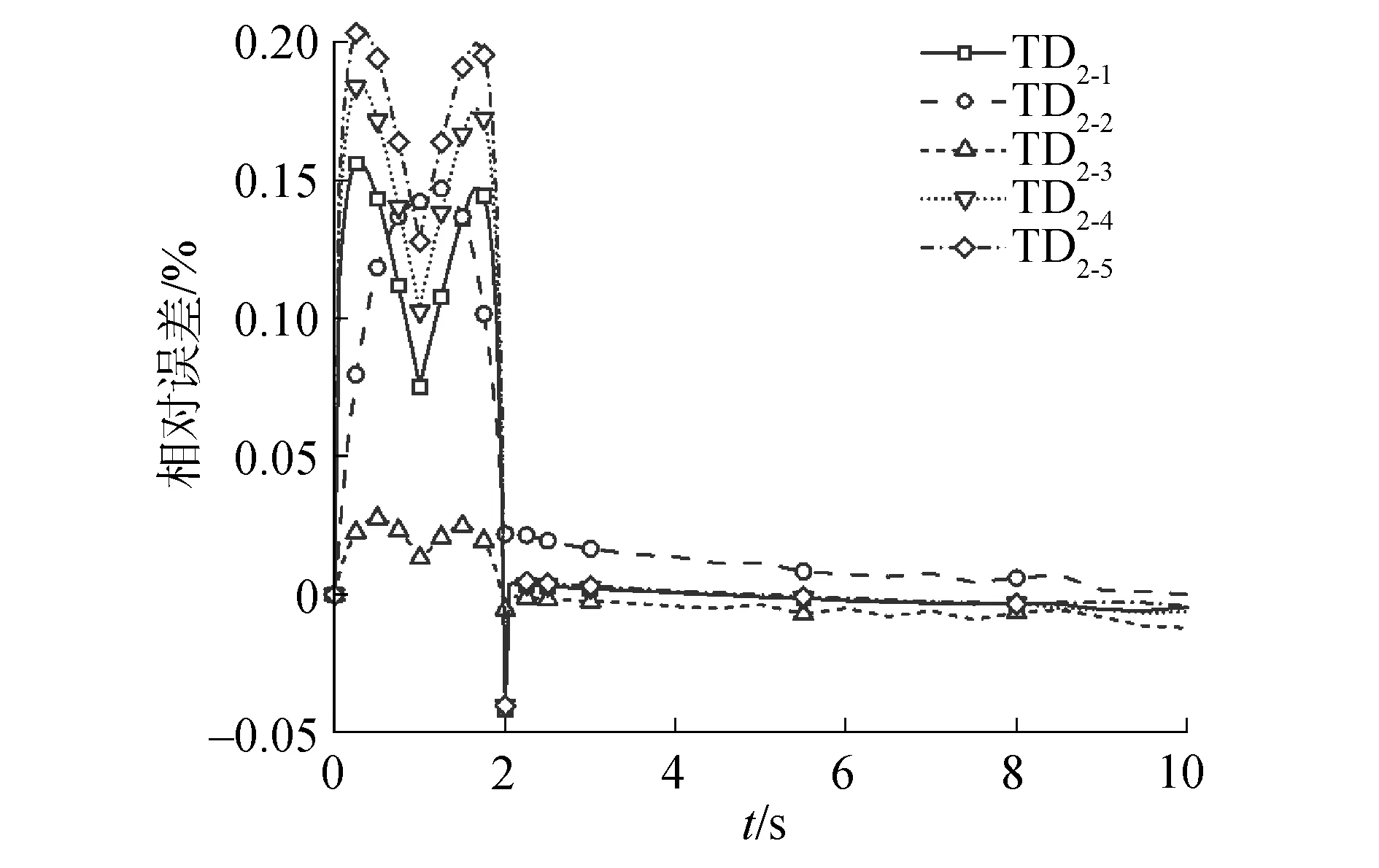
图5 对比MPACT程序的TD2系列堆芯功率相对误差Fig.5 Relative error of TD2 fractional core power compared to MPACT results

图6 TD2系列反应性历史Fig.6 TD2 reactivity history
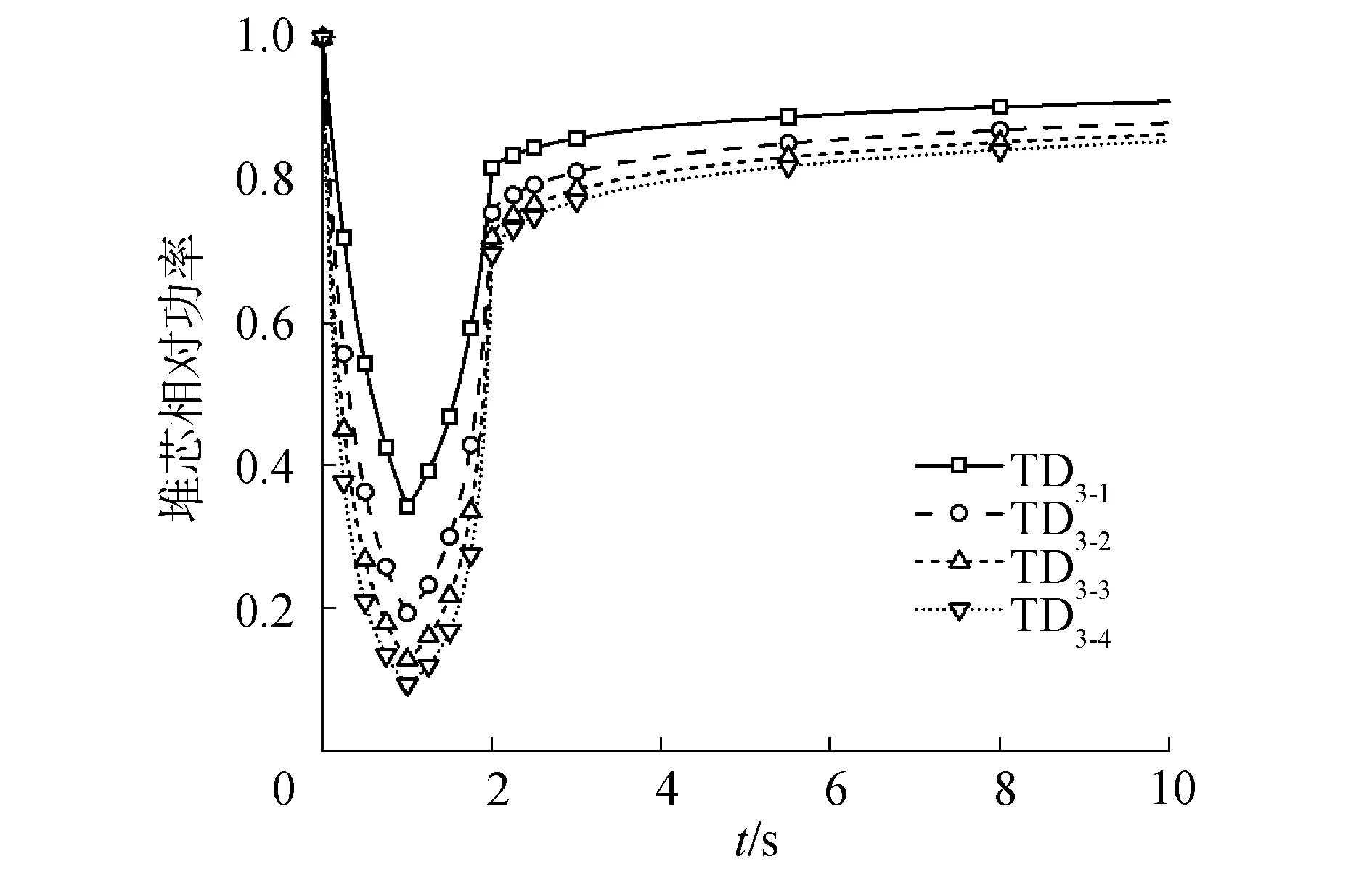
图7 TD3系列堆芯相对功率历史Fig.7 TD3 fractional core power history

图8 对比MPACT程序的TD3系列堆芯功率相对误差Fig.8 Relative error of TD3 fractional core power compared to MPACT results
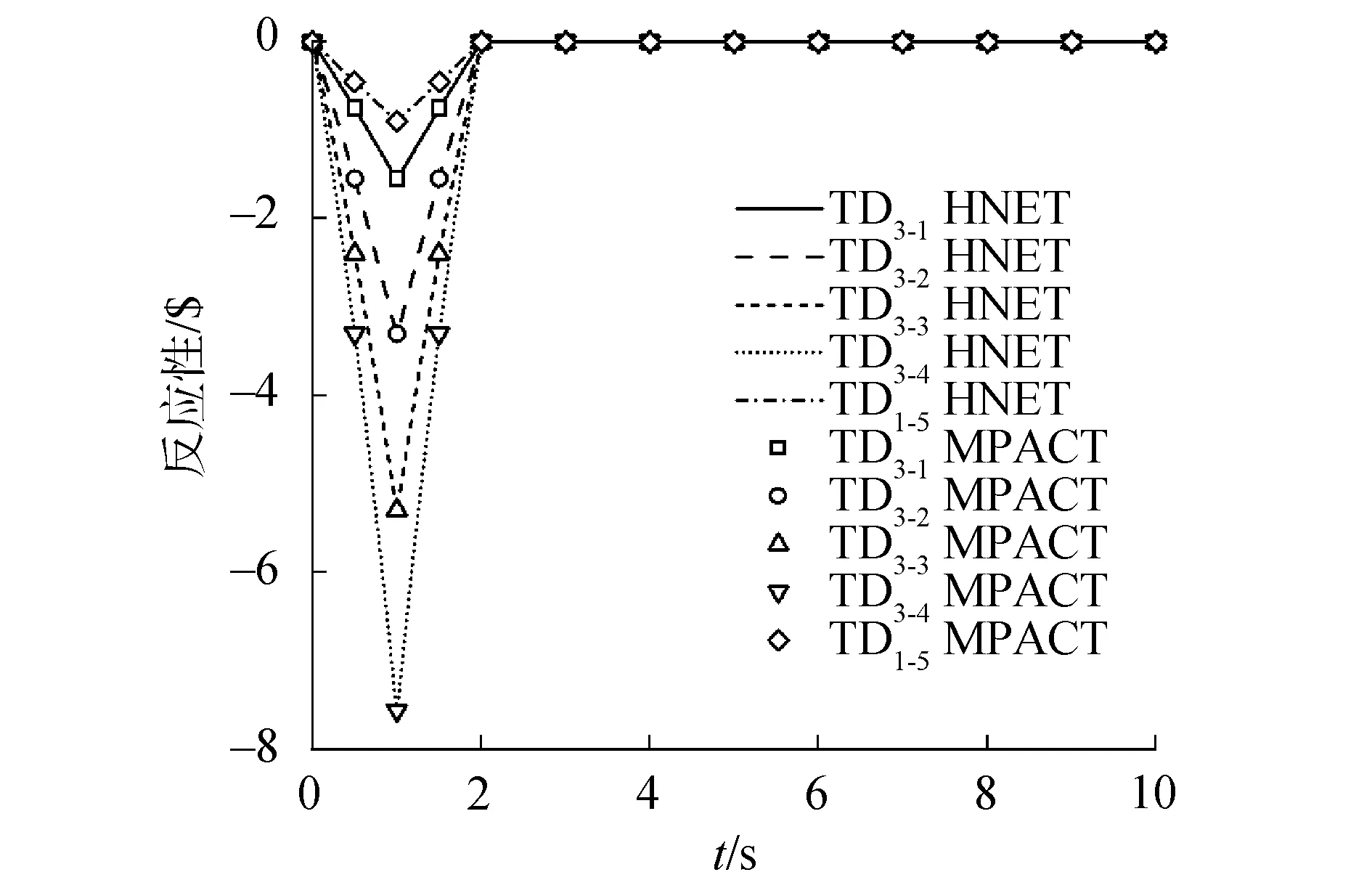
图9 TD3系列反应性历史Fig.9 TD3 reactivity history
对于TD1、TD2和TD3系列,在0~1 s和1~2 s的过程中,宏观截面以相同的速度增减变化,使得裂变率和反应性的增减也出现了对称的趋势。同时,TD2系列的控制棒插入深度大于TD1系列,导致TD2系列引入了数值更大的负反应性。图1~9表明相对功率和反应性的变化规律与MPACT的结果相符。同时,表1列出了每个二维算例的10 s瞬态过程的运行时间并与MPACT参考解对比。
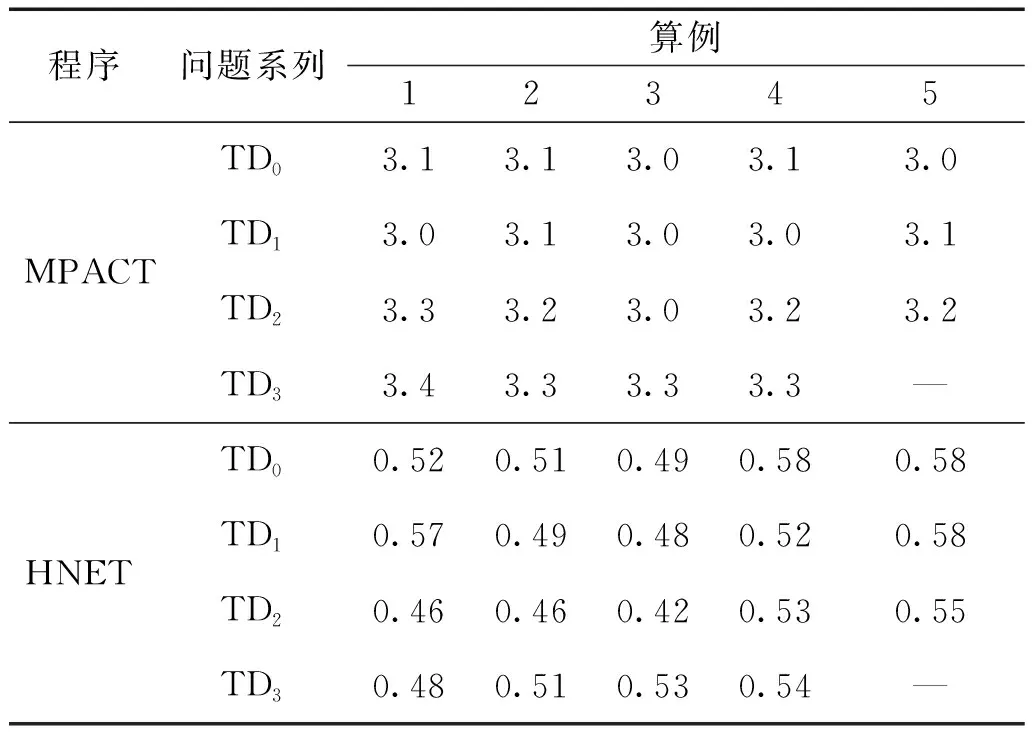
表1 TD1~TD3系列算例运行时间对比Table 1 Comparison of total run times for TD1~TD3 h
对于TD1系列,功率峰值的最大偏差为0.48%;功率的最大偏差为0.48%,发生在“TD1-5”的1 s时刻;反应性峰值最大偏差为0.26%,发生在“TD1-1”。对于TD2系列,功率峰值的最大偏差为0.21%;功率的最大偏差为0.14%,发生在“TD2-5”的10 s时刻;反应性峰值的最大偏差为1.26%,发生在“TD2-3”。对于TD3系列,功率峰值的最大偏差为-0.72%;功率的最大偏差为-0.74%,发生在“TD3-1”的1.05 s时刻;反应性峰值的最大偏差为1.14%,发生在“TD3-1”。
3.2 三维算例计算结果
对于三维问题TD4和TD5系列,堆芯相对功率变化和反应性变化见图10~15。其中,“TD4-4”和“TD4-5”描述了不同控制棒同时插入和提出的过程,这导致了相对复杂的裂变率变化和反应性变化。表2给出了所有三维算例的运行时间并与MPACT参考解对比。
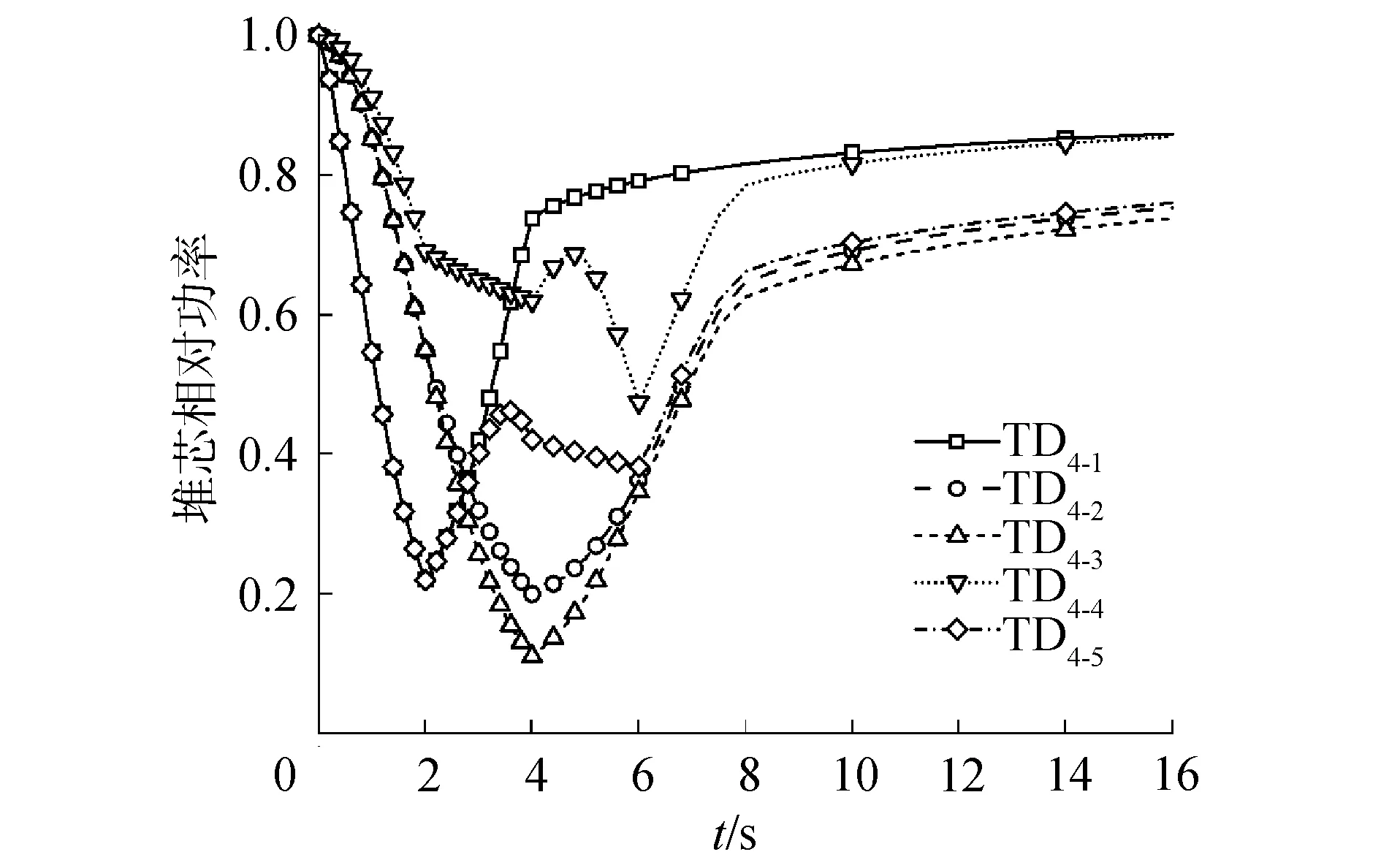
图10 TD4系列堆芯相对功率历史Fig.10 TD4 fractional core power history
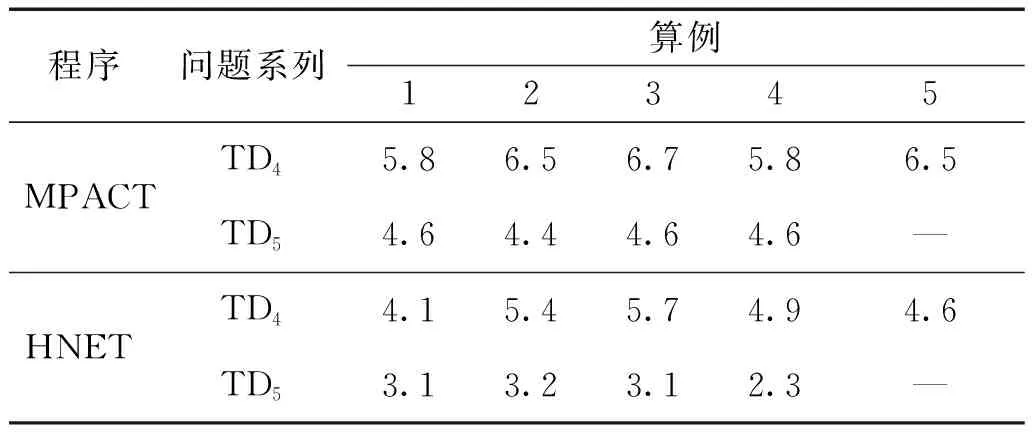
表2 TD4、TD5算例的运行时间Table 2 Run time summaries for TD4, TD5 h
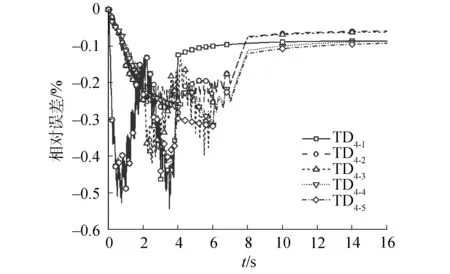
图11 对比MPACT程序的TD4系列堆芯功率相对误差Fig.11 Relative error of TD4 fractional core power compared to MPACT results
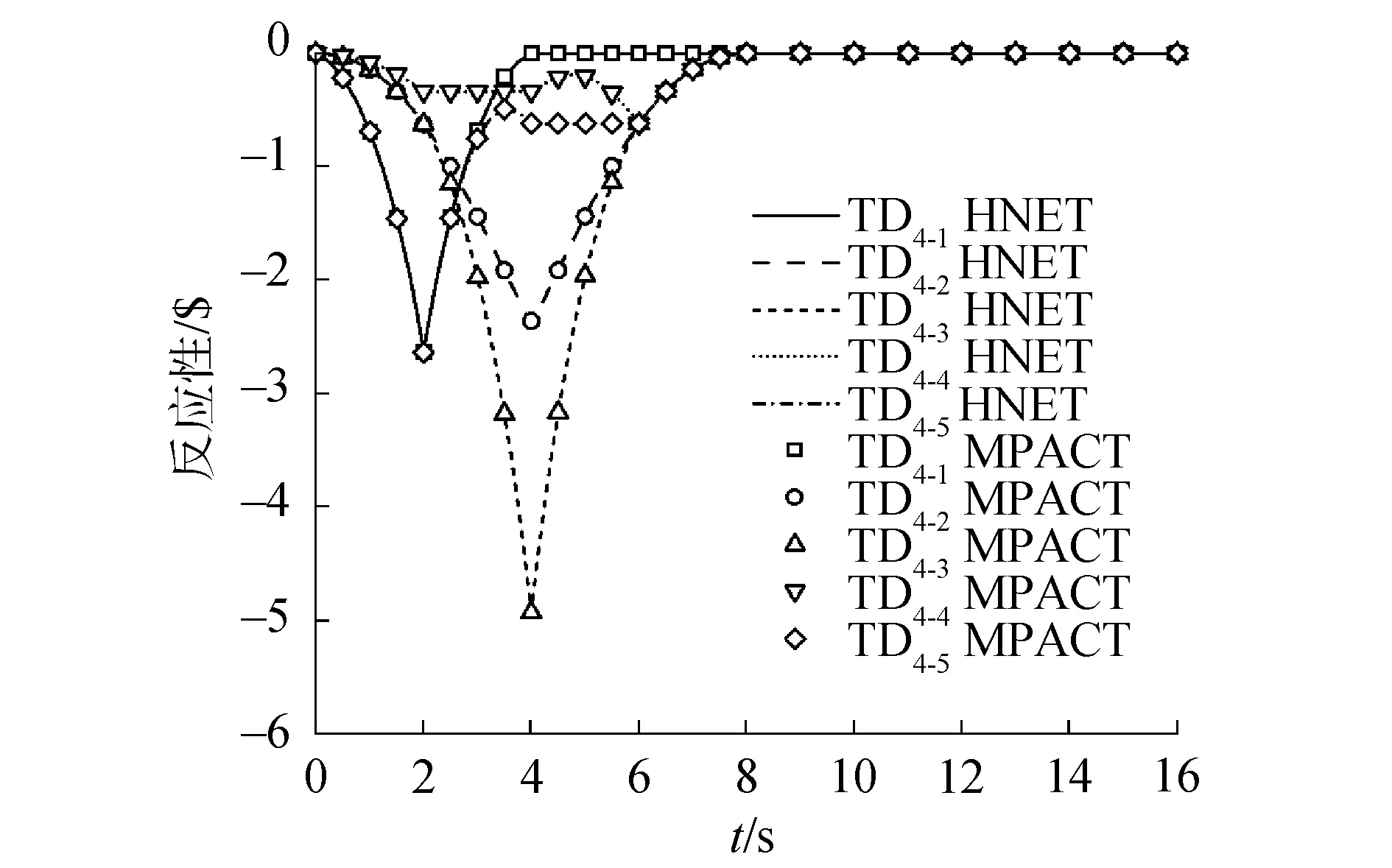
图12 TD4系列反应性历史Fig.12 TD4 reactivity history
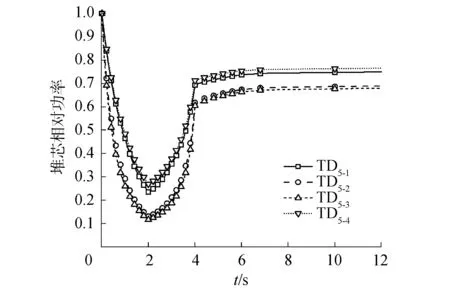
图13 TD5系列堆芯相对功率历史Fig.13 TD5 fractional core power history
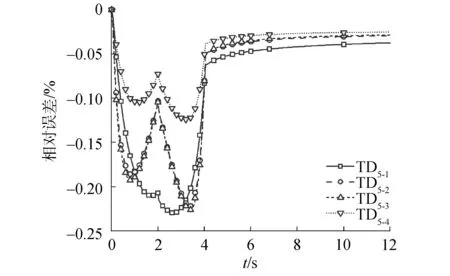
图14 对比MPACT程序的TD5系列堆芯功率相对误差Fig.14 Relative error of TD5 fractional core power compared to MPACT results
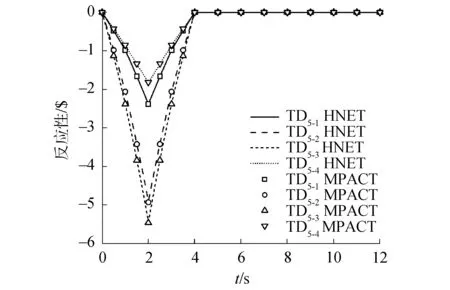
图15 TD5系列反应性历史Fig.15 TD5 reactivity history
对于TD4系列,功率峰值的最大偏差为-0.21%,出现在“TD4-1”;功率的最大偏差为-0.55%,发生在“TD4-5”的3.375 s时刻;稳定之后相对偏差为0.10%。反应性峰值最大相对偏差为2.21%,发生在“TD4-4”。对于TD5系列,功率峰值的最大偏差为-0.21%,出现在“TD5-1”;功率最大偏差为-0.23%,发生在“TD5-1”的2.3 s时刻;稳定之后相对偏差为-0.05%。反应性峰值最大相对偏差为0.66%,发生在“TD5-4”。
4 结论
1) 对于二维问题,在瞬态事件期间堆芯功率的相对误差有所波动,瞬态事件结束后相对误差逐渐趋于平稳。虽然计算模型的细微差别可能引入了一些偏差,如空间几何模型、离散策略、动力学参数的处理和加速方法等,但是总体而言,HNET的数值结果与MPACT基准解吻合得很好,堆芯功率的相对误差最大不超过0.8%,在保持足够精度的同时HNET程序算例拥有明显的效率优势。
2) 对于三维问题,在TD4问题上HNET的相对误差不超过0.55%,在TD5问题上相对误差小于0.23%,在输运时间步长相同的情况下,HNET程序的计算总耗时更少,与MPACT程序相比HNET程序只需要50%~85%的计算时间便可实现相同精度的瞬态输运计算。
3) 总体而言,HNET瞬态过程中堆芯总功率变化与反应性变化均与MPACT符合良好,已完全具备三维瞬态精细化计算的能力。
同时,用于瞬态计算的热工反馈功能正在研发中,未来将进一步测试HNET的时空动力学计算能力。
猜你喜欢
核科学与工程(2021年2期)2021-05-18 10:38:46
现代应用物理(2021年1期)2021-04-16 05:36:54
表面工程与再制造(2019年3期)2019-09-18 01:35:22
辐射防护通讯(2019年3期)2019-04-26 05:16:12
核技术(2016年4期)2016-08-22 09:05:32
工业设计(2016年8期)2016-04-16 02:43:35
设备管理与维修(2016年6期)2016-03-16 02:22:08
核科学与工程(2016年3期)2016-01-03 07:22:21
核科学与工程(2015年3期)2015-09-26 11:58:19
核科学与工程(2015年1期)2015-09-08 13:24:35
