
Q-learning算法优化的SVDPP推荐算法
2021-02-05 03:02周运腾张雪英李凤莲刘书昌焦江丽
计算机工程 2021年2期
周运腾,张雪英,李凤莲,刘书昌,焦江丽,田 豆
(太原理工大学信息与计算机学院,太原 030600)
0 概述
随着网络和信息技术的不断发展,现实社会中网络信息的数据量呈指数级增长。面对种类繁多的信息,如何获取个性化服务已成为人们的迫切需求。个性化推荐[1]通过各种推荐算法分析用户的行为喜好,能够有效过滤用户不需要的信息,主动为用户提供个性化的产品或服务。目前,个性化推荐已被广泛应用于社交[2]、新闻、音乐、图书和电影网站等应用[3],如网易云音乐[4]、淘宝商品推荐[5]、Netflix和MovieLens电影推荐等。
协同过滤(Collaborative Filtering,CF)技术[6]可用于推荐算法,其主要包括基于内存和基于模型两类算法。其中:基于内存的协同过滤推荐算法通过分析“用户-项目”评分矩阵计算相似度,并根据相似度进行预测推荐;基于模型的协同过滤推荐算法通过用户的历史购买记录、网络操作等数据训练一个预测模型,进而利用此模型对项目进行预测评分。许多研究通过改进协同过滤算法优化了推荐效果,如限制性玻尔兹曼机、K近邻算法[7]、奇异值分解[(8]Singular Value Decomposition,SVD)算法及其改进模型(Singular Value Decomposition Plus Plus,SVDPP)。SVD不仅是一个数学问题,其在很多工程中也得到了成功应用。在推荐系统方面,利用SVD可以很容易地得到任意矩阵的满秩分解,进而实现对数据的压缩降维。SVDPP在SVD基础上进一步融入了隐式反馈信息,采用隐式偏好对SVD模型进行优化,因此性能更优。但是SVDPP与SVD都没有考虑时间戳对推荐性能的影响,而实际推荐效果与时间戳仍然有一定的关联性,如十年前的用户对某一部电影的评分与当前用户的评分是有一定差异的,因此有必要对其进行改进,优化预测效果。
本文考虑时间戳对推荐性能的影响,通过马尔科夫决策过程(Markov Decision Process,MDP)对用户、评分、电影和时间进行建模,并利用强化学习Q-learning算法优化推荐算法,从而提升推荐效果,实现更准确的预测。
1 问题描述
在使用基于模型的推荐算法进行预测时,SVD和SVDPP模型都没有考虑时间戳对于推荐准确性的影响,而用户之前看过的电影会对他之后选择观看的电影类型及其对电影的评分产生影响。因此,本文利用马尔科夫决策过程对这种时序决策问题建模,反映时间戳数据与评分的关系,并通过强化学习对推荐算法进行优化。
Q-learning算法是一种基于反馈和智能体的无模型的强化学习方法,本文提出一种基于Q-learning算法优化的SVDPP推荐算法RL-SVDPP,以解决SVDPP在电影推荐预测中未考虑时间戳影响的问题。
强化学习[9-10]作为一种机器学习方法,主要原理是智能体以试错的方式进行学习,通过自身与环境交互获得奖励。目前,强化学习已经被成功应用到神经网络和文本处理等领域,但将该方法直接应用于推荐算法的研究较少,现有研究主要通过结合深度神经网络进行模型训练并推荐预测[11]。笔者受启发于Netflix Prize比赛中竞赛选手将时间戳应用到矩阵分解模型[12],以及文献[13]将强化学习用于协同过滤的思路,考虑到用户对一部未看过电影的评分可以通过他之前看过的电影评分来预测,即时间戳会影响用户对未知电影的评分,将SVDPP推荐算法得到的预测评分进一步采用马尔科夫决策过程中的奖惩函数进行优化,建立推荐预测评分与马尔科夫决策过程之间的映射关系,并利用强化学习Q-learning算法[14]进行模型训练,以优化预测过程。
2 建模过程
2.1 奇异值分解
现实生活中的“用户-项目”矩阵规模很大,但是由于用户的兴趣和消费能力有限,单个用户消费产生评分的物品是少量的,SVD的核心思想是将高维稀疏的矩阵分解为2个低维矩阵,相对于特征值分解只能用于对称矩阵,SVD能对任意M×N矩阵进行满秩分解,以实现数据压缩。但是在采用SVD对矩阵进行分解之前,需要对矩阵中的空白项进行填充,以得到一个稠密矩阵。假设填充前的矩阵为R,填充后为R′,则计算公式为:

利用SVD算法获取预测评分的计算公式如下:

其中:μ代表评分的平均值;bu、bi分别代表用户u和电影i的偏置量;qi、pu分别对应电影和用户在各个隐藏特质上的特征向量,上标T代表转置。
如果用户对某个电影进行了评分,则说明他看过这部电影,这样的行为蕴含了一定的信息,从而可以推理出评分这种行为从侧面反映了用户的喜好,据此可将这种喜好通过隐式参数的形式体现在模型中,得到一个更为精准的模型SVDPP[15]。
利用SVDPP模型获取预测评分的计算公式如下:
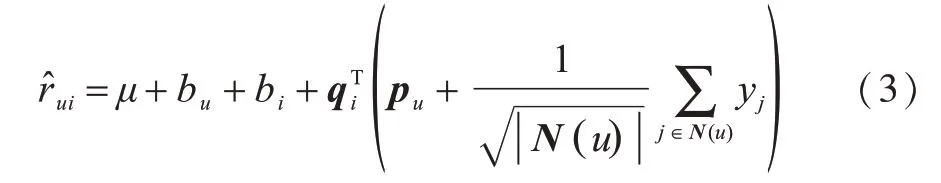
其中:N(u)为用户u浏览和评价过的所有电影的集合;yj为隐藏的评价了电影j的个人喜好偏置;用户u的偏好程度由显式反馈pu和隐式反馈两部分组成。
2.2 马尔科夫决策过程
马尔科夫决策过程是决策理论规划、强化学习及随机域中其他学习问题的一种直观和基本的构造模型[16]。在这个模型中,环境通过一组状态和动作进行建模,可用于执行控制系统的状态。通过这种方式来控制系统的目的是最大化一个模型的性能标准。目前,很多问题(如多智能体问题[17]、机器人学习控制[18]和玩游戏的问题[19-20])成功通过马尔科夫决策过程进行建模,因此,马尔科夫决策过程已成为解决时序决策问题的标准方法[21]。
一般的马尔科夫决策过程由五元组<S,A,P,γ,Rew>表示,如图1所示,其中,st表示状态,at表示动作,rt表示回报函数。智能体感知当前环境中的状态信息,根据当前状态选择执行某些动作,环境根据选择的动作给智能体反馈一个奖惩信号,根据这个奖惩信号,智能体就从一个状态转移到了下一个状态。
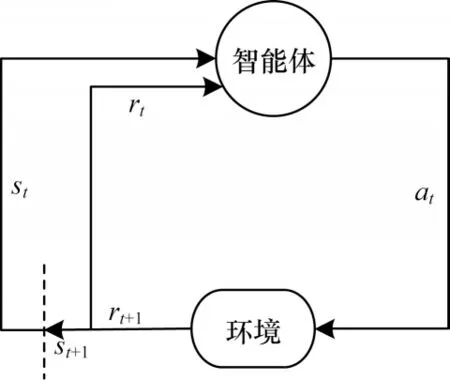
图1 马尔科夫决策过程Fig.1 Markov decision process
采用强化学习方法对SVDPP推荐模型进行优化,首先需要建立推荐预测模型与马尔科夫决策过程的映射关系。由于本文采用MovieLens 1M数据集作为研究对象,因此需要将用户在不同时间戳下对电影的评分转换成五元组以构造马尔科夫决策过程。下面给出本文设计的电影评分到马尔科夫决策过程的映射关系。

2.3 状态表生成
由上述马尔科夫决策过程可知,一个状态转移到下一个状态的动作对应下一个时间电影的评分,虽然这样在表面上忽略了电影名及电影类型,但用户对电影的喜好被隐式地反映在时间戳里,通过这个过程可将MovieLens 1M数据集处理为表1所示的形式。其中,括号中的第1个数字反映了对应行用户给对应列电影的评分,第2个数字反映了对应行用户观看对应列电影的时间戳信息或者时间顺序,如第1行第1列(4,3th)表示用户1观看电影1的时间顺序是第3个,因此,时间戳t=3且用户1对电影1打了4分,NaN表示对应用户未观看这部电影。
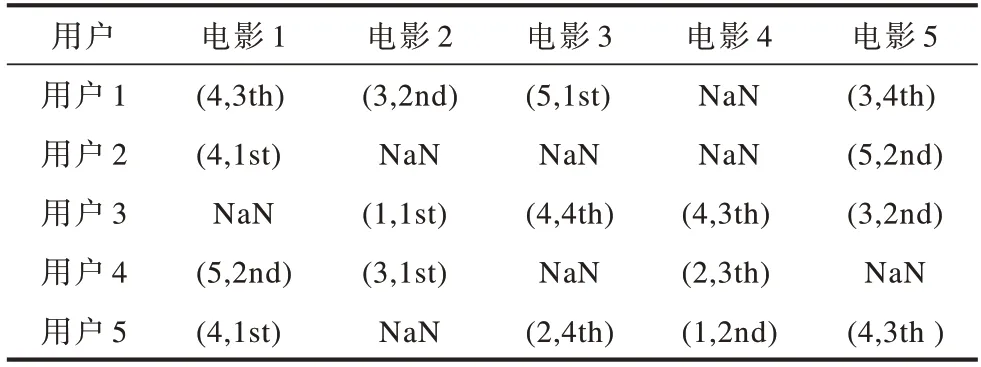
表1 MovieLens 1M数据集部分数据Table 1 Partial data of MovieLens 1M data set
将表1的数据按照时间戳排序,生成的状态转移路径如下:

根据表1得到该状态转移路径的规则,以第1行为例进行说明。第1行状态转移路径5→3→4 →3反映了用户1在时间戳t=1时看电影3,对电影3的评分为5,t=2时看电影2,对电影2的评分为3,t=3时看电影1,对电影1的评分为4,t=4时看电影5,对电影5的评分为3。其余4个转移路径采用类似方式得到。
此状态转移路径表示马尔科夫决策过程中状态的转移,指引了Q表更新的方向。
3 RL-SVDPP算法
本文提出的RL-SVDPP算法包括训练与预测两部分。训练时,首先采用SVDPP算法对训练集进行模型训练,得到SVDPP推荐模型,如式(3)所示,然后对强化学习模型进行训练,利用式(5)所示的奖惩函数计算状态转移的奖惩值Rew,完成强化学习Q表的更新,用于SVDPP推荐评分的优化模型。预测时,首先根据SVDPP推荐模型得到预测评分值,再用本文设计的优化模型对预测评分进行优化,得到最终的预测评分。本文设计的优化模型表示如下:

3.1 训练过程
首先通过式(3)对训练集进行训练,得到SVDPP推荐模型;然后对强化学习模型进行训练,利用式(5)计算奖惩值Rew,进而将Rew用于Q-learning算法中Q值的更新过程。Q表更新公式如下:

RL-SVDPP算法训练过程的伪代码如下:
算法RL-SVDPP算法训练过程

3.2 预测过程
预测过程根据SVDPP推荐模型得到的预测评分,结合训练的Q表来预测用户u对电影i的评分,同时可预测用户u未观看但是其他用户观看过的电影。

3.3 数据稀疏性及边界点问题的处理
本文所采用的MovieLens 1M数据集存在缺省值,即存在没有评分的电影信息。根据本文优化模型的构建思路,后续优化过程中需要利用未评分电影评分信息,这将导致中可能缺少s或者a的值,从而使优化模型失效。为避免出现这一情况,本文采用SVDPP模型对缺失值进行预测再取整填充,以解决数据稀疏的问题。
此外,当t=1,2时,边界的会超出下标范围,出现没有对应取值的情况。因此,本文采用最后两列的预测评分作为第-1列和第0列的预测评分数据,以保证数据的完整性。
4 实验
4.1 实验数据
本文实验采用MovieLens 1M数据集,其中包含6 040个用户对3 952个影片的近1亿条评分,评分范围为1分~5分。本文将数据的80%作为训练集来训练RL-SVDPP模型,其他的20%作为测试集,通过均方根误差(Root-Mean-Square Error,RMSE)来评价推荐算法的准确性。
4.2 评价指标
评分预测的准确度一般通过均方根误差来决定,定义如下:
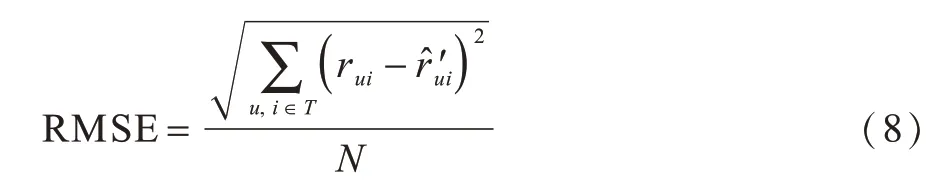
其中:rui表示测试集中用户u对电影i的真实评分;为采用本文算法得到的预测评分;T为电影集合;N表示该用户看过的电影总数。
4.3 实验结果与分析
为验证本文算法的有效性,除了对SVDPP模型进行优化得到RL-SVDPP模型外,同时也对SVD模型进行训练,建立优化模型RL-SVD。实验分别建立SVD及SVDPP模型,并求出预测评分,以得到奖惩函数Rew,根据奖惩函数可得到对应的奖惩表,如表2和表3所示。奖惩函数作为马尔科夫决策过程中最重要的部分,能够隐式地反映学习目标,指出马尔科夫决策过程的前进方向。在表2和表3中,行表示状态,列表示动作,如-1.137 11表示在状态1时,进行动作1得到的奖励值为-1.137 11,其他以此类推,其中奖励值为正表明对正确行为给予奖励,奖励值为负表明对错误动作给予惩罚。
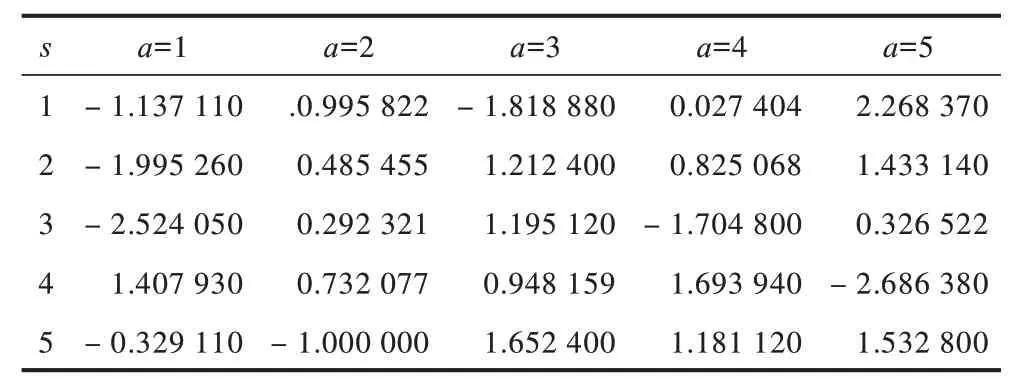
表2 由SVD预测评分得到的奖惩表Table 2 Reward and punishment table by SVD prediction scores
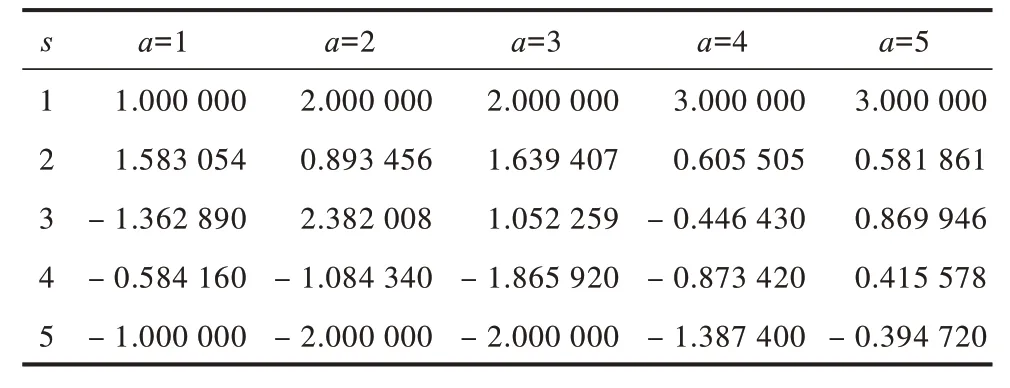
表3 由SVDPP预测评分得到的奖惩表Table 3 Reward and punishment table based by SVDPP prediction scores
将奖惩函数Rew用于Q表更新过程,更新后的Q表如表4和表5所示。可以看出,通过Q-learning算法训练生成的Q表中的值有正有负。为更形象地进行描述,将表中数据绘制成三维空间图,如图2和图3所示,其中,凸起和凹陷部分表示在某状态下采取动作获得的期望收益有好有坏。可以看出:RL-SVD算法Q表三维图中Q值动态变化范围较大,变化范围为-0.979 930~1.000 000,25个Q值中有14个为负值;RL-SVDPP算法得到的Q表三维图中Q值动态变化范围较小,变化范围为-0.145 190~0.175 280,25个Q值中有10个为负值。这表明RL-SVDPP选择正确动作得到奖励的情况多于选择错误动作进行惩罚的情况,因此,其优化性能优于RL-SVD。下文将通过RMSE性能对比进一步验证该结论。
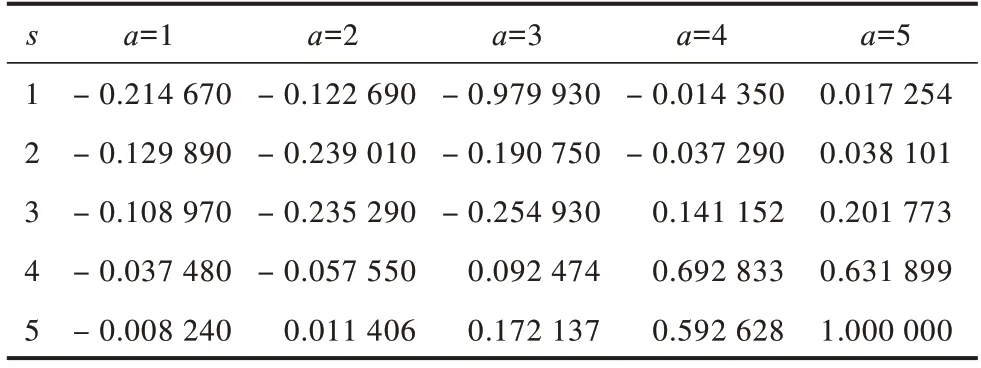
表4 由SVD预测评分得到的Q表Table 4 Q table by SVD prediction scores
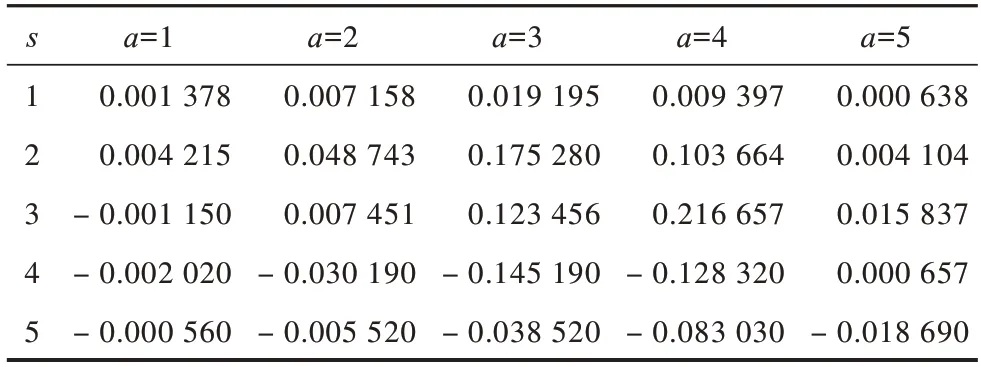
表5 由SVDPP预测评分得到的Q表Table 5 Q table by SVDPP prediction scores
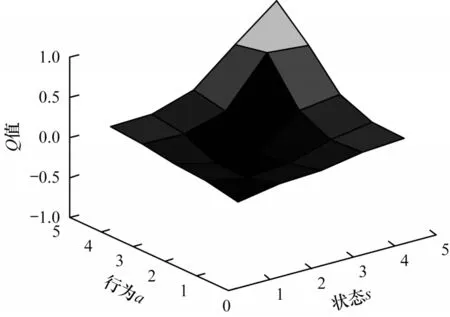
图2 RL-SVD算法Q表三维图Fig.2 3D diagram of Q table for RL-SVD algorithm
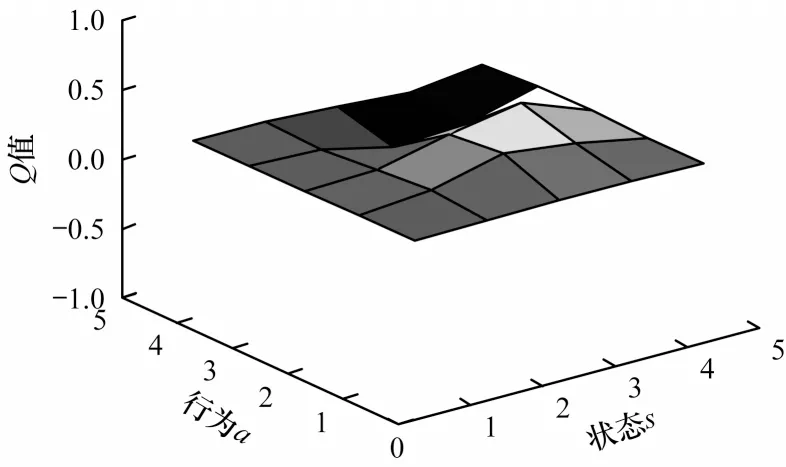
图3 RL-SVDPP算法Q表三维图Fig.3 3D diagram of Q table for RL-SVDPP algorithm
对20%的测试集采用本文提出的优化模型RL-SVD和RL-SVDPP计算预测评分,并通过式(8)求解其与实际评分的均方根误差,验证本文优化方法的有效性。RMSE比较结果如表6所示。
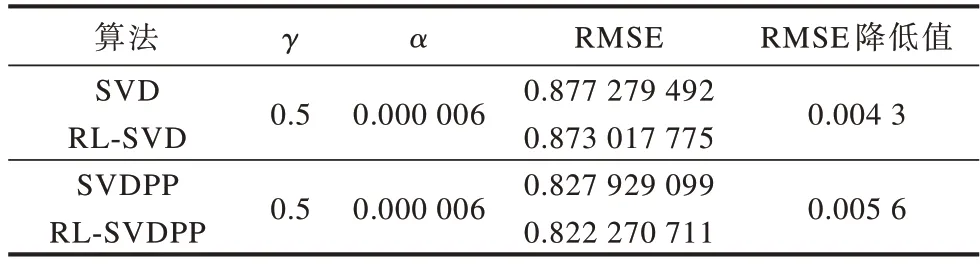
表6 本文算法与已有SVD/SVDPP的RMSE对比Table 6 Comparison of RMSE by the proposed algorithm and the existing SVD/SVDPP
可以看出:相对SVD算法,采用RL-SVD算法得到的预测结果比优化前SVD算法预测结果的RMSE降低了0.004 3;相对SVDPP算法,采用本文提出的RL-SVDPP算法得到的预测结果比优化前SVDPP的RMSE降低了0.005 6,验证了本文融合时间戳信息建立的强化学习优化的推荐模型的有效性,也说明用户对电影的评分与时间戳确实有一定的关系。
由于学习率α和折扣因子γ是可以动态调整的,因此进一步研究RL-SVDPP算法中α和γ的变化对预测性能的影响,实验结果如图4和图5所示。由图4可知,当γ一定时,α从0.000 003增大到0.3,10倍递增,RMSE的值会增大,并且当α比较大时,RMSE变化很小,因此,α应尽可能取较小的值。由图5可知,当α一定时,γ从0.4增大到0.6,RL-SVDPP算法的RMSE不断减小,实验中最好的效果是当α=0.000 003和γ=0.6时,此时RMSE能达到0.819 48,相比之前降低了0.008 6,由此证明了RL-SVDPP算法的可行性。
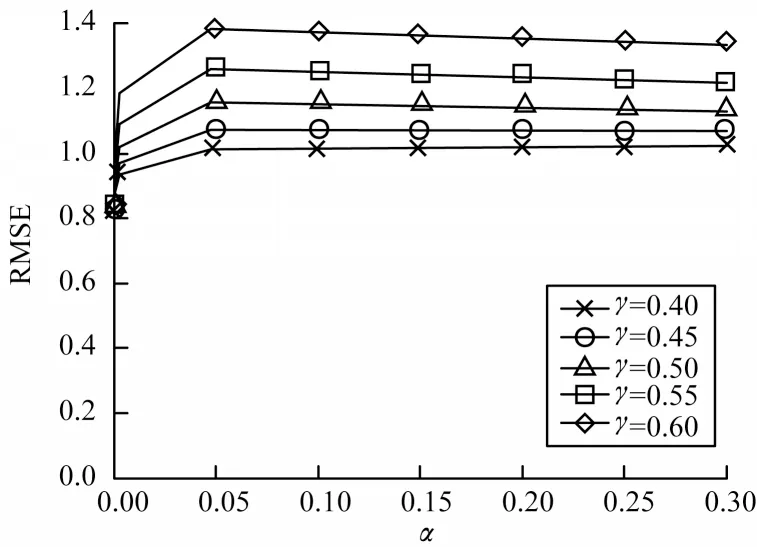
图4 γ 一定时α 变化对RMSE的影响Fig.4 Effect of α change on RMSE with constant γ
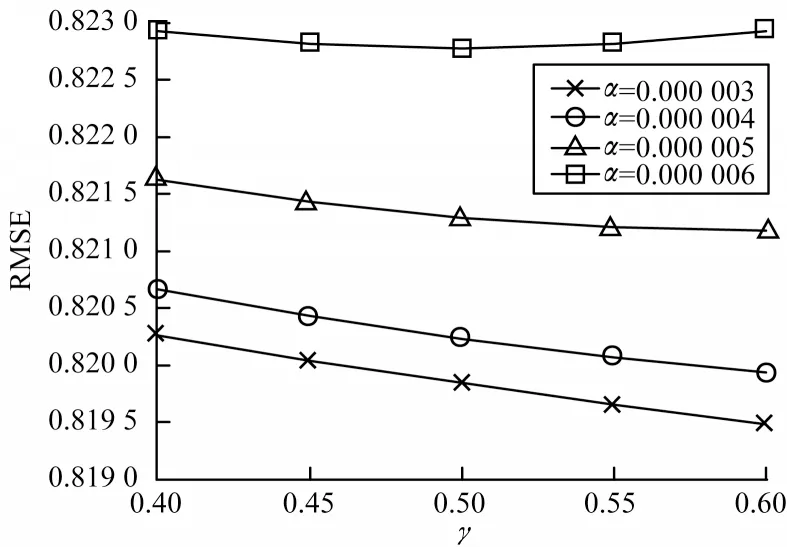
图5 α 一定时γ 变化对RMSE的影响Fig.5 Effect of γ change on RMSE with constant α
5 结束语
本文提出一种强化学习Q-learning算法优化的SVDPP推荐算法RL-SVDPP。将用户在不同时间戳下对电影的评分动作转化为马尔科夫决策过程,结合协同过滤算法与强化学习奖惩过程进行建模,对SVDPP推荐预测评分进行优化,并通过调整影响因子来改善预测效果。实验结果表明,用户过去的评分数据对当前的评分有显著影响,将用户对电影的喜好隐式地反映在时间戳中,有助于得到更精确的结果。本文仅采用强化学习方法中的Q-Learning对SVDPP进行优化,如何能通过融入时间戳对算法直接进行优化,或者将强化学习与其他推荐方法(如深度学习网络)相结合进行优化,将是下一步的研究方向。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
数字技术与应用(2022年3期)2022-04-14
有色金属(矿山部分)(2021年4期)2021-08-30
资源导刊(信息化测绘)(2020年5期)2020-06-22
长江丛刊(2017年10期)2017-11-24
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
赤峰学院学报·哲学社会科学版(2016年12期)2017-03-20
湖北师范大学学报(自然科学版)(2015年1期)2016-01-10
