
汽车语音交互技术发展趋势综述
2021-02-01 07:02王兴宝雷琴辉梅林海张亚邢猛
汽车文摘 2021年2期
王兴宝 雷琴辉 梅林海 张亚 邢猛
(科大讯飞股份有限公司 智能汽车事业部,合肥230088)
主题词:语音交互 人机交互 语音识别 多模态
0 前言
近年来随着车联网系统迅速发展,汽车人机交互越受车企重视,其中语音作为最便捷的交互入口,在人机交互中发挥至关重要的价值,分析汽车行业近百年发展史,从早期的物理按键到触屏以及发展到现在的语音多模态等交互模式,每次变革都是围绕如何提升人机交互的体验为目标。语音交互全链路包括语音增强、语音识别、语义理解等多个环,如果其中一环亮红灯则会导致整体交互失败,但近几年由于深度学习算法改进,在各个算法模块都进行了升级,语音交互在部分垂类场景达到可用门槛。从汽车市场分析报告得出2020年中国汽车保有量将超过2亿辆,其中网联化备受人们关注,人机交互也面临着重大挑战,用户不再满足于基础的功能可用,期望更智能的交互模式。因此,未来的人机交互模式发展是重要研究课题。
1 汽车人机交互发展概述
1.1 汽车人机交互重要性
智能化和网联化已经成为汽车行业发展的必然趋势,越来越多的汽车企业正在积极向人工智能、软件服务、生态平台等方向发展,在汽车安全、性能全面提升的同时,让驾驶更智能、更有趣[1]。在此过程中,汽车与人之间的交互变的更为重要,如何让人与汽车之间更便捷和更安全的交互一直是各大车企及相关研究机构的研发方向。
1.2 汽车人机交互方式发展
1.2.1 物理按键
汽车在早期主要是以驾驶为目的,内饰也比较单一,主要集中在中控仪表盘上。车载收音机和CD 机的出现,成为了第一代车机主要娱乐功能,人与汽车交互开启了物理按键时代。在上世纪90年代,车内主要靠大量的物理开关按键进行控制车载影音娱乐系统,并且这些物理开关和按钮在空间设计上进行了一系列优化,由最初全部集中在中控仪表,慢慢迁移到驾驶员方向盘上。这些设计优化使人机交互的安全性和便捷性得到提升。
物理按键虽然是最原始的交互模式,但是在车内是最可靠的方式,车内安全性较高的部位还是使用物理按键,如:发动机起动、驻车以及车门开关等。随着汽车电子技术的发展及大规模的应用,汽车功能越来越丰富,收音机、空调、音响及电子系统开关按键分区排列,单一的物理按键方式已经不能满足用户的驾驶体验,于是屏幕显示开始引入车机。
1.2.2 触屏
在上世纪80年代触摸屏被大规模商用化,但是触摸屏根据材料不一样可分为:红外线式、电阻式、表面声波式和电容式触摸屏4 种。1986 年别克推出全触屏中控的量产车型Riviera,内部使用了一块带有触摸传感器的CRT(阴极射线显像管)显示屏,该屏幕在功能上集成了比传统物理按键更多的控制功能,包括:电台、空调、音量调节、汽车诊断、油量显示等功能,使得整个车内人机交互体验上升一个档次。2007 年,iPhone 手机将触摸屏做到了极致的交互体验,开创了手机正面无键盘触摸屏操作的时代。之后各家车企也着手中控屏幕的设计,以及相应的人机交互系统的设计。大屏支持音、视频播放,触屏操控的交互方式成为第2代车机的标配。
2013年,特斯拉全新推出了采用垂直定向搭载17英寸车载显示屏的电动车—MODEL S,全面取消中控物理按键,几乎可利用屏幕操控所有的车载功能。2018 年,比亚迪第2 代唐推出了支持90°旋转功能大尺寸的悬浮式中控屏。中控屏也朝着大尺寸、可移动、多屏幕方向发展。
1.2.3 语音交互
在互联网通信技术以及智能交通快速发展的环境下,汽车本身也逐渐演变成能集成各种信息源的载体,随着人工智能技术的突飞猛进和车联网应用的大范围普及,语音交互的准确率、响应速度、便利性上有了很大提高。
在国际上,宝马、奔驰、福特、大众等多家车企已经将语音交互技术整合到车机内,为用户提供方便、安全、高效的车内人机交互方案。而在2012 年之前,中国汽车市场的语音交互几乎都是由国外公司定义的。随着2010 年科大讯飞发布了全球首个智能语音云开放平台,自主语音技术占据市场主导。2011~2013年,云+端技术架构、全球首个车载麦克风阵列降噪模块的发布,标志着中国自主的车载语音交互产品效果已经反超国外,到2014年在行车高噪环境下识别率已经超过90%。吉利、长安、奇瑞、上汽等自主品牌积极与语音技术和产品公司合作,深度定制搭载语音交互技术的车载系统。
2015年,科大讯飞和奇瑞汽车联合打造的iCloudrive 2.0智能车载系统上市发布,产品以高效的语音体验颠覆了人们对于交互场景的认知,以语音交互深度打通了车机功能和信息娱乐服务,成为了业内追捧的人车交互标杆产品。
2016 年,上汽和阿里联合打造的斑马智行1.0 搭载荣威RX5上市发布,通过集成丰富的互联网生态服务和内容,以语音交互的方式作为连接用户的桥梁,成了当时行业内公认的互联网汽车标杆。
2017 年,蔚来ES8 首次在车内搭载Nomi 机器人,让人机交互更形象好,用户对人机交互助理的热度提升,定位开车旅途中的伙伴更拟人化。
随着技术的发展,第3代车机在往信息化、智能化发展,采用更好、兼容性更强的安卓等车机系统。通过快速集成免唤醒、语音增强、声源定位、声纹识别、自然语音交互、主动式交互、智能语音提示等新的技术,全面增强了驾驶空间的安全性、趣味性,互动性[2],打造了沉浸式交互体验的智能驾舱。
1.2.4 多模态交互
人与人交流除听觉外,还有许多感官通道,为了提供更好的人机交互体验,需充分利用人的多种感知通道(听觉通道、视觉通道、触觉通道、嗅觉通道、意识通道等),以不同形式的输入组合(语音、图像、手势、触摸、姿势、表情、眼动、脑电波等)为人机交互通道提供多种选择,提高人机交互的自然度和效率。多模态并非多个模态的集合,而是各单一模态之间的有机协同和整合[3]。
机器利用电脑视觉技术,识别人类的姿势和动作,理解其传递的信息、指令,使得人机交互体验更加自然、高效。而识别人类的面部表情和目光,更重要的意义在于传递的情感,进而增强语言、手势传递的含义,这也解释了为什么我们在面对面交流时,会试图注视对方的表情和目光,就是为了准确判断对方的意图和情绪。因此,使机器从“能听会说”到“理解思考”再到“察言观色”,才能全面提高人机交互的智能化水平。
在2019 年北美CES 展上,奔驰CLA 车型搭载的最新人机交互系统,支持复杂语音指令和手势识别。拜腾保留了48寸的车载大屏,同时将触摸屏、语音控制、手势控制、物理按键进行了充分的融合。日产展示了全新的车载AR 概念,应用了无形可视化、I2V 技术。丰田发布了搭载个性化、情感化感知的全新汽车驾舱。围绕语音识别、手势识别、图像识别等多模态融合交互方式必将成为新的制高点,成为下一代人机交互势不可挡的发展趋势。
2 汽车语音交互技术发展现状
2.1 语音交互技术发展
从语音交互整个处理链路来看(图1),可将其分为3部分:语音输入、语音处理和语音输出,其中语音输入包括:语音增强;语音处理包括:语音唤醒、语音识别、语义理解;语音输出包括:语音合成和音效增强。在2006年人工智能第3次浪潮推动下,利用深度学习理论框架将语音交互链路中各模块算法得到升级,并且配合大量数据持续迭代,语音交互成功率得到较大提升,达到可用的门槛,另外随着芯片算力的显著提升以及5G 的普及,提高语音交互整体交互成功率。

图1 语音交互全链路
2.2 语音交互核心技术
2.2.1 语音增强
声音的信号特征提取的质量将直接影响语音识别的准确率。车内环境噪音源包含发动机噪声、胎噪、风噪、周围车辆噪声、转向灯噪声以及媒体播放声等,这些噪声源都会减弱人声的信号特征,从而加大识别难度。

图2 语音增强处理流程
基于麦克风阵列的语音增强算法如图2、图3,包括:波束形成、语音分离、远场拾音与去混响、多通道降噪、声源定位和回声消除等技术,可有效抑制周围环境噪音,消除混响、回声干扰,判断声源的方向,保障输入较干净的音频,提高识别准确率,做到机器能“听得清”[4-5]。目前最新采用基于神经网络的降噪技术在高噪环境下取得较好效果[6]。
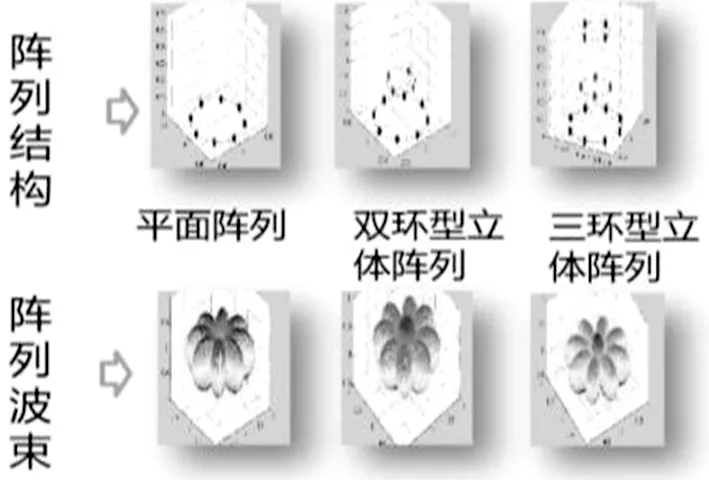
图3 麦克风阵列结构
2.2.2 语音唤醒
语音唤醒是现阶段语音交互的第一入口,通过指定的唤醒词来开启人机交互对话,其技术原理是指在连续语流中实时检测说话人特定语音片段,要求高时效性和低功耗。语音唤醒在技术发展上也经历3个阶段(图4):启蒙阶段、新技术探索阶段和大规模产业化阶段。从最初的模板规则到最新基于神经网络的方案[7]。另外,配合语音增强中声源定位技术,可实现车内主副驾、前后排等多音区唤醒。
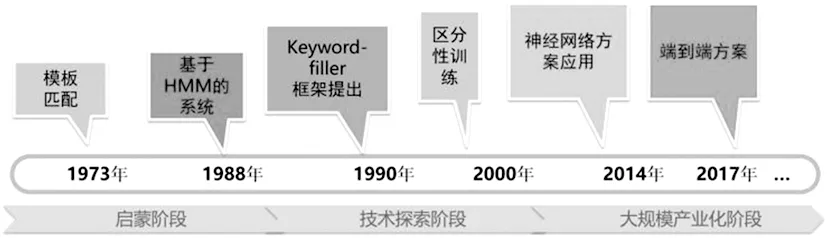
图4 语音唤醒技术发展史
2.2.3 语音识别
语音识别是将人的语音内容转成文字,其技术原理主要包括2大模型(图5):声学模型和语言模型,在技术从最初的基于模板的孤立词识别,发展到基于统计模型的连续词识别,并且在近几年深度学习爆发,将语音识别率达到新水平[8-9]。当前语音识别中重点需解决如下3类问题。
(1)语音尾端点检测问题,能量VAD(Voice Active Detection)、语义VAD和多模态VAD;
(2)多语种和多方言统一建模问题;
(3)垂类场景和针对单独人群的个性化识别问题。
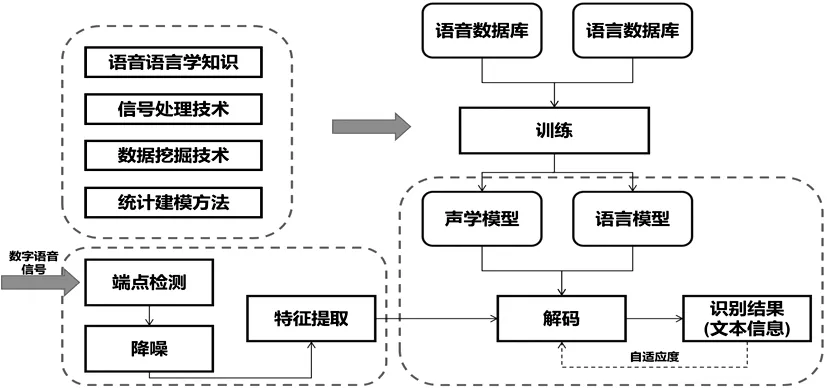
图5 语音识别处理流程
2.2.4 语义理解
语义理解是当前语音交互中最难的一环,将人类的表达抽象成统一表示形式以让机器能够理解,在语音交互对话系统中,主要包括:语义抽取、对话管理和语言生成;在技术方案上(图6),近几年随着词向量模型、端到端注意力模型以及谷歌最新BERT 模型进步[10-11](图7),语义理解正确率在部分垂直领域达到基本可用,如汽车领域头部技能“导航、音乐、车控、收音机和电话”等[12]。但是,语义理解最核心的难点是语义表示问题和开放性说法等问题,导致在语义效果评判上很难统一,也是未来人机交互中最核心板块。

图6 对话理解技术方案
2.2.5 语音合成
语音合成是将文字信息转化为可听的声音信息,让机器会说话,其技术原理上将文字序列转换成音韵序列,再用语音合成器生成语音波形(图8)。语音合成的方法主要有共振峰合成、发音规则合成、波形拼接合成和基于HMM 参数合成4 种。前2 种是基于规则驱动,后2种基于数据驱动,目前主要以数据驱动为主。近年来基于神经网络技术的语音合成,在主观体验MOS 分达4.5 分,接近播音员水平[13-14]。另外,当前在个性化合成、情感化合成以及方言小语种合成等方面继续探索。
图7 自然语言处理[10-11]

图8 语音合成处理流程
2.2.6 音效增强
音效增强是语音交互全链路最后一环,在基于车内复杂噪声环境及扬声器位置造成的复杂声场环境,进行专业的声学系统设计与调教,还原出自然清晰舞台感明确的音响效果。未经过专业声学处理的音响系统,会丢失声音的定位信息,不能还原音乐的左右空间感和前后纵深感。声音出现杂乱无章,从各个地方出来并互相干扰。根据不同场景包括:3D沉浸环绕声、EOC(Engine Order Cancellation)、超重低音、高精度声场重建、声浪模拟、提示音播报优化、延时修正、声场重建、虚拟低音、限幅调整和车速补偿等音效算法技术[15]。通过加入高级环绕算法,音量随车速动态增益,主动降噪,引擎声优化,能为汽车打造音乐厅级的听感体验(图9)。

图9 音效增强的优势
3 汽车未来人机交互发展展望
3.1 汽车人机交互的市场价值
从当前的市场和行业发展趋势可预测,到2020年中国汽车的保有量也将超过2亿辆,市场增长空间依然巨大。智能化、网联化、电动化、共享化已成为汽车产业发展的趋势,国家层面陆续发布一系列政策推动汽车产业变革。根据中国汽车流通协会发布的《2019中国汽车消费趋势报告》[16]得出,消费者正从基础功能满足延伸至科技智能追求,智能化、网联化越来越受到关注,2019 年智能化关注度相比2018 年同比增长30.8%,网联化关注度同比增长52.3%,其中网联化最关注语音和导航体验,另外消费者对语音识别的准确性和反应速度比较看重,而从具体配置上来看,消费者对CarLife、CarPlay 和语音识别的需求上升趋势较为明显,这也说明消费者对汽车联网有诉求,但是对原生车机应用效果不满(图10)。

图10 消费者对汽车网联化的需求[16]
目前,中国在汽车智能化网联方面处于领先水平,这涉及到“中国汽车市场规模全球最大”、“中国互联网和移动互联网发展迅速”、“国家政策倾向”和“自主车企进步较大”等众多因素影响。面对重大的机遇与挑战,车联网人机交互作为整个智能化的入口,如何给用户提供最便捷和安全的交互方式,对于其未来的发展至关重要。
在人机交互方面的升级将会为未来汽车产生革命性的消费体验,车云研究院发布的《2020 智能汽车趋势洞察及消费者调研报告》[17]中,提到智能汽车3大体验革命:个性化体验、智能交互体验和车路协同体验,其中智能交互1.0基本围绕功能交互、触控交互和初级语音交互,智能汽车2.0 应建立起以人为中心的个性化服务全新体验,多模、主动和情感交互将成为智能交互典型特征。
3.2 汽车人机交互发展趋势
3.2.1 从“基本可用”到“好用易用”
语音交互的整个链条,包括了语音增强-语音唤醒-语音识别-语义理解-语音合成-音效增强。优秀的语音交互系统,需要全闭环的技术链条上每一个环节都是优秀的,如果过程中某一技术环节出问题,则会导致整个交互过程失败,用户体验效果不好。
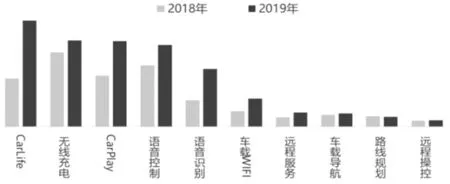
图11 消费者对汽车网联化具体配置需求[16]

图12 智能汽车2.0未来发展典型特征[17]
当前语音交互已经达到基本可用状态,用户已经可以通过语音做垂类领域信息查询以及车辆控制等,但还有许多待解决的问题,主要体现如下3个方面。
(1)核心技术上需要继续突破,包括高噪环境、方言、口音、童声等因素下语音识别鲁棒性问题,语义理解的泛化性以及歧义性问题,个性化和情感化语音合成问题等;
(2)语音交互模式上的持续优化,从最初单轮one-shot 模式到全双工免唤醒模式,需要在系统误触发方面技术突破;
(3)信源内容深度对接和打磨,语音交互只是入口,用户希望通过语音便捷的获取到更有价值以及更有趣的内容,则需要语音交互各模块能力与信源内容深度耦合。
3.2.2 从“主副驾交互”到“多乘客交互”
目前智能汽车中应用场景交互主要考虑的是主驾驶方位和副驾驶方位2侧,而对于后排的乘车人员的交互过程和交互效果没有得到很好的保证,例如,在功能范围内,主驾驶和副驾驶人员基本可以自由的与车机对话,实现相应的功能,但是对于后排乘客,就有很多制约条件,后排人员距离麦克风位置较远,语音指令不能被很好的检测到,整体交互效果较差。
基于整车多乘客需求,未来将会在车内实现“多乘客交互”的目标,所谓“多乘客交互”就是说,将以往采用的双音区技术更改为四音区技术,在每一个位置前都装1个麦克风,可以让各自位置的乘客通过语音或者其他交互方式控制各自的交互设备,即使在同一时间说出指令也互不影响。例如,当后排右后座位乘客想要打开或者关闭自侧车窗时,可以直接语音指令说“打开车窗/关闭车窗”就可以打开右后侧车窗,其它方位不受影响,而驾驶员(主驾驶)语音指令说“打开车窗”时也只会打开主驾驶一侧的车窗,不会打开车内全部车窗,这也是未来智能汽车更智能更人性化的一种表现。
3.2.3 从“被动式执行机器人”到“拟人化贴心助理”
随着智能化技术的不断进步,单纯的功能型产品已经不能满足用户的需求了,用户想要在保证功能的前提下也可以感受到更多的“以人为中心”的产品服务,真正实现让汽车越来越理解人,越来越有温度的理念。通过用户交互的历史数据生成用户的知识图谱和交流风格画像,生成一个针对用户的个性化人机交互策略,该策略具备调动车载系统各项服务(比如车控、音乐、导航、游戏等)的能力,以虚拟形象或实体机器人的方式生成符合用户个性化需求的外表和声音特性与用户主动或被动的进行交流。例如,用户在车上说“查找附近的餐馆”,机器会依据用户的口味和习惯自动推荐符合该用户餐馆;另外驾驶员在开车过程中,机器预测到驾驶途中天气情况恶劣,则主动告知驾驶员天气信息注意开车;车辆发生故障,机器主动告知车辆故障情况,并引导驾驶员到最近的4S店维修;心情不好时候,能够推荐一些喜欢的歌曲或者讲一些笑话等等。
3.2.4 从“车内交互”到“跨场景交互”
物联网的出现可以让所有能行使独立功能的普通物体实现互联互通,借助于物联网的浪潮,汽车内跨场景交互也将是智能汽车未来发展的必然趋势。
当前,汽车人机交互的使用场景过于单一,车机系统放在车内只可以控制车内的设备,而对于车外其他场景的控制却无能为力。比如在车内控制自己家中的设备,在车内控制自己办公室的设备,在家中控制车内的设备,在公司控制自己车内的设备,未来“智能汽车-智能家居”、“智能汽车-智能公司”的跨场景交互的实现,不仅可以给车主提供一体化的车-家、车-公司的互联生活,也让智能汽车的发展达到了一个崭新的制高点。
3.2.5 从“语音交互”到“多模态交互融合协同”
语音交互的方式已经成为汽车内人机交互的主流方式,但是当车内的噪音比较大时,单纯的语音交互方式就不能完全满足用户的需求,此时多模态融合的交互方式就显得尤为重要,此时用户的诉求就可以通过手势识别、表情识别等多模态相协作的方式来更好的完成交互过程。
多模态融合的交互方式可以根据用户当前所处的场景需要给用户提供不同的交互过程。当驾驶员正在行驶时,眼动跟踪技术会持续检测驾驶员的眼睛,表情识别会随时检测驾驶员脸部表情,当检测出现眼皮下垂、眨眼次数频繁或者驾驶员正在打哈欠时,就会对驾驶员执行语音提示,并自动打开空调设备或者是打开车窗,做一系列给车内通风的动作来帮助驾驶员恢复清醒的意识。如果在高速行驶会自动导航至附近的休息站或者是服务区,不在高速行驶时就会语音提示驾驶员临时靠边停车,以确保驾驶员的行车安全。表情识别可以实时检测驾驶员的面部表情,进而根据驾驶员当前所处的场景来判断其心理情绪,并根据其情绪自动语音打开合适类型的音乐,开启相对应的氛围灯,调节车内氛围以适应车内用户的当下心情,给用户更亲和、更智能化、更沉浸式的体验感受。
4 结束语
汽车领域在基于人工智能的人机交互整体还算刚起步阶段,语音交互虽然取得较大进步但是还不够稳定,许多场景下替代不了触摸和按键等操作,目前需要在语音、图像以及语义方面拥有技术上的突破,多模态融合和协同的交互模式将成为下一代汽车人机交互的重点。此外,随着无人驾驶和智能驾舱的发展,人们对人机交互的要求越来越高,需要在保障交互的安全性前提下,不断提升交互体验,使驾驶更安全、更便捷和更有趣。
猜你喜欢
意林·作文素材(2021年9期)2021-07-06
阅读(快乐英语高年级)(2019年5期)2019-09-10
阅读(快乐英语高年级)(2019年2期)2019-09-10
文苑(2018年23期)2018-12-14
小说界(2018年5期)2018-11-26
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
文苑(2018年21期)2018-11-09
儿童时代·快乐苗苗(2017年7期)2018-01-24
作文大王·低年级(2016年4期)2016-04-18
