
基于深度主动学习的甲状腺癌病理图像分类方法
2021-01-30 14:00:26尤富生李浩然
南京大学学报(自然科学版) 2021年1期
张 萌 ,韩 冰* ,王 哲 ,尤富生 ,李浩然
(1.西安电子科技大学电子工程学院,西安, 710071;2.空军军医大学基础医学院病理学教研室,西安, 710071;3.空军军医大学生物医学工程系,西安,710071)
甲状腺癌是内分泌系统最常见的恶性肿瘤,也是全球发病率增长最快的恶性肿瘤[1].在众多的甲状腺癌检查方法中[2],病理穿刺活检是当前敏感性和特异性最高的方法[3].在甲状腺癌的四种主要病理类型中,甲状腺乳头状癌约占甲状腺癌的85%以上,虽然甲状腺乳头状癌预后非常好,十年的存活率高达90%左右,但此类癌症的淋巴转移率高达40%~50%[4],因此甲状腺乳头状癌的早期确诊并制订合适的治疗方案对防止病情恶化、挽救病人的生命具有重要意义.
卷积神经网络(Convolutional Neural Networks,CNN)在生物医学图像分析中被广泛应用,然而大部分基于CNN 的图像分析方法是以大量带标注的数据集为基础的.对生物医学图像进行标注不仅繁琐、耗时,而且需要领域内的专业知识指导,这些专业知识需要系统学习,难以迅速掌握,所以很难获取大量带标签的数据.然而,目前已经有公开的其他类型疾病的病理图像数据集,我们可以充分利用现有带标签的其他数据集,辅助挑选有价值的样本进行标注,减少标注代价.
近年来,由于数字数据的爆炸性增长,存储和检索效率极高的哈希编码在各种计算机视觉任务中已被广泛应用.Venkateswara et al[5]使用深度神经网络学习样本的代表性哈希码来解决域适配问题,在无监督域自适应方面取得良好的效果.本文以该深度哈希网络为基础,结合主动学习算法,提出一种基于深度主动学习的甲状腺乳头状癌病理图像分类方法,将深度学习与主动学习集成到同一框架中.该方法通过CNN 来提取图像特征,并利用不确定性信息与代表性信息对未标注数据集中“有价值的”样本进行注释.通过在每一轮迭代中加入新注释的样本对模型进行微调以增强模型的分类性能.在甲状腺癌病理图像数据集上的实验结果表明,和原始的CNN 网络相比,本文提出的基于深度主动学习的甲状腺乳头状癌病理图像分类方法将标注样本数量降低了70%左右.
本文的主要贡献如下:
(1)提出一个新的深度主动学习分类框架对甲状腺癌病理切片进行分类,该方法将深度学习与主动学习集成到一个框架中;
(2)设计了一种样本不确定性评估方法评估未标记样本的不确定性;
(3)设计了一种样本间相似性评估方法,从同一患者样本间相似性以及不同患者的样本间相似性两个角度对样本相似性进行评估;
(4)在甲状腺癌数据库上的实验表明该方法能够有效降低标注代价,仅需标注少量样本便能取得良好的分类效果.
1 相关工作
目前,解决标注问题的方法可以分为两大类:无监督方法和有监督方法.无监督学习能够根据未知类别的训练样本解决分类等问题,然而无监督学习的效果远远比不上监督学习,尤其对于医学图像,准确的分类是十分重要的,关乎后续治疗方案的制订.主动学习(Active Learining,AL)可以很好地平衡这两个问题,在减少标注代价的同时能保证分类准确率,因此众多研究者对主动学习进行了深入研究.在主动学习的早期研究中,主要依赖手工特征进行信息查询与样本选择.Abe and Mamitsuka[6]提出一种查询学习策略,结合委员会查询和装袋查询学习策略,在实际应用中获得了较好的效果.Ebert et al[7]分析不同的采样标准并提出一种基于强化学习的新型反馈驱动的主动学习框架,能够根据经验在学习过程中调整采样策略.Huang et al[8]提出一种基于主动学习的最小-最大观点,为结合样本的信息性和代表性提供了一种系统的方法.Tang and Huang[9]提出一种自定步长的主动学习方法:一方面考虑了信息量和代表性,选取的实例对模型的改进具有较高的潜在价值;另一方面,利用样本的易用性,使模型能够充分利用样本潜在价值.
近年来,由于深度学习的发展,主动学习与深度学习的研究[10-14]逐渐受到越来越多的重视.Wang and Shang[10]可能是第一次将主动学习与深度学习相结合,提出基于堆叠受限玻尔兹曼机和堆叠自动编码器的主动标记方法.Li[11]也将类似的方法应用于高光谱图像分类.Stark et al[12]利用主动学习提高基于CNNs 的验证码识别性能,Al Rahhal et al[13]利用深度学习和主动学习进行心电图分类.Zhou et al[14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015 年MICCAI腺体分割数据集上获得了较好的分割结果.
虽然上述方法在解决样本标注问题上取得了很大进展,但这些方法往往只关注低预测置信度的不确定样本,未能综合考虑样本的不确定性与代表性,同时也没有充分利用CNN 训练过程中得到的特征以及现有的带标签数据库信息.为了克服上述缺陷,结合甲状腺癌病理图像特点,本文提出一种基于深度主动学习的甲状腺乳头状癌病理图像分类方法,充分利用现有的带标签的其他病理切片数据集,能够综合多种信息,同时考虑样本的不确定性与样本的重复性,通过有限数量的标记训练实例实现最优的分类效果.
2 基于深度主动学习的甲状腺癌病理图像分类方法
本文提出的方法主要包括三个部分:(1)深度CNN 框架;(2)样本不确定性评估与相似性评估;(3)样本选择与模型更新.将包含nu个实例的未标记甲状腺癌数据集表示为首先根据未标记样本的不确定性信息和代表性信息从数据集U中选出b个样本,组成集合并对UB进行标记;然后用这些已标记的样本微调分类模型,改善模型的分类效果.
2.1 深度CNN 框架本文的深度CNN 框架包括两个模块,如图1 所示.绿色虚线框内模块用于计算无标签样本的信息熵以及模型参数更新,红色虚线框内模块为特征哈希码提取模块,用于学习辅助数据集中的样本和甲状腺数据集中样本的深度哈希码.选用包含na个带标签的乳腺癌病理图像数据集作为辅助数据,对应的标签为yi∈Y:={1,…,C} .
在特征哈希码提取模块中,使用VGG-f 网络作为特征提取网络,该网络包括五个卷积层、三个全连接层.通过引入哈希编码层将网络学习到的特征转化为二进制哈希码h(x) .将VGG-f 网络输出的样本深度特征记为u(x),将二进制哈希码记作h(x),h(x)=sgn(u(x)).该哈希编码层受到有标签乳腺癌病理图像数据集A的监督哈希损失函数L(HA)以及无监督熵损失函数L(U,A)驱动.有监督的哈希损失函数L(HA)确保乳腺癌病理图像样本生成的特征哈希码的相似性与判别性,也就是说,如果数据集A中的样本xi和样本xj属于同一类别,则它们的哈希码是相似的.无监督熵损失函数L(U,A)根据数据集U产生的哈希码和数据集A产生的哈希码的相似性对这两个数据集中的样本进行对齐,使每个甲状腺病理图像样本与乳腺癌数据集中某个类别的样本相似并且与其他类别的样本不相似.L(HA)定义为:
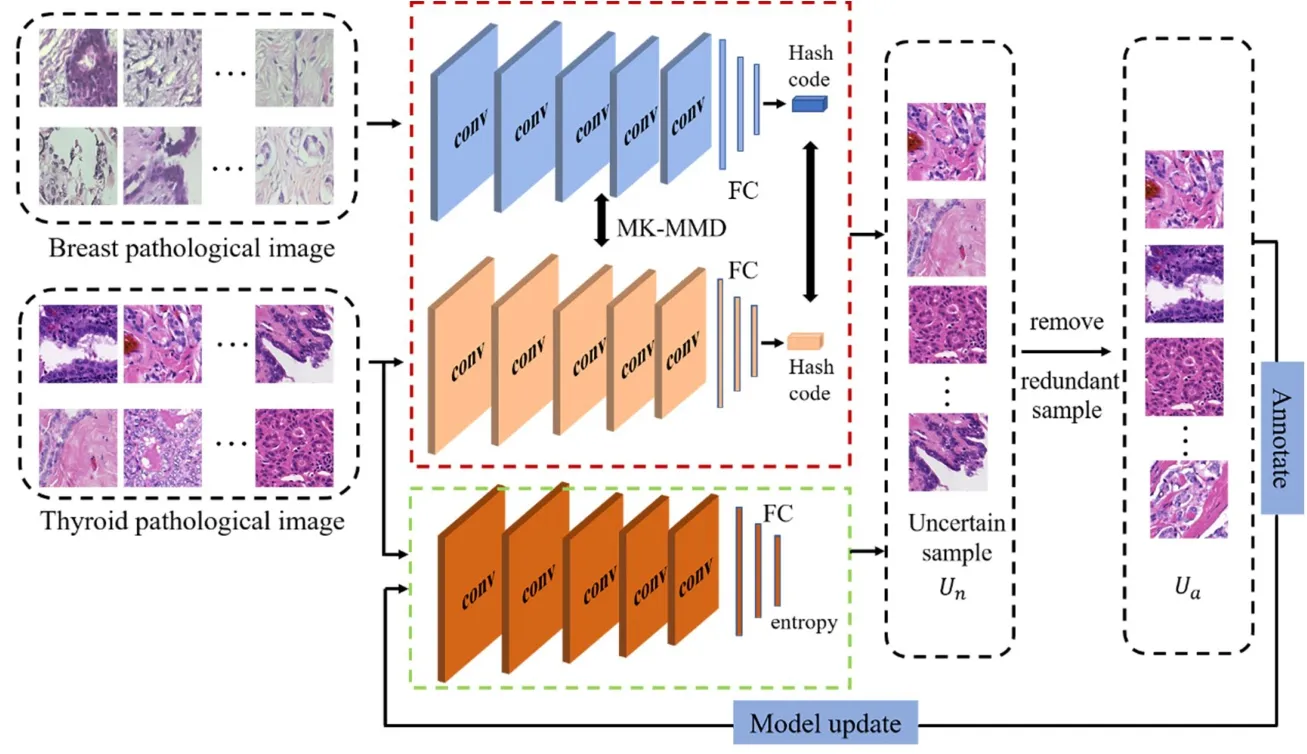
图1 分类方法整体框架图Fig.1 The overall framework of the proposed classification method

其中,sij∈{ 0,1} 表示样本和样本生成的哈希码的相似性.如果样本和样本属于同一类,则sij=1,否则sij=0.无监督熵损失函数L(U,A)表示为:
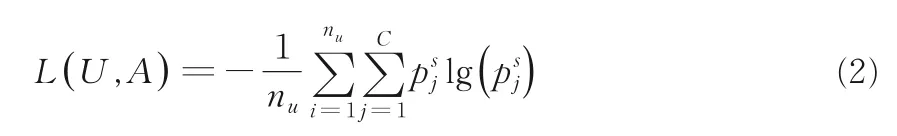
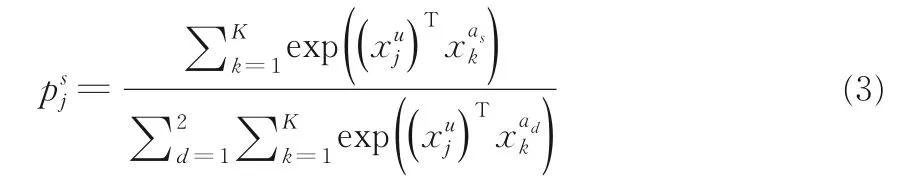
其中,K为类别s的样本数量,s∈{1,…,C},和为数据集A中类别s和类别d的第k个输出值.通过最小化L(U,A),甲状腺癌数据集中的每个样本产生的哈希特征码与某一类乳腺癌病理图像特征哈希码相似,而与其他类不相似.由于本方法是对甲状腺乳头状癌病理图像的二分类,C=2,辅助数据集的类别与甲状腺癌病理切片数据集类别相同.
甲状腺癌病理图像与乳腺癌病理图像虽然都是病理数据,但这两种组织取自人体不同部位,切片制作过程不同,且扫描时使用的扫描仪不同,因此需要减小这两种数据的差异.对于病理图像,细胞核的特征是关键,底层感受野较小的神经元能够学到核的形状及分布等特征,网络的高层特征对分类十分重要,因此对网络的五个卷积层与全连接层进行特征对齐,以减少甲状腺癌病理图像特征与乳腺癌病理图像特征表示之间的域差异.多核最大均值差异(Multi-Kernel Maximum Mean Discrepancy,MK-MMD)在减少域差异方面表现优异.然而现有的减小域差异的模型大多针对自然图像数据,需要对MK-MMD 进行改进.多层MK-MMD 损失函数表示为:
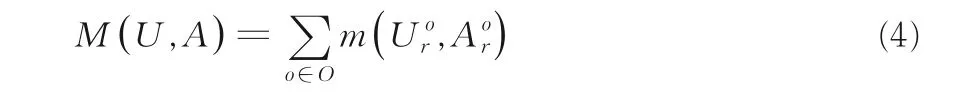
其中,O为五个卷积层与全连接层的索引,和分别代表甲状腺癌病理图像数据和乳腺癌病理图像数据的在第o层的输出.最大平均偏差表示为:
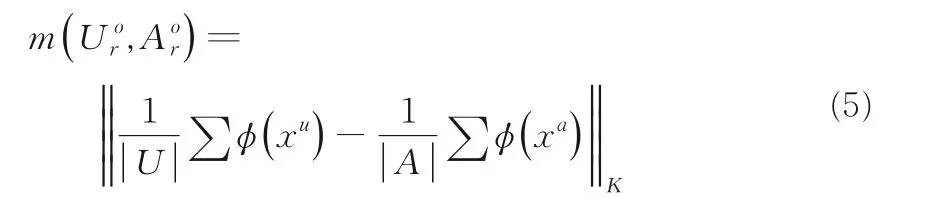
其中,xu和xa分别表示数据集U和A的样本,φ(⋅)表示将数据集U和A的样本映射到一个再生核希尔伯特空间的核函数.K表示k个单一内核的组合:

其中,α∈{0,1}为自适应参数,Lcls为交叉熵分类损失函数.主动学习过程中样本训练的不同阶段,α取值不同.在计算样本的特征哈希码阶段α=0,在样本信息熵计算阶段α=1.β,λ和μ用于平衡各个损失函数的重要性.
样本信息熵计算模块主要用于计算未标注样本信息熵并更新模型.本文采用VGG-f 模型来计算样本的信息熵.为了适应甲状腺癌病理图像数据的类别,用一个二输出的全连接层代替原有的最后一个全连接层.
2.2 不确定性评估与相似性评估在主动学习中,如何选择“有价值”的样本对提升模型的性能十分重要,主动学习的关键在于建立一个判断候选对象“价值量”的标准.本研究通过评估样本的不确定性与样本间的相似性来选择标注样本.较高的不确定性表示样本有较高的信息量,样本间相似性的评估能够辅助去除冗余样本,以更少的标注样本获得最优的分类模型.本方法中样本的不确定性评估准则由两部分组成:特征哈希码的相似性以及样本信息熵.特征哈希码的相似性定义为:在获取甲状腺癌病理图像数据集与乳腺癌病理图像数据集的样本特征哈希码后,甲状腺癌数据集U中的样本的特征哈希码应与某一类别乳腺癌病理图像生成的特征哈希码相似,而与其他类别乳腺癌病理图像特征哈希码有较大差异,即样本的特征哈希码分配到某一类别的概率接近1,而分配到其他类别的概率接近0.由于甲状腺乳头状癌病理图像分类为二分类,则分配到两个类别的概率差值越小,表示样本的不确定性越大.
未标记样本的信息熵也是不确定性评价的重要指标,信息熵表示数据集U中样本提供的信息量,因此不确定样本的选择综合考虑了样本熵以及哈希特征码的相似性.选择不确定性样本的指标如下:
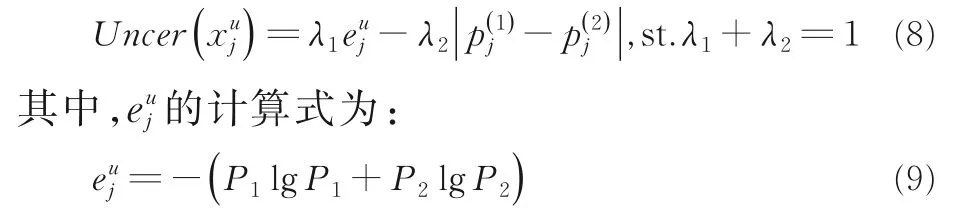
P1和P2分别为信息熵计算模块中未标记样本被分类为正常图像和PTC 的概率.
直接进行图像的相似度计算十分复杂,然而通过CNN 学到的深度特征能够很好地表征图像,因此可以将图像深度特征向量之间的相似度作为图像间的相似度.取分类网络最后一个卷积层的多个特征图均值作为样本的特征向量在本方法中,VGG-f 网络最后一个卷积层输出特征图的尺寸为6×6×256,即有256 个特征图,每个特征图大小为6×6.为了减小计算量,以每个特征图的均值代表该特征图,最终得到一个尺寸为1×256 的特征向量.最后,使用余弦相似度来计算特征向量的相似性.即数据集U中的两个样本的相似性可以表示为:
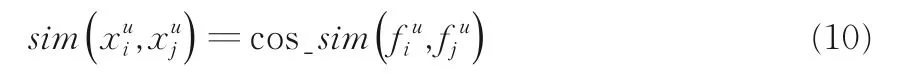
2.3 样本选择与模型更新注释样本的选择综合考虑样本的不确定性以及代表性.首先从未标注甲状腺癌数据集U中选出不确定性较高的样本集合Un,然后评估集合Un中样本间的相似性并去除冗余样本,从Un中选择有代表性的样本集合UB并进行标注.
在待标注样本选择阶段,目标是根据预先设定的标注数量选出同时具有不确定性和代表性的样本集合UB并进行标记,进一步进行模型更新,改善模型的分类效果.首先根据式(8)计算样本的不确定性,选取不确定性得分最高的b个图像组成不确定性样本集合Un;然后从同一患者样本相似性评估以及患者间样本相似性评估两个角度评估样本的相似性,选出代表性样本构成集合UB,如图2 所示.
在初始阶段,由于不同数据集之间样本哈希码相似性概率的获取不需要样本标签,因此能够直接对特征哈希码提取模块进行训练.对于熵的计算,随机选择少量训练样本进行标注,然后使用标注的数据微调预训练VGG-f 模型,并使用微调后的模型计算样本信息熵.主动学习是一个不断循环的学习过程,在训练过程中,特征哈希码提取模块和样本信息熵计算模块交替进行训练.当特征哈希码提取模块进行训练时,α设置为0,此时得到样本哈希码的相似性.当样本信息熵计算模块进行训练时,α设置为1,β,λ,μ设置为0,获取样本信息熵.

图2 相似性样本评估示意图Fig.2 The framework of similarity estimation
随着训练的进行,新标记的样本被合并到UB中,并使用UB不断微调CNN 网络.一些研究[5,17]已经证明,对模型进行微调和使用标注样本从头开始训练模型相比,可以获得更好的性能.因此,在我们的实验中,当新标注的样本合并到数据集UB时,使用新标记的数据对CNN 进行微调,以不断更新模型参数,改善模型的分类性能.
3 实验结果与分析
本文建立了甲状腺病理图像数据集以证明该方法的有效性.收集西京医院2017 年至2018 年的55 例甲状腺乳头癌的病理图像,构建的数据集包括7928 例正常病理图像和8572 例PTC 病理图像,均由江丰生物信息技术有限公司的KF-PRO-005 扫描仪扫描.将数据集在患者级别随机分为训练、验证和测试数据集,并使用30%的数据集作为测试数据集.
本文构建了三组实验并使用甲状腺癌病理图像数据库对该方法进行验证.算法通过深度学习工具箱MatConvNet[18]实现,运行的软件环境为64 位Ubuntu14.04 系统,MatlabR2014b,Matconvnet 深度学习工具包.
3.1 特征哈希码维度对分类效果的影响待标注样本选择的主要依据为样本的不确定性,不确定性信息评估准则包括样本特征哈希码的相似性与样本信息熵.其中,哈希码的维度对不确定性样本的选择有一定影响,并影响模型的分类性能.为了验证特征哈希码维度对模型分类效果的影响,本实验将哈希码维度设置为16,32,64 和128 bits,实验结果如图3 所示.
可以看出,当哈希码维度为16 bits 时分类准确率略低,主要是因为当哈希码的维度较低时,信息表征的准确性受到影响,使分类准确率略微下降.当哈希码的维度设置为32 和64 bits 时,性能略微提升;当哈希码维度增加为128 bits 时,分类准确率却没有明显变化,说明64 位哈希码已能较准确地表征病理图像信息.哈希码维度在64 bits的基础上再增加,对病理图像的特征表示没有更多贡献,因此将哈希码的维度设置为64 bits.
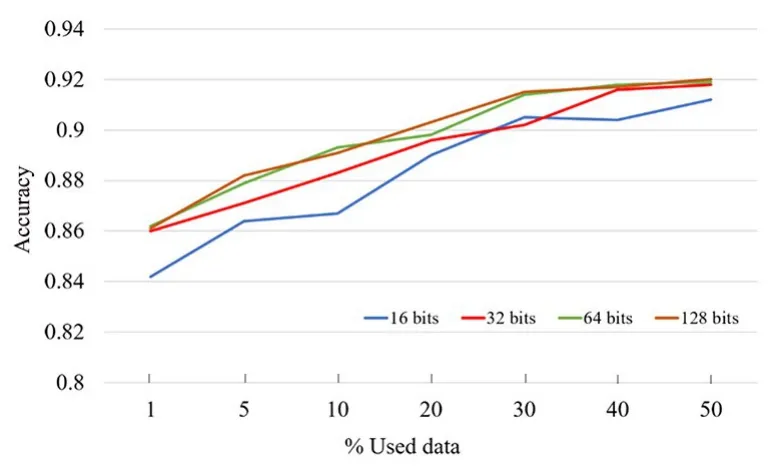
图3 不同哈希码维度分类准确率的对比Fig.3 Classification accuracy with different hash length
3.2 λ1 与λ2 比值对分类效果的影响前文已经说明样本不确定性度量准则包括样本的特征哈希码相似性与样本信息熵两个部分,为探究这两者比重对样本挑选的影响,构建以下实验来确定不确定信息计算(式(8))中比例系数λ1与λ2的取值对病理图像分类准确率的影响,实验结果如表1所示,其中黑体字表示最好的分类结果.可以看出,当仅使用特征哈希码相似性与样本信息熵选择不确定性样本时模型分类准确率较低,且需标注40%~50%的数据才能达到90%的分类准确率.而两者联合进行不确定性样本选择时,挑选出来的样本对模型的贡献率较高,仅需标注20%~30%的样本便可以达到90%的分类准确率,λ1∶λ2=1∶9 时模型的分类性能最好.
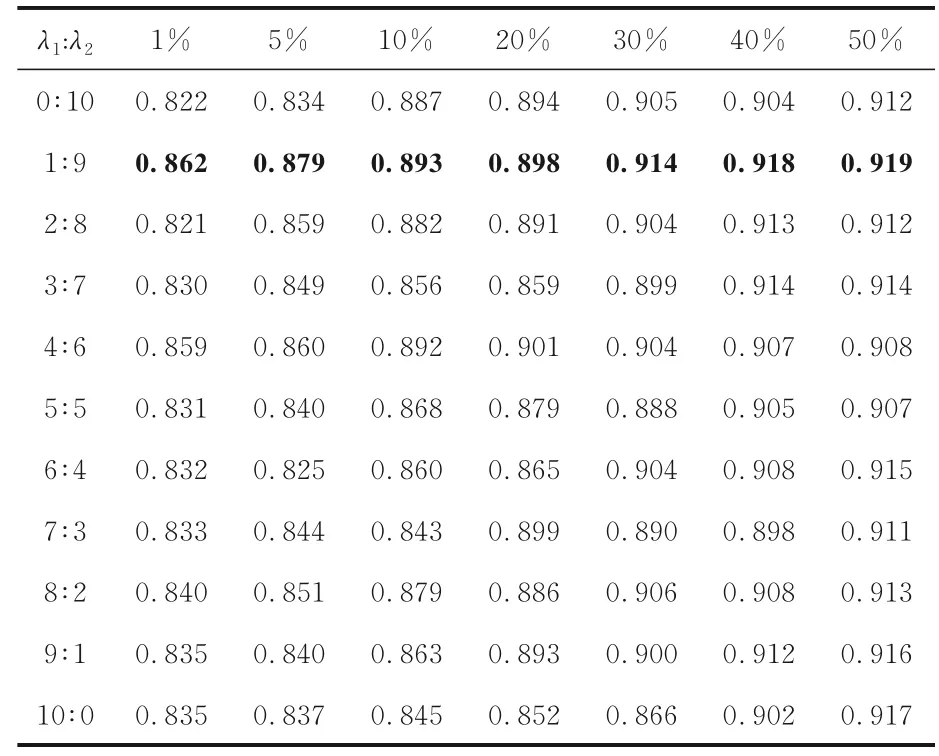
表1 不同标注比例的分类结果(λ1∶λ2)Table 1 Classification results with different ratio for λ1:λ2
3.3 不同标注比例分类结果对比实验为了验证本文算法在不同标注比例数据上的有效性,将其与现有的几种基于主动学习的分类方法进行了对比,共对比了Uncertainty[19],QBC[6],GD[7],QUIRE[8],SPAL[9]以及Random 六种方法.
由于本文算法的目的是使用尽可能少的标注成本获取能准确进行甲状腺癌病理图像分类的模型,因此主要对不同比例的标注图像的分类准确率进行比较.实验结果如表2 所示,其中黑体字表示最好的分类结果.Random 方法表示在未标记池中随机选取样本进行标注的方法.为确保实验的公平性,基于主动学习的对比方法使用的样本特征与本文方法使用的样本特征相同,即VGG-f 网络提取的深度特征.同时,初始标记样本数均设置为训练样本总数的0.5%.
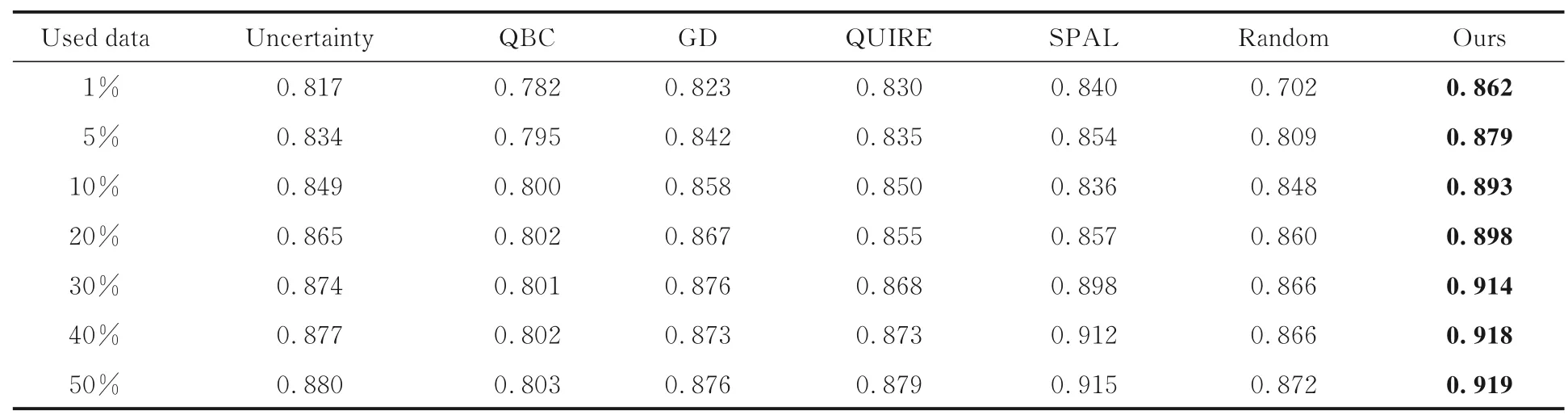
表2 不同方法分类结果Table 2 Classification results of different methods
可以看出,当标注数据量占总数据量的1%,5%,10%,20%,30%,40%及50%时,与其他方法相比,本文方法的分类准确率最高,且仅需标注不到30%的数据,就可获得90%的分类准确率.
此外,还将本文方法与原始的VGG-f 网络的分类效果进行对比,如图4 所示.可以看出,本文方法仅需标注30%的样本,便超过原始VGG-f 网络使用全部数据时的分类准确率,能够节约70%左右的标注成本.
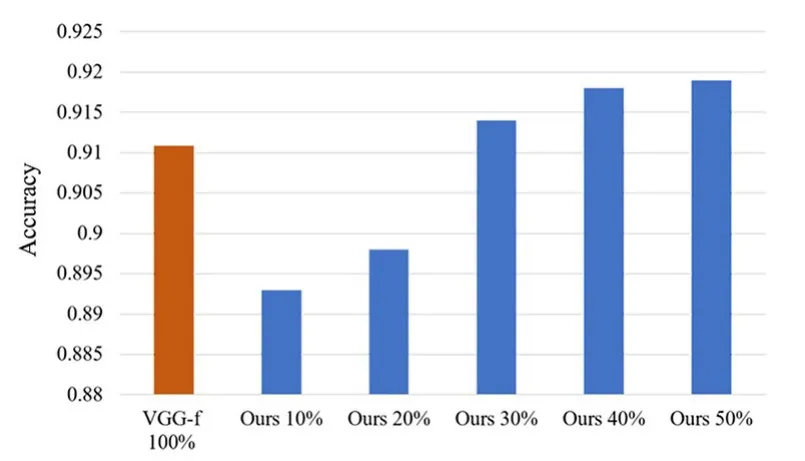
图4 VGG-f 与本文方法分类性能对比Fig.4 Performance of VGG-f and our method
4 结论
本文提出一种基于深度主动学习的甲状腺癌病理图像分类方法,能有效减少标注代价.该方法针对病理图像标注困难的问题,将深度学习与主动学习集成到一个框架中,无须标注所有的训练数据,只需选择对模型“有价值的”样本并进行标注,使用较少的标注数据便能提高模型的分类性能.
所提出的方法首先利用样本特征哈希码相似性与样本信息熵挑选不确定样本,然后进一步评估不确定性样本间的相似性,并去除冗余样本.最后对选择的样本进行标注并使用标注的数据更新模型参数,提升模型的分类性能.在甲状腺病理图像数据集上的实验结果表明,所提出方法能够有效降低标注代价.
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
国际放射医学核医学杂志(2021年10期)2021-02-28 08:43:46
国际放射医学核医学杂志(2021年10期)2021-02-28 08:43:24
河北画报(2020年8期)2020-10-27 02:54:20
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
工业设计(2016年8期)2016-04-16 02:43:34
中国卫生标准管理(2015年2期)2016-01-15 00:31:34
计算机工程(2015年8期)2015-07-03 12:20:04
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年12期)2014-02-27 11:58:03
