
小样本条件下基于卷积孪生网络的变压器故障诊断
2021-01-29 12:45朱瑞金郝东光胡石峰
电力系统及其自动化学报 2021年1期
朱瑞金,郝东光,胡石峰
(1.西藏农牧学院电气工程学院,林芝 860000;2.国网西藏电力有限公司,林芝 860100)
变压器是发电厂和变电所的主要设备之一。变压器的运行状态关系到整个电力系统的稳定性,倘若其发生故障会引发局部或者大面积停电,造成巨大的经济损失。因此,对变压器故障做出准确地及时诊断对于电力系统的安全运行具有重要意义[1]。
变压器故障诊断主要包括特征提取和模式识别两个步骤。特征提取的质量对于分类准确率有着至关重要的作用,已有的方法主要包括三比值法、Rogers比值法、大卫三角形法及Dornenburg比值法[2-3]。这些方法是以溶解气体分析DGA(dis⁃solved gas analysis)为基础,通过四则运算构建人工特征,具有方法简单、容易实现的特点,因而在实际应用中发挥了重要的作用。然而,这些方法需要依靠专家经验选择特征,特征提取的过程没有统一的理论依据,总结的特征个数有限,不具有普适性。模式识别指的是对提取的特征进行分析以诊断出变压器的故障类型。传统的方法主要包括支持向量机SVM(support vector machine)、贝叶斯网络、k近邻、模糊集理论、多层感知机MLP(multi-layer per⁃ceptron)和XGBoost算法[4-7]。其中:SVM处理小样本数据集的速度较快,但由于它的本质是一个二分类器,对于变压器故障诊断这种多分类问题,它的准确率不高;贝叶斯网络在使用时需要预先设定先验概率,可能会由于假设的先验概率不够准确而导致分类的效果不好;MLP虽然有着较强的学习能力,但它容易出现过拟合现象,而且特征提取能力有限;XGBoost是一种常用的集成学习方法,通过训练多个分类器提高分类的准确率,但它的参数太多,存在着调参困难的缺陷。总的来说,虽然这些传统方法适用于小样本数据集的变压器故障诊断,但各个方法的特征提取能力不足、分类的准确率有待提升。
近年来,深度学习发展迅猛,在国内外都引起了广泛的关注,也给变压器故障诊断带来了新的研究思路[8]。已有的基于深度学习的变压器故障诊断方法主要包括自动编码器、深度信念网络和深度卷积网络[9-11]。尽管这些深度神经网络相对于传统模式识别的方法具有更高的诊断准确率,但它们都需要海量的样本来训练网络,对于小样本数据集难以奏效。特别的,卷积孪生网络CSNN(convolutional Siamese neural network)是一种基于相似性度量的方法,可以对少量标签样本进行有效的学习,从而获得对未知样本的判别能力[12]。目前,CSNN在人脸匹配、签名验证、语义相似度分析及视觉跟踪等领域得到了广泛地应用,但在电力系统故障诊断中的应用还相对较少[13-14]。如何根据变压器的溶解气体数据特征设计出一种具有强大特征提取能力和较高诊断准确率的网络结构有待进一步的研究。
针对已有的变压器故障诊断方法对于小样本数据集的准确率不高的问题,提出了一种小样本条件下基于CSNN的变压器故障诊断方法,所提方法的主要优势在于:
(1)在特征提取环节,具有强大特征提取能力的卷积层和池化层被用来构建孪生网络将原始数据映射到低维空间,不仅可以实现特征的自动提取,还能避免人工提取特征的主观和繁琐;
(2)在模式识别环节,不同于已有的深度学习方法都需要训练一个分类器(比如,SoftMax),所提的CSNN是在低维空间基于欧式距离进行相似度的对比,从而实现故障的分类,这给基于深度学习的故障诊断提供了新的研究思路;
(3)所提方法只需要通过少量标签样本就能获取到多种故障类型的共通特征,并用于预测未知样本的故障类型。在小样本条件下,所提方法相对于已有方法具有更高的准确率。
1 基于CSNN的变压器故障诊断方法
1.1 CSNN的原理
传统的分类方法(比如SVM)需要确切的知道每个样本属于哪个类型。在类型的数量过多,每个类型的样本数量又相对较少的情况下,这些方法的准确率会大打折扣。出现这种现象的原因是对于整个数据集来说,每个类型的样本数量太少,用传统的分类方法难以训练出好的分类器。为了解决小样本数据集的分类问题,有学者提出了基于相似性度量的CSNN。从数据中去学习一个相似性度量,并用这个学习出来的度量去比较和匹配新的未知类别的样本[15]。
CSNN的结构如图1所示,CSNN的训练和预测过程都需要成对的变压器故障样本(归一化后的溶解气体特征序列)作为输入,通过相同权重的神经网络将输入数据映射到低维空间,在低维空间使用简单的距离(比如欧式距离)进行相似度的对比。在训练阶段,CSNN的目标是去最小化来自相同类型的一对变压器故障样本的损失函数值,并最大化来自不同类型的一对变压器故障样本的损失函数值。一般的,卷积网络的输出值是GW(X),其中W是神经网络的权重参数,X是输入的样本数据。训练的目标就是优化权重W使得当X1和X2属于不同一个故障类型的时候,相似度是一个较大的值,X1和X2属于同一个故障类型的时候,相似度是一个较小的值。
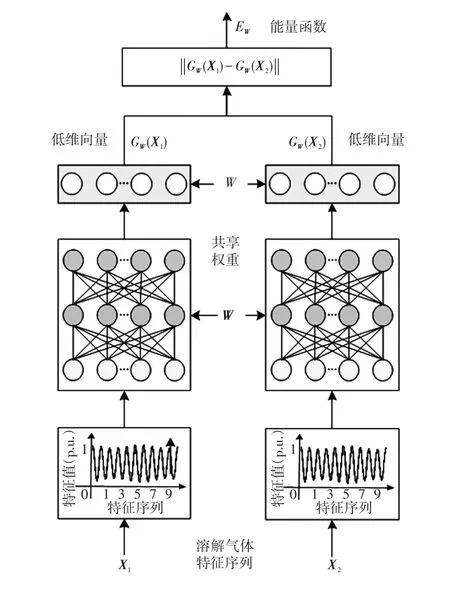
图1CSNN的结构Fig.1 Structure of Siamese network
从图1可以看出,左右两边的网络是完全相同的网络结构,它们共享相同的权重W,输入数据为一对变压器故障样本(X1,X2,Y),其中Y=0表示X1和X2属于同一个故障类型,Y=1则表示不是同一个故障类型。针对两个变压器故障样本X1和X2,分别映射到低维空间GW(X1)和GW(X2)。得到的这两个输出结果将被用于计算能量函数EW(X1,X2),若能量函数小于阈值,则认为输入的两个样本属于同类故障。能量函数的表达式为
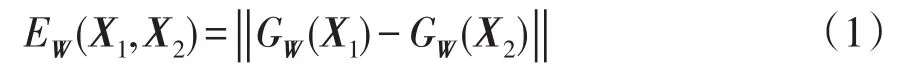
对比损失(contrastive loss)函数和输入样本、参数有关,它的形式为
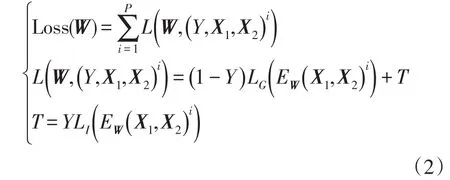
式中:P为输入的总样本数;i为当前样本的下标;LG为两个样本为同类型时的损失函数;LI为两个样本为不同故障类型时的损失函数;Y为X1和X2是否属于同一类故障。通过这样分开设计,可以使得最小化损失函数的时候,可以减少相同类型故障样本对的能量,增加不同类型故障样本对的能量。为了实现这种效果,只需要将LG设计成单调增加,让LI单调递减即可。根据文献[12],设计单个故障样本的损失函数为
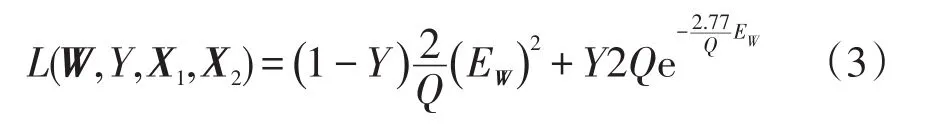
式中,Q为一个常量,这个损失函数的收敛证明见文献[12]。
1.2 CSNN的结构
由于卷积神经网络CNN(convolutional neural network)具有强大的特征提取能力,在图像识别、稳定性评估和模式识别等领域得到了广泛地应用[16]。因此,卷积神经网络被用来构建孪生网络将溶解气体数据映射到低维空间。
卷积神经网络主要由卷积层、池化层及全连接层FC(fully-connected layers)组成。卷积层的主要操作是对上一层的输出数据进行卷积运算,并加上偏置向量作为下一层的输入数据,其表达式为

式中:yi为第i层的输出数据;fi为第i层的激活函数(这里取线性整流函数ReLU);xi为第i层的输入数据;wi为第i层卷积核的权重;bi为第i层卷积核的偏置向量;*为卷积运算符号。
采样层对卷积层输出的数据进行下采样操作,只保留关键的特征以降低数据的维度。如图2所示,池化方式有最大池化和平均池化,其数学表达式为

式中:R为池化的区域;为最大池化层输出的数据;为平均池化层输出的数据。
池化层的后面一般是平坦层,将池化层输出的多维数据转变成一维向量作为全连接层的输入数据。全连接层输出的就是低维空间的数据,将被用于计算相似度。其表达式如下:

对于小样本数据集,训练的神经网络容易出现过拟合现象。为了缓解这个问题,在卷积层后面插入“Dropout”层。它的作用是以一定的概率让神经元停止工作,有利于提高模型的泛化能力。
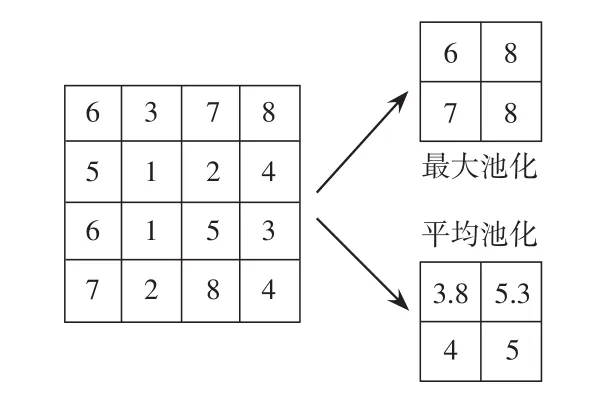
图2 不同的池化方式Fig.2 Different pooling modes
1.3 CSNN的流程
基于CSNN的变压器故障诊断过程主要包括4个步骤,如图3所示。
(1)特征的选择。变压器在正常运行时,固体绝缘和绝缘油都会被分解并释放出微量的气体,主要包括乙炔C2H2、乙烷C2H6、甲烷CH4、氢气H2、乙烯C2H4、二氧化碳CO2和一氧化碳CO。当变压器发生绝缘受潮湿、低能发电和高温过热等异常现象时,这些气体含量会迅速地剧增,大部分溶解在绝缘油中,少部分会上升到绝缘油的表面进入继电器。通过溶解气体分析可以为变压器的故障诊断提供重要依据。因此,本文以溶解气体H2、CH4、C2H6、C2H4和C2H2的含量作为原始特征,再加上Rogers比值法构建的4个特征[10],一共9个特征,作为CSNN的输入。
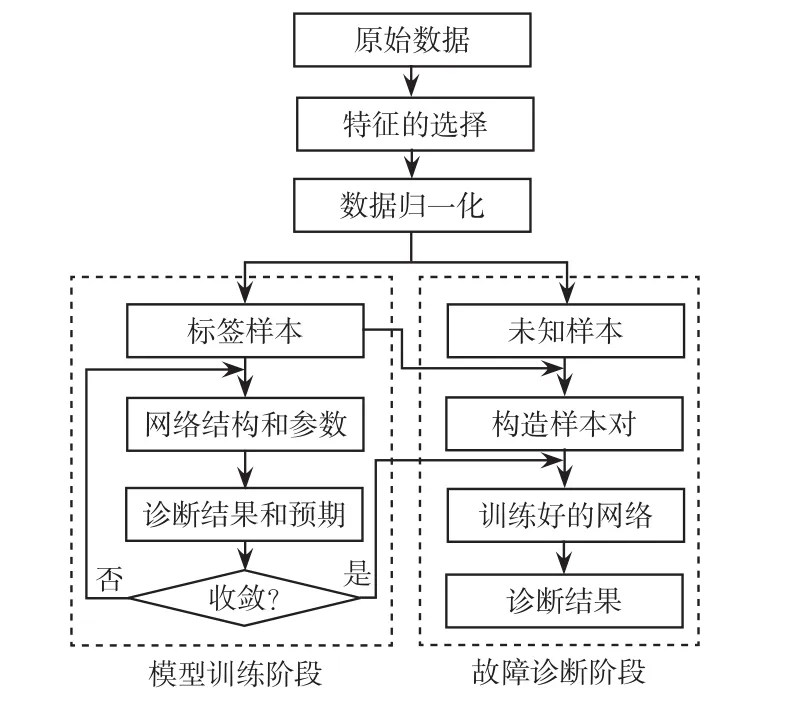
图3 变压器故障诊断的流程Fig.3 Flow chart of transformer fault diagnosis
(2)数据预处理。考虑到各个特征的单位和数量级不一样,如果不对原始特征进行归一化,在后续的模型训练过程中可能会出现准确率低或者难以收敛的现象。因此,在把数据作为CSNN的输入前,将其映射到[0,1]区间,其数学表达式为
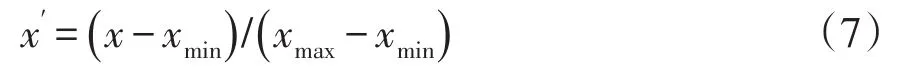
式中:x、x′分别为归一化前、后的数据;xmin、xmax分别为该特征的最小值和最大值。
(3)CSNN的训练。在模型的训练阶段,初始化CSNN的结构和参数,将标签样本以成对的形式输入到模型中。通过前向传播,计算出模型输出数据和预期目标的误差。判断模型是否收敛,若收敛则训练结束,输出训练好的CSNN用于诊断未知样本的故障类型。否则,利用误差反向更新网络的权值和阈值。
(4)未知样本的故障诊断。在故障诊断阶段,将未知样本和每一个标签样本组成样本对。将样本对作为CSNN的输入数据,若这个样本对的欧式距离小于阈值,则认为它们是同类。统计这个未知样本属于每一类故障的概率,将这个样本归到概率最高的那一类中。
2 算例分析
为了说明CSNN诊断变压器故障的有效性,采用衡水市和上海市供电公司的实际数据集进行仿真验证[17]。经过清洗后,数据集包括535个样本,一共9种状态分别是正常、低能放电、高能放电、高温高热、低温过热、中温过热、局部放电、高能放电兼过热及低能放电兼过热。训练集占总样本个数的60%,验证集和测试集各占20%。训练集和验证集用来训练CSNN,测试集用来分析CSNN的性能。所有方法均在带有TensorFlow的Spyder平台下运行。通过对CSNN的结构和参数进行多次试探,最优模型如图4所示。CSNN的输入样本是一对维度是1×9的溶解气体特征序列。通过Python自带的Reshape函数将向量重构成3×3的矩阵作为卷积层的输入。经过多个卷积层、池化层和全连接层的处理后,输出1×8的向量用于这对样本的计算欧式距离。模型细节如下:两个卷积层的卷积核个数依次是16和36,卷积核大小都是2×2;最大池化层的池化窗口大小是2×2。卷积层和池化层的激活函数都是ReLU;在两个卷积层后面插入一个Dropout层以缓解过拟合,Dropout层的概率设置为0.2;全连接层的神经元个数是8,激活函数是ReLU。
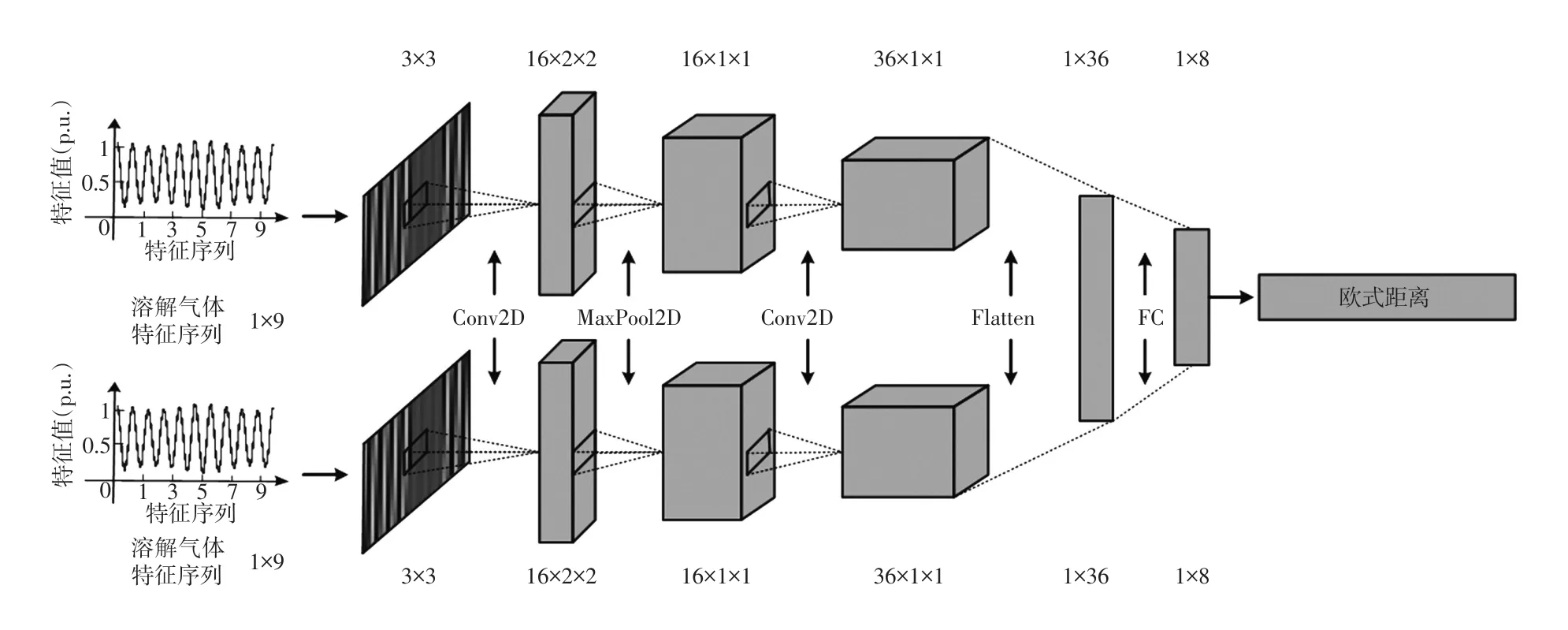
图4 卷积CSNN的结构Fig.4 Structure of convolutional Siamese network
为了分析CSNN的训练状态是否稳定,图5展示了损失函数随着迭代次数增加的变化情况。
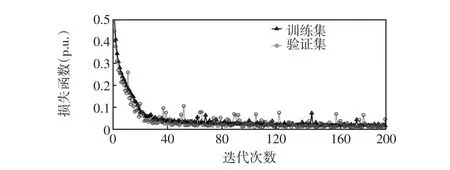
图5CSNN的训练过程Fig.5 Training process of Siamese network
显而易见,验证集和训练集的损失函数随着迭代次数的增加而减小。当迭代次数大于80时,CSNN的损失函数趋于平稳不再继续下降,这表明该网络已经收敛。此外,对比训练集和验证集的损失函数发现它们的损失函数非常接近,这说明网络的泛化能力较强,没有出现过拟合现象。
为了分析CSNN的批尺寸(Batch size)对于分类准确率的影响,分别设置批尺寸为5、10、20、40、60、80、100和120,统计出测试集的准确率如图6所示。
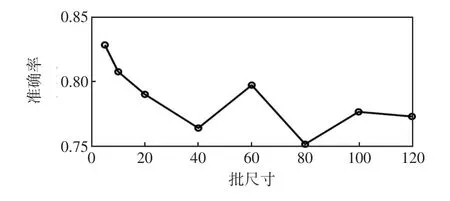
图6 不同批尺寸的准确率Fig.6 Accuracy with different batch sizes
为了分析CSNN的阈值对于分类准确率的影响,分别设置不同阈值,统计测试集的准确率如图7所示。
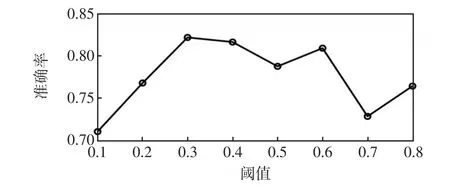
图7 不同阈值的准确率Fig.7 Accuracy with different thresholds
由图7可知:(1)当阈值比较小的时候,被CSNN判定成和未知样本同类的已知样本个数会很少。若阈值足够小,这个未知样本会被归到和它距离最近的那个样本所属的故障类型中。从仿真结果来看,阈值较小时,准确率不高;(2)相对的,如果阈值很大,被CSNN判定成和未知样本同类的已知样本个数会很多。这个未知样本很有可能会被归到拥有最多样本的故障类型中,此时的准确率很有限。当阈值设定0.3的时候,模型的分类准确率达到最高。
为了验证所提方法的有效性,分别统计CSNN、基于全连接层的孪生网络FSNN(fully connected neural Siamese network)、SVM、XGBoost、MLP及CNN在不同输入特征下,对于测试集的准确率如表1所示。

表1 不同方法的准确率Tab.1 Accuracy of different methods%
由表1可知:(1)根据输入特征的不同,变压器故障的诊断准确率按IEC比值法、Rogers比值法和本文的特征依次提升,这说明这些比值法虽然在包含了原始数据大部分信息的前提下,在一定程度上减小了输入特征的维度,但也损失了部分准确率;(2)相对于SVM、XGBoost、MLP和CNN而言,孪生网络有着更高的分类准确率。进一步对比两个孪生网络的准确率,发现利用卷积层和池化层来构建孪生网络比仅用全连接层构建来孪生网络会收获更高的准确率,这是因为卷积层比全连接层具有更强大的特征提取能力。
为了进一步测试本文所提CSNN、FSNN、SVM、XGBoost、MLP和CNN在不同数据量下的分类准确率,设置了4种仿真场景,如表2所示。4种仿真场景统计出测试集的准确率如表3所示。
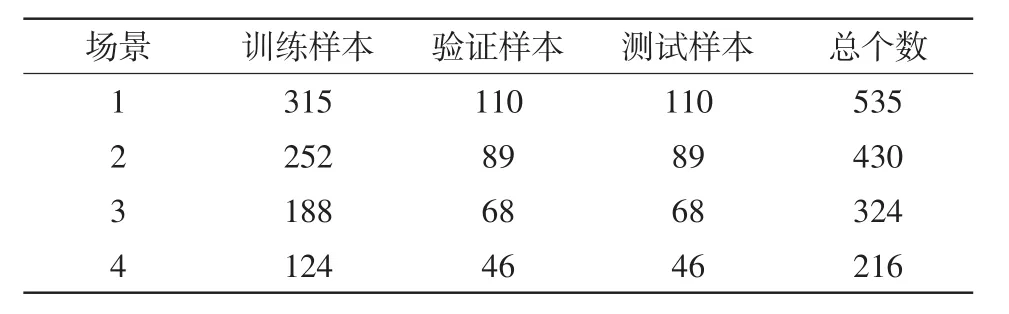
表2 不同场景的样本个数Tab.2 Numbers of samples in different scenarios
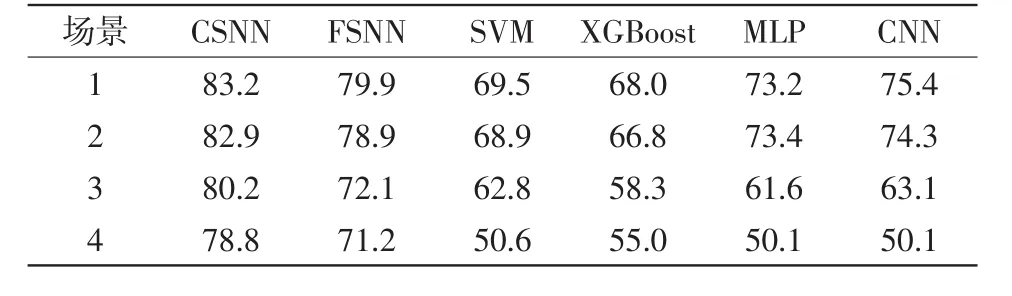
表3 不同场景的准确率Tab.3 Accuracy in different scenarios%
由表2和表3可知:(1)随着数据集中样本个数的增加,各个模型能够学习到更多的信息,分类准确率也就越高。相对而言,CSNN的准确率比其他方法的准确率都高,而且数据量越小越明显,这说明CSNN比其他方法更适合小样本条件下的变压器故障诊断;(2)CNN和CSNN都是先利用卷积层和池化层来提取特征,不同的是前者在特征后面接分类器(比如Softmax),后者是利用欧式距离进行相似度对比。CSNN比CNN的准确率高,这表明相似度对比法比训练分类器法更加适合小样本条件下的变压器故障诊断。
3 结论
针对已有的变压器故障诊断方法对于小样本数据集的准确率不高的问题,本文提出了一种小样本条件下基于CSNN的变压器故障诊断方法。卷积层和池化层被用来构建孪生网络将原始数据映射到低维空间,并通过欧式距离对比相似度,从而实现故障的分类。通过仿真得出的结论如下。
(1)相比于SVM、XGBoost、MLP和CNN,所提出的CSNN在不同输入特征的场景下均得到了更高的诊断准确率。此外,利用卷积层和池化层来构建孪生网络比仅用全连接层构建来孪生网络会得到更高的准确率。
(2)CSNN相对比SVM、XGBoost、MLP和CNN,更加适合小样本条件下的变压器故障诊断。
(3)通过对比CSNN和CNN的准确率,发现相似度对比法比训练分类器法更加适合小样本条件下的变压器故障诊断。
猜你喜欢
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
电视技术(2014年19期)2014-03-11
