
基于改进K-means算法的电子商务客户细分研究
2021-01-28 16:14靖立峥吴增源
中国计量大学学报 2020年4期
靖立峥,吴增源
(中国计量大学 经济与管理学院,浙江 杭州 310018)
凭借方便快捷、低成本、不受时空限制等优势,全球电子商务蓬勃发展。今年上半年,在新冠疫情防控期间,电子商务在保障社会基本生产、生活物资供应和拉动经济增长方面起到了重要作用。良好的客户关系管理是电商平台构建竞争优势的重要一环[1-2]。百雀羚广告《一九三一》的低转化率以及频频爆出的直播带货失败案例表明,高效的客户关系管理必须以客户细分为基础[3-4]。客户细分是指利用统计分析或数据挖掘等技术分析客户数据,对客户进行分类,以提供有针对性、个性化的服务,从而提高营销效率[5]。只有深入了解不同客户群体的偏好和需求,才能实施精准营销。
在电子商务客户细分研究领域,基于机器学习的聚类分析技术是目前较常使用的方法之一。该方法以经典的RFM模型[5]为基础,利用多维度指标,精准体现不同客户群体的消费行为和习惯。但是,现有研究侧重于使用客户的历史订单数据,无法全面反应不同客户群体的行为偏好和消费习惯。另外,经典的K-means算法存在人为设定K值的缺陷。因此,在特征选择过程中,本文增加了客户消费行为数据:客户消费间隔(recency,R)、消费次数(frequency,F)、浏览(details page of product,P)、加购(add to cart,A),以及收藏次数(favourite,V);在算法改进方面,引入Calinski-Harabasz(CH)聚类质量评价指标,优化K值选取。实验结果表明:使用CH聚类评价质量指标优化传统K-means算法,能有效提高电子商务客户细分的效率和准确性。
1 文献回顾
很多学者从不同的角度提出了客户细分方法[6],这些方法依据选取的客户指标的不同主要分为三类:基于人口统计的视角、基于客户生命周期的视角和基于客户行为的视角。基于人口统计[7]视角的客户细分方法主要采用问卷调查的手段,以客户年龄、性别、家庭收入、婚姻状况教育程度等为基础划分成不同的群体。但是这种单纯地利用人口统计指标细分客户的方法不能预测客户的未来购买行为[8],也不能对客户流失的原因做出精准的分析,企业难以采取具体的针对性措施去吸引客户、保持客户。基于客户生命周期视角[9]的客户细分方法的具体过程是:企业利用新增、留存、流失的客户数量信息,绘制客户生命周期分布曲线。根据客户所处的生命周期的不同阶段,对其采取不同的措施。客户忠诚度分类方法[10-11]是现有基于客户生命周期的细分研究中最常用的细分方法。Christopher & Payne(2008)根据客户所处的生命周期的不同阶段分为潜在顾客、现实买主、长期客户、支持者和鼓吹者[12]。但是这种细分方法无法体现客户价值特征之间的差异,以及客户的偏好特征和行为特征的差异。近年来,随着数据挖掘技术的不断发展,基于客户行为的客户细分方法逐渐成为研究热点。这类细分方法主要采用的是基于机器学习的聚类分析技术,利用多维度指标,精准体现不同客户群体的消费行为和习惯[13]。在这种方法中,作为经典的客户价值模型-RFM模型已经成功应用于不同行业的客户细分[14-15]。但是,RFM模型中的F、M指标会存在多重共线性的问题[16]。由于以上模型的缺陷,不同行业的研究学者根据行业特点对其进行了改进和扩展[17-19]。Serhat Peker(2017)针对杂货店的客户,利用K-means聚类算法,提出了基于LRFMP的客户细分模型,但是仍没有解决F和M之间的多重共线性的问题[13]。任春华等(2019),针对汽车销售行业的特点,提出了汽车忠诚客户的LRFAT模型。该模型可以消除F值与M值的共线性问题,并且能识别出忠诚客户[16]。虽然引入客户行为特征数据之后,电子商务客户细分研究取得了一定的研究成果,但是仍有以下两个问题没有得到解决:一是对于客户细分模型指标的选取,现有研究侧重于使用客户的历史订单数据,但是忽略了客户的线上行为数据,无法更加全面的反映不同客户群客户的行为偏好和消费习惯;二是经典的K-means算法虽然原理简单,易于实现,但存在人为设定K值的缺陷。由于每个行业客户的结构分布不同,人为设定K值,很有可能造成细分结果与实际有较大差异。因此,在特征选择上,本文构建了融入客户线上行为特征的RFPAV客户细分模型;在算法上,本文借助K-means算法进行聚类分析的基础上,引入CH聚类质量评价指标,以期实现更优的聚类效果。
2 基于改进K-means的电子商务客户细分方法
2.1 客户细分指标选取
RFM模型最早由Hughes(1994)[20]提出,一般用来衡量客户的价值特征,识别高价值客户。自提出以来,RFM模型已经广泛应用于客户细分,R(recency)通常代表客户最近一次消费据观察期截止日期的消费间隔,R值越大代表客户据上一次消费的日时间越长,客户价值越低;F(frequency)通常代表观察期内的消费的次数,F值越大代表客户消费越频繁,客户价值越高;M(monetary)通常代表客户在观察期内消费的总金额,M值越大,客户价值越高。
虽然传统RFM模型已广泛应用于各个行业的客户细分问题,但是仍存在两个问题:第一,RFM模型中的F和M指标存在多重共线的问题;第二,使用RFM模型进行客户细分,不能体现客户在该电商平台的活跃度,以及不同客户群之间消费和行为习惯的差异。随着大数据技术的提升,从电商平台提取的客户信息数据的维度增多,这些数据更加细致全面的反映了客户的价值特征、消费习惯以及行为偏好,因此,基于传统RFM模型,本文融入了客户的线上行为指标,提出了针对电子商务客户细分的RFPAV模型,其中,P、A、V指标可以体现客户的活跃度、线上消费习惯。
2.2 基于优化K值选取的改进K-means算法
2.2.1K-means算法描述
K-means[21]是一种经典的基于划分的聚类方法,一般用欧氏距离作为衡量两个数据点之间相似度的指标,相似度越大,距离越小。该算法的核心思想是:首先确定聚类数目K和K个初始聚类中心。根据数据点与聚类中心的距离,不断更新聚类中心的位置,使得每个簇的误差平方和(sum of squared error,SSE)变小。当SSE不再变化或者目标函数收敛时,SSE值达到最小,迭代停止,得到最终的聚类结果。其算法流程如下。
1)初始化聚类中心 确定聚类数目K,从数据集中随机选取K个点作为初始聚类中心Ci(1≤i≤K)。
2)分配样本 计算其余数据点与聚类中心Ci的欧氏距离,找出最短距离并将所有样本分配到聚类中心Ci对应的簇中。
欧式距离计算公式为
(1)
式(1)中,x为数据对象,Ci为第i个聚类中心,m为数据对象的维度,xj、Cij为x和Ci的第j个属性值。
3)更新聚类中心 计算每一簇中所有点的平均值及平方误差,将平均值作为新的聚类中心,重复步骤2)。
平方误差计算公式为
(2)
4)直至聚类中心不再变化或达到最大的迭代次数,循环结束,得到最终聚类结果。
2.2.2 优化K值选取的改进K-means算法
尽管K-means聚类算法不依赖于数据的标签信息,对大数据特征挖掘有很好的解释效果,但是传统的K-means算法存在人为设定K值的缺陷。基于此,本文引入了Calinski-Harabasz(CH)聚类质量评价指标,将最高的CH得分所对应的类设定为本研究的聚类数目。
CH指标由簇间样本分离度与簇内样本紧密度的比值得到,CH越大代表类自身越紧密,类与类之间越分散,即聚类结果更优。当簇内密集且簇间分离较好时,从CH得分折线图中可以明确得出最佳聚类数目,并且具有计算速度快的优点。
CH指标优化K-means算法的实现步骤如下:
输入:数据集X={x1,x2,…,xn}(n表示数据点的数量)。
1)确定最佳聚类数目k。
①计算WGSS
WGSS(Within-Groups Sum of Squared Error)为簇内平方误差和,用来度量簇内样本的紧密度,WGSS越小,簇内越紧密,聚类效果越好。其计算公式为
(3)
②计算BGSS
BGSS(between-groups sum of squared error)为簇间平方误差和,用来度量簇间样本的分离度,BGSS越大,簇间越分散,聚类效果越好。其计算公式为

(4)
③计算CH值
CH得分值S的数学计算公式为
(5)
WGSS越小,BGSS越大,则CH指标值越大,聚类效果越好。
④绘制CH折线图,确定最佳聚类数目k。
2)运行K-means,得出聚类结果:
①初始化聚类中心
输入聚类数目k,从数据集中随机选取k个点作为初始聚类中心Ci(1≤i≤K)。
②分配样本
计算其余数据点与聚类中心Ci的欧氏距离,找出最短距离并将所有样本分配到聚类中心Ci对应的簇中。
③更新聚类中心
计算每一簇中所有点的平均值及平方误差。将平均值作为新的聚类中心,重复步骤2)。
④直至聚类中心不再变化或达到最大的迭代次数,循环结束,得到最终聚类结果。
输出:聚类结果C={c1,c2,…,ck}。
2.2.3 对比验证
为了验证本文采取方法的有效性,本文进行了两次对比实验:第一次为聚类算法对比;第二次为聚类质量评价指标的对比。
1)算法对比
为验证本文算法的有效性,选取UCI数据库中两个标准的测试数据集Breast cancer和Iris plants进行实验,并采用相关研究中常用的谱聚类(Spectral Clustering)方法,与本文的K-means算法进行对比研究。在算法评价上,主要比较了两种算法在两个数据集上的聚类准确率以及运行时间,如表1。

表1 两种算法在不同数据集上的运行情况
从表1可以看出:第一,在聚类准确性上,K-means在两个数据集上的准确率分别为85.4%和89.3%,都有比较好的聚类效果,谱聚类的准确率分别为66.7%和90%,聚类效果相较K-means更不稳定;第二,在运行时间上,K-means在两个数据集上的运行时间分别为19.8 ms和21.9 ms,而谱聚类的运行时间分别为103.8 ms和118.1 ms,可以明显看出,谱聚类的运行时间是K-means算法的5倍多,聚类效率较低。这主要由于谱聚类算法涉及数据之间的相似度矩阵,在数据集维度较高时,无法表现出更优的准确性和聚类效率。然而,电商平台交易量大,数据规模庞大且维度复杂,对聚类效率的要求高,需要及时根据客户的消费行为数据进行划分,以实现高效精准的客户管理。因此,对于电子商务平台的客户细分,相比谱聚类,K-means的聚类效果更优。
2)聚类质量评价指标对比
针对传统K-means算法存在人为设定K值的缺陷,本文引入CH指标,作为客户细分时决定K值的依据。为了验证CH指标对于电子商务行业中的客户细分的适用性,本文使用实证部分的电商数据集,选取拐点法与CH进行对比。图1和图2分别为CH指标和拐点法的实验结果。
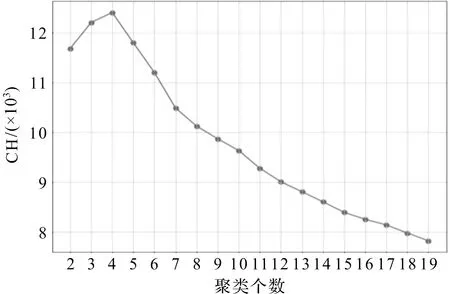
图1 CH得分折线图Figure 1 Line chart of CH score
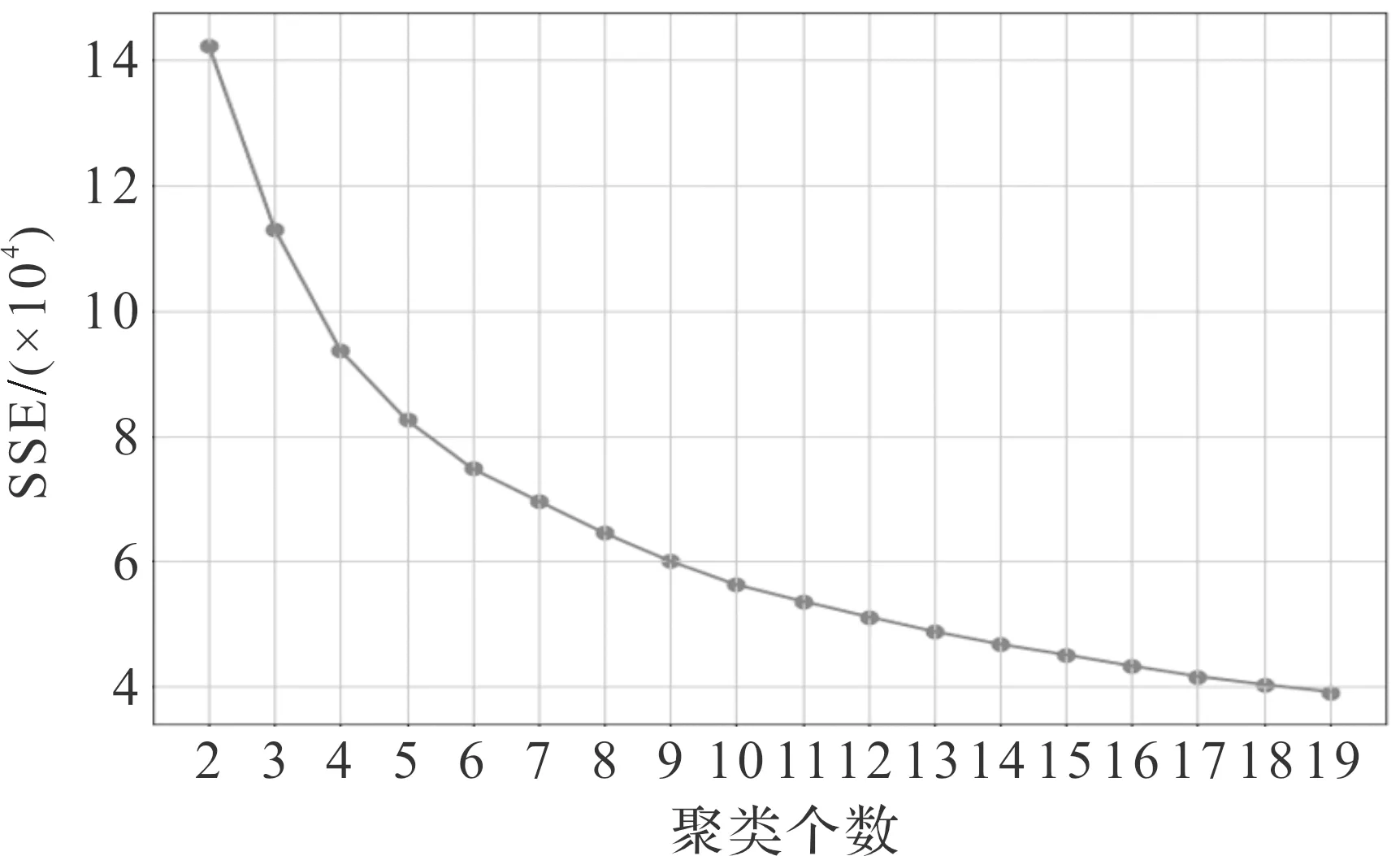
图2 拐点法折线图Figure 2 Line chart of inflexion point method
由图1可以看出,CH得分折线图呈现先上升后下降的趋势,当聚类数目为4时,CH值最高。因此,使用CH指标可以明确得出:该电子商务平台数据集的最佳聚类数目为4。
在图2中,横轴为聚类个数的变化,纵轴为数据的SSE方差,即凝聚度。拐点法原理是:在折线图的拐点处取得最佳聚类数目。其原因在于:拐点之后继续增加K值,对分类的准确度增加不高,但会增加簇数。从而导致对数据的划分过细,影响聚类效果。但是,从图2中可以看出,当K值从4变化到6时,折线图的变化较为平滑,即没有明显的拐点,无法准确判断出最佳聚类个数。
因此,与图1中CH得分的变化趋势相比,拐点法不适合用于电子商务客户细分的研究,使用CH指标优化K-means算法对于电子商务客户细分更具有有效性。
3 电子商务客户细分实证研究
3.1 数据集描述
本文研究数据是从国内某电子商务平台中提取的客户消费数据,数据集包含了2014年11月18日至2014年12月18日之间,一个月内的该平台移动端的37 376名客户的订单及线上行为数据。该数据集可用于以下实际问题的研究:1)建立客户流失预测模型,预测客户流失;2)研究用户在不同时间尺度下的行为规律,找到用户在不同时间周期下的活跃规律;3)根据数据集中的客户订单信息及行为和消费偏好信息,找出最具付费价值的客户群,对这部分客户行为进行分析;4)将数据集中的核心信息整合成几个指标,进行客户细分研究,针对不同特征的客户群采取针对性措施。表2为本文研究涉及数据集中的字段及字段描述。
3.2 数据处理
3.2.1 数据清洗
2014年11月18日至2014年12月18日之间该电子商务客户的行为数据大约一亿多条,需要进行数据清洗:首先处理缺失值和异常值的数据,如购买费用为0的数据、购买日期为空以及购买费用明显有误的数据;然后处理重复数据。用户的购买行为由于时间精确到小时,会存在少量用户在一小时内重复购买或浏览统一商品的行为,因此不对此部分数据进行处理;最后,处理数据的一致性问题,本文涉及的指标L、R涉及到时间特征,并且以天为单位。而时间数据中的日期和小时存在于一列中,故将其拆分成两列。另外,本文将Timestamp字段中的时间戳字段类型转换成年月日的形式,以方便计算时间。
3.2.2 指标提取及归一化
结合本文提出的RFPAV模型,计算整理数据得到37 376位客户的数据,表3为部分数据。
为了防止各指标单位不同所引起的差距过大,在进行算法实验之前,需要对指标提取之后的数据集进行归一化处理。本文采用的归一化方法为Z-score标准化方法,这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为
(6)
式(6)中,μ为所有样本数据的均值,σ为所有样本数据的标准差。
表4为归一化处理前后的部分数据,指标R、F、P、A、V的数据全部被转换为无量纲的数据值。
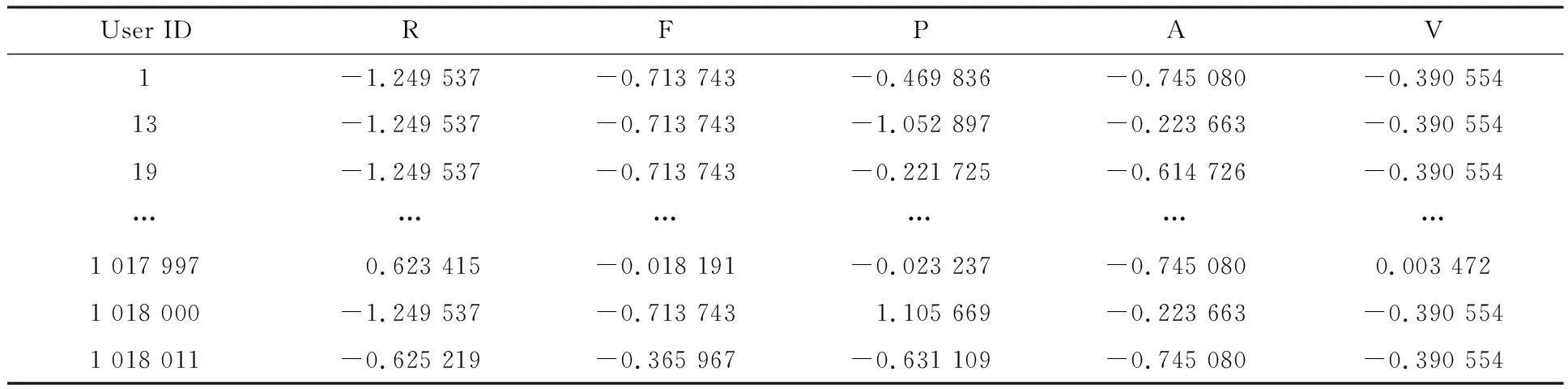
表4 RFPAV模型归一化处理后部分数表
3.3 实证结果分析
根据本文2.2.3小节中的实验结果,确定最佳聚类数目K=4。通过K-means算法和RFPAV模型,得到4组客户聚类数据,图3为4组客户分布饼状图,图4为4组客户RFPAV模型各指标分布图。
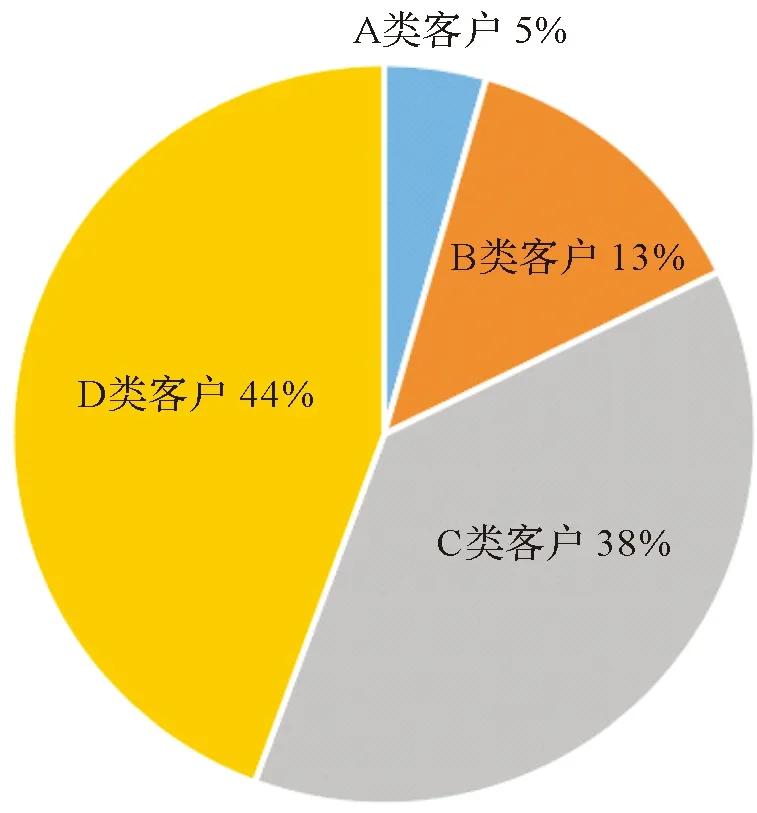
图3 客户类型分布图Figure 3 Distribution chart of customer types
从图3和图4可以看出,价值最大的客户群体是B类客户,包括4 984名顾客,占该电子商务平台数据集的13%。与其他三种客户类型的指标值相比:B类客户的R值较小,说明近期有在该电商平台进行消费;F值最高,说明订单频率高,属于该电商平台中的活跃客户;P值和A值均最高,说明这类客户经常在该电商平台浏览商品,将商品加入购物车的频率也高。这可看出该类客户群当前价值和增值潜力最大,可将其归类为该电商平台的高价值客户群;V值较低,说明这类客户群在遇到感兴趣的商品时,习惯于加购而不是收藏。针对这类客户群,企业需要投入主要精力和资源,保持和发展与这些客户的关系,充分挖掘这类客户的消费潜力。
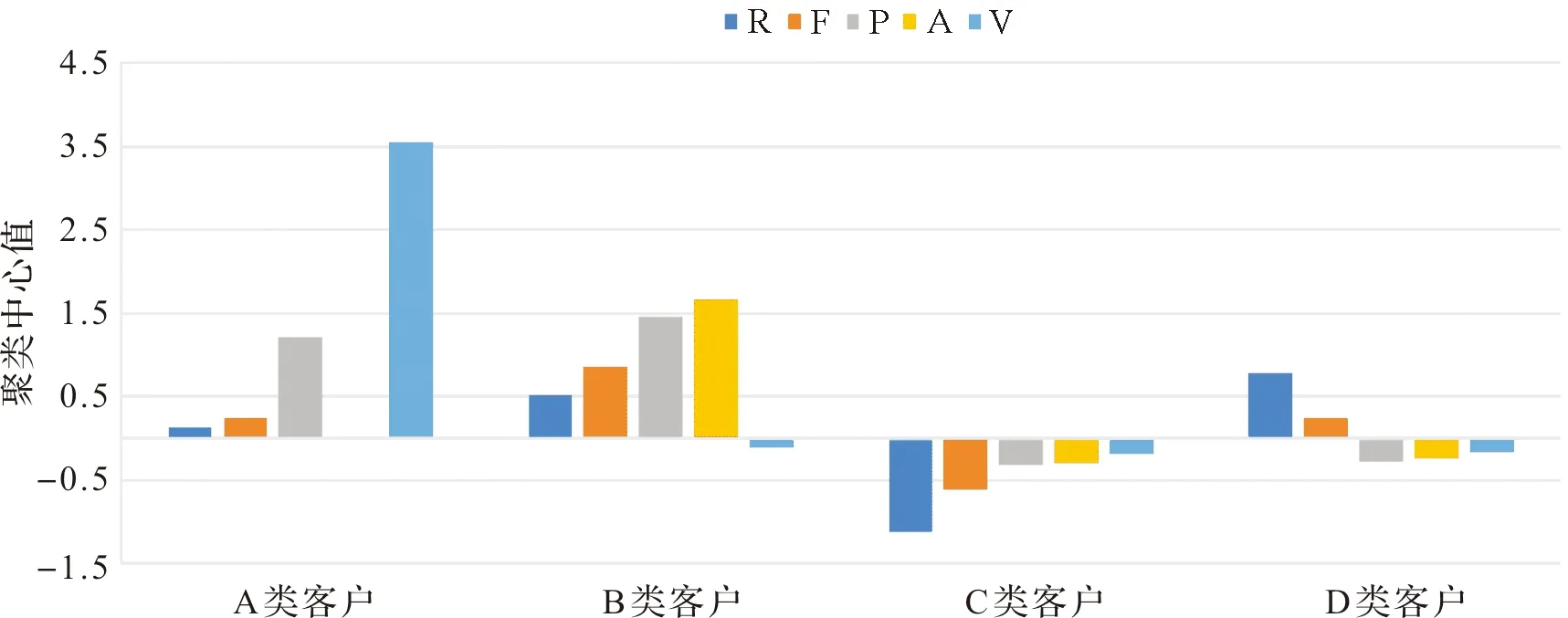
图4 RFPAV模型各指标分布图Figure 4 Distribution chart of RFPAV model
第二类较有价值的客户群体是A类客户,包括1 661名客户,占该电子商务平台数据集的5%。与其他三种客户类型的指标值相比:A类客户的R值相较B类更小,说明在最近几天有在该电商平台进行消费。但是该类客户群的F值更低,说明消费频率比B类低,属于该电商平台中的较活跃客户;P值较高,说明这类客户也经常在该电商平台浏览商品;与B类不同的是,A类客户群的指标A的值低,V值在这四类中属于最高,这说明该类客户群在遇到感兴趣的商品时不习惯于加购,而更习惯于将商品收藏。根据以上分析,可将这类客户归为中等价值客户群。这类客户有较大的价值挖掘潜力,公司应尽可能保持这些客户,提高这类客户在该平台的消费频率,使他们不能够容易地转向竞争对手。
第三类客户群为D类客户,包括16 575名客户,占该电子商务平台数据集的44%。与其他三种客户类型的指标值相比:这类客户的购买频率属于中等程度,但是R值最高,说明很久没有在该电商平台购买商品;P值、A值和V值都较低,表明这类客户属于该电商平台中不活跃的一类群体,不会经常在该平台浏览商品、加购或者收藏。可以将其归类为低价值客户群。但是虽然D类客户群的当前价值一般但增值潜力较好,商家应该重点培养这类客户,增加个性化推送商品的频率,尽可能提升这类客户群的价值。
第四类客户群为C类客户,包括14 156名客户,占该电子商务平台数据集的38%。与其他三种客户类型的指标值相比:这类客户的R值很低,但是F值也是最低的,说明这类客户群最近有在该平台消费,但总体消费频率很低;在P、A、V值方面类似于第三类客户,也属于不活跃的客户群。与D类客户不同的是,虽然这类客户的当前价值很低,购买频率和活跃度都一般,但他们最后一次消费日子却很近,所以这类客户很可能是新获得的客户。对这类客户需特别注意,应及时地推送客户可能感兴趣的商品,做好相关的服务,促进客户关系进一步发展,进而增加客户的购买频率,减少客户流失。
4 结 论
客户关系管理是电商平台保持竞争优势的前提。企业要实现高效的客户关系管理,必须提高客户细分的准确性和效率。针对现有研究存在的客户细分指标单一的问题,以及传统K-means人为设定K值的缺陷,在指标选取上,本文加入了客户的消费行为数据,选取RFPAV作为细分指标;在方法上,引入CH指标对传统K-means算法进行改进,并利用某电子商务平台的37 376个客户样本进行实证研究。基于本文的对比实验结果和实证结果,可以得到以下两点结论:第一,针对电子商务客户特点提出的RFPAV客户细分指标是有效的,本文选取的客户价值特征和客户消费行为特征,能够识别和区分电子商务客户在进行线上消费时表现出的不同消费习惯和偏好;第二,改进K-means算法能够提高电子商务客户数据集的聚类准确性和效率,由于传统的K-means算法存在人为设定K值的缺陷,本文加入了CH聚类质量评价指标,对K-means算法进行改进。当然,本文的研究也存在一定的局限性:第一,客户细分指标需要更加多元,由于电商平台的数据量庞大,数据维度多样,未来可以挖掘更加多元化的特征数据;第二,由于每种算法都有其自身的局限性,为了更好契合电商平台客户样本数据集,实现更有效的客户细分,未来可以考虑将密度聚类、层次聚类等方法引入电子商务客户细分研究中。
猜你喜欢
华人时刊(2020年23期)2020-04-13
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
专用汽车(2016年9期)2016-03-01
现代计算机(2016年17期)2016-02-28
科技与创新(2015年9期)2015-06-02
专用汽车(2015年2期)2015-03-01
中国经济信息(2014年7期)2014-08-09
中国记者(2014年1期)2014-03-01
