
海洋科学中尺度涡的计算机视觉检测和分析方法
2021-01-27 03:23沈飙陈扬杨琛刘博文
数据与计算发展前沿 2020年6期
沈飙,陈扬,杨琛,刘博文
中国海洋大学,山东 青岛 266100
引言
在海洋领域,中尺度涡是指在海洋中持续时间为2~10 个月、半径约为10~100 千米的涡旋[1]。相比于海洋中常见的涡旋,中尺度涡有着更大的半径以及更长的持续时间,但是其规模又远小于海洋中的持续存在的大环流。中尺度涡携带极大的动能,中尺度涡内海水流速非常快,相对洋流平均流速要快几倍到一个量级[2]。径向涡旋通常为几十米到上百米,甚至上千米的深海,海洋深层的营养盐和冷水会被径向涡旋带到海洋表面。中尺度涡还能够将海表暖水压到较深的海洋中,在全球海洋物质、能量和热量等的运输和分配中起着重要的作用。因此,对中尺度涡的研究具有非常重要的科学意义和渔业价值。
近年来,深度神经网络在图像分类、人脸识别、文本识别等多个方面取得了非凡的成就,特别是在图像分类领域,一些新型的技术比如随机丢弃技术(Dropout)、正 则化(Normalization)、 批归一化(Batch Normalization)等,使得深度卷积神经网络模型在复杂的计算机视觉问题中展现出高效的性能。而在目标检测和分割领域,深度网络模型(R-CNN,Faster R-CNN,Mask R-CNN 等)的很多改进版本,识别准确率达到了很高的水准,应用到了生产生活的很多领域[3-7]。
通过结合超分辨率、遥感卫星数据和海洋浮标资料,中尺度涡的检测技术已成为物理海洋领域的研究热点之一[8]。但从卫星遥感数据中识别中尺度涡的主要方法还是依赖专家分析,这种方法劳动强度大,很难满足快速、准确检测的需求,对于大规模数据而言更难以做到全面的检测和分析。另外,传统算法利用海表高度、温度等数据,基于流场几何特征、边缘检测以及拉格朗日随机模型进行中尺度涡检测,这些算法误检率较高。还有一些基于图像和深度神经网络的方法,通过将海洋卫星遥感数据转换成图像作为神经网络的输入,但是这一类方法会损失卫星遥感数据的细节信息,且已有的深度学习模型相对简单,通常检测结果不能达到良好的预期[9-13]。
为解决上述问题,我们将探索使用人工智能中的深度学习算法,对涡旋进行检测、分类和实例分割,也就是结合深度卷积神经网络和多模态海洋卫星遥感数据,实现对中尺度涡的精确检测。我们将使用多模态数据融合,对卫星遥感数据,如海洋表面高度(SSH)、温度(SST))及流速数据(SSV)进行融合学习,摒弃以往将单一类型数据转换成图像数据再进行检测分析的策略。同时,借鉴目标检测、语义分割网络的优点,设计深度区域提取网络用于中尺度涡检测。其中,残差神经网络部分负责学习中尺度涡的特征表示,区域生成网络生成含有中尺度涡的区域并提取特征,头网络部分负责中尺度涡类别和范围预测,整体网络能通过端到端的方式进行训练。
本文主要从设计应用于中尺度涡检测的深度神经网络入手,探索神经网络在提取卫星遥感数据特征中的有效性。本文通过建立特定中尺度涡检测数据集,训练深度神经网络模型,并对比本文提出的基于深度区域提取网络的方法和其同类算法之间的功能性和准确率。
1 数据集来源及构造
1.1 数据集来源
本研究使用的卫星遥感数据来自于哥白尼海洋环境监测服务中心。哥白尼海洋环境监测服务中心的全 球海洋物理再分析数据包(GLOBAL OCEAN PHYSICS REANALYSIS GLORYS2V4)包含海表温度、盐度、洋流、高度以及海冰参数的日常平均值,分辨率为0.25 度,覆盖时间为1993年~2015年。由于其精度高,数据类型全面,所以本数据集的建立使用了全球海洋物理再分析数据包中能够辅助中尺度涡检测的温度、高度以及流速数据。其中海水流速数据包含两个方向,分别是东向海水的流速以及北向海水的流速。
本文实验的数据是GLORYS2V 4 中2000年01月16日到2009年12月16日共计十年的温度、高度以及流速数据,其中这三种数据的维度分别为681×1440×120,681 为纬度的维度,1440 为经度的维度,120 表示数据来自连续的 120 个月。
为了保证神经网络的训练速度,如图1所示,本研究使用了区域大小为128 × 128 的遥感数据。数据采集的方式为随机不重复的在每个月的各类数据中取 13 次,并保证温度、高度以及流速的对应位置相同。在标签(label)的设计中,如图1 气旋涡标(cyclonic)注为1.0,反气旋涡(anticyclonic)标注为-1.0,没有涡的区域标注为0.0。这样能将三种情况的差异尽可能地变大,在识别的时候尽可能降低学习的难度。
在训练集和测试集分配上选择按照3:7 的比例将所有数据分为测试数据和训练数据。
1.2 中尺度涡蒙版的生成
本文使用的Mask-RCNN 算法除了需要给出涡形类别的标注外,还需要给出对应区域的中尺度涡的蒙版(Mask)作为网络的评价,而数据集中并没有直接的给出中尺度涡的蒙版,我们需要基于一个传统的非机器学习算法EddyScan 对卫星雷达高度计数据进行中尺度涡检测,并将此结果作为数据的蒙版标注,然后对本文提出的算法进行有效性检测[14-15]。
该方法在-100m 到+100m 的区间进行间隔为 1m的重复计算。在每个阈值i,EddyScan 识别出数量具有至少为 i 的海平面高度异常的所有连通组件[16]。然后,算法去除属于已经识别的连通分量的所有像素,并且以 i 递增。为了识别反气旋涡,作者在-100 m 初始化并以 1m 步长增加到+100m。相反,通过将 i 从+100m 减小到-100m 来实现对气旋涡的检测[17-19]。
对于大于正常规模的涡旋,用凸包函数(convex hull function)来确定包含涡旋的所有网格数据的最小凸集的大小[20]。如果凸包的面积远大于连接区域的面积,则可能是多个涡旋合并的情况,并且连接的部分未标记为涡旋,丢弃连接的区域,它将保留在之后要检查的网格数据中,增加了再次检测的几率,这样能够保证不漏检,运行流程见表1。

表1 EddyScan 算法流程图Table 1 Flow chart of EddyScan algorithm
该算法运行结束后,我们可以得到SSH 数据对应该图的气旋涡和反气旋涡的Mask 蒙版,及其旋涡的个数,我们为了保证算法能够有效地检测中尺度涡,剔除了不含涡旋的数据,保证了训练集和验证集都是存在中尺度涡。
本文提出的算法是基于深度学习方法的,相对EddyScan 的优势主要体现在以下几个方面:
(1)我们只需要用训练好的模型对图像进行一次操作,就可以准确地得出中尺度涡的位置大小和种类;
(2)从算法复杂度上,EddyScan 需要用逐像素地扫描全部点并通过广度优先搜索来得到涡旋的位置和大小等信息[21],时间复杂度远在我们的算法之上。
2 多模态数据融合和深度区域提取网络的算法描述
卫星遥感数据中的海洋表面温度、高度以及流速都会从不同的角度描述中尺度涡的特征,所以理想的情况下,使用尽可能多的数据类型进行中尺度涡检测是最有效的。多模态数据的融合不仅有利于卷积网络进行中尺度涡特征的提取,更有利于进行中尺度涡的预测。
2.1 数据的预处理
首先,不同数据的数值差异很大,在神经网络的前向传播中,会造成前向传播过程中的数据计算异常。其次,近似为 0 的数值频繁在很多数据中出现,会造成预测结果难以学习。最后,不同类型的数据对中尺度涡检测起到的作用是不同的,换句话说,数据需要按比重进行缩放[21-22]。
我们采用数据预处理进行数据整合。在数据预处理过程中,最重要的是解决数据分布不均匀的问题,本研究尝试使用归一化方式是 min-max 标准化(min-max normalization),这种方式是通过线性计算,把原始的遥感数据进行线性缩放,最终落到[a,b]之间[23]。首先需要找到原始数据分布中的最大值(max)和最小值(min),然后计算缩放系数,
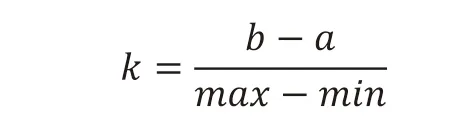
这里我们一般将区间设置为[0,1],因此计算方式也很简单:
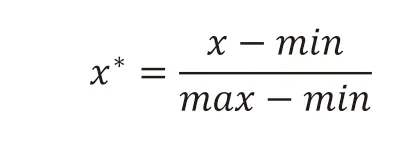
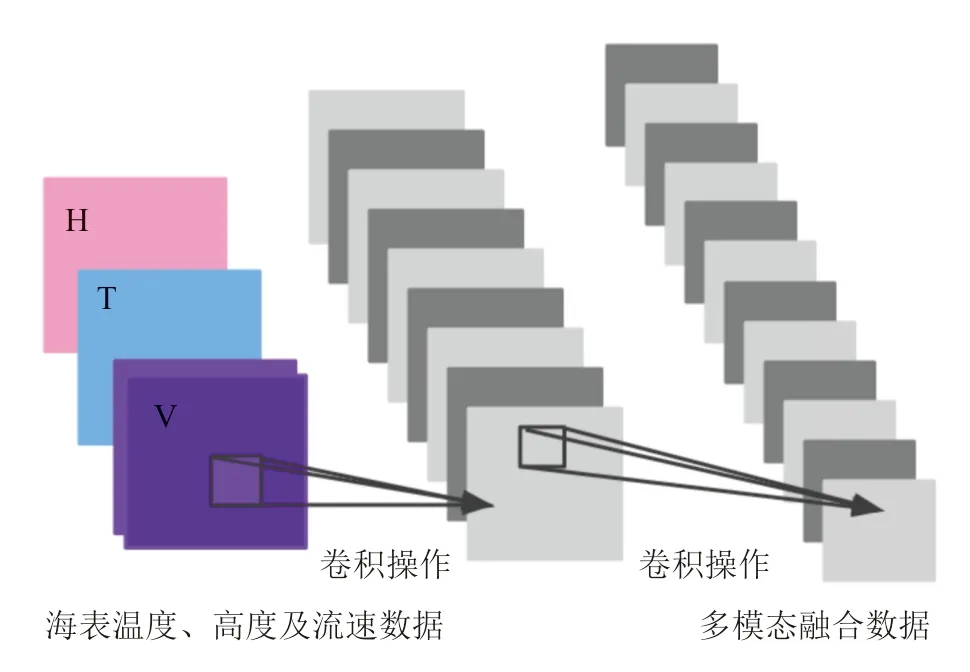
图2 多模态数据融合Fig.2 Multi-modal data fusion
2.2 多模态数据融合
在本文使用的海洋数据中,一共有3 种:分别是海洋表面高度数H,海洋表面温度数据T,海洋表面流速数据V(双通道)。
除了使用归一化方法之外,本文需要用超参数对不同类型数据进行缩放,以探索不同数据类型在中尺度涡检测任务中的重要性。

接下来通过一个简单的卷积神经网络,我们将包含多模态信息的数据进行特征融合。

H 表示海洋表面高度数据,T 表示海洋表面温度数据,V 表示海表面流速数据。
2.3 基于深度区域提取网络的中尺度涡检测算法
本文用到的目标检测算法是深度学习中具有分类、定位和实例分割功能的Mask-RCNN 算法。其主要由 四个部分组成:深度残差网络ResNet-101,区域生成网络RPN,用于定位和分类的全连接网络和生成实例分割的反卷积网络[24]。

图3 深度区域提取网络的中尺度涡检测算法流程图Fig.3 Flow chart of mesoscale eddy detection algorithm for deep region extraction network
2.3.1 深度残差网络
本文中针对中尺度涡的检测问题难度相比较于复杂场景目标检测任务来说,难度较低,所以我们选择了在 coco 数据集下预训练好的ResNet-101 作为特征提取网络。由于我们在 RestNet-101 使用了残差连接,可以有效地减少网络的过拟合,同时减少梯度在反向传播的时候产生梯度弥散现象。
上一步得到的多模态融合数据,经过深度残差网络得到一张通道数维 256 维,尺度为 8*8 的特征图(feature maps),这个特征图表示的是多模态融合数据的高维特征。

图4 残差单元示意图[25]Fig.4 Schematic diagram of residual element
2.3.2 区域生成网络RPN
区域生成网络RPN(Regi on Proposal Networks),作用是找出多模态数据中可能存在旋涡的位置(proposals)。

图5 区域生成网络RPN[26]Fig.5 Region Proposal Networks
产生proposals 需要用到3×3 的滑动窗口(slides-window),每一个滑动窗口需要产生 9 个锚点框(anchors boxs),c6 个变量组成,分别是分别表示的是对输入数据中可能存在涡旋的位置的坐标(x,y),以及以该坐标为几何中心的宽为w,高为h 的锚点框,p 表示该锚点框为旋涡的概率,̂表示不是旋涡的概率[27-28]。通过softmax 判断anchors box 属于positive 或者negative。

接下来通过比较 anchor box 和 ground truth 的 IOU是否大于置信度求得 P*,对预测为旋涡的 anchor box的A =[x,y,w,h]做回归。
先计算positive anchor 与ground truth 之间的平移量和:
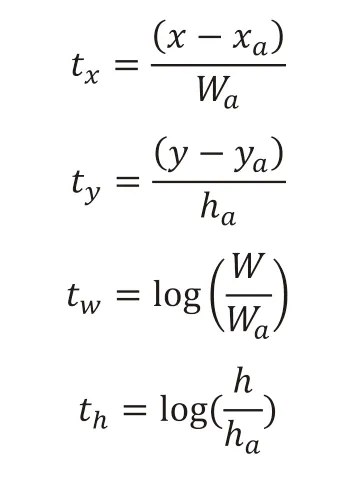
设计回归的损失函数为:
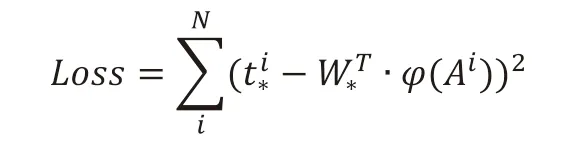
近似于优化目标 :

综上所述,我们在 RPN 层在通过设立分类和回归两个任务,找出 feature maps 在对应位置可能含有旋涡的锚点位置及其的anchor box 的大小。

图6 Mask-RCNN 头网络示意图[29]Fig.6 Mask-RCNN header network diagram
2.3.3 ROI 池化
运用训练好的RPN 网络,我们在 feature maps上预测出旋涡可能出现的区域ROI,将这些可能出现中尺度涡的区域作为接下来全连接网络的输入。由于全连接网络需要固定的输入,所以我们使用ROIAlign 方法规整到相同的尺寸。

图7 ROIAlign 算法[30]Fig.7 ROIAlign algorithm
ROIAlign 池化是基于双线性插值的一种池化方法,对feature map 上距离采样点最近的四个像素点进行双线性插值得到其下采样的像素值。整个过程中不需要对ROI 产生的子区域和采样点进行量化。
其前向传播公式为:

其反向传播公式为:

利用 ROIAlign 下采样方法,我们很大程度上解决了传统池化方法中像素点精度造成的Misalignment对齐问题。
2.3.4 定位、分类和实例分割
接下来我们将规整后的ROI 拉伸成一维向量,作为第一个全连接网络的输入,这个全连接网络的输出分为三个部分。

表2 不同锚点规模对应的学习率Table 2 Learning rate of different anchor size
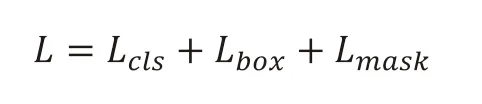
第一部分负责判断中尺度涡的类别。上一步中的 RPN 网络已经帮我们检测出来该ROI 区域内存在旋涡,这一部分的全连接网络的输出仍然是一个二维的向量,每一维分别表示气旋涡和反气旋涡的概率。其损失函数 的计算公式为:

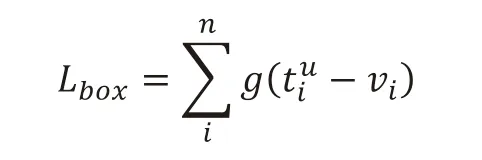
其中,tu表示真实分类对应的预测参数,v 表示ground truth 的参数,平移缩放参数n=4,表示一个候选目标框的四个数值。g(·)表示 Smooth L1 损失,在区间[-1,1]内为二次函数,其余区间为线性函数。Smooth L1 损失的优势在于能够让模型更加鲁棒,在训练过程中不容易造成过大的梯度值,避免越过最优值的情况出现

第三部分为掩码分支,其作用在于对目标区域的中尺度涡进行实例分割。将ROI 通过反卷积转化为和ground truth 尺度一致的bounding box。如果ground truth 中标记了这个 bounding box 的是气旋涡的话,那我们就只针对气旋涡的 Mask 进行分割,而对这个 bounding box 中其他可能存在的物体一律忽视。
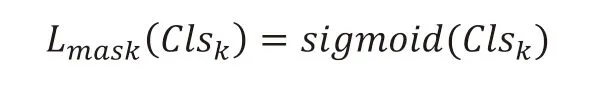
通过上面三个损失函数,我们求得了多模态数据中的存在的中尺度涡的分类、定位以及实例分割。
3 实验结果与分析
3.1 深度学习框架与预训模型的选取
本文选择了深度学习框架为Keras 以及Tensor-Flow。Keras 是一个基于Tensorflow、Theano 的一个高级神经网络API,其框架都有良好的兼容性。Keras的设计初衷是速度快,封装性强,且能够实现功能复杂的深度神经网络模型。TensorFlow 是目前使用范围最广的深度学习框架,由谷歌大脑(Google Brain)负责开发和维护。
硬件方面,深度模型的训练需要进行大量的并行计算,为了在短的时间内对模型进行学习,我们使用了英伟达(NVIDIA)的并行计算产品GeForce GTX 1080Ti,并使用双显卡来提高设备的并行计算能力。
在预训练模型选择上,本研究使用了 Microsoft COCO 数据集对主题网络进行了预训练。Microsoft COCO 数据集是一个用于视觉算法训练的大型数据集,内含有超过 30 万张标注图像,超过 200 万个标注实体,主要用于目标检测、语义场景分割等模型的训练,标注复杂程度上远超图像分类。
3.2 评价指标的设立
本研究通过计算模型 mAP 检验模型的准确度。mAP 为不同 IOU(intersection over union)阈值下的平均准确率(average precision)的平均值[31]。IOU 指的是检测结果和真实标注的交集与并集的比值,IOU值越大说明检测结果越好。
本研究中评估在不同的交并比(IoU)[0.5:0.05:0.95]共10 个IoU 下的AP,并且在最后以这些阈值下的AP 平均作为结果,记为mAP@[.5,.95]。
3.3 实验结果分析
本节将从三个方面设计实验,首先选出适合中尺度涡检测网络的最佳超参数,如学习率、锚点尺度,然后测试多模态数据融合的最佳方法,最后和同类型深度学习算法比较中尺度涡检测的有效性和准确度。
3.3.1 模型超参数选择
本研究采用的优化方法为随机梯度下降法(Stochastic Gradient Descent,SGD),超参数包括锚点尺度(anchor scale)和学习率(learning rate)。SGD是是一种较优深度学习模型优化算法,相比于梯度下降法来说,其能够避免过早陷入局部最优解,在收敛速度上要略慢于Adam、RMSProp 算法,但是SGD 训练得到的模型准确率较高。锚点尺度表示滑动窗口生成的区域的尺寸比例。学习率表示反向传播对模型参数的更新幅度,过大的学习率将会导致更新幅度过大可能越过最优值点,过小的学习率将导致更新幅度偏小、学习时间过长。学习率衰减法是指模型在学习过程中按照一定规则让学习率逐步衰减,这样就能在接近模型最优值时避免因为参数更新幅度过大而偏离最优值。
由上述检测结果可得,在锚点尺度为(4,16,64),训练头网络的初始学习率为 0.001,整体训练的初始学习率为 0.0001 时,mAP 最高为 56.35。
3.3.2 多模态数据融合实验
本小节设置的实验旨在测试多模态数据融合方法的有效性。在 2.2 节中,我们介绍了会对每个类型的数据进行归一化处理,并对每个数据类型赋予权重,分别是海洋表面温度、高度以及流速的权重超参数,且α + β + γ = 1。权重超参的设定不仅能够在一定程度上体现出不同数据类型在进行中尺度涡检测过程中的重要性,而且能够探索多模态数据融合是否对中尺度涡的检测有帮助。
我们固定其他参数,尝试不同的α、β、γ 组合进行实验,训练方式与 3.3.1 小节相同,得到的实验结果如表3。

表3 不同权重比例对应的mAPTable 3 mAP corresponding to different weight proportion size
通过上述实验结果可知,当α、β、γ 的比例为5:3:2 时实验结果最优,表明了海表面高度数据在多模态数据融合中较为重要。
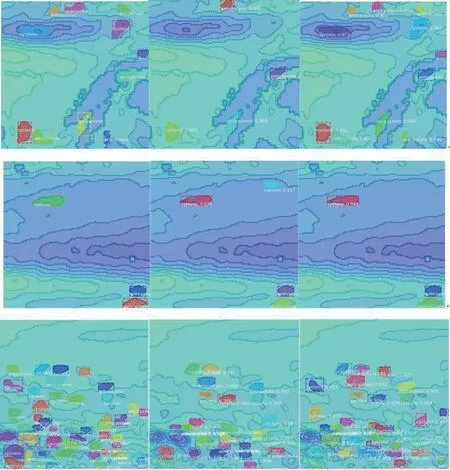
图8 标注数据、海表面高度以及多模态融合数据训练效果对比图Fig.8 The training effect comparison chart of annotated data,sea surface height and multi-mode fusion data
可以看到在仅使用海表面高度数据训练的检测结果中,存在多检或漏检的情况,检测结果不够准确。当被检区域涡旋数量较少时,使用多模态数据训练的模型能够以较高的准确率识别出所有涡旋。在涡旋密集的情况下,仅存在很少量的误检结果。因此可以得出结论,使用多模态数据训练的检测结果整体明显优于仅使用海表面高度训练的检测结果。
3.3.3 同类算法对比
本节将对比实现中尺度涡检测的深度学习方法。本节选了效果比较优秀的两个方法进行对比:方法一是DeepEddy,方法二是EddyNet。

图9 本文方法得到的中尺度涡检测结果示意图Fig.9 A schematic diagram of mesoscale eddy detection results obtained by this method
在功能实现方面,DeepEddy 仅能实现涡旋分类,而 Eddynet 在旋涡分类的基础上实现了涡旋的分割,本研究能基于多模态遥感数据实现涡旋定位、分类和实例分割。
通过对比mAP 值,本研究提出的方法在使用多模态融合数据进行训练时检测结果好于EddyNet。

表4 不同方法实现功能对比[32]Table 4 Function comparison of different methods proportion size

表5 Eddynet 与本方法的mAP 对比[32]Table 5 mAP comparison of Eddynet and this method proportion size
4 总结
本文将中 尺度涡检测和深度学习相结合,探索深度学习中目标检测算法在海洋遥感数据处理上的能力,并实现对遥感数据进行较高准确率的涡旋分割。主要包括三个方面:
(1)提出了基于深度区域提取网络的涡旋检测模型,实现了在卫星遥感数据上的中尺度涡的定位、分类和实例分割。
(2)在中尺度涡检测的过程中使用海表面高度、海表面温度和海水流速数据等多模态数据融合,并通过实验找到数据融合的最佳参数比例。
(3)验证了中尺度涡检测模型的有效性。提出了一个中尺度涡检测数据集,数据集制作中采用了传统非深度学习算法,对遥感卫星数据中每个数据点的类别进行精准标注,并在中尺度涡检测数据集上进行学习,得到了更准确的反馈结果。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
物理学报(2022年22期)2022-12-05
装备制造技术(2022年6期)2022-10-02
北京航空航天大学学报(2022年7期)2022-08-06
流体机械(2021年12期)2021-02-16
成都信息工程大学学报(2021年6期)2021-02-12
现代农业科技(2020年10期)2020-06-04
热带海洋学报(2020年3期)2020-05-25
山西教育·幼教(2020年2期)2020-03-07
扬子江(2019年1期)2019-03-08
南方农业·下旬(2017年3期)2017-07-19
