
自适应局部迭代滤波在齿轮故障识别中的应用
2021-01-26 03:39郭德伟普亚松江洁俞利宾闵洁张文斌
工矿自动化 2021年1期
郭德伟, 普亚松, 江洁, 俞利宾, 闵洁, 张文斌
(1.红河学院 工学院,云南 蒙自 661199;2.云南省高校高原机械性能分析与优化重点实验室,云南 蒙自 661199)
0 引言
齿轮箱是机械设备中进行运动和动力传动的主要部件。在齿轮传动过程中,齿轮的失效常常会诱发机器故障,进而引发设备停机甚至损坏,因此,研究强噪声环境下的齿轮故障特征参数提取技术一直是旋转机械故障诊断的研究热点[1-2]。N.E.Huang等[3]提出的经验模式分解方法吸引了众多学者的关注,它从传统的正交基函数展开,跨越到完全由数据驱动的对任意复杂信号具有自适应能力的信号表示。但是,经验模式分解方法存在如信号中的奇异点容易导致模式混淆、在噪声干扰下不稳定等问题。集合经验模式分解(Ensemble Empirical Mode Decomposition, EEMD)方法在对白噪声进行经验模式分解的基础上,将白噪声加入信号来补充一些缺失的尺度,可较好地减轻模态混叠现象,但仍然不能有效地消除模态混叠现象。在经验模式分解思想的启发下,一些学者提出了新的自适应模式分解方法,自适应局部迭代滤波[4]就是其中比较有代表性的一种。自适应局部迭代滤波方法在保留经验模式分解方法思想的基础上,通过引入Fokker-Planck方程设计滤波器的方式,有效避免了在分解过程中产生虚假分量,更加适用于分析非线性非平稳信号。自适应局部迭代滤波方法已被应用于电力系统非平稳信号的特征提取[5]、滚动轴承的故障特征提取[6]中,取得了较好效果。但在齿轮系统的故障特征提取中应用自适应局部迭代滤波方法的研究还比较少。
针对现场采集信号往往包含大量的噪声干扰而无法准确反映故障特征的问题,提出将自适应局部迭代滤波、样本熵和灰色关联度相结合的齿轮故障识别方法。在齿轮箱模拟实验平台上对齿轮系统的4种不同工况进行实验,采用自适应局部迭代滤波对采样信号进行自适应分解,计算分解得到的各本质模态函数分量的样本熵[7],再计算待识别样本与标准故障模式的灰色关联度,根据灰色关联度进行故障识别和分类。
1 自适应局部迭代滤波
在经验模式分解中,瞬时均值定义为上下包络的均值函数。因为应用对奇异点敏感的三次样条分别连接局部极大值和局部极小值来拟合上下包络,所以这种瞬时均值在扰动下不稳定。为了克服该缺陷,L.Lin等[8]提出了迭代滤波算法。该算法遵循和经验模式分解相同的算法框架,通过对信号进行低通滤波获得瞬时均值。为了保证扰动下的稳定性和收敛性,迭代滤波应用均一的双重长度的平均滤波器。但是,这种滤波器不够平滑,可能会在本质模态函数中引起虚假波动。自适应局部迭代滤波算法应用非均一滤波器拓展迭代滤波算法,将滤波器设计为Fokker-Planck方程(式(1)),使得滤波器在时域内具有紧致支撑且长度灵活变化,避免在迭代滤波过程中产生虚假波动[9]。
(1)
式中:h为信号长度;z为设定参数,取值范围为1.6~2;g(h,z)为滤波函数;α,β为稳态系数,取值范围为(0,1);p(h,z)和q(h,z)为光滑可导函数。
自适应局部迭代滤波算法实现过程:
(1)初始化:令迭代次数i=1,残余信号r0(t)=x(t),x(t)为采样信号,t为采样时间。
(2)提取第i个本质模态函数ci(t)。
(3)更新残余信号ri(t):
ri(t)=ri-1(t)-ci(t)
(2)
(4)若残余信号ri(t)满足算法的终止准则,即最多只有一个极值点而成为趋势项时,终止自适应局部迭代滤波分解;否则令迭代次数i=i+1,返回步骤(2)。
提取第i个本质模态函数的具体实现步骤:
(1)令筛选次数j=0,原型本质模态函数hij(t)=ri-1(t)。
(2)设计自适应局部Fokker-Planck滤波器gij(t,τ)(τ为t的无穷小量),确定相应的时变滤波器长度lij(t)。
(3)计算瞬时均值mij(t):

(3)
(4)更新原型本质模态函数:
hij(t)=hij(t)-wij(t)
(4)
(5)若原型本质模态函数hij(t)满足本质模态函数的条件要求,则用式(5)设置第i个本质模态函数;否则令筛选次数j=j+1,返回步骤(2)。
ci(t)=hij(t)
(5)
2 样本熵的定义
样本熵常用于衡量非线性时间序列的复杂度,其具备抗干扰能力强、在参数较大取值范围内一致性好等特性,便于进行故障特征的提取。设采样序列为x(1),x(2),…,x(N),共N个样本,样本熵[10-12]计算方法如下。
按序号连续抽取m个数据构造一组m维向量X(i):
X(i)=[x(i),x(i+1),…,x(i+m-1)]
(i=1,2,…,N-m+1)
(6)
m维空间中X(i)与X(j)之间的距离为
(j=1,2,…,N-m+1)
(7)
给定阈值u(u>0),对每一个i≤N-m+1,可得
(8)
(9)
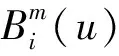
将维数m加1,重复以上步骤,可得样本熵:

(10)
当N为有限值时,样本熵的估计值为
(11)
显然,参数m和u直接影响样本熵的值。根据S.M.Pincus[13]的研究成果,本文中取m=2,u=0.2Std,Std为标准差。
3 齿轮故障识别步骤
(1)搭建齿轮系统故障实验平台,进行故障模拟实验。
(2)采集不同工况下的齿轮故障信号。
(3)对采样信号进行自适应局部迭代滤波分解,得到若干个本质模态函数。
(4)选择前m个包含齿轮故障信息的本质模态分量作为研究对象,求取样本熵。
(5)求出同类状态下N个训练样本的样本熵的平均值,将其作为标准故障模式的参考值。
(6)计算待检测信号的样本熵与各状态下的标准故障模式样本熵平均值的灰色关联度,进行故障分类识别。
在齿轮实验系统中模拟不同工况的故障状态。采用灰色关联度进行故障类型识别,用灰色关联度识别的详细过程可参见作者前期的研究成果[14-15]。
4 实测信号分析
4.1 自适应局部迭代滤波结果
在齿轮箱模拟实验平台上采集齿轮系统正常、齿面轻度磨损、齿面中度磨损和断齿4种工况下的数据,用于检测本文提出的方法在齿轮故障识别中的实际效果。实验台由变速驱动电动机、轴系总成、齿轮箱、加载装置等组成,如图1所示。被试齿轮转频为fr=23.6 Hz,啮合频率为fz=686 Hz,振动信号的采样频率为16 384 Hz。

图1 齿轮故障识别实验平台
分别对4种齿轮工况进行采样,各取20个样本,以齿面轻度磨损故障信号为例,利用自适应局部迭代滤波对采样信号进行自适应分解,得到10个IMF(本征模式函数)分量IMF1—IMF10和1个残余分量,如图2所示,其中a为加速度。从图2可知,自适应局部迭代滤波把非平稳的齿轮故障信号分解为若干个平稳的IMF分量,齿面轻度磨损故障的特征主要集中在IMF1分量上。在IMF8分量中可看出较明显的周期成分,计算该成分的频率可知,该成分对应齿轮的转频信号。

(a)IMF1
为便于比较,采用EEMD方法对同一信号进行自适应分解,结果如图3所示。在EEMD分解中,多个IMF分量均存在故障特征,这说明虽然EEMD方法通过在分解过程中添加噪声来减轻模态混叠程度,但与自适应局部迭代滤波分解相比,模态混叠现象还比较明显。为便于比较,对2种分解结果的前8个IMF分量设置相同的纵坐标范围,由于幅值波动小的模态混叠程度较轻,可以明显看出,EEMD方法的分解结果波动范围比较大,而且在EEMD的分解结果中基本看不出齿轮的转频分量。这也充分说明自适应迭代滤波能有效抑制模态混叠现象。

(a)IMF1
4.2 样本熵计算
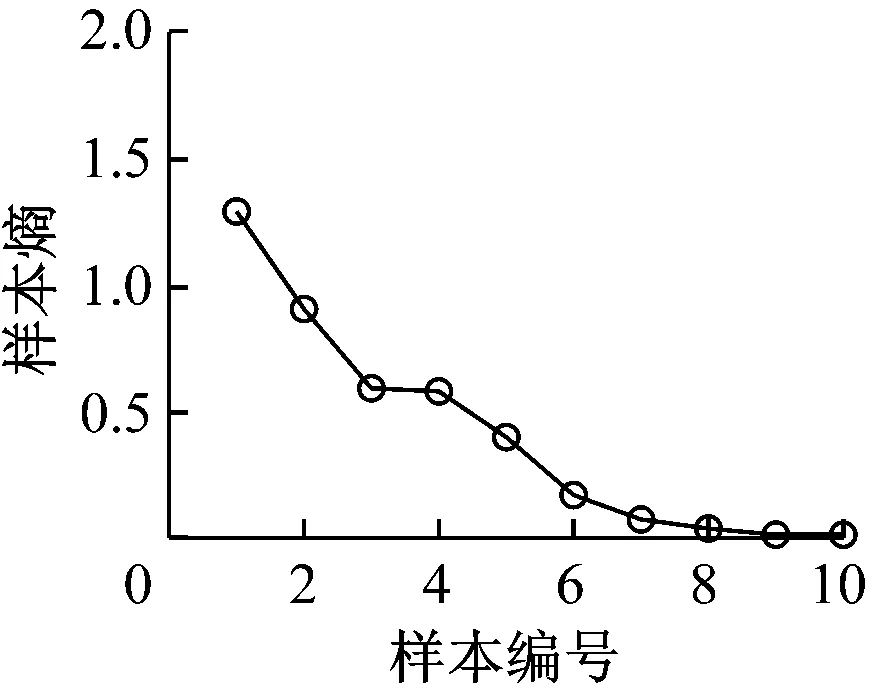
随机抽取每种状态的10个样本作为训练样本,根据齿轮故障识别步骤,将每种状态分解得到的10个本质模态函数作为采样序列,分别代入式(6)—式(11)进行样本熵计算。计算10个训练样本的样本熵平均值,结果如图4所示。从图4可看出,4种工况的样本熵曲线形状存在明显差异,这对于后续进行故障分类识别十分有利。仔细观察样本熵曲线还可发现,每种工况的最后3个样本熵值很小且变化趋于平缓;由于IMF8对应齿轮转频,表明齿轮的故障信息主要包含于前7个IMF中,这说明样本熵能有效表征齿轮故障特征的变化。取前7个IMF分量的样本熵作为故障特征,采用灰色关联度方法对不同故障类型进行分类识别。
(a)正常
限于篇幅,从每种工况的剩余10个样本中随机抽取5个作为待检测样本,同样作为采样序列,分别代入式(6)—式(11)进行样本熵计算,得到前7个IMF信号的样本熵SE1—SE7,结果见表1。

表1 齿轮不同工况下的样本熵
4.3 灰色关联度计算
用灰色关联度方法计算待检测样本的样本熵与各状态下训练样本的样本熵平均值之间的灰色关联度。根据关联度的值进行齿轮故障模式的分类识别,与待识别样本灰色关联度最大的标准故障模式即被认为是待识别样本的故障类型。灰色关联度计算结果及故障识别结果见表2。
从表2可看出,齿轮故障模式识别效果显著,尤其是齿面轻度磨损故障和齿面中度磨损故障。由图4可知,两者的样本熵曲线类似,而从表1的样本熵值可以看到,两者的区别仅在于第2个和第3个样本熵值,但灰色关联度方法能有效地将4种不同的故障类型进行分类识别,相应故障类型的灰色关联度与其余故障类型的灰色关联度之间的差值较大。对剩余的故障样本进行识别,也能得到正确的分类结果。

表2 待检测样本与标准故障模式的灰色关联度
4.4 对比分析
为测试灰色关联度方法是否适合小样本数据的分类识别,将常用的BP神经网络与灰色关联度方法进行对比。将每种工况的20组数据进行平分,一半作为训练样本,一半作为测试样本,2种方法的识别结果见表3。可见,灰色关联度方法的分类识别性能优于BP神经网络,对小样本数据具有较好的分类识别能力。

表3 BP神经网络与灰色关联度分类识别性能对比
5 结论
(1)与EEMD方法的对比分析结果表明,采用自适应局部迭代滤波后,能够发现明显的齿轮转频信号,而采用EEMD方法进行信号分解后,模态混叠现象比较明显,且在EEMD的分解结果中基本看不出齿轮的转频分量,说明自适应迭代滤波能有效抑制模态混叠现象。
(2)样本熵计算结果表明,4种工况的样本熵曲线形状存在明显差异,每种工况的最后3个样本熵值很小且变化趋于平缓;由于IMF8对应齿轮转频,表明齿轮的故障信息主要包含于前7个IMF中,这说明样本熵能有效表征齿轮故障特征的变化。
(3)灰色关联度方法能有效对4种不同的故障类型进行分类识别,相应故障类型的灰色关联度与其余故障类型的灰色关联度之间的差值较大。对比分析结果表明,灰色关联度方法的分类识别性能优于BP神经网络,对小样本数据具有较好的分类识别能力。
猜你喜欢
内燃机工程(2021年6期)2021-12-10
小学生学习指导(低年级)(2020年3期)2020-06-02
少儿科学周刊·少年版(2020年9期)2020-03-04
少儿科学周刊·少年版(2020年9期)2020-03-04
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
中成药(2018年1期)2018-02-02
制造技术与机床(2017年3期)2017-06-23
Coco薇(2017年2期)2017-04-25
Coco薇(2017年2期)2017-04-25
