
汉语学术口语语料库的创建与应用研究
2021-01-22 06:04同济大学刘运同
语料库语言学 2020年2期
同济大学 韩 毅 刘运同
提要:在汉语国际教育的理论研究和教学实践中,汉语学术口语是一个重要的组成部分,然而目前该领域的研究和探索十分有限。本文使用LancsBox平台搭建了规模达86,395字的试验性汉语学术口语语料库。在语料采写的过程中,通过运用语音识别技术,再结合文本人工校对,大幅提高了采写的工作效率。语料处理方面,在参考各类标注系统的基础上,研究采用XML格式,标注了停顿、重复、口误、填充词、未完句和替换等口语现象。同时,利用所搭建的汉语学术口语语料库,本文对汉语学术口语的一些典型特征开展了初步研究。在词频统计和词语分布分析的基础上,本文还完成了汉语学术口语中的自然停顿单位分析及其分布统计,发现自然停顿单位的长度集中在1—15个音节的区间上。
1.引言
在汉语国际教育的研究与教学实践中,生活汉语、通用汉语的教学与研究较多,学术汉语的教学与研究较少,汉语学术口语的教学与研究更少。无论是在英语作为第二语言还是汉语作为第二语言的研究领域,目前语料库的建设都呈现出书面语语料库较多、口语语料库较少的局面。
本文希望通过创建小型试验性汉语学术口语语料库,为进一步创建大型口语语料库,特别是学术口语语料库的探索提供工具和方法方面的支持。利用所搭建的汉语学术口语语料库,初步统计分析所选取语料的停顿单位、词频分布、语义关联以及特殊句式等研究课题,为汉语学术口语研究、口语研究提供语料基础和方法借鉴。
2.汉语学术口语语料库的设计和研制
2.1 语料的采集和转写
语料的采集是搭建任一类型语料库的基础工作。本文所进行的汉语学术口语语料库的搭建是一项试验性的、先导性的研究,并未按照随机抽样或一定规则的分类抽样选择语料,而是依据便利性原则,选取了网易公开课平台上的“南昌大学公开课:现代汉语与社会生活”1的视频作为语料的主要来源。该课程由徐阳春教授主讲,视频音质较高,普通话相对标准,杂音较少,有利于提高转写效率,减少转写错误。
相较于规范的书面语语料来说,口语语料的采写过程更为繁琐。本研究的采写流程为:
(1)转录。使用虚拟声卡工具Virtual Audio Cable配合声音处理工具Adobe Audition CS6对视频声音进行转录并处理保存。其中,采用内录的方式是为了保证声音质量的稳定,不掺杂外界噪声。
(2)转写。将处理过的音频文件导入“讯飞听见”平台,使用“语音转文字——中文机器快转”功能,利用语音识别技术,对声音文本进行前期处理。该步骤的识别准确率可保证在90%以上,能够较好地提升转写效率。
(3)加工存档。对转写后的语料进行精细加工,对照音频文件逐字逐句校对修正,标注停顿等符号,并储存为文本文档。
2.2 语料的标注
语料的标注分为两个层面:第一是语料基本性质的标注,以及语料的采集时间、分类等方面的标注。在这一层面上,汉语学术口语语料库对每一篇语料的标注包括以下6个方面。
(1)类型,包括课堂(这是本研究的试验性语料库的主要语料类型)、学术会议、学术报告等;
(2)学科,分为语言学、金融、计算机科学等;
(3)时间,指语言行为发生的时间,精确至月;
(4)地点,指语言行为发生的地点,精确至单位、组织和场合,如南昌大学、XX学术研讨会;
(5)说话人性别;
(6)说话人年龄,以10岁为单位进行分段分类,如20—29岁、30—39岁等。
语料标注的另一个层面为对具体的词、句子、段落进行标注。如上所述,进行语料标注的目的是研究语言现象,因此语料标注需要有较强的可拓展性和灵活性。本文认为这一层面的标注应坚持以下4个原则。
(1)标注分类明确可辨;
(2)标注符号可以全部或按照分类快速移除;
(3)可以通过标注符号快速提取相应分类的语料;
(4)标注系统具有较强的适配性和拓展性。
在口语话语标注时,通常会从以下4种标注系统中进行选取,包括:Bois的TD、Konrad Ehlich的HIAT、会话分析(CA)传统的转写系统和Brian MacWhinney的CHAT(刘运同 2016)。本文在参考上述标注系统的基础上,结合XML语言的形式与格式,同时以本文重点研究的课题为出发点,对以下口语特征进行标注。
(1)停顿,即口语表达中的自然停顿。在判断停顿时不仅依靠听力辨别,还依靠音频声波图中的静音时长辅助判断,在停顿处插入符号[P]表示。
(2)重复,即口语表达中的语言重复。用“”符号表示,例如:“连不起来有点杂糅[P]。”此处需要对标注符号的形式做一点简单的说明:在“”中,“df”表示一种标注的大类,此处“df”定义的是“口语中的不流畅”现象,也是本文主要标注的类别。“type='repeat'”中的“'repeat'”表示“口语中的不流畅”这一上层类别中的子类别“重复”,下文还会分别介绍其他次级子类。正如例句所示,标注时将需要标注的文本放置与两个尖括号中间,“”表示该标注的完成,“/”是结束的主要标记,在分析时用于提取和定位标注内容。
(3)口误,即在话语中表达错误,但没有进行修改或修改为其他不相关的内容。用“”符号表示,例如:“那么我们的课大学的课呢[P]跟高中那个时候呢[P]不同点在哪里呢[P]。”
(4)填充词,即用于语段间的停顿和过渡的内容。用“”符号表示。这类现象出现的次数较多,例如:“然后[P]那么A怎么怎么样就可以报考是这样的[P]。”
(5)未完句,即当前句子没有说完,重新说或转说其他句子。用“”符号表示。例如:“跟动作的关系最为[P]密切唉你同学们注意第一句没有[P]啊last year in May[P]。”
(6)替换,即在说话时觉得表达不够清晰完整,从而选择快速替换为意思相同或相近的内容。用“”符号表示,例如:“接着往下看[P]成分赘余[P]那就多余了[P]校门前是一条[P]很笔直的大道唉那不就这个很是多余的啦[P]”。
2.3 语料库的搭建
选择以LancsBox作为语料库的搭载平台开展相应研究。LancsBox是由英国兰卡斯特大学的学者们开发的用于语料数据收集、储存和分析的软件系统2。选取LancsBox作为搭载平台的理由包括以下几点。
(1)本地化处理自有语料;
(2)内置算法可以帮助开展分词、词频统计、关键词检索等语料分析的基础性工作;
(3)可将语料分析结果进行可视化展示;
(4)支持中文。
2.4 语料库的检索
2.4.1 语料库基本数据
语料规模:口语音频长度约200 分钟,转写文本(除各类符号)约10万字;
语料类型:高校课堂;
学科细分:语言学;
时间:2013 年4 月(根据网易公开课网站信息推算);
地点:南昌大学;
说话人性别:男;
说话人年龄:50—60岁(根据南昌大学公开资料推算)。
2.4.2 语料关键词检索
语料关键词检索功能通过LancsBox提供的前后文关键字工具KWIC(key word in context)实现。其具体功能包括以下几点。
(1)查询一个词或短语在语料中出现的频率;
(2)检索特殊的语言结构,例如关联词语、口语词、被动句等在语料中的分布情况;
(3)对检索出的语料条目根据具体需求进行分类、筛选和排序;
(4)在两个语料库中对检索数据进行对比分析。
在进行语料关键词检索的过程中,常用的检索方式包括以下4种。
(1)直接输入词或短语进行检索;(2)使用通配符“*”进行检索;(3)使用正则表达式;(4)复杂度更高的方法就是将通配符与正则表达式相结合。
在进行关键词检索时,语料库可以为研究者提供一些自定义的配置选项,下文详细介绍了几种常用的配置。
(1)对关键词左右显示词语数量的配置:默认显示7个词语,可通过自定义配置的方式更改该数值。
(2)初级筛选:研究者在得到相应检索结果后,如得到非常多的信息条目,可据此使用初级筛选配置,定位需要保留的信息条目或者排除带有干扰的信息条目。
(3)高级筛选:若研究者需要进行更为具体的研究工作,则需要限定更多的筛选条件,KWIC tools提供了高级筛选功能,可以对关键词及其左、右的各个词语进行条件设定,同时可进行正则运算。
3.汉语学术口语的词频统计分布与语义关联研究
3.1 词频统计分析
词频统计分析是词汇研究的重要方法,也是语料库研究中分析文本特点的重要方法。汉语词与词之间没有空格等符号标识词的边界,在做词频统计之前需要对汉语文本进行分词处理。本研究结合LancsBox自带的分词模型和Jieba分词模型对语料进行了分词处理。经过两种分词结果的词汇对照,在Jieba分词的基础上,添加自定义词典,并启用HMM模型3,将“是吧”“对不对”等词语准确地切分出来。本文使用Python程序语言引入Jieba模块进行相关的切词处理,在切词前已经将少量英文、阿拉伯数字等先行去除。
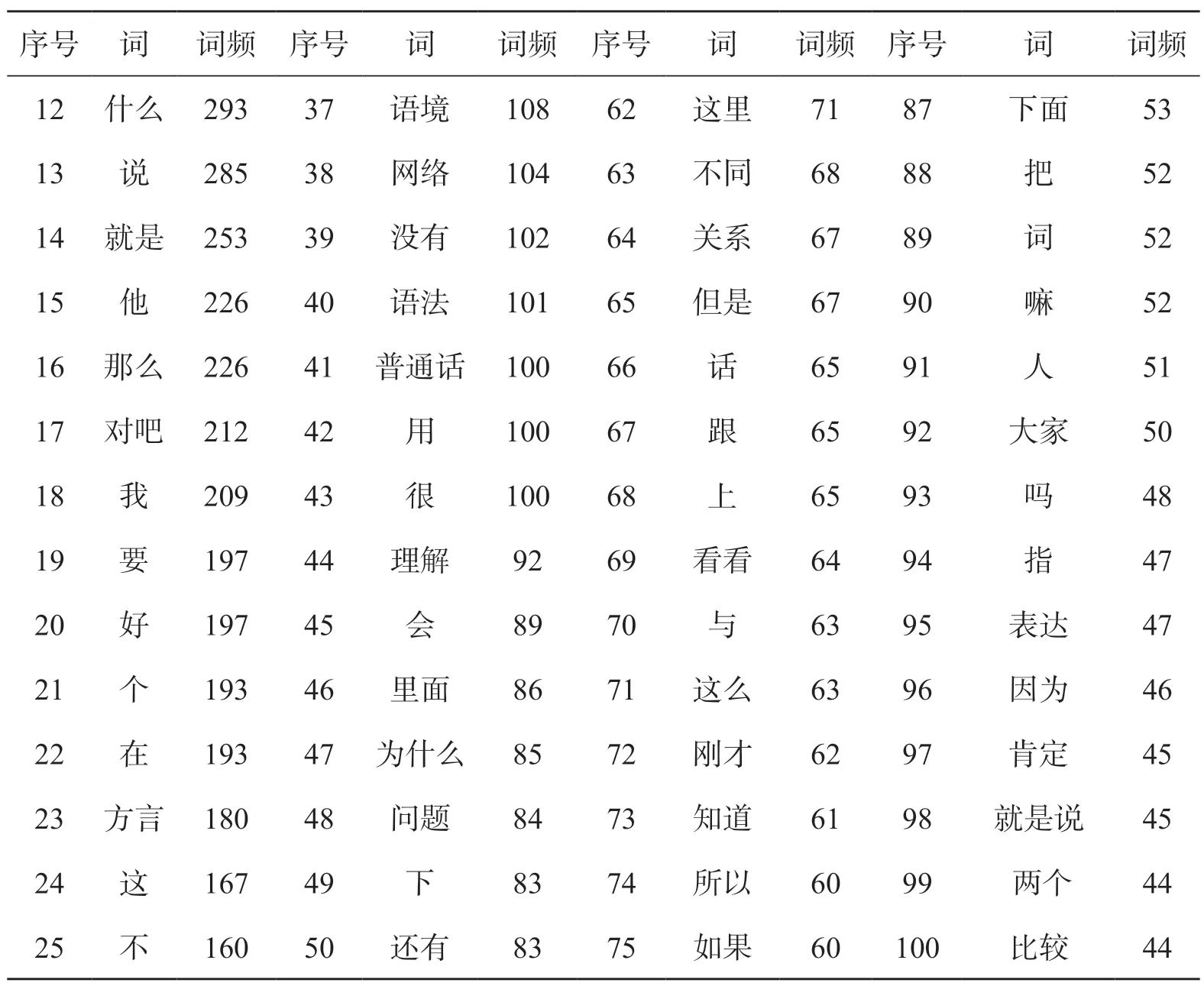
经过中文分词处理,相关语料总共被切出了25,902个词,本文对词频在前100的词进行分析研究。按照词频降序排列后的结果如表1所示。

表1 词频前100的词降序排列结果
(续表)
从统计结果看,词频最高的是“的”“啊”“是”“呢”“了”这些词语。众所周知,“的”在通用汉语中的词频本身就很高。“啊”“呢”等虚词在LCMC(Lancaster Corpus of Mandarin Chinese)汉语书面语语料库中的词频都在200以上4,语料库中“啊”和“呢”等词的高频使用,可视为汉语口语语料库的特征之一。
3.2 词语搭配网络分析
任何一个词语都不是孤立的。在不同的场景下,词语之间存在着某种特定的关系,这种关系很难通过只言片语或少量的文本发现,而运用语料库数据,语料的规模越大,越容易发现特定背景下的语言中词与词之间的特定关系,称之为词语搭配。
我们可以使用两种方法衡量语料库中词语间的关联程度:互信息(MI)和T值(T-score)。MI值可展示语料库中词语的共现频率与预期值的差异。用统计学术语说,这种方法可用来测量词x 和y 之间的关联强度。
但是,在词频非常低的情况下,用MI值测量词语之间关联强度的效果难以尽如人意。T值则可以避免这一问题,这种方法也将词频因素纳入了考虑范围。T值测量的不是关联强度,而是分析可以断言存在关联的置信度(confidence)。从实际的操作情况出发,MI值更可能赋予完全固定的短语以较高的分值,而T值则会产生出现频率相对较高的、特征鲜明的搭配词。
从本次搭建的汉语口语语料库情况来看,词语的出现频率并不低,并且本研究主要关注词语之间的关联强度而非置信度。同时,作者对两种计算方法进行了应用试验,发现MI值更为准确,因此本文选择使用MI值来测算词语之间的关联强度。
LancsBox支持的GraphColl能够便捷地提供MI值与T值的计算,GraphColl是由兰卡斯特大学社会科学语料库研究中心开发的跨平台工具,用于分析搭配网络,建立和研究词语搭配网络,MI值的计算方法如下。
MI=log((AB * sizeCorpus)/(A * B * span))/log(2)
试以“语言”这个词作为关键节点,将参数span(跨距)的取值设置为10(即到关键节点词的左边5个词和右边5个词,可以对这个参数进行调节),“语言”这个词语、与其相关的词语及关联强度可见于表2。

表2 “语言”及相关词语的关联强度
在“位置”一栏中,“L”表示该词出现在关键节点词左边的频率更高,“R”表示该词出现在关键节点词右边的频率更高,“M”表示该词出现在关键节点词的左边和右边的频率一样高。MI值越大,表示与词语“语言”的关联强度越大。
从分析结果中可以看出,与“词语”关联度最强的词是“功能”,常出现在“词语”的右边,即在当前语料中,“语言”和“功能”的关系紧密且顺序常为“语言”在前,“功能”在后。与“语言”关联关系紧密的词还有“形式(R)”“网络(L)”“民族(R)”“环境(R)”“规范(M)”和“交际(M)”等。
词语关联强度的结果可以通过GraphColl绘制成可视化网络图表,距离关键节点越近,则表示关联强度越高;节点颜色越深,代表该词的词频越高,详见图1。
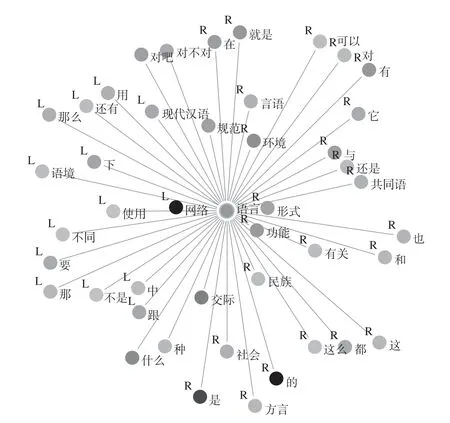
图1 词语关联强度可视化网络
4.学术汉语口语的停顿单位分析
经过梳理,研究根据口语中的停顿将目标文本切分成5,739个停顿单位。需要特别注明的是,一些句子包含英文,英文在统计时会计算构成单词的字母数。例如句子“那么last year in May he went to Hong Kong”统计结果为38个字符。依据这一规则得到的计算结果不尽合理,因此在按停顿单位长度排序时,去除了包含较多英文单词的停顿单位,未将其纳入排序。
4.1 停顿单位长度分析
停顿单位的长度是指一个口语停顿单位所包含的音节数,用正整数表示。依据对当前语料进行的相关统计和排序6,最长的停顿单位包含72个音节,在11秒钟说完,每秒平均说出6.5个音节,其中有较多语言重复。长度在前20的停顿单位包含的音节数以及对应文本如表3所示。

表3 长度前20停顿单位的音节数及文本
(待续)

(续表)
从表3中可以看出,口语中的停顿越长,其话语中的重复、更正等不流畅的语言现象就越多、越明显。
当前语料的平均停顿单位长度为7.57个音节,据此将停顿单位长度分为1—3个音节、4—6个音节、7—9个音节、10—15个音节、16—20个音节、21—30个音节、31—40个音节、41—50个音节、51—60个音节、61—70个音节及71个音节及以上,共计11个停顿单位进行分段统计,其具体分布情况见表4。

表4 语料停顿单位长度分布情况
根据表4的统计分析可以看出,长度在1—15的停顿单位数量占绝对优势,占比达到91.3%以上。可见在学术口语中,长度在1—15的停顿单位更为常见。在这一区间中,长度为1—3和4—6两个区间段的停顿单位又相对较多,由此可以得出,短句在汉语学术口语或课堂语言中较为常见。
4.2 几种长度的停顿单位特点分析
根据表4可以看到停顿单位的长度集中在1—15这一区间上,若再进行一次细分统计,则可得到如表5所示的结果。
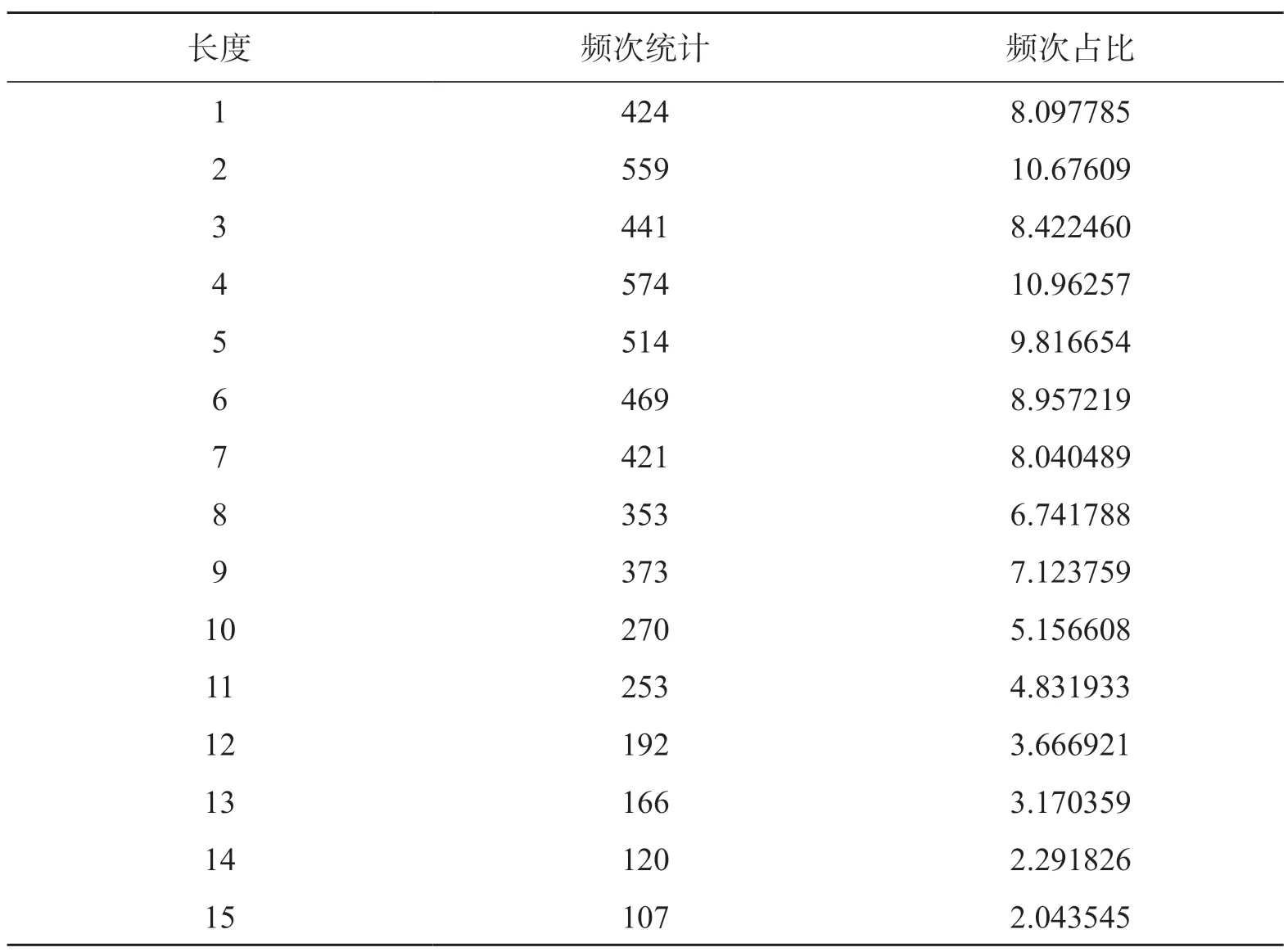
表5 停顿单位为1—15的细分统计情况
下面以停顿单位长度为3个音节的表达单位为例,具体从文本、频次和排序三个方面进行观察。
长度为3个音节的停顿单位共有441个,其中出现频率最高的为“对不对”,在441个句子中出现了45次,占比为10.2%。表6展示了按照频次降序排列的前20个停顿单位及其频次。
在长度为3个音节的停顿单位中,首先,高频使用的是用来进行发问的“对不对”“为什么”“是不是”等;其次,是用于引出解释和说明的“所以呢”“比如说”“可见呢”和“那就是”,也有用来引起听话者注意的“同学们”和“你看看”等,同时也不乏与学术内容相关的专业词语,如“普通话”和“共同语”等。
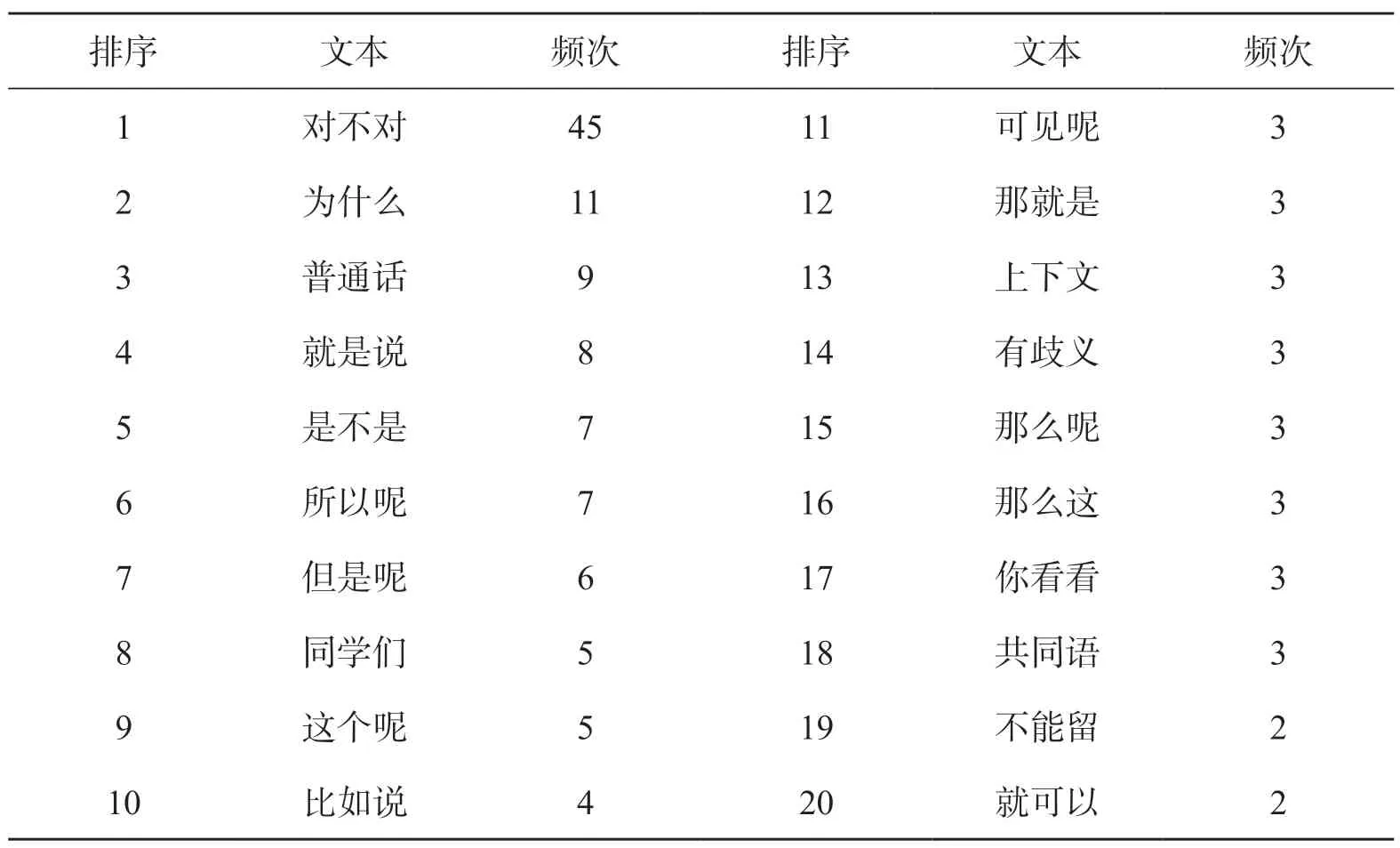
表6 频次降序前20个长度为3的停顿单位及其频次
5.小结
汉语学术口语语料库的创建和分析是一项充满挑战的研究。本研究参考了国外已建成的学术口语语料库的搭建逻辑,如英国学术英语语料库(British Academic Spoken English,简称BASE),并参照了国内部分口语语料库的转写和标注规范,搭建了试验性的学术汉语口语语料库。从语料的收集、音视频的转码、文字的转写到语料标注和入库,搭建语料库的主体环节基本完成。同时,还通过使用相关技术手段,提升了部分流程的效率,例如使用语音识别技术辅助声音转为文本,以及使用程序进行汉语自动分词等。所搭建的汉语学术口语语料库,能够执行检索、分析等研究功能。这项先导研究为大规模学术口语语料库的创建积累了宝贵的经验。
语料库的创建是一项复杂的工程,本研究也存在一些不足。第一,转写与标注的严密性有待加强。严格意义上说,转写文本和标注文本需要多人多层校对审核,以保证较高的准确率。第二,语料库的规模虽然已经超过8 万字(86,395),但对语料库来说规模仍然较小,在进行分析时一些偶然因素可能会导致结果存在较大的误差。
我们发现,即使是一个小规模的学术口语语料库,仍然可以为学术口语研究和教学提供许多有益的参考,例如通过对当前语料库的统计分析,发现汉语学术口语的句长以1—15个音节居多。另外,通过对停顿间的言语单位开展研究,本文发现了大量常用的固定表达方式,如“对不对”“就是说”“为什么”“所以呢”“是不是”等。上述信息不仅能够深化我们对学术口语的认识,也将为学术口语的教学提供真实而有效的素材,以帮助学习者更高效地掌握汉语学术口语。
注 释
1.见http://open.163.com newview/movie/courseintro? newurl=M8s7 JDCEP。
2.见http://corpora.lancs.ac.uk/lancsbox/index.php。
3.HMM模型,即隐马尔可夫模型(Hidden Markov Model,简称HMM),是一种基于概率的统计分析模型,用来描述一个系统隐性状态的转移和隐性状态的表现概率。在Jieba中,对于未登录到词库的词,使用了基于汉字成词能力的HMM模型和Viterbi算法。
4.LCMC语料库是一个100万词次(按每1.6个汉字对应一个英文单词折算)的现代汉语书面语通用型平衡语料库。
5.标准离差率越小,偏离程度越小,词语在整个语料库中的分布更为广泛;反之,标准离差率越大,偏离程度越大,词语在整个语料库中出现更为集中。
6.音频链接https://pan.baidu.com/s/1BvrZDgk5Gcd_Wg3Dg2w1Yw,提取码:h7vt。
猜你喜欢
通信技术(2021年12期)2022-01-25
快乐作文(1.2年级)(2019年9期)2019-09-10
中国修辞(2017年0期)2017-01-31
西藏大学学报(自然科学版)(2016年1期)2016-11-15
读者·校园版(2015年7期)2015-05-14
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中国音乐教育(2014年11期)2014-05-18
图书馆论坛(2014年8期)2014-03-11
心理学报(2014年4期)2014-02-02
