
融合支持向量机和面向对象方法的矿区土地利用信息提取
2021-01-21 01:07霍光杰胡乃勋陈涛甄娜
河南理工大学学报(自然科学版) 2021年2期
霍光杰,胡乃勋,陈涛,甄娜
(1.河南省地质环境监测院,河南 郑州 450000;2.河南省地质环境保护重点实验室,河南 郑州 450006;3.中国地质大学 地球物理与空间信息学院,湖北 武汉 430074)
0 引 言
随着社会经济快速发展,因矿物开采活动带来的环境问题日益突出[1]。传统的矿山地质环境遥感监测依靠人工目视解译,结合现场验证的方式进行,这种方式耗时、费力,且结果受解译人员主观影响较大,准确度和可信性存在一定差异[2]。随着计算机和人工智能技术的快速发展,越来越多的机器智能学习方法被提出,并开始应用于数据提取与挖掘、图像处理与分析、生物信息学等领域[3],这也为矿区信息遥感提取提供了新的方向。在20世纪末,随着遥感技术在高空间分辨率方面的快速发展,影像空间分辨率进入亚米级别,提供了更多的纹理和几何信息,面向对象的思想开始进入人们的视野[4]。M.Baatz等[5]提出了一种多尺度的分割方法,该方法以最小异质性原则为基础,将影像分割为若干对象,在分类过程中具有良好的适用性和高精度,目前已逐渐成为面向对象影像分割中常用的方法。JIANG Y M等[6]研究了时态地理信息系统(GIS)和数字矿山中时空等相关参数的基本概念,提出一种基于面向对象概念的动态变化模拟方法,并应用到湖北开滦数字矿山,可以更高效地提取矿区信息;李昊阳[7]针对山地露天钛铁矿特征的地质环境,基于面向对象思想,建立相关规则集对武定钛铁矿区环境遥感信息进行提取,得到较好的结果;夏孟等[8]应用基于ENVI中面向对象分层分类的方法对湘西花垣县某铅锌矿区进行地物信息提取,得到较好的结果;曹筱莹[9]应用基于面向对象分类技术,采用模糊C均值聚类对矿山开发占地信息进行自动提取方法,在大、小范围的矿区均取得了较好的结果;代晶晶等[10]利用隶属度函数法实现面向对象的稀土开采区分类,提取稀土开采区的总体精度为92.49%,Kappa系数为0.858,具有较高的精度;贾玉娜等[11]以唐山市古冶矿区为研究对象,运用面向对象多尺度分割方法对其进行地物信息提取,矿物对该研究区提取分类总精度可达88.55%,有效避免了“椒盐现象”;周智勇等[12]应用基于面向对象思想结合决策树方法,对露天花岗岩矿山信息进行提取,提取总体精度达到86.29%,Kappa系数达到0.807。随着机器学习(machine learning)算法的快速发展,越来越多的学者们应用其方法对地物进行特征信息提取。陈伟涛等[13]使用WorldView-3影像结合使用遗传算法(GA)、K倍交叉验证(CV)和粒子群优化(PSO)3种方法优化支持向量机算法,应用于露天矿区的精细土地覆盖分类,取得了不错的结果。
上述研究结果表明:基于遥感影像数据,利用机器学习算法或者利用面向对象思路对矿区土地利用信息进行提取,可以得到较高的精度。虽然这些方法都取得了不错的结果,但大部分是应用国外遥感数据,很少有学者利用面向对象的思路结合机器学习方法,采用国产高分数据对露天矿区地表信息进行提取研究。因此,本文基于高分二号(GF-2)国产高空间分辨率遥感影像数据,利用机器学习中的支持向量机算法结合面向对象思想,对河南省禹州市采矿区范围内的土地利用信息进行提取,以探索结合面向对象思想的机器学习方法在矿山环境遥感监测领域的应用,为高效治理矿区生态环境提供及时、准确的数据支撑。
1 研究区概况及数据源
研究区位于河南省禹州市北部,地理位置经度113.375°E~113.561°E,纬度34.256°N~34.352N°,面积约为102.59 km2(图1),属于伏牛山山脉与豫东平原的分界地带,研究区内矿物的主要种类为建筑用灰岩和制作水泥用灰岩。
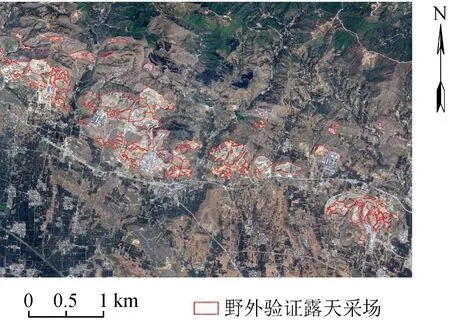
图1 研究区区位图
本文所用遥感数据为一景GF-2影像数据,成像时间为2018年4月16日。GF-2遥感影像的近红外、红、绿、蓝4个不同波段与遥感图像全色融合之后的分辨率可达1 m,成像整体清晰可辨。另有其他矿山辅助数据,现场验证数据、行政区划数据以及土地利用数据等。由现场验证数据可知,研究区内部共有大小露天采场105处,总面积9.35 km2,占研究区面积的9.12%。
2 研究方法
研究流程如图2所示,主要包括数据准备、面向对象影像分割、SVM分类和精度评价等3个部分。
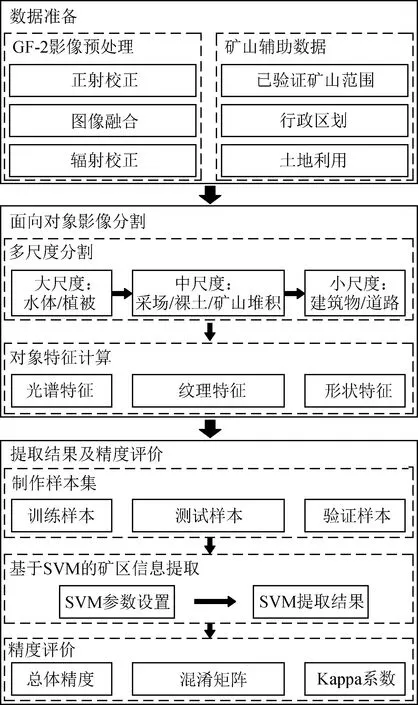
图2 研究流程图
2.1 面向对象的多尺度分割
分形网络演化方法(fractal net evolution approach,FNEA)是目前被大范围运用于遥感影像分割的一种多尺度分割算法,它是利用模糊子集理论对遥感影像进行特征信息提取[14]。其基本思想是遵循异质性最小原则,基于像素从下向上的区域增长的分割算法,将相似光谱信息的像元合并为一个属性的影像地物,分割后将统一地物的所有像元赋予相同含义。反复进行此算法,当异质性的最小增长量超过事先所设定的阈值,则立即终止。
设h为合并前后异质度变化的描述,其值变化主要受对象的光谱异质性和对象的形状异质性影响。计算方法为
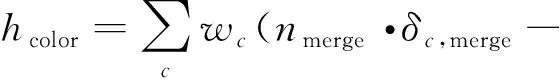
(1)
式中:hcolor为2个对象合并后得到的光谱异质性值与合并前对象obj1和obj2各自光谱异质性值之和的差异;wc为参与分割合并波段的权重,nmerge,δc,merge分别为合并后的区域面积和光谱方差,δc,obj1,nc,obj1,δc,obj2,nc,obj2分别为两个空间相邻区域的光谱方差和面积,c为波段数。
对象合并前后紧凑度指数的增量公式为
(2)
对象合并前后光滑度指数的增量公式为

(3)
对象合并前后的形状异质性增量为光滑度指数增量和紧凑度指数增量的加权平均值,ωsmoothness与ωcompactness为两者间的权重调配,两者的和为1,其表达形式为
hshape=ωsmoothness×hsmoothness+
ωcompactness×hcompactness,
(4)
式中:hshape为对象的形状异质性;I为对象的实际边长;b为对象的最短边长;n为对象面积。
若平滑指标的权重较高,分割后的对象边界较为平滑,反之,若紧密指标的权重较高,分割后的对象形状较为紧密,较接近矩形,对于研究矿区的实际分布情况,调配不同的影像特性和目标对象特性的权重。在影像分割的过程中加入形状因子来制约对象形状的发展,使分割后的区域形状平滑完整。
2.2 对象特征选择
高分遥感影像地物特征主要包括光谱特征、纹理特征、几何特征[15]。为高精度提取研究区地物信息,本文针对研究区域矿区分布情况,主要求得光谱特征中标准差、均值、比率、亮度的值;纹理特征中能量、熵、惯性矩、相关系数、均值的值;几何特征中形状指数、圆度、长宽比、紧致度、主方向、非对称性、密度的值。
2.3 支持向量机(SVM)
支持向量机(support vector machine,SVM)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的[16]。通俗而言,支持向量机是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。因此可以利用已知的有效算法发现目标函数的全局最小值。
3 结果与讨论
3.1 影像分割与特征提取
根据研究区地物实际分布情况,本文将研究区地物分为7类:水体、植被、露天采场、矿山堆积、裸土、道路、建筑。基于eCognition软件平台对研究区遥感图像进行分割,为提高研究矿区的信息提取精度,经过尝试不同的分割尺度并采用目视比较其分割效果后,最后确定的分割尺度、形状/光谱权值、紧致度/平滑度权值如表1所示。

表1 分割尺度和权重值
对研究区域进行影像分割与特征信息提取之后,最终得到48 227个影像对象,图3为局部分割结果。根据质心包含原则,结合原有的禹州市土地利用数据和矿山地貌景观破坏数据,选取其中7 318个影像对象作为训练样本和7 318个影像对象作为研究区矿区精度评价的验证样本。

图3 局部分割结果
在考虑研究区特点并参考前人的研究结果[17],本文选择了如表2所示的影像对象的特征进行后续计算。

表2 影像对象的特征选择
3.2 基于支持向量机的面向对象分类
样本集中训练、测试样本共7 318个,其中露天采场2 153个,矿山堆积1 203个,建筑物1 383个,植被1 026个,道路899个,水体149个,裸土505个,按照7∶3的原则随机划分成训练和测试样本,SVM的核函数选择为高斯核函数(RBF),决策函数类型使用一对多法(one-versus-rest,OVR),惩罚系数C和gamma经过网格参数寻优后分别为1和0.045。经过训练样本的训练后,得到了0.85的测试样本精度。将分类器应用于全部48 227个对象,对其进行预测,得到SVM的最终分类结果,如图4所示。

图4 SVM分类结果
为了判断SVM的分类效果,本研究同时使用融合K近邻 (K-nearest neighbors,KNN)与面向对象的方法进行矿区土地利用信息提取,得到KNN的分类结果并与SVM进行比较。KNN算法是一种广泛应用于字符识别、文本分类、图像识别等领域的分类算法[18]。在算法具体应用中,最相邻样本的个数是最关键的参数。在本研究中,K值经过多次尝试后,取值为7。实验流程中所涉及到的影像分割、特征计算和样本选取均与SVM分类过程相同,最后得到0.82的测试样本精度。将分类器应用于全部48 227个对象,对其进行预测,得到KNN的最终分类结果(图5)。
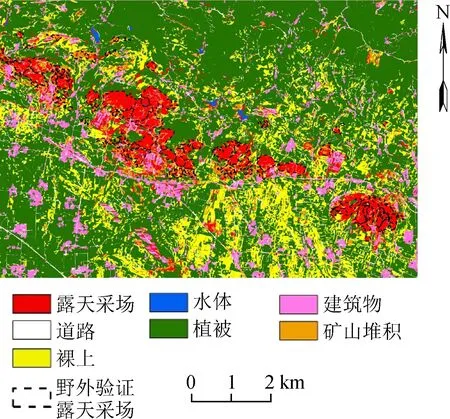
图5 KNN分类结果
3.3 精度评价
本研究采用监督学习中混淆矩阵精度评价方法[19]。在研究范围内选取7 318个影像对象为分类精度验证样本,精度评价参数包括生产者精度(user accuracy,UA)、使用者精度(producer accuracy,PA)、总体分类精度(overall accuracy,OA)、Kappa系数,最终所得分类结果数据如表3所示。

表3 SVM/KNN分类精度融合矩阵
经混淆矩阵计算,融合SVM和面向对象方法的OA为86.44%,Kappa系数为0.83,其中露天采场的UA和PA分别为82.86%和87.43%,而融合KNN和面向对象方法的OA为82.90%,Kappa系数为0.79,其中露天采场的UA和PA分别为89.78%和68.71%(表4)。从表3中可以看出,融合SVM和面向对象方法的精度总体上优于融合KNN和面向对象的方法。虽然融合KNN和面向对象方法的UA优于融合KNN和面向对象的方法,但是从混淆矩阵中可以看到,融合KNN和面向对象方法露天采场分类正确的个数要远远少于融合SVM和面向对象方法的个数。

表4 SVM/KNN露天采场分类精度对比
4 结 论
本文以提取矿区露天采场为出发点展开研究,利用GF-2遥感影像,结合面向对象分类思想,构建了基于SVM的矿区地表信息提取模型,在此基础上提取了河南省禹州市以露天采场为主的矿区占地信息,利用OA,Kappa,UA和PA对提取结果进行精度评价。得出以下结论:
(1)将基于面向对象思想的机器学习算法应用于矿山环境监测领域,构建了SVM模型并结合面向对象方法对以露天采场为主的矿区占地信息进行提取。利用混淆矩阵计算得到模型总体精度为86.44%,Kappa系数为0.83,露天采场的UA为82.86%,PA为87.43%。
(2)结果表明,基于SVM和面向对象思想的矿区信息提取方法,在矿山地质环境监测中的精度总体上优于融合KNN和面向对象的方法,说明其具有一定的优势和准确性,其结果具有理想的精度,可以为矿山环境治理提供快速、可信的技术支持。
猜你喜欢
国外核新闻(2022年7期)2022-11-25
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年10期)2022-08-22
采矿技术(2022年4期)2022-08-17
农业工程学报(2022年8期)2022-08-08
矿冶工程(2021年6期)2022-01-06
矿山安全信息(2021年16期)2021-11-29
矿冶(2021年4期)2021-08-25
新疆有色金属(2021年2期)2021-05-22
电脑知识与技术(2016年27期)2016-12-15
