
人工智能识别主持人语音情感
2021-01-20 10:24夏文心
文化产业 2020年33期
◎夏文心
(云南师范大学传媒学院 云南 昆明 650500)
就目前而言,人工智能技术成为我们日常生活中不可缺少的一项重要技术,可以通过运用互联网计算机系统研究许多事物以及这些事物的方方面面,如识别人们的语音、情感、态度等,并从理论研究逐渐走向实质性研究[1]。人工智能通过辨别我们的语音,能获取主持人在此时所要表达的情绪和情感;从原有的数据库中筛选调取与个人情绪情感相匹配的音乐、视频以及图像,通过“情感标签”筛选出适应个人情绪,然后实现自动配乐和配景[2]。
一、研究的方法与步骤
本研究首先进行情感定义,使输出语音有相应的对应标签。使用语谱图作为主持人的语音的认识辨别功能,利用GAN(简称生成对抗网络)对原始输入特征进行提取。使用长短记忆网络对GAN的输出特征进行进一步提取[3],使其具有上下时刻关联性,大大提高了最终的识别结果。将提取出的特征进行分类,输出“情感标签”。
二、情感的定义
本研究的主要基础与核心部分,是探究情感是什么,如何进行情感的分析。当前学术界通常将情感表示为连续型情感和离散型情感。连续型情感主要是匹配一个比较单一的情感态势和语音这个空间中的一小部分或者是连续的一个段落,然后通过连续的情感坐标表达人类的语音情感态势[4]。
三、提取语音特征的方法
怎样提炼筛选适合的匹配的特征用以显示不同的情绪情感,最关键最主要的问题是在于,怎样提取筛选比较合适的匹配的特点特征来表达不一样的情绪情感,同时具有准确性与泛化性。声学特征通常具体包括:频谱的特征、连续的特征、Teager能量算子,质量的特征。本文我们使用生成对抗网络来进行语音特征提取与生成,经过GAN的判别网络进行精确的语音识别,从而提升语音识别的精确度[4]。
四、GAN模型的定义
生成对抗网络进行语音特征的提取增强了语音识别的准确性,我们在生成器阶段使用GAN对其语音技术进行准确的特征提取[3]。判别器使用卷积神经网络进行精度判别。二者之间使用空间变换网络进行连接。
五、GAN+ LSTM + SVM情感识别模型设计
本部分主要研究基于GAN+ LSTM + SVM的情感识别模型的设计。
(一)GAN提取语音特征
首先是进行基于GAN的语音情感的特征进行筛选与提取,在运用网络进行特征的筛选与提取时,其深度在比较大程度上决定了最后识别出来的结果成效的好坏[4]。伴随着卷积神经网络逐渐增加的层级数量、逐渐变深的深度,筛选出不同的维度特征越来越多样化,比较高的维度特征更加具有抽象特点,可以更好地表现出最终展现结果的好坏。
(二)LSTM进行进一步提取
我们运用长段记忆网络LSTM进一步筛选语音情绪情感的特征。在以往的神经网络中,上下时刻处理信息的关联,模型是不会关注的,通常一段话中每一个时刻要表述的情绪情感是不太一致的。所以,我们将前后两个语句与他们各自所对应的情感特征相互联系起来,这样能非常好地识别出情绪情感的标签。
(三)使用SVM进行分类
我们使用支持向量机,进行最后的精准分类。
六、语音情感识别的整体流程
本部分主要包括:情感定义、语音情感特征提取,生成对抗网络,支持向量机和基于GAN+ LSTM + GAN的情感识别模型的设计五部分。
(一)情感定义
本次研究我们使用中科院CASIA汉语情感语料库和太原理工大学张雪英老师团队录制的情感数据库,对主持人情感定义语音情感数据库。
(二)语音情感特征提取
本小结主要介绍两种常用的语音特征:梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)和语谱图。公式(1)表述了梅尔频率与声音频率f的关系[4]:
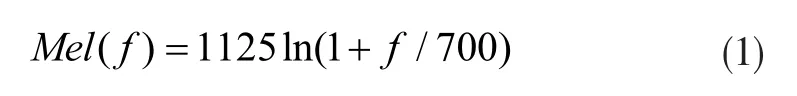
通过提取梅尔频率倒谱系数,语音里面所有包含的情绪情感特征都可以显示一部分的向量,每一帧都可以代表一个向量。
语谱图自身本来就涵盖了全部声音信号的频谱,是一种具有动态的频谱,产生的快速傅里叶变换为如下:

其中,Xn(m)为分帧语音的第n帧信号。0≤k≤N-1,则|X( n, k)|是X( n)的短时幅度谱估计,而m处的频谱能量密度函数p( n, k)为:

(三)生成对抗网络
2014年Ian Goodfellow提出了GAN以来,对GAN的研究可谓如火如荼[3]。GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。他的训练是处于一种对抗博弈。在此我们给出了GAN识别语音的原理图:
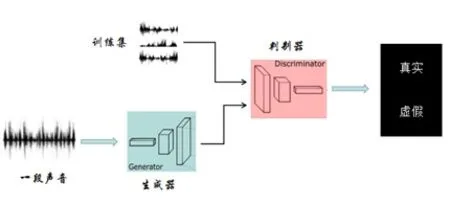
GAN识别语音的原理图
(四)支持向量机
支持向量机通常是运用于如何进行分类和回归的问题[3]。在这种情况下虽然样本量比较少,但是其表现不错。支持向量机主要运用二元分类当中。
(五)GAN+ LSTM + GAN的情感识别模型的设计
本部分给出了基于GAN+ LSTM + GAN的情感识别模型的设计,基于GAN+ LSTM + SVM模型是一种先利用语谱图进行输入,使用生成对抗网络进行特征的提取;使用长短记忆网络对生成对抗网络进行进一步的提取;最后作为SVM支持向量机的输入,得到分类结果,然后输出感情标签[4]。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
